David Et Al Hum Genet Supp Mat 2020
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

The DEAD-Box RNA Helicase-Like Utp25 Is an SSU Processome Component
Downloaded from rnajournal.cshlp.org on September 25, 2021 - Published by Cold Spring Harbor Laboratory Press The DEAD-box RNA helicase-like Utp25 is an SSU processome component J. MICHAEL CHARETTE1,2 and SUSAN J. BASERGA1,2,3 1Department of Molecular Biophysics & Biochemistry, Yale University School of Medicine, New Haven, Connecticut 06520, USA 2Department of Therapeutic Radiology, Yale University School of Medicine, New Haven, Connecticut 06520, USA 3Department of Genetics, Yale University School of Medicine, New Haven, Connecticut 06520, USA ABSTRACT The SSU processome is a large ribonucleoprotein complex consisting of the U3 snoRNA and at least 43 proteins. A database search, initiated in an effort to discover additional SSU processome components, identified the uncharacterized, conserved and essential yeast nucleolar protein YIL091C/UTP25 as one such candidate. The C-terminal DUF1253 motif, a domain of unknown function, displays limited sequence similarity to DEAD-box RNA helicases. In the absence of the conserved DEAD-box sequence, motif Ia is the only clearly identifiable helicase element. Since the yeast homolog is nucleolar and interacts with components of the SSU processome, we examined its role in pre-rRNA processing. Genetic depletion of Utp25 resulted in slowed growth. Northern analysis of pre-rRNA revealed an 18S rRNA maturation defect at sites A0,A1, and A2. Coimmunoprecipitation confirmed association with U3 snoRNA and with Mpp10, and with components of the t-Utp/UtpA, UtpB, and U3 snoRNP subcomplexes. Mutation of the conserved motif Ia residues resulted in no discernable temperature- sensitive or cold-sensitive growth defects, implying that this motif is dispensable for Utp25 function. -

Analysis of Gene Expression Data for Gene Ontology
ANALYSIS OF GENE EXPRESSION DATA FOR GENE ONTOLOGY BASED PROTEIN FUNCTION PREDICTION A Thesis Presented to The Graduate Faculty of The University of Akron In Partial Fulfillment of the Requirements for the Degree Master of Science Robert Daniel Macholan May 2011 ANALYSIS OF GENE EXPRESSION DATA FOR GENE ONTOLOGY BASED PROTEIN FUNCTION PREDICTION Robert Daniel Macholan Thesis Approved: Accepted: _______________________________ _______________________________ Advisor Department Chair Dr. Zhong-Hui Duan Dr. Chien-Chung Chan _______________________________ _______________________________ Committee Member Dean of the College Dr. Chien-Chung Chan Dr. Chand K. Midha _______________________________ _______________________________ Committee Member Dean of the Graduate School Dr. Yingcai Xiao Dr. George R. Newkome _______________________________ Date ii ABSTRACT A tremendous increase in genomic data has encouraged biologists to turn to bioinformatics in order to assist in its interpretation and processing. One of the present challenges that need to be overcome in order to understand this data more completely is the development of a reliable method to accurately predict the function of a protein from its genomic information. This study focuses on developing an effective algorithm for protein function prediction. The algorithm is based on proteins that have similar expression patterns. The similarity of the expression data is determined using a novel measure, the slope matrix. The slope matrix introduces a normalized method for the comparison of expression levels throughout a proteome. The algorithm is tested using real microarray gene expression data. Their functions are characterized using gene ontology annotations. The results of the case study indicate the protein function prediction algorithm developed is comparable to the prediction algorithms that are based on the annotations of homologous proteins. -

