Chapter 6 Inference with Tree-Clustering
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
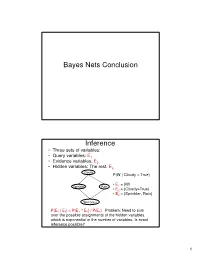
Bayes Nets Conclusion Inference
Bayes Nets Conclusion Inference • Three sets of variables: • Query variables: E1 • Evidence variables: E2 • Hidden variables: The rest, E3 Cloudy P(W | Cloudy = True) • E = {W} Sprinkler Rain 1 • E2 = {Cloudy=True} • E3 = {Sprinkler, Rain} Wet Grass P(E 1 | E 2) = P(E 1 ^ E 2) / P(E 2) Problem: Need to sum over the possible assignments of the hidden variables, which is exponential in the number of variables. Is exact inference possible? 1 A Simple Case A B C D • Suppose that we want to compute P(D = d) from this network. A Simple Case A B C D • Compute P(D = d) by summing the joint probability over all possible values of the remaining variables A, B, and C: P(D === d) === ∑∑∑ P(A === a, B === b,C === c, D === d) a,b,c 2 A Simple Case A B C D • Decompose the joint by using the fact that it is the product of terms of the form: P(X | Parents(X)) P(D === d) === ∑∑∑ P(D === d | C === c)P(C === c | B === b)P(B === b | A === a)P(A === a) a,b,c A Simple Case A B C D • We can avoid computing the sum for all possible triplets ( A,B,C) by distributing the sums inside the product P(D === d) === ∑∑∑ P(D === d | C === c)∑∑∑P(C === c | B === b)∑∑∑P(B === b| A === a)P(A === a) c b a 3 A Simple Case A B C D This term depends only on B and can be written as a 2- valued function fA(b) P(D === d) === ∑∑∑ P(D === d | C === c)∑∑∑P(C === c | B === b)∑∑∑P(B === b| A === a)P(A === a) c b a A Simple Case A B C D This term depends only on c and can be written as a 2- valued function fB(c) === === === === === === P(D d) ∑∑∑ P(D d | C c)∑∑∑P(C c | B b)f A(b) c b …. -

Inference Algorithm for Finite-Dimensional Spin
PHYSICAL REVIEW E 84, 046706 (2011) Inference algorithm for finite-dimensional spin glasses: Belief propagation on the dual lattice Alejandro Lage-Castellanos and Roberto Mulet Department of Theoretical Physics and Henri-Poincare´ Group of Complex Systems, Physics Faculty, University of Havana, La Habana, Codigo Postal 10400, Cuba Federico Ricci-Tersenghi Dipartimento di Fisica, INFN–Sezione di Roma 1, and CNR–IPCF, UOS di Roma, Universita` La Sapienza, Piazzale Aldo Moro 5, I-00185 Roma, Italy Tommaso Rizzo Dipartimento di Fisica and CNR–IPCF, UOS di Roma, Universita` La Sapienza, Piazzale Aldo Moro 5, I-00185 Roma, Italy (Received 18 February 2011; revised manuscript received 15 September 2011; published 24 October 2011) Starting from a cluster variational method, and inspired by the correctness of the paramagnetic ansatz [at high temperatures in general, and at any temperature in the two-dimensional (2D) Edwards-Anderson (EA) model] we propose a message-passing algorithm—the dual algorithm—to estimate the marginal probabilities of spin glasses on finite-dimensional lattices. We use the EA models in 2D and 3D as benchmarks. The dual algorithm improves the Bethe approximation, and we show that in a wide range of temperatures (compared to the Bethe critical temperature) our algorithm compares very well with Monte Carlo simulations, with the double-loop algorithm, and with exact calculation of the ground state of 2D systems with bimodal and Gaussian interactions. Moreover, it is usually 100 times faster than other provably convergent methods, as the double-loop algorithm. In 2D and 3D the quality of the inference deteriorates only where the correlation length becomes very large, i.e., at low temperatures in 2D and close to the critical temperature in 3D. -

