PANDA Vignette
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Longitudinal Study of Leukocyte DNA Methylation and Biomarkers for Cancer Risk in Older Adults
bioRxiv preprint doi: https://doi.org/10.1101/597666; this version posted April 3, 2019. The copyright holder for this preprint (which was not certified by peer review) is the author/funder, who has granted bioRxiv a license to display the preprint in perpetuity. It is made available under aCC-BY-NC-ND 4.0 International license. 1 Longitudinal Study of Leukocyte DNA Methylation and 2 Biomarkers for Cancer Risk in Older Adults 3 Alexandra H. Bartlett1, Jane W Liang1, Jose Vladimir Sandoval-Sierra1, Jay H 4 Fowke 1, Eleanor M Simonsick2, Karen C Johnson1, Khyobeni Mozhui1* 5 1Department of Preventive Medicine, University of Tennessee Health Science 6 Center, Memphis, Tennessee, USA 7 2Intramural Research Program, National Institute on Aging, Baltimore Maryland, 8 USA 9 AHB: [email protected]; JWL: [email protected]; JVSS: 10 [email protected]; JHF: [email protected]; EMS: [email protected]; 11 KCJ: [email protected]; KM: [email protected] 12 *Corresponding author: Khyobeni Mozhui 13 14 15 16 17 18 1 bioRxiv preprint doi: https://doi.org/10.1101/597666; this version posted April 3, 2019. The copyright holder for this preprint (which was not certified by peer review) is the author/funder, who has granted bioRxiv a license to display the preprint in perpetuity. It is made available under aCC-BY-NC-ND 4.0 International license. 19 Abstract 20 Background: Changes in DNA methylation over the course of life may provide 21 an indicator of risk for cancer. We explored longitudinal changes in CpG 22 methylation from blood leukocytes, and likelihood of a future cancer diagnosis. -

Implications of Zonal Architecture on Differential Gene Expression
www.nature.com/scientificreports OPEN Implications of zonal architecture on diferential gene expression profling and altered pathway expressions in mandibular condylar cartilage Aisha M. Basudan1*, Mohammad Azhar Aziz2 & Yanqi Yang3 Mandibular condylar cartilage (MCC) is a multi-zonal heterogeneous fbrocartilage containing diferent types of cells, but the factors/mechanisms governing the phenotypic transition across the zones have not been fully understood. The reliability of molecular studies heavily rely on the procurement of pure cell populations from the heterogeneous tissue. We used a combined laser-capture microdissection and microarray analysis approach which allowed identifcation of diferential zone-specifc gene expression profling and altered pathways in the MCC of 5-week-old rats. The bioinformatics analysis demonstrated that the MCC cells clearly exhibited distinguishable phenotypes from the articular chondrocytes. Additionally, a set of genes has been determined as potential markers to identify each MCC zone individually; Crab1 gene showed the highest enrichment while Clec3a was the most downregulated gene at the superfcial layer, which consists of fbrous (FZ) and proliferative zones (PZ). Ingenuity Pathway Analysis revealed numerous altered signaling pathways; Leukocyte extravasation signaling pathway was predicted to be activated at all MCC zones, in particular mature and hypertrophic chondrocytes zones (MZ&HZ), when compared with femoral condylar cartilage (FCC). Whereas Superpathway of Cholesterol Biosynthesis showed predicted activation in both FZ and PZ as compared with deep MCC zones and FCC. Determining novel zone-specifc diferences of large group of potential genes, upstream regulators and pathways in healthy MCC would improve our understanding of molecular mechanisms on regional (zonal) basis, and provide new insights for future therapeutic strategies. -

