Download Preprint
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Stephen P. Lock on "Journalology"
INSTITUTE FOn SCIENTl FICl NF0F4MAT10N8 3501 MARKET ST PHILADELPHIA PA 19104 Stephen P. Lock on “Journalology” Number 3 January 15, 1990 I don’t remember exactly how long I have Lock: Editor and Scholar known Stephen P. Lock. Our first encounter was probably at a meeting of the Council of Biology Editors (CBE) some 20 years Stephen P. Lock was born in 1929 and re- ago. It is somewhat unsettling to realize that ceived his education at Queen’s College, so much time has gone by. Equally disquiet- Cambridge University, UK, and the Medical ing is the notion that Steve will soon retire College of St. Bartholomew’s Hospital. as editor of the venerable British Medical Trained as a hematologist, he served on the Journal (BMJ). But in the near future Steve staffs of various London teaching hospitals, will indeed step down, having helped train including St. Bartholomew’s and the Hos- his successor, due to be appointed in the fall pital for Sick Children, before being ap- of 1990. pointed assistant editor of BMJ in 1964. It seems odd to refer to Lock as an elder After serving as senior assistant editor and statesman of biomedical editing-however deputy editor, Lock became editor in 1975. accurate that description might be. The word I am amused that Steve opened his talk that comes to mind when I think of Steve with the traditional, mythical reminder about is youth. This youthfidness is reflected in the estimates of the number of extant jour- his writing and in his approach to problems. nals. -

Statistical Fallacy: a Menace to the Field of Science
International Journal of Scientific and Research Publications, Volume 9, Issue 6, June 2019 297 ISSN 2250-3153 Statistical Fallacy: A Menace to the Field of Science Kalu Emmanuel Ogbonnaya*, Benard Chibuike Okechi**, Benedict Chimezie Nwankwo*** * Department of Ind. Maths and Applied Statistics, Ebonyi State University, Abakaliki ** Department of Psychology, University of Nigeria, Nsukka. *** Department of Psychology and Sociological Studies, Ebonyi State University, Abakaliki DOI: 10.29322/IJSRP.9.06.2019.p9048 http://dx.doi.org/10.29322/IJSRP.9.06.2019.p9048 Abstract- Statistical fallacy has been a menace in the field of easier to understand but when used in a fallacious approach can sciences. This is mostly contributed by the misconception of trick the casual observer into believing something other than analysts and thereby led to the distrust in statistics. This research what the data shows. In some cases, statistical fallacy may be investigated the conception of students from selected accidental or unintentional. In others, it is purposeful and for the departments on statistical concepts as it relates statistical fallacy. benefits of the analyst. Students in Statistics, Economics, Psychology, and The fallacies committed intentionally refer to abuse of Banking/Finance department were randomly sampled with a statistics and the fallacy committed unintentionally refers to sample size of 36, 43, 41 and 38 respectively. A Statistical test misuse of statistics. A misuse occurs when the data or the results was conducted to obtain their conception score about statistical of analysis are unintentionally misinterpreted due to lack of concepts. A null hypothesis which states that there will be no comprehension. The fault cannot be ascribed to statistics; it lies significant difference between the students’ conception of with the user (Indrayan, 2007). -

Misuse of Statistics in Surgical Literature
Statistics Corner Misuse of statistics in surgical literature Matthew S. Thiese1, Brenden Ronna1, Riann B. Robbins2 1Rocky Mountain Center for Occupational & Environment Health, Department of Family and Preventive Medicine, 2Department of Surgery, School of Medicine, University of Utah, Salt Lake City, Utah, USA Correspondence to: Matthew S. Thiese, PhD, MSPH. Rocky Mountain Center for Occupational & Environment Health, Department of Family and Preventive Medicine, School of Medicine, University of Utah, 391 Chipeta Way, Suite C, Salt Lake City, UT 84108, USA. Email: [email protected]. Abstract: Statistical analyses are a key part of biomedical research. Traditionally surgical research has relied upon a few statistical methods for evaluation and interpretation of data to improve clinical practice. As research methods have increased in both rigor and complexity, statistical analyses and interpretation have fallen behind. Some evidence suggests that surgical research studies are being designed and analyzed improperly given the specific study question. The goal of this article is to discuss the complexities of surgical research analyses and interpretation, and provide some resources to aid in these processes. Keywords: Statistical analysis; bias; error; study design Submitted May 03, 2016. Accepted for publication May 19, 2016. doi: 10.21037/jtd.2016.06.46 View this article at: http://dx.doi.org/10.21037/jtd.2016.06.46 Introduction the most commonly used statistical tests of the time (6,7). Statistical methods have since become more complex Research in surgical literature is essential for furthering with a variety of tests and sub-analyses that can be used to knowledge, understanding new clinical questions, as well as interpret, understand and analyze data. -