Supplemental Table S1
Entrez Gene Symbol Gene Name Affymetrix EST Glomchip SAGE Stanford Literature HPA confirmed Gene ID Profiling profiling Profiling Profiling array profiling confirmed 1 2 A2M alpha-2-macroglobulin 0 0 0 1 0 2 10347 ABCA7 ATP-binding cassette, sub-family A (ABC1), member 7 1 0 0 0 0 3 10350 ABCA9 ATP-binding cassette, sub-family A (ABC1), member 9 1 0 0 0 0 4 10057 ABCC5 ATP-binding cassette, sub-family C (CFTR/MRP), member 5 1 0 0 0 0 5 10060 ABCC9 ATP-binding cassette, sub-family C (CFTR/MRP), member 9 1 0 0 0 0 6 79575 ABHD8 abhydrolase domain containing 8 1 0 0 0 0 7 51225 ABI3 ABI gene family, member 3 1 0 1 0 0 8 29 ABR active BCR-related gene 1 0 0 0 0 9 25841 ABTB2 ankyrin repeat and BTB (POZ) domain containing 2 1 0 1 0 0 10 30 ACAA1 acetyl-Coenzyme A acyltransferase 1 (peroxisomal 3-oxoacyl-Coenzyme A thiol 0 1 0 0 0 11 43 ACHE acetylcholinesterase (Yt blood group) 1 0 0 0 0 12 58 ACTA1 actin, alpha 1, skeletal muscle 0 1 0 0 0 13 60 ACTB actin, beta 01000 1 14 71 ACTG1 actin, gamma 1 0 1 0 0 0 15 81 ACTN4 actinin, alpha 4 0 0 1 1 1 10700177 16 10096 ACTR3 ARP3 actin-related protein 3 homolog (yeast) 0 1 0 0 0 17 94 ACVRL1 activin A receptor type II-like 1 1 0 1 0 0 18 8038 ADAM12 ADAM metallopeptidase domain 12 (meltrin alpha) 1 0 0 0 0 19 8751 ADAM15 ADAM metallopeptidase domain 15 (metargidin) 1 0 0 0 0 20 8728 ADAM19 ADAM metallopeptidase domain 19 (meltrin beta) 1 0 0 0 0 21 81792 ADAMTS12 ADAM metallopeptidase with thrombospondin type 1 motif, 12 1 0 0 0 0 22 9507 ADAMTS4 ADAM metallopeptidase with thrombospondin type 1 -

ANKRD11 Gene Ankyrin Repeat Domain 11
ANKRD11 gene ankyrin repeat domain 11 Normal Function The ANKRD11 gene provides instructions for making a protein called ankyrin repeat domain 11 (ANKRD11). As its name suggests, this protein contains multiple regions called ankyrin domains; proteins with these domains help other proteins interact with each other. The ANKRD11 protein interacts with certain proteins called histone deacetylases, which are important for controlling gene activity. Through these interactions, ANKRD11 affects when genes are turned on and off. For example, ANKRD11 brings together histone deacetylases and other proteins called p160 coactivators. This association regulates the ability of p160 coactivators to turn on gene activity. ANKRD11 may also enhance the activity of a protein called p53, which controls the growth and division (proliferation) and the self-destruction (apoptosis) of cells. The ANKRD11 protein is found in nerve cells (neurons) in the brain. During embryonic development, ANKRD11 helps regulate the proliferation of these cells and development of the brain. Researchers speculate that the protein may also be involved in the ability of neurons to change and adapt over time (plasticity), which is important for learning and memory. ANKRD11 may function in other cells in the body and appears to be involved in normal bone development. Health Conditions Related to Genetic Changes KBG syndrome Several ANKRD11 gene mutations have been found to cause KBG syndrome, a condition characterized by large upper front teeth and other unusual facial features, skeletal abnormalities, and intellectual disability. Most of these mutations lead to an abnormally short ANKRD11 protein, which likely has little or no function. Reduction of this protein's function is thought to underlie the signs and symptoms of the condition. -