Detailed Review Paper on Retinoid Pathway Signalling
1 1 Detailed Review Paper on Retinoid Pathway Signalling 2 December 2020 3 2 4 Foreword 5 1. Project 4.97 to develop a Detailed Review Paper (DRP) on the Retinoid System 6 was added to the Test Guidelines Programme work plan in 2015. The project was 7 originally proposed by Sweden and the European Commission later joined the project as 8 a co-lead. In 2019, the OECD Secretariat was added to coordinate input from expert 9 consultants. The initial objectives of the project were to: 10 draft a review of the biology of retinoid signalling pathway, 11 describe retinoid-mediated effects on various organ systems, 12 identify relevant retinoid in vitro and ex vivo assays that measure mechanistic 13 effects of chemicals for development, and 14 Identify in vivo endpoints that could be added to existing test guidelines to 15 identify chemical effects on retinoid pathway signalling. 16 2. This DRP is intended to expand the recommendations for the retinoid pathway 17 included in the OECD Detailed Review Paper on the State of the Science on Novel In 18 vitro and In vivo Screening and Testing Methods and Endpoints for Evaluating 19 Endocrine Disruptors (DRP No 178). The retinoid signalling pathway was one of seven 20 endocrine pathways considered to be susceptible to environmental endocrine disruption 21 and for which relevant endpoints could be measured in new or existing OECD Test 22 Guidelines for evaluating endocrine disruption. Due to the complexity of retinoid 23 signalling across multiple organ systems, this effort was foreseen as a multi-step process. -

Longitudinal Study of Leukocyte DNA Methylation and Biomarkers for Cancer Risk in Older Adults Alexandra H
Bartlett et al. Biomarker Research (2019) 7:10 https://doi.org/10.1186/s40364-019-0161-3 RESEARCH Open Access Longitudinal study of leukocyte DNA methylation and biomarkers for cancer risk in older adults Alexandra H. Bartlett1, Jane W. Liang1, Jose Vladimir Sandoval-Sierra1, Jay H. Fowke1, Eleanor M. Simonsick2, Karen C. Johnson1 and Khyobeni Mozhui1* Abstract Background: Changes in DNA methylation over the course of life may provide an indicator of risk for cancer. We explored longitudinal changes in CpG methylation from blood leukocytes, and likelihood of future cancer diagnosis. Methods: Peripheral blood samples were obtained at baseline and at follow-up visit from 20 participants in the Health, Aging and Body Composition prospective cohort study. Genome-wide CpG methylation was assayed using the Illumina Infinium Human MethylationEPIC (HM850K) microarray. Results: Global patterns in DNA methylation from CpG-based analyses showed extensive changes in cell composition over time in participants who developed cancer. By visit year 6, the proportion of CD8+ T-cells decreased (p-value = 0. 02), while granulocytes cell levels increased (p-value = 0.04) among participants diagnosed with cancer compared to those who remained cancer-free (cancer-free vs. cancer-present: 0.03 ± 0.02 vs. 0.003 ± 0.005 for CD8+ T-cells; 0.52 ± 0. 14 vs. 0.66 ± 0.09 for granulocytes). Epigenome-wide analysis identified three CpGs with suggestive p-values ≤10− 5 for differential methylation between cancer-free and cancer-present groups, including a CpG located in MTA3, agene linked with metastasis. At a lenient statistical threshold (p-value ≤3×10− 5), the top 10 cancer-associated CpGs included a site near RPTOR that is involved in the mTOR pathway, and the candidate tumor suppressor genes REC8, KCNQ1,andZSWIM5. -

