Using Graphical Representation of User Interfaces As Visual
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

WEKA Manual for Version 3-7-8
WEKA Manual for Version 3-7-8 Remco R. Bouckaert Eibe Frank Mark Hall Richard Kirkby Peter Reutemann Alex Seewald David Scuse January 21, 2013 ⃝c 2002-2013 University of Waikato, Hamilton, New Zealand Alex Seewald (original Commnd-line primer) David Scuse (original Experimenter tutorial) This manual is licensed under the GNU General Public License version 3. More information about this license can be found at http://www.gnu.org/licenses/gpl-3.0-standalone.html Contents ITheCommand-line 11 1Acommand-lineprimer 13 1.1 Introduction . 13 1.2 Basic concepts . 14 1.2.1 Dataset . 14 1.2.2 Classifier . 16 1.2.3 weka.filters . 17 1.2.4 weka.classifiers . 19 1.3 Examples . 23 1.4 Additional packages and the package manager . .24 1.4.1 Package management . 25 1.4.2 Running installed learning algorithms . 26 II The Graphical User Interface 29 2LaunchingWEKA 31 3PackageManager 35 3.1 Mainwindow ............................. 35 3.2 Installing and removing packages . 36 3.2.1 Unofficalpackages ...................... 37 3.3 Usingahttpproxy.......................... 37 3.4 Using an alternative central package meta data repository . 37 3.5 Package manager property file . 38 4SimpleCLI 39 4.1 Commands . 39 4.2 Invocation . 40 4.3 Command redirection . 40 4.4 Command completion . 41 5Explorer 43 5.1 The user interface . 43 5.1.1 Section Tabs . 43 5.1.2 Status Box . 43 5.1.3 Log Button . 44 5.1.4 WEKA Status Icon . 44 3 4 CONTENTS 5.1.5 Graphical output . 44 5.2 Preprocessing . 45 5.2.1 Loading Data . -

Tinkertool System 7 Reference Manual Ii
Documentation 0642-1075/2 TinkerTool System 7 Reference Manual ii Version 7.5, August 24, 2021. US-English edition. MBS Documentation 0642-1075/2 © Copyright 2003 – 2021 by Marcel Bresink Software-Systeme Marcel Bresink Software-Systeme Ringstr. 21 56630 Kretz Germany All rights reserved. No part of this publication may be redistributed, translated in other languages, or transmitted, in any form or by any means, electronic, mechanical, recording, or otherwise, without the prior written permission of the publisher. This publication may contain examples of data used in daily business operations. To illustrate them as completely as possible, the examples include the names of individuals, companies, brands, and products. All of these names are fictitious and any similarity to the names and addresses used by an actual business enterprise is entirely coincidental. This publication could include technical inaccuracies or typographical errors. Changes are periodically made to the information herein; these changes will be incorporated in new editions of the publication. The publisher may make improvements and/or changes in the product(s) and/or the program(s) described in this publication at any time without notice. Make sure that you are using the correct edition of the publication for the level of the product. The version number can be found at the top of this page. Apple, macOS, iCloud, and FireWire are registered trademarks of Apple Inc. Intel is a registered trademark of Intel Corporation. UNIX is a registered trademark of The Open Group. Broadcom is a registered trademark of Broadcom, Inc. Amazon Web Services is a registered trademark of Amazon.com, Inc. -

Predicting Search Task Difficulty
Predicting Search Task Difficulty Jaime Arguello University of North Carolina at Chapel Hill [email protected] Abstract. Search task difficulty refers to a user's assessment about the amount of effort required to complete a search task. Our goal in this work is to learn predictive models of search task difficulty. We evaluate features derived from the user's interaction with the search engine as well as features derived from the user's level of interest in the task and level of prior knowledge in the task domain. In addition to user-interaction fea- tures used in prior work, we evaluate features generated from scroll and mouse-movement events on the SERP. In some situations, we may prefer a system that can predict search task difficulty early in the search session. To this end, we evaluate features in terms of whole-session evidence and first-round evidence, which excludes all interactions starting with the second query. Our results found that the most predictive features were different for whole-session vs. first-round prediction, that mouseover fea- tures were effective for first-round prediction, and that level of interest and prior knowledge features did not improve performance. 1 Introduction Search engine users engage in a wide variety of search tasks. A large body of prior research focused on characterizing different types of search tasks (see Li and Belkin [10]). The motivation behind this prior work is to understand how task characteristics influence search behavior and how search systems can provide customized interactions for different task types. One important search task characteristic is search task difficulty. -