Many-Pairs Mutual Information for Adding Structure to Belief Propagation Approximations
Proceedings of the Twenty-Third AAAI Conference on Artificial Intelligence (2008) Many-Pairs Mutual Information for Adding Structure to Belief Propagation Approximations Arthur Choi and Adnan Darwiche Computer Science Department University of California, Los Angeles Los Angeles, CA 90095 {aychoi,darwiche}@cs.ucla.edu Abstract instances of the satisfiability problem (Braunstein, Mezard,´ and Zecchina 2005). IBP has also been applied towards a We consider the problem of computing mutual informa- variety of computer vision tasks (Szeliski et al. 2006), par- tion between many pairs of variables in a Bayesian net- work. This task is relevant to a new class of Generalized ticularly stereo vision, where methods based on belief prop- Belief Propagation (GBP) algorithms that characterizes agation have been particularly successful. Iterative Belief Propagation (IBP) as a polytree approx- The successes of IBP as an approximate inference algo- imation found by deleting edges in a Bayesian network. rithm spawned a number of generalizations, in the hopes of By computing, in the simplified network, the mutual in- understanding the nature of IBP, and further to improve on formation between variables across a deleted edge, we the quality of its approximations. Among the most notable can estimate the impact that recovering the edge might are the family of Generalized Belief Propagation (GBP) al- have on the approximation. Unfortunately, it is compu- gorithms (Yedidia, Freeman, and Weiss 2005), where the tationally impractical to compute such scores for net- works over many variables having large state spaces. “structure” of an approximation is given by an auxiliary So that edge recovery can scale to such networks, we graph called a region graph, which specifies (roughly) which propose in this paper an approximation of mutual in- regions of the original network should be handled exactly, formation which is based on a soft extension of d- and to what extent different regions should be mutually con- separation (a graphical test of independence in Bayesian sistent. -

Matroid Theory
MATROID THEORY HAYLEY HILLMAN 1 2 HAYLEY HILLMAN Contents 1. Introduction to Matroids 3 1.1. Basic Graph Theory 3 1.2. Basic Linear Algebra 4 2. Bases 5 2.1. An Example in Linear Algebra 6 2.2. An Example in Graph Theory 6 3. Rank Function 8 3.1. The Rank Function in Graph Theory 9 3.2. The Rank Function in Linear Algebra 11 4. Independent Sets 14 4.1. Independent Sets in Graph Theory 14 4.2. Independent Sets in Linear Algebra 17 5. Cycles 21 5.1. Cycles in Graph Theory 22 5.2. Cycles in Linear Algebra 24 6. Vertex-Edge Incidence Matrix 25 References 27 MATROID THEORY 3 1. Introduction to Matroids A matroid is a structure that generalizes the properties of indepen- dence. Relevant applications are found in graph theory and linear algebra. There are several ways to define a matroid, each relate to the concept of independence. This paper will focus on the the definitions of a matroid in terms of bases, the rank function, independent sets and cycles. Throughout this paper, we observe how both graphs and matrices can be viewed as matroids. Then we translate graph theory to linear algebra, and vice versa, using the language of matroids to facilitate our discussion. Many proofs for the properties of each definition of a matroid have been omitted from this paper, but you may find complete proofs in Oxley[2], Whitney[3], and Wilson[4]. The four definitions of a matroid introduced in this paper are equiv- alent to each other. -