United Nations Fundamental Principles of Official Statistics
UNITED NATIONS United Nations Fundamental Principles of Official Statistics Implementation Guidelines United Nations Fundamental Principles of Official Statistics Implementation guidelines (Final draft, subject to editing) (January 2015) Table of contents Foreword 3 Introduction 4 PART I: Implementation guidelines for the Fundamental Principles 8 RELEVANCE, IMPARTIALITY AND EQUAL ACCESS 9 PROFESSIONAL STANDARDS, SCIENTIFIC PRINCIPLES, AND PROFESSIONAL ETHICS 22 ACCOUNTABILITY AND TRANSPARENCY 31 PREVENTION OF MISUSE 38 SOURCES OF OFFICIAL STATISTICS 43 CONFIDENTIALITY 51 LEGISLATION 62 NATIONAL COORDINATION 68 USE OF INTERNATIONAL STANDARDS 80 INTERNATIONAL COOPERATION 91 ANNEX 98 Part II: Implementation guidelines on how to ensure independence 99 HOW TO ENSURE INDEPENDENCE 100 UN Fundamental Principles of Official Statistics – Implementation guidelines, 2015 2 Foreword The Fundamental Principles of Official Statistics (FPOS) are a pillar of the Global Statistical System. By enshrining our profound conviction and commitment that offi- cial statistics have to adhere to well-defined professional and scientific standards, they define us as a professional community, reaching across political, economic and cultural borders. They have stood the test of time and remain as relevant today as they were when they were first adopted over twenty years ago. In an appropriate recognition of their significance for all societies, who aspire to shape their own fates in an informed manner, the Fundamental Principles of Official Statistics were adopted on 29 January 2014 at the highest political level as a General Assembly resolution (A/RES/68/261). This is, for us, a moment of great pride, but also of great responsibility and opportunity. In order for the Principles to be more than just a statement of noble intentions, we need to renew our efforts, individually and collectively, to make them the basis of our day-to-day statistical work. -

Assessing the Utility of an Institutional Publications Officer: a Pilot Assessment
Assessing the utility of an institutional publications officer: a pilot assessment Kelly D. Cobey1,2,3, James Galipeau1, Larissa Shamseer1,2 and David Moher1,2 1 Centre for Journalology, Clinical Epidemiology Program, Ottawa Hospital Research Institute, Ottawa, Canada 2 School of Epidemiology, Public Health, and Preventative Medicine, University of Ottawa, Ottawa, Canada 3 School of Natural Sciences, Department of Psychology, University of Stirling, Stirling, United Kingdom ABSTRACT Background. The scholarly publication landscape is changing rapidly. We investigated whether the introduction of an institutional publications officer might help facilitate better knowledge of publication topics and related resources, and effectively support researchers to publish. Methods. In September 2015, a purpose-built survey about researchers' knowledge and perceptions of publication practices was administered at five Ottawa area research institutions. Subsequently, we publicly announced a newly hired publications officer (KDC) who then began conducting outreach at two of the institutions. Specifically, the publications officer gave presentations, held one-to-one consultations, developed electronic newsletter content, and generated and maintained a webpage of resources. In March 2016, we re-surveyed our participants regarding their knowledge and perceptions of publishing. Mean scores to the perception questions, and the percent of correct responses to the knowledge questions, pre and post survey, were computed for each item. The difference between these means or calculated percentages was then examined across the survey measures. Results. 82 participants completed both surveys. Of this group, 29 indicated that they had exposure to the publications officer, while the remaining 53 indicated they did not. Interaction with the publications officer led to improvements in half of the knowledge items (7/14 variables). -