E-37-V Dome Camera Operation Manual
E-37-V Dome Camera Operation Manual i Table of Contents 1 Network Config .............................................................................................................. 1 1.1 Network Connection .......................................................................................... 1 1.2 Log in ................................................................................................................ 1 2 Live ................................................................................................................................ 6 2.1 Encode Setup ................................................................................................... 6 2.2 System Menu .................................................................................................... 7 2.3 Video Window Function Option ......................................................................... 7 2.4 Video Window Setup ......................................................................................... 8 2.4.1 Image Adjustment ....................................................................................... 8 2.4.2 Original Size ............................................................................................... 9 2.4.3 Full Screen ................................................................................................. 9 2.4.4 Width and Height Ratio ............................................................................. 10 2.4.5 Fluency Adjustment ................................................................................. -

The Fancytooltips Package∗†
The fancytooltips package∗y Robert Maˇr´ık [email protected] May 4, 2009 1 Introduction The package fancytooltips is a package for LATEX. The pdf can be created by pdflatex or by latex + dvips + AdobeDistiller1 + Adobe Acrobat2. It allows to create tooltips in a similar way like cooltooltips package, but the tooltip is a page from another PDF file. In this way you can use mathematics, pictures and animations in your tooltips. The resulting PDF file can be used also with free Abobe Reader. The tooltips are activated by clicking the active area on the screen and deac- tivated after closing page or by moving mouse outside the link. You can try the links here (Einstein's formula) and also here (animation { numbers from 1 to 6). You have to use the free Adobe Reader or nonfree Adobe Acrobat to see the effect (xpdf, evince and others fail to work with JavaScripts). For more examples how the presentation may look like see the example.pdf and example-min.pdf files in the examples subdirectory. The buttons are created using eforms.sty which is a part of AcroTeX bundle. 2 Usage 2.1 The file with tooltips The file with tooltips is an ordinary pdf file, one tooltip per page, tooltips should be in the top right corner at the page, in a colored box and the rest of the page should be transparent. If you consider to use movetips option (see below), then every page should have the dimensions equal to the dimen- sions of the colored box with tooltip3. -

Class -IV Super Computer Year- 2020-21
s Class -IV Super Computer Year- 2020-21 2. Windows 7 ❖ Focus of the Chapter 1. Windows desktop 2. Desktop icons 3. Start Menu 4. Task bar 5. Files and folders 6. Creating & saving new file/folder 7. Selecting a file/folder 8. Opening a file/folder 9. Renaming a file/folder 10. Deleting a file/folder 11. Moving a file/folder 12. Copying a file/folder 13. Creating a shortcut to a file/folder Keywords • Booting – Loading of the operating system. • Taskbar- The long bar present at the bottom of the desktop • Notification area- The area located on the right side of the taskbar • Folder- A container for storing files and other folders. Introduction Windows 7 is an operating system that Microsoft has produced for use on personal computers. It is the follow-up to the Windows Vista Operating System, which was released in 2006. An operating system allows your computer to manage software and perform essential tasks. It is also a Graphical User Interface (GUI) that allows you to visually interact with your computer’s functions in a logical, fun, and easy way. Interact with your computer’s functions in a logical, fun, and easy way. * The first screen appear after you turn on the power of computer is a desktop • If it is a shared PC; more than one user uses it, or one user with password protected, you will arrive at Welcome Screen Desktop Components 1- Icons: An icon is a graphic image, a small picture or object that represents a file, program, web page, or command. -
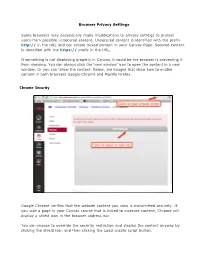
Chrome Security
Browser Privacy Settings Some browsers may occasionally make modifications to privacy settings to protect users from possible unsecured content. Unsecured content is identified with the prefix http:// in the URL and can create mixed content in your Canvas Page. Secured content is identified with the https:// prefix in the URL. If something is not displaying properly in Canvas, it could be the browser is preventing it from showing. You can always click the ‘new window’ icon to open the content in a new window. Or you can ‘allow the content. Below, are images that show how to enable content in both browsers Google Chrome and Mozilla Firefox. Chrome Security Google Chrome verifies that the website content you view is transmitted securely. If you visit a page in your Canvas course that is linked to insecure content, Chrome will display a shield icon in the browser address bar. You can choose to override the security restriction and display the content anyway by clicking the shield icon and then clicking the Load unsafe script button. Chrome Media Permissions Chrome has its own media permission within the browser. To use your computer camera and microphone within any Canvas feature, you will have to approve two permissions: 1. Allow access to Canvas via the Adobe Flash Player Settings. This prompt appears in the center of the video and audio pop-up windows, or the center of the browser if you are accessing Conversations. 2. Allow access to Canvas via Chrome's media permission settings. This prompt appears just below the address bar. Click the Allow button. -