A Computational Approach for Defining a Signature of Β-Cell Golgi Stress in Diabetes Mellitus
Page 1 of 781 Diabetes A Computational Approach for Defining a Signature of β-Cell Golgi Stress in Diabetes Mellitus Robert N. Bone1,6,7, Olufunmilola Oyebamiji2, Sayali Talware2, Sharmila Selvaraj2, Preethi Krishnan3,6, Farooq Syed1,6,7, Huanmei Wu2, Carmella Evans-Molina 1,3,4,5,6,7,8* Departments of 1Pediatrics, 3Medicine, 4Anatomy, Cell Biology & Physiology, 5Biochemistry & Molecular Biology, the 6Center for Diabetes & Metabolic Diseases, and the 7Herman B. Wells Center for Pediatric Research, Indiana University School of Medicine, Indianapolis, IN 46202; 2Department of BioHealth Informatics, Indiana University-Purdue University Indianapolis, Indianapolis, IN, 46202; 8Roudebush VA Medical Center, Indianapolis, IN 46202. *Corresponding Author(s): Carmella Evans-Molina, MD, PhD ([email protected]) Indiana University School of Medicine, 635 Barnhill Drive, MS 2031A, Indianapolis, IN 46202, Telephone: (317) 274-4145, Fax (317) 274-4107 Running Title: Golgi Stress Response in Diabetes Word Count: 4358 Number of Figures: 6 Keywords: Golgi apparatus stress, Islets, β cell, Type 1 diabetes, Type 2 diabetes 1 Diabetes Publish Ahead of Print, published online August 20, 2020 Diabetes Page 2 of 781 ABSTRACT The Golgi apparatus (GA) is an important site of insulin processing and granule maturation, but whether GA organelle dysfunction and GA stress are present in the diabetic β-cell has not been tested. We utilized an informatics-based approach to develop a transcriptional signature of β-cell GA stress using existing RNA sequencing and microarray datasets generated using human islets from donors with diabetes and islets where type 1(T1D) and type 2 diabetes (T2D) had been modeled ex vivo. To narrow our results to GA-specific genes, we applied a filter set of 1,030 genes accepted as GA associated. -

