SMP Node Architecture
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Summer HP Desktop Datasheet
HP Pavilion t3449.uk PC ● Genuine Windows XP Home Edition ● Intel® Pentium® D Processor 820 Dual core ● 1 GB DDR2-SDRAM ● 160 GB Serial ATA hard drive (7200 rpm) ● ATI Radeon XPRESS 200 Graphics Up to 256 MB shared video memory ● DVD writer Double Layer ±R/ ±RW 16x/8x max supporting LightScribe technology ● 10/100BT network interface ● IEEE 1394 FireWire® Interface ● 9in1 memory card reader HP recommends Microsoft® Windows® XP Professional Create silkscreen-quality disc labels direct from your PC with LightScribe: Just burn, flip, burn. HP Pavilion t3449.uk PC HP recommends Microsoft® Windows® XP Professional Operating system Genuine Windows XP Home Edition Internet & Online Easy Internet Signup with leading Internet Service Providers Processor Intel® Pentium® D Processor 820 Dual core 2 x 2.80 GHz Level 2 cache 2 x 1 MB 800 MHz bus Service & Support HP Pavilion on-line user's guide, HP Help, HP Pavilion speed recovery partition (including possibility to recover system, ATI RADEON® XPRESS 200 Chipset applications and drivers separately) Optional re-allocation of recovery partition Memory 1 GB DDR2-SDRAM Recovery CD/DVD creation tool 2 DIMM sockets Symantec™ Norton Internet Security™ 2006 (60 days live Storage 160 GB Serial ATA hard drive (7200 rpm) update) incl. 6 GB partition for system recovery DVD writer Double Layer ±R/ ±RW 16x/8x max supporting LightScribe technology Create silkscreen-quality disc labels direct from your PC with LightScribe: Just burn, flip, burn. 9in1 memory card reader Communication High speed 56K modem 10/100BT -

BIOS EPOX, Motherboard 4PCA HT ======Change Optimized Defaults Are Marked !!! Změny Oproti DEFAULT Jsou Označeny !!! ======
BIOS EPOX, motherboard 4PCA HT =================================================== Change Optimized Defaults are marked !!! Změny oproti DEFAULT jsou označeny !!! =================================================== Standard CMOS Features ====================== Halt On [All, But Keyboard] !!! Advanced BIOS Features ====================== CPU Feature-Delay Prior to Termal [16 Min] Limit CPUID MaxVal [Disabled] Hard Disk Boot Priority Bootovani disku CPU L1 & L2 Cache [Enabled] Hyper-Threading Technology [Enabled] !!! First Boot Device [HDD] !!! Second Boot Device [Disabled] !!! Third Boot Device [Disabled] !!! Boot Other Device [Disabled] !!! Boot Up Floppy Seek [Disabled] !!! Boot Up NumLock Status [On] Security Option [Setup] x APIC Mode (zasedle) [Enabled] HDD S.M.A.R.T .... [Disabled] Advanced Chipset Features ========================= DRAM Timing Selectable [By SPD] x x x x Agresive Memory Mode [Standard] x x x System BIOS Cacheable [Enabled] VIDEO BIOS Cacheable [Disabled] AGP Aperture ... [128] Init Display First [AGP] DRAM DATA Inregrity Mode [ECC] Integrated Peripherals ====================== On Chip IDE Device: IDE HDD [Enabled] IDE DMA [Enabled] On-Chip Primary [Enabled] IDE Primary MASTER PIO [Auto] ... [Auto] On-Chip Secondary [Enabled] IDE Secondary MASTER PIO[Auto] ... [Auto] On Chip Serial ATA [Disabled] (ostatni sede) OnBoard Device: USB Controller [Enabled] USB 2.0 [Enabled] USB Keyboard [Auto] USB Mouse [Disabled] !!! AC97 Audio [Disabled] !!! Game Port [Disabled] !!! Midi Port [Disabled] !!! On Board LAN Device [Enabled] -

Product Line Card
