Decoupling Provenance Capture and Analysis from Execution
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Download Media Player Codec Pack Version 4.1 Media Player Codec Pack
download media player codec pack version 4.1 Media Player Codec Pack. Description: In Microsoft Windows 10 it is not possible to set all file associations using an installer. Microsoft chose to block changes of file associations with the introduction of their Zune players. Third party codecs are also blocked in some instances, preventing some files from playing in the Zune players. A simple workaround for this problem is to switch playback of video and music files to Windows Media Player manually. In start menu click on the "Settings". In the "Windows Settings" window click on "System". On the "System" pane click on "Default apps". On the "Choose default applications" pane click on "Films & TV" under "Video Player". On the "Choose an application" pop up menu click on "Windows Media Player" to set Windows Media Player as the default player for video files. Footnote: The same method can be used to apply file associations for music, by simply clicking on "Groove Music" under "Media Player" instead of changing Video Player in step 4. Media Player Codec Pack Plus. Codec's Explained: A codec is a piece of software on either a device or computer capable of encoding and/or decoding video and/or audio data from files, streams and broadcasts. The word Codec is a portmanteau of ' co mpressor- dec ompressor' Compression types that you will be able to play include: x264 | x265 | h.265 | HEVC | 10bit x265 | 10bit x264 | AVCHD | AVC DivX | XviD | MP4 | MPEG4 | MPEG2 and many more. File types you will be able to play include: .bdmv | .evo | .hevc | .mkv | .avi | .flv | .webm | .mp4 | .m4v | .m4a | .ts | .ogm .ac3 | .dts | .alac | .flac | .ape | .aac | .ogg | .ofr | .mpc | .3gp and many more. -

Ardour Export Redesign
Ardour Export Redesign Thorsten Wilms [email protected] Revision 2 2007-07-17 Table of Contents 1 Introduction 4 4.5 Endianness 8 2 Insights From a Survey 4 4.6 Channel Count 8 2.1 Export When? 4 4.7 Mapping Channels 8 2.2 Channel Count 4 4.8 CD Marker Files 9 2.3 Requested File Types 5 4.9 Trimming 9 2.4 Sample Formats and Rates in Use 5 4.10 Filename Conflicts 9 2.5 Wish List 5 4.11 Peaks 10 2.5.1 More than one format at once 5 4.12 Blocking JACK 10 2.5.2 Files per Track / Bus 5 4.13 Does it have to be a dialog? 10 2.5.3 Optionally store timestamps 5 5 Track Export 11 2.6 General Problems 6 6 MIDI 12 3 Feature Requests 6 7 Steps After Exporting 12 3.1 Multichannel 6 7.1 Normalize 12 3.2 Individual Files 6 7.2 Trim silence 13 3.3 Realtime Export 6 7.3 Encode 13 3.4 Range ad File Export History 7 7.4 Tag 13 3.5 Running a Script 7 7.5 Upload 13 3.6 Export Markers as Text 7 7.6 Burn CD / DVD 13 4 The Current Dialog 7 7.7 Backup / Archiving 14 4.1 Time Span Selection 7 7.8 Authoring 14 4.2 Ranges 7 8 Container Formats 14 4.3 File vs Directory Selection 8 8.1 libsndfile, currently offered for Export 14 4.4 Container Types 8 8.2 libsndfile, also interesting 14 8.3 libsndfile, rather exotic 15 12 Specification 18 8.4 Interesting 15 12.1 Core 18 8.4.1 BWF – Broadcast Wave Format 15 12.2 Layout 18 8.4.2 Matroska 15 12.3 Presets 18 8.5 Problematic 15 12.4 Speed 18 8.6 Not of further interest 15 12.5 Time span 19 8.7 Check (Todo) 15 12.6 CD Marker Files 19 9 Encodings 16 12.7 Mapping 19 9.1 Libsndfile supported 16 12.8 Processing 19 9.2 Interesting 16 12.9 Container and Encodings 19 9.3 Problematic 16 12.10 Target Folder 20 9.4 Not of further interest 16 12.11 Filenames 20 10 Container / Encoding Combinations 17 12.12 Multiplication 20 11 Elements 17 12.13 Left out 21 11.1 Input 17 13 Credits 21 11.2 Output 17 14 Todo 22 1 Introduction 4 1 Introduction 2 Insights From a Survey The basic purpose of Ardour's export functionality is I conducted a quick survey on the Linux Audio Users to create mixdowns of multitrack arrangements. -