ARTICLE Doi:10.1038/Nature10523
ARTICLE doi:10.1038/nature10523 Spatio-temporal transcriptome of the human brain Hyo Jung Kang1*, Yuka Imamura Kawasawa1*, Feng Cheng1*, Ying Zhu1*, Xuming Xu1*, Mingfeng Li1*, Andre´ M. M. Sousa1,2, Mihovil Pletikos1,3, Kyle A. Meyer1, Goran Sedmak1,3, Tobias Guennel4, Yurae Shin1, Matthew B. Johnson1,Zˇeljka Krsnik1, Simone Mayer1,5, Sofia Fertuzinhos1, Sheila Umlauf6, Steven N. Lisgo7, Alexander Vortmeyer8, Daniel R. Weinberger9, Shrikant Mane6, Thomas M. Hyde9,10, Anita Huttner8, Mark Reimers4, Joel E. Kleinman9 & Nenad Sˇestan1 Brain development and function depend on the precise regulation of gene expression. However, our understanding of the complexity and dynamics of the transcriptome of the human brain is incomplete. Here we report the generation and analysis of exon-level transcriptome and associated genotyping data, representing males and females of different ethnicities, from multiple brain regions and neocortical areas of developing and adult post-mortem human brains. We found that 86 per cent of the genes analysed were expressed, and that 90 per cent of these were differentially regulated at the whole-transcript or exon level across brain regions and/or time. The majority of these spatio-temporal differences were detected before birth, with subsequent increases in the similarity among regional transcriptomes. The transcriptome is organized into distinct co-expression networks, and shows sex-biased gene expression and exon usage. We also profiled trajectories of genes associated with neurobiological categories and diseases, and identified associations between single nucleotide polymorphisms and gene expression. This study provides a comprehensive data set on the human brain transcriptome and insights into the transcriptional foundations of human neurodevelopment. -
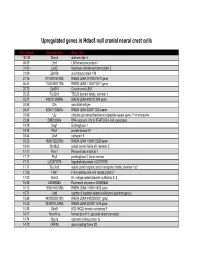
Supp Table 1.Pdf
Upregulated genes in Hdac8 null cranial neural crest cells fold change Gene Symbol Gene Title 134.39 Stmn4 stathmin-like 4 46.05 Lhx1 LIM homeobox protein 1 31.45 Lect2 leukocyte cell-derived chemotaxin 2 31.09 Zfp108 zinc finger protein 108 27.74 0710007G10Rik RIKEN cDNA 0710007G10 gene 26.31 1700019O17Rik RIKEN cDNA 1700019O17 gene 25.72 Cyb561 Cytochrome b-561 25.35 Tsc22d1 TSC22 domain family, member 1 25.27 4921513I08Rik RIKEN cDNA 4921513I08 gene 24.58 Ofa oncofetal antigen 24.47 B230112I24Rik RIKEN cDNA B230112I24 gene 23.86 Uty ubiquitously transcribed tetratricopeptide repeat gene, Y chromosome 22.84 D8Ertd268e DNA segment, Chr 8, ERATO Doi 268, expressed 19.78 Dag1 Dystroglycan 1 19.74 Pkn1 protein kinase N1 18.64 Cts8 cathepsin 8 18.23 1500012D20Rik RIKEN cDNA 1500012D20 gene 18.09 Slc43a2 solute carrier family 43, member 2 17.17 Pcm1 Pericentriolar material 1 17.17 Prg2 proteoglycan 2, bone marrow 17.11 LOC671579 hypothetical protein LOC671579 17.11 Slco1a5 solute carrier organic anion transporter family, member 1a5 17.02 Fbxl7 F-box and leucine-rich repeat protein 7 17.02 Kcns2 K+ voltage-gated channel, subfamily S, 2 16.93 AW493845 Expressed sequence AW493845 16.12 1600014K23Rik RIKEN cDNA 1600014K23 gene 15.71 Cst8 cystatin 8 (cystatin-related epididymal spermatogenic) 15.68 4922502D21Rik RIKEN cDNA 4922502D21 gene 15.32 2810011L19Rik RIKEN cDNA 2810011L19 gene 15.08 Btbd9 BTB (POZ) domain containing 9 14.77 Hoxa11os homeo box A11, opposite strand transcript 14.74 Obp1a odorant binding protein Ia 14.72 ORF28 open reading -

Integrating Single-Step GWAS and Bipartite Networks Reconstruction Provides Novel Insights Into Yearling Weight and Carcass Traits in Hanwoo Beef Cattle
animals Article Integrating Single-Step GWAS and Bipartite Networks Reconstruction Provides Novel Insights into Yearling Weight and Carcass Traits in Hanwoo Beef Cattle Masoumeh Naserkheil 1 , Abolfazl Bahrami 1 , Deukhwan Lee 2,* and Hossein Mehrban 3 1 Department of Animal Science, University College of Agriculture and Natural Resources, University of Tehran, Karaj 77871-31587, Iran; [email protected] (M.N.); [email protected] (A.B.) 2 Department of Animal Life and Environment Sciences, Hankyong National University, Jungang-ro 327, Anseong-si, Gyeonggi-do 17579, Korea 3 Department of Animal Science, Shahrekord University, Shahrekord 88186-34141, Iran; [email protected] * Correspondence: [email protected]; Tel.: +82-31-670-5091 Received: 25 August 2020; Accepted: 6 October 2020; Published: 9 October 2020 Simple Summary: Hanwoo is an indigenous cattle breed in Korea and popular for meat production owing to its rapid growth and high-quality meat. Its yearling weight and carcass traits (backfat thickness, carcass weight, eye muscle area, and marbling score) are economically important for the selection of young and proven bulls. In recent decades, the advent of high throughput genotyping technologies has made it possible to perform genome-wide association studies (GWAS) for the detection of genomic regions associated with traits of economic interest in different species. In this study, we conducted a weighted single-step genome-wide association study which combines all genotypes, phenotypes and pedigree data in one step (ssGBLUP). It allows for the use of all SNPs simultaneously along with all phenotypes from genotyped and ungenotyped animals. Our results revealed 33 relevant genomic regions related to the traits of interest. -

