CABA White Paper on Project Haystack.Pdf
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

AIT Presentation
Distributed Sensors & Connectivity as the answer to future grid requirements Karl-Heinz Mayer Director Engineering Innovation & Program Management AIT Industry Day – September 11th, 2015 © 2015 Eaton Corporation. All rights reserved. Power business – status quo • Electricity is still the backbone and driver of mankind‘s productivity – this seems not to be changed soon 2 © 2015 Eaton Corporation. All rights reserved. 2 Power business – status quo • Electricity is still the backbone and driver of mankind‘s productivity – this seems not to be changed soon • Climate changes are requesting less CO2 emission despite the worldwide increase of power demand Green Energy; programs for ISO 50001, LEED,…certifications 3 © 2015 Eaton Corporation. All rights reserved. 3 Power business – status quo • Electricity is still the backbone and driver of mankind‘s productivity – this seems not to be changed soon • Climate changes are requesting less CO2 emission despite the worldwide increase of power demand Green Energy; programs for ISO 50001, LEED,…certifications • Consumer – Prosumer transformation requests new system approaches Virtual power plants 4 © 2015 Eaton Corporation. All rights reserved. 4 Technology trends are lowering the hurdles to develop and connect more intelligent devices • Semiconductor component costs continue to decline • Functionality and power management performance improving • Pervasiveness of communications increasing • Cloud services and development tools are being used more and more…and their costs are dropping dramatically with scale 5 © 2015 Eaton Corporation. All rights reserved. 5 Future challenges 1. Growing Electricity 2. Electricity Peak 3. Increasing Variable 4. Increasing Demand & Ageing Management Energy Generation Integration of Electric Infrastruture Vehicle World Energy Consumption by fuel type, 1990-2040 - Source : EIA (2013) 6 © 2015 Eaton Corporation. -

Evaluation of Alternative Field Buses for Lighting Control Applications
Evaluation of Alternative Field Buses for Lighting Control Applications Prepared By: Ed Koch, Akua Controls Edited By: Francis Rubinstein, Lawrence Berkeley National Laboratory Prepared For: Broadata Communications Torrence, CA March 21, 2005 Table of Contents Introduction......................................................................................................................... 3 Purpose ................................................................................................................................. 3 Statement of Work ................................................................................................................ 3 1-Wire Net .......................................................................................................................... 4 Introduction and Background................................................................................................ 4 Technical Specifications......................................................................................................... 5 Description of Technology........................................................................................ 5 Practical Considerations .......................................................................................... 7 Available Devices ...................................................................................................... 7 Standards and Trade Organizations .................................................................................... 11 Companies.......................................................................................................................... -
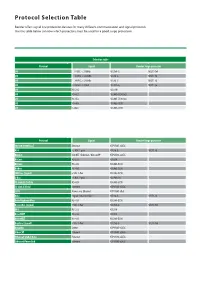
Protocol Selection Table
Protocol Selection Table Bender offers signal line protection devices for many different communication and signal protocols. Use the table below to know which protectors must be used for a good surge protection. Selection table Protocol Signal Bender Surge protector I/O ± 5 VDC, < 250kHz NSL7v5-G NSLT1-7v5 I/O ± 12 VDC, < 250kHz NSL18-G NSLT1-18 I/O ± 24 VDC, < 250kHz NSL36-G NSLT1-36 I/O 0-20mA / 4-20mA NSL420-G NSLT1-36 I/O RS-232 NSL-DH I/O RS-422 NSL485-EC90 (x2) I/O RS-452 NSL485-EC90 (x2) I/O RS-485 NSL485-EC90 I/O 1-Wire NSL485-EC90 Protocol Signal Bender Surge protector 10/100/1000BaseT Ethernet NTP-RJ45-xCAT6 AS-i 32 VDC 1-pair NSL36-G NSLT1-36 BACnet ARCNET / Ethernet / BACnet/IP NTP-RJ45-xCAT6 BACnet RS-232 NSL-DH BACnet RS-485 NSL485-EC90 BitBus RS-485 NSL485-EC90 CAN Bus (Signal) 5 VDC 1-Pair NSL485-EC90 C-Bus 36 VDC 1-pair NSSP6A-38 CC-Link/LT/Safety RS-485 NSL485-EC90 CC-Link IE Field Ethernet NTP-RJ45-xCAT6 CCTV Power over Ethernet NTP-RJ45-xPoE DALI Digital Serial Interface NSL36-G NSLT1-36 Data Highway/Plus RS-485 NSL485-EC90 DeviceNet (Signal) 5 VDC 1-Pair NSL7v5-G NSLT1-7v5 DF1 RS-232 NSL-DH DirectNET RS-232 NSL-DH DirectNET RS-485 NSL485-EC90 Dupline (Signal) 5 VDC 1-Pair NSL7v5-G NSLT1-7v5 Dynalite DyNet NTP-RJ45-xCAT6 EtherCAT Ethernet NTP-RJ45-xCAT6 Ethernet Global Data Ethernet NTP-RJ45-xCAT6 Ethernet Powerlink Ethernet NTP-RJ45-xCAT6 Protocol Signal Bender Surge protector FIP Bus RS-485 NSL485-EC90 FINS Ethernet NTP-RJ45-xCAT6 FINS RS-232 NSL-DH FINS DeviceNet (Signal) NSL7v5-G NSLT1-7v5 FOUNDATION Fieldbus H1 -