Command-Line Sound Editing Wednesday, December 7, 2016
21m.380 Music and Technology Recording Techniques & Audio Production Workshop: Command-line sound editing Wednesday, December 7, 2016 1 Student presentation (pa1) • 2 Subject evaluation 3 Group picture 4 Why edit sound on the command line? Figure 1. Graphical representation of sound • We are used to editing sound graphically. • But for many operations, we do not actually need to see the waveform! 4.1 Potential applications • • • • • • • • • • • • • • • • 1 of 11 21m.380 · Workshop: Command-line sound editing · Wed, 12/7/2016 4.2 Advantages • No visual belief system (what you hear is what you hear) • Faster (no need to load guis or waveforms) • Efficient batch-processing (applying editing sequence to multiple files) • Self-documenting (simply save an editing sequence to a script) • Imaginative (might give you different ideas of what’s possible) • Way cooler (let’s face it) © 4.3 Software packages On Debian-based gnu/Linux systems (e.g., Ubuntu), install any of the below packages via apt, e.g., sudo apt-get install mplayer. Program .deb package Function mplayer mplayer Play any media file Table 1. Command-line programs for sndfile-info sndfile-programs playing, converting, and editing me- Metadata retrieval dia files sndfile-convert sndfile-programs Bit depth conversion sndfile-resample samplerate-programs Resampling lame lame Mp3 encoder flac flac Flac encoder oggenc vorbis-tools Ogg Vorbis encoder ffmpeg ffmpeg Media conversion tool mencoder mencoder Media conversion tool sox sox Sound editor ecasound ecasound Sound editor 4.4 Real-world -
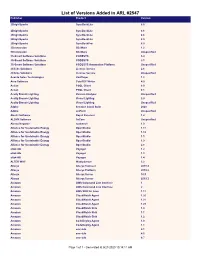
List of Versions Added in ARL #2547 Publisher Product Version
List of Versions Added in ARL #2547 Publisher Product Version 2BrightSparks SyncBackLite 8.5 2BrightSparks SyncBackLite 8.6 2BrightSparks SyncBackLite 8.8 2BrightSparks SyncBackLite 8.9 2BrightSparks SyncBackPro 5.9 3Dconnexion 3DxWare 1.2 3Dconnexion 3DxWare Unspecified 3S-Smart Software Solutions CODESYS 3.4 3S-Smart Software Solutions CODESYS 3.5 3S-Smart Software Solutions CODESYS Automation Platform Unspecified 4Clicks Solutions License Service 2.6 4Clicks Solutions License Service Unspecified Acarda Sales Technologies VoxPlayer 1.2 Acro Software CutePDF Writer 4.0 Actian PSQL Client 8.0 Actian PSQL Client 8.1 Acuity Brands Lighting Version Analyzer Unspecified Acuity Brands Lighting Visual Lighting 2.0 Acuity Brands Lighting Visual Lighting Unspecified Adobe Creative Cloud Suite 2020 Adobe JetForm Unspecified Alastri Software Rapid Reserver 1.4 ALDYN Software SvCom Unspecified Alexey Kopytov sysbench 1.0 Alliance for Sustainable Energy OpenStudio 1.11 Alliance for Sustainable Energy OpenStudio 1.12 Alliance for Sustainable Energy OpenStudio 1.5 Alliance for Sustainable Energy OpenStudio 1.9 Alliance for Sustainable Energy OpenStudio 2.8 alta4 AG Voyager 1.2 alta4 AG Voyager 1.3 alta4 AG Voyager 1.4 ALTER WAY WampServer 3.2 Alteryx Alteryx Connect 2019.4 Alteryx Alteryx Platform 2019.2 Alteryx Alteryx Server 10.5 Alteryx Alteryx Server 2019.3 Amazon AWS Command Line Interface 1 Amazon AWS Command Line Interface 2 Amazon AWS SDK for Java 1.11 Amazon CloudWatch Agent 1.20 Amazon CloudWatch Agent 1.21 Amazon CloudWatch Agent 1.23 Amazon -