Rabbit Anti-ANKRD11/FITC Conjugated Antibody-SL16651R
SunLong Biotech Co.,LTD Tel: 0086-571- 56623320 Fax:0086-571- 56623318 E-mail:[email protected] www.sunlongbiotech.com Rabbit Anti-ANKRD11/FITC Conjugated antibody SL16651R-FITC Product Name: Anti-ANKRD11/FITC Chinese Name: FITC标记的锚蛋白重复结构域蛋白11抗体 ANCO 1; ANCO1; Ankyrin repeat containing cofactor 1; Ankyrin repeat domain 11; Alias: Ankyrin repeat domain containing protein 11; LZ16; T13; ANR11_HUMAN; Ankyrin repeat domain-containing protein 11; Ankyrin repeat-containing cofactor 1. Organism Species: Rabbit Clonality: Polyclonal React Species: ICC=1:50-200IF=1:50-200 Applications: not yet tested in other applications. optimal dilutions/concentrations should be determined by the end user. Molecular weight: 296kDa Form: Lyophilized or Liquid Concentration: 2mg/1ml immunogen: KLH conjugated synthetic peptide derived from human ANKRD11 Lsotype: IgG Purification: affinity purified by Protein A Storage Buffer: 0.01Mwww.sunlongbiotech.com TBS(pH7.4) with 1% BSA, 0.03% Proclin300 and 50% Glycerol. Store at -20 °C for one year. Avoid repeated freeze/thaw cycles. The lyophilized antibody is stable at room temperature for at least one month and for greater than a year Storage: when kept at -20°C. When reconstituted in sterile pH 7.4 0.01M PBS or diluent of antibody the antibody is stable for at least two weeks at 2-4 °C. background: Ankyrin is a membrane protein that mediates the attachment of the erythrocyte membrane skeleton to the plasma membrane and interacts with CD44 and inositol triphosphate. It contains three functional domains: a conserved N-terminal ankyrin Product Detail: repeat domain (ARD(consisting of 22–24 tandem repeats of 33 amino acids), a spectrin binding domain and a variably sized C-terminal regulatory domain. -

CRL4-DCAF12 Ubiquitin Ligase Controls MOV10 RNA Helicase During Spermatogenesis and T Cell Activation
International Journal of Molecular Sciences Article CRL4-DCAF12 Ubiquitin Ligase Controls MOV10 RNA Helicase during Spermatogenesis and T Cell Activation Tomas Lidak 1,2, Nikol Baloghova 1, Vladimir Korinek 1,3 , Radislav Sedlacek 4, Jana Balounova 4 , Petr Kasparek 4 and Lukas Cermak 1,* 1 Laboratory of Cancer Biology, Institute of Molecular Genetics of the Czech Academy of Sciences, 252 42 Vestec, Czech Republic; [email protected] (T.L.); [email protected] (N.B.); [email protected] (V.K.) 2 Faculty of Science, Charles University, 128 00 Prague, Czech Republic 3 Laboratory of Cell and Developmental Biology, Institute of Molecular Genetics of the Czech Academy of Sciences, 252 42 Vestec, Czech Republic 4 Czech Centre for Phenogenomics, Institute of Molecular Genetics of the Czech Academy of Sciences, 252 50 Vestec, Czech Republic; [email protected] (R.S.); [email protected] (J.B.); [email protected] (P.K.) * Correspondence: [email protected] Abstract: Multisubunit cullin-RING ubiquitin ligase 4 (CRL4)-DCAF12 recognizes the C-terminal degron containing acidic amino acid residues. However, its physiological roles and substrates are largely unknown. Purification of CRL4-DCAF12 complexes revealed a wide range of potential substrates, including MOV10, an “ancient” RNA-induced silencing complex (RISC) complex RNA helicase. We show that DCAF12 controls the MOV10 protein level via its C-terminal motif in a Citation: Lidak, T.; Baloghova, N.; proteasome- and CRL-dependent manner. Next, we generated Dcaf12 knockout mice and demon- Korinek, V.; Sedlacek, R.; Balounova, strated that the DCAF12-mediated degradation of MOV10 is conserved in mice and humans. -