Visualizing User Interface Events Event Stream Summarization Through Signs
Visualizing User Interface Events Event Stream Summarization through Signs Vagner Figueredo de Santana and Maria Cecília Calani Baranauskas Institute of Computing, University of Campinas (UNICAMP), Albert Einstein Av., 1251, Campinas, Brazil Keywords: Semiotics, User Interface Events, Visualization of Usage Data, Log Visualization, Event Icons, Icon Library, Image Library, User Interface Evaluation, Usability Evaluation, Accessibility Evaluation, Web Usage Mining. Abstract: Effective visual representation is related to how people interpret signs created to carry specific information. In the last years many user interface evaluation tools are considering detailed usage data to represent users’ actions. The volume of data gathered is leading developers to represent usage in a summarized way through graphical representations. If visual components used to represent complex data are not effective, then graphics used to summarize data may turn the interpretation of complex terms even harder. This work presents a study about graphical representations for user interface (UI) events and contributes with the validation of usage graph visualization and an open set of signs to support the summarization of client-side logs. The study involved 28 Information Technology specialists, potential users of UI evaluation tools. From the results one expects that evaluation tool developers, evaluators, and Web usage miners can reuse the validated usage graph representation and proposed set of signs to represent usage data in a summarized way. 1 INTRODUCTION these events is called, respectively, client-side logs and server-side logs (Santana and Baranauskas, The evaluation of user interface (UI) is a key task 2010a). when developing information systems and is part of In the last decade, website evaluation tools using a number of Software Engineering development server-side data (i.e., based on Web server logs) processes. -

CUSTOMIZING YOUR TOOLBARS in INTERNET EXPLORER, OUTLOOK EXPRESS, WINDOWS and WORD a Seminar Presented by Bill Wilkinson April 2008
CUSTOMIZING YOUR TOOLBARS IN INTERNET EXPLORER, OUTLOOK EXPRESS, WINDOWS AND WORD A Seminar Presented by Bill Wilkinson April 2008 Internet Explorer 7 Toolbars Internet Explorer 7, the latest version of Microsoft’s Web browser, sports a cleaner look than its predecessor. In fact, some users might wonder where everything went. The main toolbar is reduced in IE7 to just a couple of main buttons in the upper-left corner near the Address bar and a smattering of smaller buttons scattered about. The Menu Bar, a familiar feature in just about every program, was hidden by default in the earliest version IE7, but Microsoft was shamed into returning it to its traditional place. If you downloaded IE7 when it first came out, you will not see the Menu Bar. We will show you how to access it during this seminar session. The IE7 standard install also lacked a visible Links toolbar. Fortunately, Internet Explorer 7 features a streamlined toolbar that you can customize if you find it a little too sparse. The Page button is really a drop-down menu of commands loosely related to viewing the page in your browser window. This is where you can change text size, zoom level, or send pages and links through email. The Copy and Paste commands also ended up here, along with the command for opening a new window . Clicking Tools opens another submenu with a lot of the same commands from the original Tools menu. Here you’ll find the Pop-up Blocker, the Internet Options command, and other settings. Rounding out the IE7 interface are star-shaped buttons on the left side of the screen to add and view Favorites (called the Favorites Center). -