Product Line Card ® CABLES Lenovo KEYBOARDS & NAS/SAN POWER SOLID STATE Accell MSI MICE D-Link PROTECTION/UPS DRIVES APC Cables by BAFO Shuttle Adesso Intel APC ADATA Link Depot ViewSonic Alaska Promise Opti-UPS Corsair StarTech.com ZOTAC Azio QNAP Tripp Lite Crucial SYBA Cooler Master SansDigital Intel EXTERNAL Corsair Synology POWER Kingston CASES ENCLOSURES Genius Thecus SUPPLIES OCZ AIC AcomData KeyTronic WD Antec PNY Antec Cremax Lenovo Apex Samsung Apex Eagle Tech Logitech NETWORKING Cooler Master WD CHENBRO iStarUSA Microsoft ASUS Corsair Compucase SIIG Razer Cisco Epower SURVEILLANCE Cooler Master Smarti SIIG D-Link FSP PRODUCTS Corsair StarTech.com Thermaltake Edimax In Win AVer Intel TRENDnet Emulex Intel D-Link In Win Vantec MEMORY Encore Electronics iStarUSA TP-LINK iStarUSA Zalman ADATA EnGenius Nspire TRENDnet Lian Li AMD Huawei Seasonic Vivotek Nspire FANS/HEATSINKS Corsair Intel Sentey Vonnic NZXT Antec Crucial Keebox Shuttle Zmodo Sentey Cooler Master Kingston NETGEAR Sparkle Power Edimax Supermicro Corsair Patriot SIIG Thermaltake Keebox Thermaltake Dynatron Samsung StarTech.com Zalman Winsis USA Enermax SYBA TABLETS Zalman Intel MONITORS TP-LINK PROJECTORS ASUS Noctua AOC TRENDnet ASUS GIGABYTE CONTROLLER StarTech.com ASUS Tripp Lite ViewSonic Lenovo CARDS Supermicro Hanns.G ZyXEL ViewSonic 3Ware Thermaltake Lenovo SERVERS HighPoint Vantec LG Electronics NOTEBOOKS/ AIC USB DRIVES Intel Zalman Planar NETBOOKS ASUS ADATA LSI ViewSonic ASI ASI Corsair Microwise HARD DRIVES ASUS Intel Kingston Promise ADATA MOTHERBOARDS -
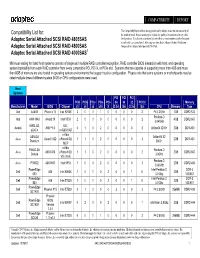
Compatibility List For: Adaptec Serial Attached SCSI RAID 4805SAS Adaptec Serial Attached SCSI RAID 4800SAS Adaptec Serial Atta
COMPATIBILITY REPORT This Compatibility Report reflects testing performed by Adaptec to test the interoperability of Compatibility List for: the products listed. It does not attempt to validate the quality of or preference for any of the Adaptec Serial Attached SCSI RAID 4805SAS listed products. It is also not an inclusive list and reflects a representative sample of products in each of the categories listed. All testing was done by the Adaptec Product Verification Adaptec Serial Attached SCSI RAID 4800SAS Group and the Adaptec InterOperability Test Lab. Adaptec Serial Attached SCSI RAID 4000SAS1 Minimum testing for listed host systems consists of single and multiple RAID controller recognition, RAID controller BIOS interaction with host, and operating system bootability from each RAID controller from every compatible PCI, PCI-X, or PCIe slot. Systems that are capable of supporting more than 4GB and more then 8GB of memory are also tested in operating system environments that support such a configuration. Please note that some systems or motherboards may be listed multiple times if different system BIOS or CPU configurations were used. Host Systems PCI PCI PCI PCIe PCIe PCIe PCIe PCI- 64 64 32 PCI 32 Memory Manufacturer Model BIOS Chipset x1 x4 x8 x16 X (3.3v) (5v) (3.3v) (5v) CPU Memory Type Abit AA8XE Phoenix 16 Intel 925XE 3 0 0 1 0 0 0 0 2 P4 3.2GHz 1GB DDR2-533 Pentium-D Abit AW8-MAX Award 19 Intel 955X 2 0 0 0 0 0 0 0 2 4GB DDR2-667 3.04GHz 939SLI32- ULI - Asrock AMI P1.0 0 1 0 2 0 0 0 0 3 Athlon64 3200+ 2GB DDR-400 eSATA m1695/1697 -

The Pentium Processor