Tree Structures
Tree Structures Definitions: o A tree is a connected acyclic graph. o A disconnected acyclic graph is called a forest o A tree is a connected digraph with these properties: . There is exactly one node (Root) with in-degree=0 . All other nodes have in-degree=1 . A leaf is a node with out-degree=0 . There is exactly one path from the root to any leaf o The degree of a tree is the maximum out-degree of the nodes in the tree. o If (X,Y) is a path: X is an ancestor of Y, and Y is a descendant of X. Root X Y CSci 1112 – Algorithms and Data Structures, A. Bellaachia Page 1 Level of a node: Level 0 or 1 1 or 2 2 or 3 3 or 4 Height or depth: o The depth of a node is the number of edges from the root to the node. o The root node has depth zero o The height of a node is the number of edges from the node to the deepest leaf. o The height of a tree is a height of the root. o The height of the root is the height of the tree o Leaf nodes have height zero o A tree with only a single node (hence both a root and leaf) has depth and height zero. o An empty tree (tree with no nodes) has depth and height −1. o It is the maximum level of any node in the tree. CSci 1112 – Algorithms and Data Structures, A. -

A Simple Linear-Time Algorithm for Finding Path-Decompostions of Small Width
Introduction Preliminary Definitions Pathwidth Algorithm Summary A Simple Linear-Time Algorithm for Finding Path-Decompostions of Small Width Kevin Cattell Michael J. Dinneen Michael R. Fellows Department of Computer Science University of Victoria Victoria, B.C. Canada V8W 3P6 Information Processing Letters 57 (1996) 197–203 Kevin Cattell, Michael J. Dinneen, Michael R. Fellows Linear-Time Path-Decomposition Algorithm Introduction Preliminary Definitions Pathwidth Algorithm Summary Outline 1 Introduction Motivation History 2 Preliminary Definitions Boundaried graphs Path-decompositions Topological tree obstructions 3 Pathwidth Algorithm Main result Linear-time algorithm Proof of correctness Other results Kevin Cattell, Michael J. Dinneen, Michael R. Fellows Linear-Time Path-Decomposition Algorithm Introduction Preliminary Definitions Motivation Pathwidth Algorithm History Summary Motivation Pathwidth is related to several VLSI layout problems: vertex separation link gate matrix layout edge search number ... Usefullness of bounded treewidth in: study of graph minors (Robertson and Seymour) input restrictions for many NP-complete problems (fixed-parameter complexity) Kevin Cattell, Michael J. Dinneen, Michael R. Fellows Linear-Time Path-Decomposition Algorithm Introduction Preliminary Definitions Motivation Pathwidth Algorithm History Summary History General problem(s) is NP-complete Input: Graph G, integer t Question: Is tree/path-width(G) ≤ t? Algorithmic development (fixed t): O(n2) nonconstructive treewidth algorithm by Robertson and Seymour (1986) O(nt+2) treewidth algorithm due to Arnberg, Corneil and Proskurowski (1987) O(n log n) treewidth algorithm due to Reed (1992) 2 O(2t n) treewidth algorithm due to Bodlaender (1993) O(n log2 n) pathwidth algorithm due to Ellis, Sudborough and Turner (1994) Kevin Cattell, Michael J. Dinneen, Michael R. -

Matroids You Have Known
26 MATHEMATICS MAGAZINE Matroids You Have Known DAVID L. NEEL Seattle University Seattle, Washington 98122 [email protected] NANCY ANN NEUDAUER Pacific University Forest Grove, Oregon 97116 nancy@pacificu.edu Anyone who has worked with matroids has come away with the conviction that matroids are one of the richest and most useful ideas of our day. —Gian Carlo Rota [10] Why matroids? Have you noticed hidden connections between seemingly unrelated mathematical ideas? Strange that finding roots of polynomials can tell us important things about how to solve certain ordinary differential equations, or that computing a determinant would have anything to do with finding solutions to a linear system of equations. But this is one of the charming features of mathematics—that disparate objects share similar traits. Properties like independence appear in many contexts. Do you find independence everywhere you look? In 1933, three Harvard Junior Fellows unified this recurring theme in mathematics by defining a new mathematical object that they dubbed matroid [4]. Matroids are everywhere, if only we knew how to look. What led those junior-fellows to matroids? The same thing that will lead us: Ma- troids arise from shared behaviors of vector spaces and graphs. We explore this natural motivation for the matroid through two examples and consider how properties of in- dependence surface. We first consider the two matroids arising from these examples, and later introduce three more that are probably less familiar. Delving deeper, we can find matroids in arrangements of hyperplanes, configurations of points, and geometric lattices, if your tastes run in that direction. -