Cd Ripping Guide
CD RIPPING GUIDE for an average user Nikola Kasic Ver.7.0, March 2007 INTRODUCTION The time has come for me to rip my CD collection and put it on my home server. Actually, I tried to do it an year ago and was hit by the complexity of the subject and postponed it for some later time. I simply wasn't ready to dig deeply enough to master offsets, cue sheets, gaps and other issues. I thought it's just a matter of putting CD in the drive, choose file format and click button, and being overwhelmed with technical issues/choices I just gave up, being scared that if I make a wrong choice I'll have to re-rip all my collection later again. I don't consider myself an audiophile. My CD collection is about 150-200 CDs and I don't spend too much time listening music from CDs. My hi-fi (home theater) equipment is decent, but doesn't cost a fortune and has a dedicated room. However, it's good enough to make it easily noticeable when CD has errors, or music is ripped at low bitrate. Therefore, I prefer that equipment is limiting factor when enjoying music, rather then the music source quality. My main reason for moving music from CDs to files might sound strange. I had DVD jukebox (Sony, 200 places) which I was filling with CDs and only a few DVDs and really enjoyed not having to deal with CDs and cases all over the place. They were protected from kids and I had photo album with sleeves where I was storing CD covers, so it was easy to find disc number in jukebox. -

Kafl: Hardware-Assisted Feedback Fuzzing for OS Kernels
kAFL: Hardware-Assisted Feedback Fuzzing for OS Kernels Sergej Schumilo1, Cornelius Aschermann1, Robert Gawlik1, Sebastian Schinzel2, Thorsten Holz1 1Ruhr-Universität Bochum, 2Münster University of Applied Sciences Motivation IJG jpeg libjpeg-turbo libpng libtiff mozjpeg PHP Mozilla Firefox Internet Explorer PCRE sqlite OpenSSL LibreOffice poppler freetype GnuTLS GnuPG PuTTY ntpd nginx bash tcpdump JavaScriptCore pdfium ffmpeg libmatroska libarchive ImageMagick BIND QEMU lcms Adobe Flash Oracle BerkeleyDB Android libstagefright iOS ImageIO FLAC audio library libsndfile less lesspipe strings file dpkg rcs systemd-resolved libyaml Info-Zip unzip libtasn1OpenBSD pfctl NetBSD bpf man mandocIDA Pro clamav libxml2glibc clang llvmnasm ctags mutt procmail fontconfig pdksh Qt wavpack OpenSSH redis lua-cmsgpack taglib privoxy perl libxmp radare2 SleuthKit fwknop X.Org exifprobe jhead capnproto Xerces-C metacam djvulibre exiv Linux btrfs Knot DNS curl wpa_supplicant Apple Safari libde265 dnsmasq libbpg lame libwmf uudecode MuPDF imlib2 libraw libbson libsass yara W3C tidy- html5 VLC FreeBSD syscons John the Ripper screen tmux mosh UPX indent openjpeg MMIX OpenMPT rxvt dhcpcd Mozilla NSS Nettle mbed TLS Linux netlink Linux ext4 Linux xfs botan expat Adobe Reader libav libical OpenBSD kernel collectd libidn MatrixSSL jasperMaraDNS w3m Xen OpenH232 irssi cmark OpenCV Malheur gstreamer Tor gdk-pixbuf audiofilezstd lz4 stb cJSON libpcre MySQL gnulib openexr libmad ettercap lrzip freetds Asterisk ytnefraptor mpg123 exempi libgmime pev v8 sed awk make -

Downloading and Installing Audacity and the Lame MP3 Encoder
Downloading and Installing Audacity and the Lame MP3 encoder Free Downloads and Complete Tutorials for installation and using Audacity are available on- line at: http://audacity.sourceforge.net/download/ For easiest installation download the Audacity 1.2.6 installer. Get it here. You will also need the LAME MP3 encoder. Get it here. After you click on the Audacity 1.2.6 installer link shown above, this window will open. Click on Direct link to download Audacity. After clicking on the above link, choose where you want to SAVE the file. After it’s downloaded just double-click on the file and do a standard installation. Audacity is ready to use but you won’t be able to export to MP3 format audio, only WAV format unless you go back and DOWNLOAD AND INSTALL THE LAME MP3 ENCODER… SEE LINK ABOVE. WARNING: DO NOT DOWNLOAD THE AVS AUDIO EDITOR (IT’S NOT FREE!) After you click on the Lame MP3 encoder link a new window will open. Click on this link. In the window that opens, choose this link Then choose SAVE and save it to the desktop This is what the downloaded Lame MP3 encoder installer will look like on your desktop. Double-click it to install. Let it install the encoder to the default location, C:\Program Files\Lame for Audacity as shown on the right. When you’re done editing your AUDACITY PROJECT, you have to EXPORT it as an MP3 audio file. Choose File > Export As MP3 as shown on the left. Name your file. The save as type will be MP3 files (*.mp3) When you click Save this window will open. -