Clickjacking: Attacks and Defenses
Clickjacking: Attacks and Defenses Lin-Shung Huang Alex Moshchuk Helen J. Wang Carnegie Mellon University Microsoft Research Microsoft Research [email protected] [email protected] [email protected] Stuart Schechter Collin Jackson Microsoft Research Carnegie Mellon University [email protected] [email protected] Abstract such as a “claim your free iPad” button. Hence, when Clickjacking attacks are an emerging threat on the web. the user “claims” a free iPad, a story appears in the user’s In this paper, we design new clickjacking attack variants Facebook friends’ news feed stating that she “likes” the using existing techniques and demonstrate that existing attacker web site. For ease of exposition, our description clickjacking defenses are insufficient. Our attacks show will be in the context of web browsers. Nevertheless, the that clickjacking can cause severe damages, including concepts and techniques described are generally applica- compromising a user’s private webcam, email or other ble to all client operating systems where display is shared private data, and web surfing anonymity. by mutually distrusting principals. We observe the root cause of clickjacking is that an Several clickjacking defenses have been proposed and attacker application presents a sensitive UI element of a deployed for web browsers, but all have shortcomings. target application out of context to a user (such as hiding Today’s most widely deployed defenses rely on frame- the sensitive UI by making it transparent), and hence the busting [21, 37], which disallows a sensitive page from user is tricked to act out of context. To address this root being framed (i.e., embedded within another web page). -

Pen Computer Technology
Pen Computer Technology Educates the reader about the technologies involved in a pen computer Fujitsu PC Corporation www.fujitsupc.com For more information: [email protected] © 2002 Fujitsu PC Corporation. All rights reserved. This paper is intended to educate the reader about the technologies involved in a pen computer. After reading this paper, the reader should be better equipped to make intelligent purchasing decisions about pen computers. Types of Pen Computers In this white paper, "pen computer" refers to a portable computer that supports a pen as a user interface device, and whose LCD screen measures at least six inches diagonally. This product definition encompasses five generally recognized categories of standard products, listed in Table 1 below. PRODUCT TARGET PC USER STORAGE OPERATING RUNS LOCAL EXAMPLE CATEGORY MARKET INTERFACE SYSTEM PROGRAMS Webpad Consumer & No Standard Flash Windows CE, Only via Honeywell Enterprise browser memory Linux, QNX browser WebPAD II plug-ins CE Tablet Enterprise No Specialized Flash Windows CE Yes Fujitsu applications memory PenCentra Pen Tablet Enterprise Yes Windows & Hard drive Windows 9x, Yes Fujitsu specialized NT-4, 2000, Stylistic applications XP Pen-Enabled Consumer Yes Windows Hard drive Windows 9x, Yes Fujitsu & Enterprise 2000, XP LifeBook B Series Tablet PC Consumer Yes Windows Hard drive Windows XP Yes Many under & Enterprise Tablet PC development Edition Table 1: Categories of Pen Computers with LCD Displays of Six Inches or Larger Since the different types of pen computers are often confused, the following paragraphs are intended to help explain the key distinguishing characteristics of each product category. Pen Computers Contrasted Webpad: A Webpad's primary characteristic is that its only user interface is a Web browser. -

Poly Video Mode Administrator Guide
ADMINISTRATOR GUIDE 3.0.0 | December 2019 | 3725-85854-004A Poly Video Mode Getting Help For more information about installing, configuring, and administering Poly/Polycom products or services, go to Polycom Support. Plantronics, Inc. (Poly — formerly Plantronics and Polycom) 345 Encinal Street Santa Cruz, California 95060 © 2019 Plantronics, Inc. All rights reserved. Poly, the propeller design, and the Poly logo are trademarks of Plantronics, Inc. All other trademarks are the property of their respective owners. Contents Before You Begin................................................................................................6 Audience, Purpose, and Required Skills.............................................................................6 Related Poly and Partner Resources..................................................................................6 Getting Started................................................................................................... 8 Product Overview of Poly Video Systems...........................................................................8 Administrator Features and Capabilities.................................................................. 9 Powering the System On and Off......................................................................................10 Navigating the System...................................................................................................... 10 Access the System Web Interface..........................................................................10