CompTIA® A+ Exam Prep (Exams A+ Essentials, 220-602, 220-603, 220-604) Associate Publisher Copyright © 2008 by Pearson Education, Inc. David Dusthimer All rights reserved. No part of this book shall be reproduced, stored in a retrieval system, or trans- mitted by any means, electronic, mechanical, photocopying, recording, or otherwise, without writ- Acquisitions Editor ten permission from the publisher. No patent liability is assumed with respect to the use of the David Dusthimer information contained herein. Although every precaution has been taken in the preparation of this book, the publisher and authors assume no responsibility for errors or omissions. Nor is any liabili- Development Editor ty assumed for damages resulting from the use of the information contained herein. Box Twelve ISBN-13: 978-0-7897-3565-2 Communications, Inc. ISBN-10: 0-7897-3565-2 Library of Congress Cataloging-in-Publication Data Managing Editor Patrick Kanouse Brooks, Charles J. CompTIA A+ exam prep (exams A+ essentials, 220-602, 220-603, 220-604) Project Editor / Charles J. Brooks, David L. Prowse. Mandie Frank p. cm. Copy Editor Includes index. Barbara Hacha ISBN 978-0-7897-3565-2 (pbk. w/cd) 1. Electronic data processing personnel--Certification. 2. Computer Indexer technicians--Certification--Study guides. 3. Tim Wright Microcomputers--Maintenance and repair--Examinations--Study guides. I. Prowse, David L. II. Title. Proofreader QA76.3.B7762 2008 Water Crest Publishing 004.165--dc22 Technical Editors 2008009019 David L. Prowse Printed in the United States of America Tami Day-Orsatti First Printing: April 2008 Trademarks Publishing Coordinator All terms mentioned in this book that are known to be trademarks or service marks have been Vanessa Evans appropriately capitalized. -

Technology Features
TECHNOLOGY FEATURES CPU INTERFACE • Anti-Aliasing using multi-sampling algorithm with EXTERNAL DISPLAY SUPPORT • AMD Sempron™, AMD Athlon™ 64 and AMD support for 2,4, and 6 samples (Available in RADEON® XPRESS 200 only) Athlon™ 64 FX processors • Hidden surface removal using 16, 24, • Supports external displays (e.g. flat panel, CRT, or • 800MHz and 1GHz HyperTransport interface speeds or 32-bit Z-Buffering TV) via a DVO port • Dynamic link width and frequency change 2D GRAPHICS • Supports DVI, DFP, and VESA P&D digital interfaces • Supports Advanced Power Management with a (Available in RADEON® XPRESS 200 only) • Support for fixed resolution displays from VGA LDTSTP Interface, CPU Throttling, and Stutter • Highly optimized 128-bit engine capable of (640x480) to wide UXGA (1600x1200) Mode capability processing multiple pixels per clock POWER MANAGEMENT FEATURES MEMORY INTERFACE • Game acceleration including support for • Fully supports ACPI states S1, S3, S4, and S5 Microsoft’s DirectDraw, Double Buffering, Virtual • UMA mode operation requires no external memory • Support for AMD Cool‘n’Quiet™ technology to Sprites, Transparent Blit, and Masked Blit. • HYPERMEMORY™ technology offers optional conserve power • Supports a maximum resolution of dedicated Local Frame Buffer configuration 2048x1536@32bpp for a 32-bit or 64-bit interface and up to OPTIMIZED SOFTWARE SUPPORT ® 128MB of memory • Support for new GDI extensions in Windows 2000 • ATI Catalyst driver update support ® and Windows XP:Alpha BLT, Transparent BLT, ® ® ® • GDDR and DDR -

2005 Ranking Results