Genetic Variability in the Italian Heavy Draught Horse from Pedigree Data and Genomic Information
Supplementary material for manuscript: Genetic variability in the Italian Heavy Draught Horse from pedigree data and genomic information. Enrico Mancin†, Michela Ablondi†, Roberto Mantovani*, Giuseppe Pigozzi, Alberto Sabbioni and Cristina Sartori ** Correspondence: [email protected] † These two Authors equally contributed to the work Supplementary Figure S1. Mares and foal of Italian Heavy Draught Horse (IHDH; courtesy of Cinzia Stoppa) Supplementary Figure S2. Number of Equivalent Generations (EqGen; above) and pedigree completeness (PC; below) over years in Italian Heavy Draught Horse population. Supplementary Table S1. Descriptive statistics of homozygosity (observed: Ho_obs; expected: Ho_exp; total: Ho_tot) in 267 genotyped individuals of Italian Heavy Draught Horse based on the number of homozygous genotypes. Parameter Mean SD Min Max Ho_obs 35,630.3 500.7 34,291 38,013 Ho_exp 35,707.8 64.0 35,010 35,740 Ho_tot 50,674.5 93.8 49,638 50,714 1 Definitions of the methods for inbreeding are in the text. Supplementary Figure S3. Values of BIC obtained by analyzing values of K from 1 to 10, corresponding on the same amount of clusters defining the proportion of ancestry in the 267 genotyped individuals. Supplementary Table S2. Estimation of genomic effective population size (Ne) traced back to 18 generations ago (Gen. ago). The linkage disequilibrium estimation, adjusted for sampling bias was also included (LD_r2), as well as the relative standard deviation (SD(LD_r2)). Gen. ago Ne LD_r2 SD(LD_r2) 1 100 0.009 0.014 2 108 0.011 0.018 3 118 0.015 0.024 4 126 0.017 0.028 5 134 0.019 0.031 6 143 0.021 0.034 7 156 0.023 0.038 9 173 0.026 0.041 11 189 0.029 0.046 14 213 0.032 0.052 18 241 0.036 0.058 Supplementary Table S3. -

Supplemental Materials ZNF281 Enhances Cardiac Reprogramming
Supplemental Materials ZNF281 enhances cardiac reprogramming by modulating cardiac and inflammatory gene expression Huanyu Zhou, Maria Gabriela Morales, Hisayuki Hashimoto, Matthew E. Dickson, Kunhua Song, Wenduo Ye, Min S. Kim, Hanspeter Niederstrasser, Zhaoning Wang, Beibei Chen, Bruce A. Posner, Rhonda Bassel-Duby and Eric N. Olson Supplemental Table 1; related to Figure 1. Supplemental Table 2; related to Figure 1. Supplemental Table 3; related to the “quantitative mRNA measurement” in Materials and Methods section. Supplemental Table 4; related to the “ChIP-seq, gene ontology and pathway analysis” and “RNA-seq” and gene ontology analysis” in Materials and Methods section. Supplemental Figure S1; related to Figure 1. Supplemental Figure S2; related to Figure 2. Supplemental Figure S3; related to Figure 3. Supplemental Figure S4; related to Figure 4. Supplemental Figure S5; related to Figure 6. Supplemental Table S1. Genes included in human retroviral ORF cDNA library. Gene Gene Gene Gene Gene Gene Gene Gene Symbol Symbol Symbol Symbol Symbol Symbol Symbol Symbol AATF BMP8A CEBPE CTNNB1 ESR2 GDF3 HOXA5 IL17D ADIPOQ BRPF1 CEBPG CUX1 ESRRA GDF6 HOXA6 IL17F ADNP BRPF3 CERS1 CX3CL1 ETS1 GIN1 HOXA7 IL18 AEBP1 BUD31 CERS2 CXCL10 ETS2 GLIS3 HOXB1 IL19 AFF4 C17ORF77 CERS4 CXCL11 ETV3 GMEB1 HOXB13 IL1A AHR C1QTNF4 CFL2 CXCL12 ETV7 GPBP1 HOXB5 IL1B AIMP1 C21ORF66 CHIA CXCL13 FAM3B GPER HOXB6 IL1F3 ALS2CR8 CBFA2T2 CIR1 CXCL14 FAM3D GPI HOXB7 IL1F5 ALX1 CBFA2T3 CITED1 CXCL16 FASLG GREM1 HOXB9 IL1F6 ARGFX CBFB CITED2 CXCL3 FBLN1 GREM2 HOXC4 IL1F7 -