Broadata Communications Technology Report
Evaluation of Alternative Field Buses for Lighting Control Applications Prepared By: Ed Koch, Akua Controls Edited By: Francis Rubinstein, Lawrence Berkeley National Laboratory Prepared For: Broadata Communications Torrence, CA March 21, 2005 Table of Contents Introduction......................................................................................................................... 3 Purpose ................................................................................................................................. 3 Statement of Work ................................................................................................................ 3 1-Wire Net .......................................................................................................................... 4 Introduction and Background................................................................................................ 4 Technical Specifications......................................................................................................... 5 Description of Technology........................................................................................ 5 Practical Considerations .......................................................................................... 7 Available Devices ...................................................................................................... 7 Standards and Trade Organizations .................................................................................... 11 Companies.......................................................................................................................... -
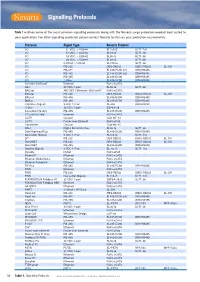
Signalling Protocols
Signalling Protocols Table 1 outlines some of the most common signalling protocols along with the Novaris surge protection product best suited to your application. For other signalling protocols please contact Novaris to discuss your protection requirements. Protocol Signal Type Novaris Product I/O ± 5 VDC, < 250kHz SL7v5-G SLT1-7v5 I/O ± 12 VDC, < 250kHz SL18-G SLT1-18 I/O ± 24 VDC, < 250kHz SL36-G SLT1-36 I/O ± 48 VDC, < 250kHz SL68-G SLT1-68 I/O 0-20mA / 4-20mA SL420-G SLT1-36 I/O RS-232 DB9-RS232 DB25-RS232 SL-DH I/O RS-422 SL485-EC90 (x2) DB9-RS485 I/O RS-452 SL485-EC90 (x2) DB9-RS485 I/O RS-485 SL485-EC90 DB9-RS485 I/O 1-Wire SL485-EC90 DB9-RS485 10/100/1000BaseT Ethernet RJ45-xCAT6 AS-i 32 VDC 1-pair SL36-G SLT1-36 BACnet ARCNET / Ethernet / BACnet/IP RJ45-xCAT6 BACnet RS-232 DB9-RS232 DB25-RS232 SL-DH BACnet RS-485 SL485-EC90 DB9-RS485 BitBus RS-485 SL485-EC90 DB9-RS485 CAN Bus (Signal) 5 VDC 1-Pair SL-DH DB9-RS232 C-Bus 36 VDC 1-pair SSP6A-38 CC-Link/LT/Safety RS-485 SL485-EC90 DB9-RS485 CC-Link IE Field Ethernet RJ45-xCAT6 CCTV Coaxial CLB-MF-10 CCTV Power over Ethernet RJ45-xPoE ControlNet Coaxial CLB-MF-10 DALI Digital Serial Interface SL36-G SLT1-36 Data Highway/Plus RS-485 SL485-EC90 DB9-RS485 DeviceNet (Signal) 5 VDC 1-Pair SL7v5-G SLT1-7v5 DF1 RS-232 DB9-RS232 DB25-RS232 SL-DH DirectNET RS-232 DB9-RS232 DB25-RS232 SL-DH DirectNET RS-485 SL485-EC90 DB9-RS485 Dupline (Signal) 5 VDC 1-Pair SL7v5-G SLT1-7v5 Dynalite DyNet RJ45-xPoE EtherCAT Ethernet RJ45-xCAT6 Ethernet Global Data Ethernet RJ45-xCAT6 Ethernet Powerlink Ethernet -