Name Description Synopsis Options
xcfa_cli(1) Manual: 0.0.6 xcfa_cli(1) NAME xcfa_cli −This program is an implementation of xcfaincommand line. DESCRIPTION xcfa_cli is an application for conversion, normalization, reconfiguring wav files and cut audio files ... What xcfa_cli can do: -replaygain on files: flac, mp3, ogg, wavpack -conversions: -from files: wav, flac, ape, wavpack, ogg, m4a, mpc, mp3, wma, shorten, rm, dts, aif, ac3 -tofiles: wav, flac, ape, wavpack, ogg, m4a, mpc, mp3, aac -conversion settings for file management: flac, ape, wavpack, ogg, m4a, aac, mpc, mp3 -management tags -management cue wav file -manipulation of the frequency, track and bit wav files -standardization on files: wav,mp3, ogg -cuts (split) wav files -displaying information on files SYNOPSIS xcfa_cli [ −i "file.*" ][ −d wav,mpc,... ][ OPTIONS ] OPTIONS −−verbose Verbose mode −h −−help Print help mode and quit −i <"file.type"> −−input <"file.type"> Input name file to convert in inverted commas: −−input "*.flac" Type input files: wav,flac, ape, wavpack, ogg, m4a, mpc, mp3, wma, shorten, rm, dts, aif, ac3 −o <path_dest/> −−output <path_dest/> Destination folder.Bydefault in the source file folder. −d <wav,flac,ape,...> −−dest <wav,flac,ape,...> Destination file: wav,flac, ape, wavpack, ogg, m4a, mpc, mp3, aac −r −−recursion Recursive search −e −−ext2src Extract in the source folder.This option is useful with ’−−recursion’ −−nice <priority> Change the priority of running processes in the interval: 0 .. 20 Management options with default parameters: −−op_flac <"−5"> −−op_ape <"c2000"> −−op_wavpack <"−y −j1"> 0.0.6 Thu, 06 -

Cannot Find Codec Libx264 in Libavcodec
Cannot find codec libx264 in libavcodec -ovc lavc -lavcopts vcodec=libx (I also tried with libxvid). It spat out this error at the end: Code: Cannot find codec 'libxvid' in libavcodec. [SOLVED] unsuported codecs in kdenlive. configure --enable-gpl --enable-libx and you need recent x (maverick) this codec is provided by package libavcodec-extra Cannot find codec 'libx' in libavcodec Couldn't open video filter 'lavc'. Failed to open the encoder. libx is right in the man page under. I didnt get how to "install" the x codec on windows so i can use ffmpeg to hmm - but i cant load the h codec - the avcodec_open function failed! as . double videoPTS; // init libavcodec, register all codecs and formats. Opening video decoder: [ffmpeg] FFmpeg's libavcodec codec family Cannot find codec 'h' in libavcodec VDecoder init failed:(Opening. I installed the x codec thus: Code: root@a:/home/g/dnlds# whereis decoder: [ffmpeg] FFmpeg/libavcodec audio decoders AUDIO: [Log in to get rid of this advertisement] Quality, I get error message that codecs libx and libmp3lame are missing. 0 libavcodec MOV track #0: chunks, samples MOV: AVC decoder configuration Opening video decoder: [ffmpeg] FFmpeg's libavcodec codec family Forced video codec: vssh Cannot find codec matching selected -vo. I've successfully compiled: x codec, libavcodec with x support enabled, -vf scale= Cannot find codec 'x' in libavcodec. In general, codecs are utilized by multimedia applications to encode or decode audio or video GStreamer; xine; libavcodec. [audio options] [output] ffmpeg [input] -vcodec libx -vpre medium -b k. sudo apt-get install libavcodec-extra libavdevice-extra To get even more codec support you can enable the Medibuntu repository. -