Contribution of Enhancer-Driven and Master-Regulator Genes to Autoimmune Disease Revealed Using Functionally Informed SNP-To-Gene Linking Strategies Kushal K
bioRxiv preprint doi: https://doi.org/10.1101/2020.09.02.279059; this version posted March 31, 2021. The copyright holder for this preprint (which was not certified by peer review) is the author/funder, who has granted bioRxiv a license to display the preprint in perpetuity. It is made available under aCC-BY-NC-ND 4.0 International license. Contribution of enhancer-driven and master-regulator genes to autoimmune disease revealed using functionally informed SNP-to-gene linking strategies Kushal K. Dey1, Steven Gazal1, Bryce van de Geijn 1,3, Samuel Sungil Kim 1,4, Joseph Nasser5, Jesse M. Engreitz5, Alkes L. Price 1,2,5 1 Department of Epidemiology, Harvard T. H. Chan School of Public Health, Boston, MA, USA 2 Department of Biostatistics, Harvard T.H. Chan School of Public Health, Boston, MA 3 Genentech, South San Francisco, CA 4 Department of Electrical Engineering and Computer Science, Massachusetts Institute of Technology, Cambridge, MA 5 Broad Institute of MIT and Harvard, Cambridge, MA, USA Abstract Gene regulation is known to play a fundamental role in human disease, but mechanisms of regulation vary greatly across genes. Here, we explore the con- tributions to disease of two types of genes: genes whose regulation is driven by enhancer regions as opposed to promoter regions (Enhancer-driven) and genes that regulate many other genes in trans (Master-regulator). We link these genes to SNPs using a comprehensive set of SNP-to-gene (S2G) strategies and apply stratified LD score regression to the resulting SNP annotations to draw three main conclusions about 11 autoimmune diseases and blood cell traits (average Ncase=13K across 6 autoimmune diseases, average N=443K across 5 blood cell traits). -

Genome-Wide DNA Methylation Analysis of KRAS Mutant Cell Lines Ben Yi Tew1,5, Joel K
www.nature.com/scientificreports OPEN Genome-wide DNA methylation analysis of KRAS mutant cell lines Ben Yi Tew1,5, Joel K. Durand2,5, Kirsten L. Bryant2, Tikvah K. Hayes2, Sen Peng3, Nhan L. Tran4, Gerald C. Gooden1, David N. Buckley1, Channing J. Der2, Albert S. Baldwin2 ✉ & Bodour Salhia1 ✉ Oncogenic RAS mutations are associated with DNA methylation changes that alter gene expression to drive cancer. Recent studies suggest that DNA methylation changes may be stochastic in nature, while other groups propose distinct signaling pathways responsible for aberrant methylation. Better understanding of DNA methylation events associated with oncogenic KRAS expression could enhance therapeutic approaches. Here we analyzed the basal CpG methylation of 11 KRAS-mutant and dependent pancreatic cancer cell lines and observed strikingly similar methylation patterns. KRAS knockdown resulted in unique methylation changes with limited overlap between each cell line. In KRAS-mutant Pa16C pancreatic cancer cells, while KRAS knockdown resulted in over 8,000 diferentially methylated (DM) CpGs, treatment with the ERK1/2-selective inhibitor SCH772984 showed less than 40 DM CpGs, suggesting that ERK is not a broadly active driver of KRAS-associated DNA methylation. KRAS G12V overexpression in an isogenic lung model reveals >50,600 DM CpGs compared to non-transformed controls. In lung and pancreatic cells, gene ontology analyses of DM promoters show an enrichment for genes involved in diferentiation and development. Taken all together, KRAS-mediated DNA methylation are stochastic and independent of canonical downstream efector signaling. These epigenetically altered genes associated with KRAS expression could represent potential therapeutic targets in KRAS-driven cancer. Activating KRAS mutations can be found in nearly 25 percent of all cancers1. -