Defining Covid-19 Elimination
EDITORIALS Department of Preventive and Social BMJ: first published as 10.1136/bmj.n1794 on 15 July 2021. Downloaded from Medicine, University of Otago, Dunedin, Defining covid-19 elimination New Zealand Correspondence to: D C G Skegg Elimination is achievable and should not be confused with eradication [email protected] Cite this as: BMJ 2021;374:n1794 David CG Skegg, Philip C Hill http://dx.doi.org/10.1136/bmj.n1794 Speaking about progress towards ending the covid-19 “zero covid” for a prolonged period. Even with border Published: 15 July 2021 epidemic in the United States, Anthony Fauci said: restrictions and strict quarantine, incursions of the “We will end the epidemic phase, and we will likely virus occur from time to time, leading to clusters of get somewhere between control and elimination, infections and occasional large outbreaks. In the more likely closer to control.”1 Now authorities in Australian state of Victoria, for example, a resurgence England are abandoning most efforts to control, let of covid-19 last year peaked at over 700 cases a day, alone eliminate, the infection.2 Throughout the before being extinguished after three months.11 pandemic, the word “elimination” has been used in Despite such setbacks, Australia and New Zealand different senses. Many confuse elimination with remain healthy economies with largely normal eradication, which normally means permanent community life, apart from temporary border reduction to zero of the worldwide incidence of an restrictions. Both are developing plans for a phased infection—as was achieved for smallpox.3 This reopening of borders. confusion helps to make the idea of eliminating The likely consequences of not aiming for elimination covid-19 seem impossible and not worth pursuing. -

Open Access Policies of Leading Medical Journals: a Cross-Sectional Study
Open access Research BMJ Open: first published as 10.1136/bmjopen-2018-028655 on 20 June 2019. Downloaded from Open access policies of leading medical journals: a cross-sectional study Tim S Ellison, 1 Tim Koder, 2 Laura Schmidt, 2 Amy Williams, 1 Christopher C Winchester 2 To cite: Ellison TS, Koder T, ABSTRACT Strengths and limitations of this study Schmidt L, et al. Open Objectives Academical and not-for-profit research access policies of leading funders are increasingly requiring that the research they ► This manuscript includes a cross-sectional analysis medical journals: a cross- fund must be published open access, with some insisting sectional study. BMJ Open of open access policies of medical journals with a on publishing with a Creative Commons Attribution (CC 2019;9:e028655. doi:10.1136/ high impact factor, including society-owned jour- BY) licence to allow the broadest possible use. We aimed bmjopen-2018-028655 nals, from multiple publishers. to clarify the open access variants provided by leading ► The open access policies of all journals analysed ► Prepublication history medical journals and record the availability of the CC BY were clarified, and confirmation of our findings and additional material for licence for commercially funded research. was received by email from 97% of the contacted this paper are available Methods We identified medical journals with a 2015 online. To view these files, journals. impact factor of ≥15.0 on 24 May 2017, then excluded please visit the journal online ► Open access policies of the journals and publishers from the analysis journals that only publish review articles. -