'Next- Generation' Sequencing Data Analysis
Novel Algorithm Development for ‘Next- Generation’ Sequencing Data Analysis Agne Antanaviciute Submitted in accordance with the requirements for the degree of Doctor of Philosophy University of Leeds School of Medicine Leeds Institute of Biomedical and Clinical Sciences 12/2017 ii The candidate confirms that the work submitted is her own, except where work which has formed part of jointly-authored publications has been included. The contribution of the candidate and the other authors to this work has been explicitly given within the thesis where reference has been made to the work of others. This copy has been supplied on the understanding that it is copyright material and that no quotation from the thesis may be published without proper acknowledgement ©2017 The University of Leeds and Agne Antanaviciute The right of Agne Antanaviciute to be identified as Author of this work has been asserted by her in accordance with the Copyright, Designs and Patents Act 1988. Acknowledgements I would like to thank all the people who have contributed to this work. First and foremost, my supervisors Dr Ian Carr, Professor David Bonthron and Dr Christopher Watson, who have provided guidance, support and motivation. I could not have asked for a better supervisory team. I would also like to thank my collaborators Dr Belinda Baquero and Professor Adrian Whitehouse for opening new, interesting research avenues. A special thanks to Dr Belinda Baquero for all the hard wet lab work without which at least half of this thesis would not exist. Thanks to everyone at the NGS Facility – Carolina Lascelles, Catherine Daley, Sally Harrison, Ummey Hany and Laura Crinnion – for the generation of NGS data used in this work and creating a supportive and stimulating work environment. -

Supp Material.Pdf
Simon et al. Supplementary information: Table of contents p.1 Supplementary material and methods p.2-4 • PoIy(I)-poly(C) Treatment • Flow Cytometry and Immunohistochemistry • Western Blotting • Quantitative RT-PCR • Fluorescence In Situ Hybridization • RNA-Seq • Exome capture • Sequencing Supplementary Figures and Tables Suppl. items Description pages Figure 1 Inactivation of Ezh2 affects normal thymocyte development 5 Figure 2 Ezh2 mouse leukemias express cell surface T cell receptor 6 Figure 3 Expression of EZH2 and Hox genes in T-ALL 7 Figure 4 Additional mutation et deletion of chromatin modifiers in T-ALL 8 Figure 5 PRC2 expression and activity in human lymphoproliferative disease 9 Figure 6 PRC2 regulatory network (String analysis) 10 Table 1 Primers and probes for detection of PRC2 genes 11 Table 2 Patient and T-ALL characteristics 12 Table 3 Statistics of RNA and DNA sequencing 13 Table 4 Mutations found in human T-ALLs (see Fig. 3D and Suppl. Fig. 4) 14 Table 5 SNP populations in analyzed human T-ALL samples 15 Table 6 List of altered genes in T-ALL for DAVID analysis 20 Table 7 List of David functional clusters 31 Table 8 List of acquired SNP tested in normal non leukemic DNA 32 1 Simon et al. Supplementary Material and Methods PoIy(I)-poly(C) Treatment. pIpC (GE Healthcare Lifesciences) was dissolved in endotoxin-free D-PBS (Gibco) at a concentration of 2 mg/ml. Mice received four consecutive injections of 150 μg pIpC every other day. The day of the last pIpC injection was designated as day 0 of experiment.