SUPPLEMENTARY MATERIAL Bone Morphogenetic Protein 4 Promotes
www.intjdevbiol.com doi: 10.1387/ijdb.160040mk SUPPLEMENTARY MATERIAL corresponding to: Bone morphogenetic protein 4 promotes craniofacial neural crest induction from human pluripotent stem cells SUMIYO MIMURA, MIKA SUGA, KAORI OKADA, MASAKI KINEHARA, HIROKI NIKAWA and MIHO K. FURUE* *Address correspondence to: Miho Kusuda Furue. Laboratory of Stem Cell Cultures, National Institutes of Biomedical Innovation, Health and Nutrition, 7-6-8, Saito-Asagi, Ibaraki, Osaka 567-0085, Japan. Tel: 81-72-641-9819. Fax: 81-72-641-9812. E-mail: [email protected] Full text for this paper is available at: http://dx.doi.org/10.1387/ijdb.160040mk TABLE S1 PRIMER LIST FOR QRT-PCR Gene forward reverse AP2α AATTTCTCAACCGACAACATT ATCTGTTTTGTAGCCAGGAGC CDX2 CTGGAGCTGGAGAAGGAGTTTC ATTTTAACCTGCCTCTCAGAGAGC DLX1 AGTTTGCAGTTGCAGGCTTT CCCTGCTTCATCAGCTTCTT FOXD3 CAGCGGTTCGGCGGGAGG TGAGTGAGAGGTTGTGGCGGATG GAPDH CAAAGTTGTCATGGATGACC CCATGGAGAAGGCTGGGG MSX1 GGATCAGACTTCGGAGAGTGAACT GCCTTCCCTTTAACCCTCACA NANOG TGAACCTCAGCTACAAACAG TGGTGGTAGGAAGAGTAAAG OCT4 GACAGGGGGAGGGGAGGAGCTAGG CTTCCCTCCAACCAGTTGCCCCAAA PAX3 TTGCAATGGCCTCTCAC AGGGGAGAGCGCGTAATC PAX6 GTCCATCTTTGCTTGGGAAA TAGCCAGGTTGCGAAGAACT p75 TCATCCCTGTCTATTGCTCCA TGTTCTGCTTGCAGCTGTTC SOX9 AATGGAGCAGCGAAATCAAC CAGAGAGATTTAGCACACTGATC SOX10 GACCAGTACCCGCACCTG CGCTTGTCACTTTCGTTCAG Suppl. Fig. S1. Comparison of the gene expression profiles of the ES cells and the cells induced by NC and NC-B condition. Scatter plots compares the normalized expression of every gene on the array (refer to Table S3). The central line -
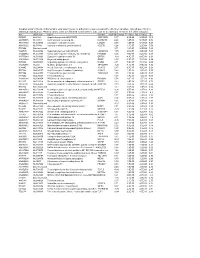
Supplementary File 2A Revised
Supplementary file 2A. Differentially expressed genes in aldosteronomas compared to all other samples, ranked according to statistical significance. Missing values were not allowed in aldosteronomas, but to a maximum of five in the other samples. Acc UGCluster Name Symbol log Fold Change P - Value Adj. P-Value B R99527 Hs.8162 Hypothetical protein MGC39372 MGC39372 2,17 6,3E-09 5,1E-05 10,2 AA398335 Hs.10414 Kelch domain containing 8A KLHDC8A 2,26 1,2E-08 5,1E-05 9,56 AA441933 Hs.519075 Leiomodin 1 (smooth muscle) LMOD1 2,33 1,3E-08 5,1E-05 9,54 AA630120 Hs.78781 Vascular endothelial growth factor B VEGFB 1,24 1,1E-07 2,9E-04 7,59 R07846 Data not found 3,71 1,2E-07 2,9E-04 7,49 W92795 Hs.434386 Hypothetical protein LOC201229 LOC201229 1,55 2,0E-07 4,0E-04 7,03 AA454564 Hs.323396 Family with sequence similarity 54, member B FAM54B 1,25 3,0E-07 5,2E-04 6,65 AA775249 Hs.513633 G protein-coupled receptor 56 GPR56 -1,63 4,3E-07 6,4E-04 6,33 AA012822 Hs.713814 Oxysterol bining protein OSBP 1,35 5,3E-07 7,1E-04 6,14 R45592 Hs.655271 Regulating synaptic membrane exocytosis 2 RIMS2 2,51 5,9E-07 7,1E-04 6,04 AA282936 Hs.240 M-phase phosphoprotein 1 MPHOSPH -1,40 8,1E-07 8,9E-04 5,74 N34945 Hs.234898 Acetyl-Coenzyme A carboxylase beta ACACB 0,87 9,7E-07 9,8E-04 5,58 R07322 Hs.464137 Acyl-Coenzyme A oxidase 1, palmitoyl ACOX1 0,82 1,3E-06 1,2E-03 5,35 R77144 Hs.488835 Transmembrane protein 120A TMEM120A 1,55 1,7E-06 1,4E-03 5,07 H68542 Hs.420009 Transcribed locus 1,07 1,7E-06 1,4E-03 5,06 AA410184 Hs.696454 PBX/knotted 1 homeobox 2 PKNOX2 1,78 2,0E-06 -

Supplementary Table S4. FGA Co-Expressed Gene List in LUAD