Incremental Dynamic Construction of Layered Polytree Networks )
440 Incremental Dynamic Construction of Layered Polytree Networks Keung-Chi N g Tod S. Levitt lET Inc., lET Inc., 14 Research Way, Suite 3 14 Research Way, Suite 3 E. Setauket, NY 11733 E. Setauket , NY 11733 [email protected] [email protected] Abstract Many exact probabilistic inference algorithms1 have been developed and refined. Among the earlier meth ods, the polytree algorithm (Kim and Pearl 1983, Certain classes of problems, including per Pearl 1986) can efficiently update singly connected ceptual data understanding, robotics, discov belief networks (or polytrees) , however, it does not ery, and learning, can be represented as incre work ( without modification) on multiply connected mental, dynamically constructed belief net networks. In a singly connected belief network, there is works. These automatically constructed net at most one path (in the undirected sense) between any works can be dynamically extended and mod pair of nodes; in a multiply connected belief network, ified as evidence of new individuals becomes on the other hand, there is at least one pair of nodes available. The main result of this paper is the that has more than one path between them. Despite incremental extension of the singly connect the fact that the general updating problem for mul ed polytree network in such a way that the tiply connected networks is NP-hard (Cooper 1990), network retains its singly connected polytree many propagation algorithms have been applied suc structure after the changes. The algorithm cessfully to multiply connected networks, especially on is deterministic and is guaranteed to have networks that are sparsely connected. These methods a complexity of single node addition that is include clustering (also known as node aggregation) at most of order proportional to the number (Chang and Fung 1989, Pearl 1988), node elimination of nodes (or size) of the network. -

Variational Message Passing
Journal of Machine Learning Research 6 (2005) 661–694 Submitted 2/04; Revised 11/04; Published 4/05 Variational Message Passing John Winn [email protected] Christopher M. Bishop [email protected] Microsoft Research Cambridge Roger Needham Building 7 J. J. Thomson Avenue Cambridge CB3 0FB, U.K. Editor: Tommi Jaakkola Abstract Bayesian inference is now widely established as one of the principal foundations for machine learn- ing. In practice, exact inference is rarely possible, and so a variety of approximation techniques have been developed, one of the most widely used being a deterministic framework called varia- tional inference. In this paper we introduce Variational Message Passing (VMP), a general purpose algorithm for applying variational inference to Bayesian Networks. Like belief propagation, VMP proceeds by sending messages between nodes in the network and updating posterior beliefs us- ing local operations at each node. Each such update increases a lower bound on the log evidence (unless already at a local maximum). In contrast to belief propagation, VMP can be applied to a very general class of conjugate-exponential models because it uses a factorised variational approx- imation. Furthermore, by introducing additional variational parameters, VMP can be applied to models containing non-conjugate distributions. The VMP framework also allows the lower bound to be evaluated, and this can be used both for model comparison and for detection of convergence. Variational message passing has been implemented in the form of a general purpose inference en- gine called VIBES (‘Variational Inference for BayEsian networkS’) which allows models to be specified graphically and then solved variationally without recourse to coding. -