The Numbers Game - the Use and Misuse of Statistics in Civil Rights Litigation
Volume 23 Issue 1 Article 2 1977 The Numbers Game - The Use and Misuse of Statistics in Civil Rights Litigation Marcy M. Hallock Follow this and additional works at: https://digitalcommons.law.villanova.edu/vlr Part of the Civil Procedure Commons, Civil Rights and Discrimination Commons, Evidence Commons, and the Labor and Employment Law Commons Recommended Citation Marcy M. Hallock, The Numbers Game - The Use and Misuse of Statistics in Civil Rights Litigation, 23 Vill. L. Rev. 5 (1977). Available at: https://digitalcommons.law.villanova.edu/vlr/vol23/iss1/2 This Article is brought to you for free and open access by Villanova University Charles Widger School of Law Digital Repository. It has been accepted for inclusion in Villanova Law Review by an authorized editor of Villanova University Charles Widger School of Law Digital Repository. Hallock: The Numbers Game - The Use and Misuse of Statistics in Civil Righ 1977-19781 THE NUMBERS GAME - THE USE AND MISUSE OF STATISTICS IN CIVIL RIGHTS LITIGATION MARCY M. HALLOCKt I. INTRODUCTION "In the problem of racial discrimination, statistics often tell much, and Courts listen."' "We believe it evident that if the statistics in the instant matter represent less than a shout, they certainly constitute '2 far more than a mere whisper." T HE PARTIES TO ACTIONS BROUGHT UNDER THE CIVIL RIGHTS LAWS3 have relied increasingly upon statistical 4 analyses to establish or rebut cases of unlawful discrimination. Although statistical evidence has been considered significant in actions brought to redress racial discrimination in jury selection,5 it has been used most frequently in cases of allegedly discriminatory t B.A., University of Pennsylvania, 1972; J.D., Georgetown University Law Center, 1975. -

The Journal Impact Factor Denominator Defining Citable (Counted) Items
COMMENTARIES The Journal Impact Factor Denominator Defining Citable (Counted) Items Marie E. McVeigh, MS The items counted in the denominator of the impact fac- tor are identifiable in the Web of Science database by hav- Stephen J. Mann ing the index field document type set as “Article,” “Re- view,” or “Proceedings Paper” (a specialized subset of the VER ITS 30-YEAR HISTORY, THE JOURNAL IMPACT article document type). These document types identify the factor has been the subject of much discussion scholarly contribution of the journal to the literature and and debate.1 From its first release in 1975, bib- are counted as “citable items” in the denominator of the im- liometricians and library scientists discussed its pact factor. A journal accepted for coverage in the Thom- Ovalue and its vagaries. In the last decade, discussion has 6 son Reuters citation database is reviewed by experts who shifted to the way in which impact factor data are used. In consider the bibliographic and bibliometric characteristics an environment eager for objective measures of productiv- of all article types published by that journal (eg, items), which ity, relevance, and research value, the impact factor has been are covered by that journal in the context of other materi- applied broadly and indiscriminately.2,3 The impact factor als in the journal, the subject, and the database as a whole. has gone from being a measure of a journal’s citation influ- This journal-specific analysis identifies the journal sec- ence in the broader literature to a surrogate that assesses tions, subsections, or both that contain materials likely to the scholarly value of work published in that journal. -