2005 Information Transparency and Disclosure Ranking Results in Taiwan Conducted by Securities and Futures Institute Entrusted by Taiwan Stock Exchange Corporation & GreTai Securities Market Despite all reasonable care given in the screening process to ensure objectivity, the SFI bears no responsibility in case of any damage or loss incurred from use of the ranking results. June 8, 2006 2005 Information Transparency and Disclosure Ranking Results in Taiwan About “Information Disclosure and Transparency Ranking System” The recent media focus on corporate governance has prompted calls for greater transparency and disclosure on companies around the globe. As a result, several leading financial-information providers have launched disclosure rankings, evaluations, and research related to how companies disclose information to rely on market force and mechanisms to encourage voluntary disclosures of companies. However, the evaluation criteria selected by those rankings, to some degree, could not provide an overall evaluation of disclosure practices in local market. In additions, there have been calls for standard setters and regulators to expand disclosure requirements according to international standards. Therefore, the Securities and Futures Institute (“SFI”), entrusted by the Taiwan Stock Exchange Corporation (“TSEC”) and the Gre Tai Securities Market (“GTSM”), currently launched “Information Transparency and Disclosure Rankings System”(ITDRS) to evaluate the level of transparency for all listed companies in Taiwan since 2003. For the third time, the 2005 full-year ranking results were released on June 8, 2006. It’s the first time that the full ranking results released. In the 1,032 listed companies of TSEC and GTSM, 12 companies were ranked as “Grade A+”, 183 companies were ranked as “Grade A”, 583 companies were ranked as “Grade B”, and 254 companies were ranked as “Grade C”. -
Product Line Card
Product Line Card 3Com Corporation ATI Technologies Distribution CCT Technologies 3M Attachmate Corporation Century Software 4What, Inc. Autodesk, Inc. Certance 4XEM Avaya, Inc. Certance LLC Averatec America, Inc. Chanx Absolute Software Avocent Huntsville Corp. Check Point Software ACCPAC International, Inc. Axis Communications, Inc. Cherry Electrical Products Acer America Corporation Chicony Adaptec, Inc. Barracuda Networks Chief Manufacturing ADC Telecommunications Sales Battery Technology, Inc. Chili Systems Addmaster Bay Area Labels Cingular Interactive, L.P. Adesso Bay Press & Packing Cisco Systems, Inc. Adobe Systems, Inc. Belkin Corporation CMS Products, Inc. Adtran Bell & Howell CNET Technology, Inc. Advanced Digital Information BenQ America Corporation Codi Advanced Micro Devices, Inc. Best Case & Accessories Comdial AEB Technologies Best Software SB, Inc. Computer Associates Aegis Micro/Formosa– USA Bionic CCTV ComputerLand AI Coach Bionic Video Comtrol Corporation Alcatel Internetworking, Inc. Black Box Connect Tech All American Semi Block Financial Corel Corporation Allied Telesyn BorderWare Corporate Procurement Altec Lansing Technologies, Inc. Borland Software Corporation Corsair Althon Micro Boundless Technologies, Inc. Corsair Altigen Brady Worldwide Countertrade Products Alvarion, Inc. Brands, Inc. Craden AMCC Sales Corp. Brenthaven Creative Labs, Inc. AMD Bretford Manufacturing, Inc. CRU-Dataport American Portwell Technology Brooktrout Technology, Inc. CryptoCard American Power Conversion Brother International Corporation CTX Anova Microsystems Buffalo Technology/Melco Curtis Young Corporation Antec, Inc. Business Objects Americas AOpen America, Inc. BYTECC Dantz Development Corp. APC Data911 Arco Computer Products, LLC Cables To Go, Inc. Datago Ardence Cables Unlimited Dataram Areca. US Caldera Systems, Inc. Datawatch Corporation Arima Computer Cambridge Soundworks Decision Support Systems Artronix Canon USA Inc. Dedicated Micros Aspen Touch Solutions, Inc. Canton Electronics Corporation Dell Astra Data, Inc. -