Name Description
SoX(7) Sound eXchange SoX(7) NAME SoX − Sound eXchange, the Swiss Army knife of audio manipulation DESCRIPTION This manual describes SoX supported file formats and audio device types; the SoX manual set starts with sox(1). Format types that can SoX can determine by a filename extension are listed with their names preceded by a dot. Format types that are optionally built into SoX are marked ‘(optional)’. Format types that can be handled by an external library via an optional pseudo file type (currently sndfile) are marked e.g. ‘(also with −t sndfile)’. This might be useful if you have a file that doesn’twork with SoX’sdefault format readers and writers, and there’sanexternal reader or writer for that format. To see if SoX has support for an optional format or device, enter sox −h and look for its name under the list: ‘AUDIO FILE FORMATS’ or ‘AUDIO DEVICE DRIVERS’. SOXFORMATS & DEVICE DRIVERS .raw (also with −t sndfile), .f32, .f64, .s8, .s16, .s24, .s32, .u8, .u16, .u24, .u32, .ul, .al, .lu, .la Raw(headerless) audio files. For raw,the sample rate and the data encoding must be givenusing command-line format options; for the other listed types, the sample rate defaults to 8kHz (but may be overridden), and the data encoding is defined by the givensuffix. Thus f32 and f64 indicate files encoded as 32 and 64-bit (IEEE single and double precision) floating point PCM respectively; s8, s16, s24,and s32 indicate 8, 16, 24, and 32-bit signed integer PCM respectively; u8, u16, u24, and u32 indicate 8, 16, 24, and 32-bit unsigned integer PCM respectively; ul indicates ‘µ-law’ (8-bit), al indicates ‘A-law’ (8-bit), and lu and la are inverse bit order ‘µ-law’ and inverse bit order ‘A-law’ respectively.For all rawformats, the number of channels defaults to 1 (but may be over- ridden). -

Here Make Use of the Command-Line and Command-Line (Or Text User Interface) Tools
Command-Line Guide to Audio Files in Ubuntu | T u... http://localhost/wordpress/static/backup_cli_audio_g... Command-Line Guide to Audio Files in Ubuntu This guide focuses on showing you how to manipulate and convert various audio files using tools included in the Ubuntu repositories. It contains mostly everything you need to know to convert various formats to the free format Ogg Vorbis, including explanations on how to convert FLAC to WAV and vice-versa, convert FLAC, WAV, APE, AC3, WMA or SHN to Ogg Vorbis, edit tags from command-line for free audio formats, and much more. The guide is divided into the following sections, so that you can click on any of them to jump directly to the chapter which is of interest to you: Introduction to Audio Manipulation on Linux The Setup: Tools That We Need Converting FLAC to WAV and Vice-Versa Converting FLAC or WAV to Ogg Vorbis Editing Ogg Vorbis Tags Converting FLAC or WAV to MP3 Ripping Audio CDs Split FLAC, WAV or APE With a CUE File Converting WMA to Ogg Vorbis Converting APE to Ogg Vorbis or MP3 Converting AC3 to WAV Using MPlayer Music Players As a side note, this tutorial does not include references on how to edit or record sound (for example with Audacity or some other audio editor). Also, all the methods explained here make use of the command-line and command-line (or text user interface) tools. At the end of the guide there are several links to helpful links, a list of music players for Linux (both for GUI and CLI), as well as links to reviews for those. -

(D-Suite) Version 5.5-C Voting System
6705 Odyssey Drive Suite C Huntsville, AL 35806 Phone (256)713-1111 Fax (256)713-1112 Test Plan for EAC 2005 VVSG Certification Testing Dominion Voting Systems Democracy Suite (D-Suite) Version 5.5-C Voting System EAC Project Number: DVS-DemSuite5.5-C Version: Rev. 01 Date: 04/13/2020 TP-01-01-DVS-38-01.01 SIGNATURES Approved by: 04/13/2020 Michael Walker, VSTL Project Manager Date Approved by: 04/13/2020 Wendy Owens, VSTL Program Manager Date TP-01-01-DVS-38-01.01 REVISIONS Revision Description Date 00 Initial Release 04/02/2020 Updated per EAC comments. Added Smart Card information to 01 Table 3.3. Added information to Section 1.1.2, Section 4.2, and 04/13/2020 Section 4.10. TP-01-01-DVS-38-01.01 TABLE OF CONTENTS 1.0 INTRODUCTION.......................................................................................................................... 1 1.1 Description and Overview of EAC System Being Modified ........................................................... 1 1.1.1 Baseline Certified System ................................................................................................... 1 1.1.2 Description of Modification .............................................................................................. 23 1.1.3 Initial Assessment ............................................................................................................. 24 1.1.4 Regression Test ................................................................................................................. 24 1.2 References .....................................................................................................................................