Overview of Building Automation Protocols
Considerations and challenges when integrating systems to achieve smart(er) buildings Lance Rütimann / SupDet 2015 / 04 March 2015 Unrestricted © Siemens AG 2015 All rights reserved. Integrating systems is not new … The technological development has advanced the dimension of integrations, both in quantitative and qualitative terms: . relay contacts . parallel data . serial data Cumulating events on one central point had its weaknesses. Unrestricted © Siemens AG 2015 All rights reserved. 04 March 2015 SupDet 2015 2 … but it has become more complex. And we continue to learn. Numbers of Protocols A protocol is a defined set of rules and regulations that determine how data is . 20+ Building Automation protocols transmitted in telecommunications . 35+ Process Automation protocols and computer networking . 4 Industrial Control System protocols . 4 Power System automation Source: http://en.wikipedia.org/wiki/List_of_automation_protocols Source: http://www.drillingcontractor.org/from-islands-to-clouds-the-data-evolution-10675 Distributed systems = increased redundancy Unrestricted © Siemens AG 2015 All rights reserved. 04 March 2015 SupDet 2015 3 Overview of Building Automation protocols 1. 1-Wire 14.Modbus (RTU or ASCII or TCP) 2. BACnet 15.oBIX 3. C-Bus 16.ONVIF 4. CC-Link Industrial Networks 17.VSCP 5. DALI 18.xAP 6. DSI 19.X10 7. Dynet 20.Z-Wave 8. EnOcean 21.ZigBee 9. HDL-Bus 10.INSTEON 11.IP500 12.KNX (previously AHB/EIB) 13.LonTalk Unrestricted © Siemens AG 2015 All rights reserved. 04 March 2015 SupDet 2015 4 Overview of Process Automation Protocols 1. AS-i 14.FINS 27.PieP 2. BSAP 15.FOUNDATION 28.Profibus 3. CC 16.HART 29.PROFINET IO 4. -

Interop Forum 2007 Paper WORD Template
Customer Energy Services Interface White Paper Version 1.0 Smart Grid Interoperability Panel B2G/I2G/H2G Domain Expert Working Groups Editor - Dave Hardin, EnerNOC, [email protected] Keywords: facility interface; ESI; SGIP; Smart Grid; (a.k.a. GWAC Stack)2 and NIST Framework and Roadmap standards for Smart Grid Interoperability Standards, Release 2.03. Abstract An ESI is a bi-directional, logical, abstract interface that The Energy Services Interface (ESI) is a concept that has supports the secure communication of information been identified and defined within a number of Smart Grid between internal entities (i.e., electrical loads, storage domains (e.g., NIST Conceptual Model1). Within these and generation) and external entities. It comprises the domains, an ESI performs a variety of functions. The devices and applications that provide secure interfaces purpose of this paper is to provide a common understanding between ESPs and customers for the purpose of and definition of the ESI at the customer boundary through facilitating machine-to-machine communications. ESIs a review of use case scenarios, requirements and functional meet the needs of today’s grid interaction models (e.g., characteristics. This paper then examines the information demand response, feed-in tariffs, renewable energy) and that needs to be communicated across the ESI, and looks at will meet those of tomorrow (e.g., retail market the standards that exist or are under development that touch transactions). the ESI. This is a general definition of an ESI as applied to the This white paper provides input to the Smart Grid customer boundary. Real implementations will have Interoperability Panel (SGIP) as well as international efforts variations arising from complex system inter-relationships: to understand grid interactions with the customer domain diverse customer business and usage models with different and the standards that govern those interactions. -