A Framework for the Evaluation and Management of Network Centrality ∗
A Framework for the Evaluation and Management of Network Centrality ∗ Vatche Ishakiany D´oraErd}osz Evimaria Terzix Azer Bestavros{ Abstract total number of shortest paths that go through it. Ever Network-analysis literature is rich in node-centrality mea- since, researchers have proposed different measures of sures that quantify the centrality of a node as a function centrality, as well as algorithms for computing them [1, of the (shortest) paths of the network that go through it. 2, 4, 10, 11]. The common characteristic of these Existing work focuses on defining instances of such mea- measures is that they quantify a node's centrality by sures and designing algorithms for the specific combinato- computing the number (or the fraction) of (shortest) rial problems that arise for each instance. In this work, we paths that go through that node. For example, in a propose a unifying definition of centrality that subsumes all network where packets propagate through nodes, a node path-counting based centrality definitions: e.g., stress, be- with high centrality is one that \sees" (and potentially tweenness or paths centrality. We also define a generic algo- controls) most of the traffic. rithm for computing this generalized centrality measure for In many applications, the centrality of a single node every node and every group of nodes in the network. Next, is not as important as the centrality of a group of we define two optimization problems: k-Group Central- nodes. For example, in a network of lobbyists, one ity Maximization and k-Edge Centrality Boosting. might want to measure the combined centrality of a In the former, the task is to identify the subset of k nodes particular group of lobbyists. -

Linearized and Single-Pass Belief Propagation
Linearized and Single-Pass Belief Propagation Wolfgang Gatterbauer Stephan Gunnemann¨ Danai Koutra Christos Faloutsos Carnegie Mellon University Carnegie Mellon University Carnegie Mellon University Carnegie Mellon University [email protected] [email protected] [email protected] [email protected] ABSTRACT DR TS HAF D 0.8 0.2 T 0.3 0.7 H 0.6 0.3 0.1 How can we tell when accounts are fake or real in a social R 0.2 0.8 S 0.7 0.3 A 0.3 0.0 0.7 network? And how can we tell which accounts belong to F 0.1 0.7 0.2 liberal, conservative or centrist users? Often, we can answer (a) homophily (b) heterophily (c) general case such questions and label nodes in a network based on the labels of their neighbors and appropriate assumptions of ho- Figure 1: Three types of network effects with example coupling mophily (\birds of a feather flock together") or heterophily matrices. Shading intensity corresponds to the affinities or cou- (\opposites attract"). One of the most widely used methods pling strengths between classes of neighboring nodes. (a): D: for this kind of inference is Belief Propagation (BP) which Democrats, R: Republicans. (b): T: Talkative, S: Silent. (c): H: iteratively propagates the information from a few nodes with Honest, A: Accomplice, F: Fraudster. explicit labels throughout a network until convergence. A well-known problem with BP, however, is that there are no or heterophily applies in a given scenario, we can usually give known exact guarantees of convergence in graphs with loops. -

Lowest Common Ancestors in Trees and Directed Acyclic Graphs1
Lowest Common Ancestors in Trees and Directed Acyclic Graphs1 Michael A. Bender2 3 Martín Farach-Colton4 Giridhar Pemmasani2 Steven Skiena2 5 Pavel Sumazin6 Version: We study the problem of finding lowest common ancestors (LCA) in trees and directed acyclic graphs (DAGs). Specifically, we extend the LCA problem to DAGs and study the LCA variants that arise in this general setting. We begin with a clear exposition of Berkman and Vishkin’s simple optimal algorithm for LCA in trees. The ideas presented are not novel theoretical contributions, but they lay the foundation for our work on LCA problems in DAGs. We present an algorithm that finds all-pairs-representative : LCA in DAGs in O~(n2 688 ) operations, provide a transitive-closure lower bound for the all-pairs-representative-LCA problem, and develop an LCA-existence algorithm that preprocesses the DAG in transitive-closure time. We also present a suboptimal but practical O(n3) algorithm for all-pairs-representative LCA in DAGs that uses ideas from the optimal algorithms in trees and DAGs. Our results reveal a close relationship between the LCA, all-pairs-shortest-path, and transitive-closure problems. We conclude the paper with a short experimental study of LCA algorithms in trees and DAGs. Our experiments and source code demonstrate the elegance of the preprocessing-query algorithms for LCA in trees. We show that for most trees the suboptimal Θ(n log n)-preprocessing Θ(1)-query algorithm should be preferred, and demonstrate that our proposed O(n3) algorithm for all- pairs-representative LCA in DAGs performs well in both low and high density DAGs.