HP Commercial PC Datasheet
HP dx5150 Business Desktop PC HP recommends Microsoft® Windows® XP Professional The HP dx5150 Business Desktop PC delivers Enhanced security features high-performance computing to businesses requiring The HP dx5150 features AMD Enhanced Virus investment protection and security. This versatile PC is Protection technology, which used with Windows XP packed with advanced features to suit a broad range SP2 provides business data security against a number of business environments and is also simple to service of dangerous viruses. HP Protect Tools Embedded and expand to meet specific user needs. Security is a hardware/software solution that provides High-performance business desktop platform authentication, cryptographic functions and At the heart of the HP dx5150 are the award-winning data transmission verification. Physical security AMD Athlon™ 64 and Sempron™ processors, features include a security loop and Kensington lock designed to handle the most challenging business support, which allow the PC to be secured to a fixed applications. Combining an ATI RADEON® XPRESS structure. 200 chipset, Broadcom NetXtreme Gigabit NIC, dual Simple to upgrade and service monitor capability, and a wide range of additional The expandable chassis is designed to fit neatly into features, the dx5150 delivers the performance any workspace and features tool-less covers and drives required of the most demanding user. enabling quick and easy access for upgrades and Increased investment protection general service. The HP dx5150 is backed by a New technologies found on the latest AMD processors one-year warranty with award-winning HP Service and help increase productivity and reduce ownership costs. Support as standard to ensure maximum productivity The AMD Athlon 64 processor is fully compatible with and return on investment. -

CHAPTER 4 Motherboards and Buses 05 0789729741 Ch04 7/15/03 4:03 PM Page 196
05 0789729741 ch04 7/15/03 4:03 PM Page 195 CHAPTER 4 Motherboards and Buses 05 0789729741 ch04 7/15/03 4:03 PM Page 196 196 Chapter 4 Motherboards and Buses Motherboard Form Factors Without a doubt, the most important component in a PC system is the main board or motherboard. Some companies refer to the motherboard as a system board or planar. The terms motherboard, main board, system board, and planar are interchangeable, although I prefer the motherboard designation. This chapter examines the various types of motherboards available and those components typically contained on the motherboard and motherboard interface connectors. Several common form factors are used for PC motherboards. The form factor refers to the physical dimensions (size and shape) as well as certain connector, screw hole, and other positions that dictate into which type of case the board will fit. Some are true standards (meaning that all boards with that form factor are interchangeable), whereas others are not standardized enough to allow for inter- changeability. Unfortunately, these nonstandard form factors preclude any easy upgrade or inexpen- sive replacement, which generally means they should be avoided. The more commonly known PC motherboard form factors include the following: Obsolete Form Factors Modern Form Factors All Others ■ Baby-AT ■ ATX ■ Fully proprietary designs ■ Full-size AT ■ micro-ATX (certain Compaq, Packard Bell, Hewlett-Packard, ■ ■ LPX (semiproprietary) Flex-ATX notebook/portable sys- ■ WTX (no longer in production) ■ Mini-ITX (flex-ATX tems, and so on) ■ ITX (flex-ATX variation, never variation) produced) ■ NLX Motherboards have evolved over the years from the original Baby-AT form factor boards used in the original IBM PC and XT to the current ATX and NLX boards used in most full-size desktop and tower systems. -