DESIGN and DEVELOPMENT of an INTERNET-OF-THINGS (Iot) GATEWAY for SMART BUILDING APPLICATIONS
DESIGN AND DEVELOPMENT OF AN INTERNET-OF-THINGS (IoT) GATEWAY FOR SMART BUILDING APPLICATIONS ADITYA NUGUR Thesis submitted to the faculty of the Virginia Polytechnic Institute and State University in partial fulfillment of the requirements for the degree of Master of Science In Electrical Engineering Saifur Rahman, Chair Manisa Pipattanasomporn Jaime De La Ree lopez 29th September, 2017 Arlington, VA Keywords: IoT, Smart Buildings, IoT Gateway, Building Energy Management DESIGN AND DEVELOPMENT OF AN INTERNET-OF-THINGS (IoT) GATEWAY FOR SMART BUILDING APPLICATIONS ADITYA NUGUR ABSTRACT With growing concerns about global energy demand and climate change, it is important to focus on efficient utilization of electricity in commercial buildings, which contribute significantly to the overall electricity consumption. Accordingly, there has been a number of Building Energy Management (BEM) software/hardware solutions to monitor energy consumption and other measurements of individual building loads. BEM software serves as a platform to implement smart control strategies and stores historical data. Although BEM software provides such lucrative benefits to building operators, in terms of energy savings and personalized control, these benefits are not harnessed by most small to mid-sized buildings due to the high cost of deployment and maintenance. A cloud-based BEM system can offer a low-cost solution to promote ease of use and support a maintenance-free installation. In a typical building, a conventional router has a public address and assigns private addresses to all devices connected to it. This led to a network topology, where the router is the only device in the Internet space with all other devices forming an isolated local area network behind the router. -

Evaluation of Alternative Field Buses for Lighting Control Applications
Lawrence Berkeley National Laboratory Lawrence Berkeley National Laboratory Title Evaluation of Alternative Field Buses for Lighting Control Applications Permalink https://escholarship.org/uc/item/69z068th Authors Koch, Ed Rubinstein, Francis Publication Date 2005-03-21 eScholarship.org Powered by the California Digital Library University of California Evaluation of Alternative Field Buses for Lighting Control Applications Prepared By: Ed Koch, Akua Controls Edited By: Francis Rubinstein, Lawrence Berkeley National Laboratory Prepared For: Broadata Communications Torrence, CA March 21, 2005 Table of Contents Introduction......................................................................................................................... 3 Purpose ................................................................................................................................. 3 Statement of Work ................................................................................................................ 3 1-Wire Net .......................................................................................................................... 4 Introduction and Background................................................................................................ 4 Technical Specifications......................................................................................................... 5 Description of Technology........................................................................................ 5 Practical Considerations ......................................................................................... -

Philips Dynalite Product Portfolio
Philips Dynalite Networked Solutions Product Portfolio PRODUCT PORTFOLIO 1 Royal Adelaide Hospital Adelaide, Australia 2 PHILIPS DYNALITE Philips Dynalite – the intelligent choice When you choose Philips Dynalite, you are selecting the world’s finest lighting control system. Tried and tested in more than 30,000 projects, Philips Dynalite has implemented some of the largest and most extensive control networks around the globe. The same robust technology can be used in any application, on any scale. Philips Dynalite is part of the Signify Professional Systems group. This global group includes several other worldwide leaders in LED lighting and advanced lighting controls – including Philips Color Kinetics, Philips CityTouch, and Philips Large Luminous Surfaces. Combined, these groups offer years of market knowledge and experience in developing best-in-class lighting solutions and controls. Signify builds on our extraordinary strengths and depth of expertise to bring the best-in-the-industry connected lighting systems to our valued customers and partners. Our experience and expertise are unrivaled and our reputation is based on delivering successful outcomes for difficult and challenging projects. So, it is not really a matter of “Why use Philips Dynalite?” but “Why use anything else?” This Product Portfolio aims to provide a general overview of the Philips Dynalite range of Indoor Networked Controls products and solutions. Further detailed information can be found on each product in their specific Technical Datasheet, available for download -