Supplementary Table S4. FGA co-expressed gene list in LUAD tumors Symbol R Locus Description FGG 0.919 4q28 fibrinogen gamma chain FGL1 0.635 8p22 fibrinogen-like 1 SLC7A2 0.536 8p22 solute carrier family 7 (cationic amino acid transporter, y+ system), member 2 DUSP4 0.521 8p12-p11 dual specificity phosphatase 4 HAL 0.51 12q22-q24.1histidine ammonia-lyase PDE4D 0.499 5q12 phosphodiesterase 4D, cAMP-specific FURIN 0.497 15q26.1 furin (paired basic amino acid cleaving enzyme) CPS1 0.49 2q35 carbamoyl-phosphate synthase 1, mitochondrial TESC 0.478 12q24.22 tescalcin INHA 0.465 2q35 inhibin, alpha S100P 0.461 4p16 S100 calcium binding protein P VPS37A 0.447 8p22 vacuolar protein sorting 37 homolog A (S. cerevisiae) SLC16A14 0.447 2q36.3 solute carrier family 16, member 14 PPARGC1A 0.443 4p15.1 peroxisome proliferator-activated receptor gamma, coactivator 1 alpha SIK1 0.435 21q22.3 salt-inducible kinase 1 IRS2 0.434 13q34 insulin receptor substrate 2 RND1 0.433 12q12 Rho family GTPase 1 HGD 0.433 3q13.33 homogentisate 1,2-dioxygenase PTP4A1 0.432 6q12 protein tyrosine phosphatase type IVA, member 1 C8orf4 0.428 8p11.2 chromosome 8 open reading frame 4 DDC 0.427 7p12.2 dopa decarboxylase (aromatic L-amino acid decarboxylase) TACC2 0.427 10q26 transforming, acidic coiled-coil containing protein 2 MUC13 0.422 3q21.2 mucin 13, cell surface associated C5 0.412 9q33-q34 complement component 5 NR4A2 0.412 2q22-q23 nuclear receptor subfamily 4, group A, member 2 EYS 0.411 6q12 eyes shut homolog (Drosophila) GPX2 0.406 14q24.1 glutathione peroxidase -

Transcriptional Regulatory Networks in Neocortical Development
Review From trans to cis: transcriptional regulatory networks in neocortical development 1 1 1,2 Mikihito Shibata , Forrest O. Gulden , and Nenad Sestan 1 Department of Neurobiology and Kavli Institute for Neuroscience, Yale School of Medicine, New Haven, CT 06510, USA 2 Department of Psychiatry and Program in Cellular Neuroscience, Neurodegeneration and Repair, Yale School of Medicine, New Haven, CT 06510, USA Transcriptional mechanisms mediated by the binding of tions among TFs and CREs form the central core of tran- transcription factors (TFs) to cis-acting regulatory ele- scriptional regulatory networks (TRNs) (Box 1) [1]. ments (CREs) in DNA play crucial roles in directing gene Interactions between TFs and CREs are complex, dynam- expression. While TFs have been extensively studied, ic,andmodulatedbyvariousepigeneticprocesses[12].While less effort has gone towards the identification and func- individual CREs may be regulated by the competitive or tional characterization of CREs and associated epigenet- cooperative binding of many TFs, multiple CREs may also ic modulation. However, owing to methodological and confer transcriptional control over the expression of any analytical advances, more comprehensive studies of single gene [12]. Furthermore, TFs and CREs regulate regulatory elements and mechanisms are now possible. transcription together with their cognate transcriptional We summarize recent progress in integrative analyses of cofactors, chromatin regulators, epigenetic modifications, these regulatory components in the development of the RNA-binding proteins, and non-coding RNAs [2,13]. This cerebral neocortex, the part of the brain involved in combinatorial and multi-level transcriptional regulation cognition and complex behavior. These studies are greatly increases the complexity of gene expression regula- uncovering not only the underlying transcriptional reg- tion, facilitating the unique spatio-temporal patterns nec- ulatory networks, but also how these networks are essary for tissue development and function [3].