Core Competencies for Scientific Editors Of
Moher et al. BMC Medicine (2017) 15:167 DOI 10.1186/s12916-017-0927-0 CORRESPONDENCE Open Access Core competencies for scientific editors of biomedical journals: consensus statement David Moher1,2* , James Galipeau3, Sabina Alam4, Virginia Barbour5, Kidist Bartolomeos6, Patricia Baskin7,8, Sally Bell-Syer9,10, Kelly D. Cobey1,2,11, Leighton Chan12, Jocalyn Clark13, Jonathan Deeks14, Annette Flanagin15, Paul Garner16, Anne-Marie Glenny17, Trish Groves18, Kurinchi Gurusamy19, Farrokh Habibzadeh20,21,22, Stefanie Jewell-Thomas23, Diane Kelsall24, José Florencio Lapeña Jr22,25,26,27, Harriet MacLehose28, Ana Marusic29,30, Joanne E. McKenzie31, Jay Shah32,33,34, Larissa Shamseer1,2, Sharon Straus35, Peter Tugwell2,36,37, Elizabeth Wager38,39, Margaret Winker22 and Getu Zhaori40 Abstract Background: Scientific editors are responsible for deciding which articles to publish in their journals. However, we have not found documentation of their required knowledge, skills, and characteristics, or the existence of any formal core competencies for this role. Methods: We describe the development of a minimum set of core competencies for scientific editors of biomedical journals. Results: The 14 key core competencies are divided into three major areas, and each competency has a list of associated elements or descriptions of more specific knowledge, skills, and characteristics that contribute to its fulfillment. Conclusions: We believe that these core competencies are a baseline of the knowledge, skills, and characteristics needed to perform competently the duties of a scientific editor at a biomedical journal. Keywords: Core competencies, Scientific editor, Biomedical journal, Delphi, Expert consensus, Editor role Introduction and in guidance for members of editor organizations Scientific editors (editors are responsible for the content [3–8]. -
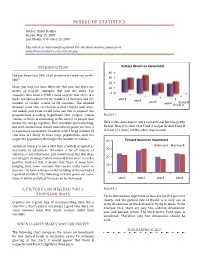
Misuse of Statistics
MISUSE OF STATISTICS Author: Rahul Dodhia Posted: May 25, 2007 Last Modified: October 15, 2007 This article is continuously updated. For the latest version, please go to www.RavenAnalytics.com/articles.php INTRODUCTION Percent Return on Investment 40 Did you know that 54% of all statistics are made up on the 30 spot? 20 Okay, you may not have fallen for that one, but there are 10 plenty of real-life examples that bait the mind. For 0 example, data from a 1988 census suggest that there is a high correlation between the number of churches and the year1 year2 number of violent crimes in US counties. The implied year3 Group B year4 Group A message from this correlation is that religion and crime are linked, and some would even use this to support the preposterous sounding hypothesis that religion causes FIGURE 1 crimes, or there is something in the nature of people that makes the two go together. That would be quite shocking, Here is the same data in more conventional but less pretty but alert statisticians would immediately point out that it format. Now it is clear that Fund A outperformed Fund B is a spurious correlation. Counties with a large number of in 3 out of 4 years, not the other way around. churches are likely to have large populations. And the larger the population, the larger the number of crimes.1 40 Percent Return on Investment Statistical literacy is not a skill that is widely accepted as Group A Group B necessary in education. Therefore a lot of misuse of 30 statistics is not intentional, just uninformed. -

Downloads Presented on the Abstract Page
bioRxiv preprint doi: https://doi.org/10.1101/2020.04.27.063578; this version posted April 28, 2020. The copyright holder for this preprint (which was not certified by peer review) is the author/funder, who has granted bioRxiv a license to display the preprint in perpetuity. It is made available under aCC-BY 4.0 International license. A systematic examination of preprint platforms for use in the medical and biomedical sciences setting Jamie J Kirkham1*, Naomi Penfold2, Fiona Murphy3, Isabelle Boutron4, John PA Ioannidis5, Jessica K Polka2, David Moher6,7 1Centre for Biostatistics, Manchester Academic Health Science Centre, University of Manchester, Manchester, United Kingdom. 2ASAPbio, San Francisco, CA, USA. 3Murphy Mitchell Consulting Ltd. 4Université de Paris, Centre of Research in Epidemiology and Statistics (CRESS), Inserm, Paris, F-75004 France. 5Meta-Research Innovation Center at Stanford (METRICS) and Departments of Medicine, of Epidemiology and Population Health, of Biomedical Data Science, and of Statistics, Stanford University, Stanford, CA, USA. 6Centre for Journalology, Clinical Epidemiology Program, Ottawa Hospital Research Institute, Ottawa, Canada. 7School of Epidemiology and Public Health, Faculty of Medicine, University of Ottawa, Ottawa, Canada. *Corresponding Author: Professor Jamie Kirkham Centre for Biostatistics Faculty of Biology, Medicine and Health The University of Manchester Jean McFarlane Building Oxford Road Manchester, M13 9PL, UK Email: [email protected] Tel: +44 (0)161 275 1135 bioRxiv preprint doi: https://doi.org/10.1101/2020.04.27.063578; this version posted April 28, 2020. The copyright holder for this preprint (which was not certified by peer review) is the author/funder, who has granted bioRxiv a license to display the preprint in perpetuity.