2019 Title 24
DOCKETED Docket Stamp 5/4/2018 1:40:43 PM Updated: Docket Number: 17-BSTD-02 Project Title: 2019 Title 24, Part 6, Building Energy Efficiency Standards Rulemaking TN #: 223320 Document Title: Wayne Alldredge Comments On TN 223309 - 2019 Title 24 Description: N/A Filer: System Organization: Wayne Alldredge Submitter Role: Public Submission Date: 5/4/2018 9:05:30 AM Docketed Date: 5/4/2018 DOCKETED Docket Stamp 5/4/2018 10:25:47 AM Updated: Docket Number: 17-BSTD-02 Project Title: 2019 Title 24, Part 6, Building Energy Efficiency Standards Rulemaking TN #: 223320 Document Title: Wayne Alldredge Comments On 2019 Title 24 Part 6 Building Energy Efficiency Standards Description: N/A Filer: System Organization: Wayne Alldredge Submitter Role: Public Submission Date: 5/4/2018 9:05:30 AM Docketed Date: 5/4/2018 DOCKETED Docket 17-BSTD-02 Number: Project Title: 2019 Title 24, Part 6, Building Energy Efficiency Standards Rulemaking TN #: 223320 Document Title: Lutron Electronics Co., Inc. Comments On 2019 Title 24 Part 6 Building Energy Efficiency Standards Description: N/A Filer: System Organization: Lutron Electronics Co., Inc. Submitter Role: Public Submission 5/4/2018 9:05:30 AM Date: Docketed Date: 5/4/2018 Comment Received From: Lutron Electronics Co., Inc. Submitted On: 5/4/2018 Docket Number: 17-BSTD-02 On 2019 Title 24 Part 6 Building Energy Efficiency Standards Additional submitted attachment is included below. From: Wayne Alldredge <[email protected]> Sent: Friday, May 04, 2018 8:21 AM To: Energy - Docket Optical System <[email protected]> Subject: Wayne D. -

Buildings Interoperability Landscape
PNNL-25124 Buildings Interoperability Landscape December 2015 DB Hardin CD Corbin EG Stephan SE Widergren W Wang Prepared for the U.S. Department of Energy under Contract DE-AC05-76RL01830 PNNL-25124 Buildings Interoperability Landscape DB Hardin CD Corbin EG Stephan SE Widergren W Wang December 2015 Prepared for the U.S. Department of Energy under Contract DE-AC05-76RL01830 Pacific Northwest National Laboratory Richland, Washington 99352 Executive Summary Buildings are an integral part of our nation’s energy economy. Advancements in information and communications technology (ICT) have revolutionized energy management in industrial facilities and large commercial buildings. As ICT costs decrease and capabilities increase, buildings automation and energy management features are transforming the small-medium commercial and residential buildings sectors. A vision is emerging of a connected world in which building equipment and systems coordinate with each other to efficiently meet their owners’ and occupants’ needs and buildings regularly transact business with other buildings and service providers (e.g., gas and electric service providers). However, while the technology to support this collaboration has been demonstrated at various degrees of maturity, the integration frameworks and ecosystems of products that support the ability to easily install, maintain, and evolve building systems and their equipment components are struggling to nurture the fledging business propositions of their proponents. Through its Building Technologies Office (BTO), the United States Department of Energy’s Office of Energy Efficiency and Renewable Energy (DOE-EERE) is sponsoring an effort to advance interoperability for the integration of intelligent buildings equipment and automation systems, understanding the importance of integration frameworks and product ecosystems to this cause.