AMD Reports Fourth Quarter and Annual 2019 Financial Results
January 28, 2020 AMD Reports Fourth Quarter and Annual 2019 Financial Results – Record quarterly revenue of $2.13 billion; record annual revenue of $6.73 billion – – Gross margin expanded to 45 percent in Q4 2019 and 43 percent for 2019 – SANTA CLARA, Calif., Jan. 28, 2020 (GLOBE NEWSWIRE) -- AMD (NASDAQ:AMD) today announced revenue for the fourth quarter of 2019 of $2.13 billion, operating income of $348 million, net income of $170 million and diluted earnings per share of $0.15. On a non- GAAP(*) basis, operating income was $405 million, net income was $383 million and diluted earnings per share was $0.32. For fiscal year 2019, the company reported revenue of $6.73 billion, operating income of $631 million, net income of $341 million and diluted earnings per share of $0.30. On a non- GAAP(*) basis, operating income was $840 million, net income was $756 million and diluted earnings per share was $0.64. GAAP Quarterly Financial Results Q4 2019 Q4 2018 Y/Y Q3 2019 Q/Q Revenue ($B) $ 2.13 $ 1.42 Up 50% $ 1.80 Up 18% Gross margin 45 % 38 % Up 7pp 43 % Up 2pp Operating expense ($M) $ 601 $ 509 Up $92 $ 591 Up $10 Operating income ($M) $ 348 $ 28 Up $320 $ 186 Up $162 Net income ($M) $ 170 $ 38 Up $132 $ 120 Up $50 Earnings per share $ 0.15 $ 0.04 Up $0.11 $ 0.11 Up $0.04 Non-GAAP(*) Quarterly Financial Results Q4 2019 Q4 2018 Y/Y Q3 2019 Q/Q Revenue ($B) $ 2.13 $ 1.42 Up 50% $ 1.80 Up 18% Gross margin 45 % 41 % Up 4pp 43 % Up 2pp Operating expense ($M) $ 545 $ 474 Up $71 $ 539 Up $6 Operating income ($M) $ 405 $ 109 Up $296 $ 240 Up $165 Net -

Integrator ® NV Series Hybrid Windows Capture Cards
Integrator ® NV Series www.avermedia-usa.com/surveillance Hybrid Windows Capture Cards www.averusa.com/surveillance RNV3000ECOMMENDATIONS Hardware Recommendation List Motherboard System Requirements: Our products support most of the current Intel chipsets for motherboards. Intel • CPU: Pentium 4 3.0 GHz or higher 848, 865, 875, 915, 925, 945, 955, 965, P35, NVIDIA nFORCE4 SLI - Intel Edition, • OS: Windows 7/XP/Vista/2000 - 32 bit NVIDIA nForce3 250Gb Platform Processor chipsets • RAM: 512MB or higher • HDD: 120GB or higher Below is a list of Motherboards that our validation labs have tested; however we • CD-RM/DVD-RM do support other motherboards beyond the ones listed below • Graphic Card: 32-bit high color SVGA Intel Socket graphics card with 128MB video Brand Asus Gigabyte Epox Intel FOXCONN MSI memory and DirectDraw/YUV 848 P4P800 SE Rendering Capability P4P800 GA-8IPE1000 P4P800-VM GA-8IG1000Pro-G • 10/100 Base-T Ethernet card 865 P4P8X GA-8IPE1000-G (Rev 3.1) • Sound card and speaker P5P800 P4C800 GA-8IK1100 875P Neo FISR 875 GA-8I875 915 P5GD1 Pro GA-8I915G-Duo EP-5EPA+ 915G Combo 925 P5AD2 Premium D925XCV 915G Combo P5LD2 GA-8I945P-G P5LD2-VM GA-8I 945G -MF 945 P5PL2-E GA-945PL-S3 (Rev 2.0) GA-8I945PL-G GA-8I955X Pro Note: 955 GA-8I955X Royal Based on Intel’s suggestion, for all of Microsoft P5B Deluxe/ GA-965P-DS3P (Rev 3.3) Windows XP Operating Systems, Hyper-Threading must 965 WiFi-AP GA-965P-DS3 2.0 be disabled in the system BIOS Setup program for our 975 GA-G1975X-C DVR products.