Planning in Inhabited Environments: Human-Aware Task Planning and Activity Recognition
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

History of Robotics: Timeline
History of Robotics: Timeline This history of robotics is intertwined with the histories of technology, science and the basic principle of progress. Technology used in computing, electricity, even pneumatics and hydraulics can all be considered a part of the history of robotics. The timeline presented is therefore far from complete. Robotics currently represents one of mankind’s greatest accomplishments and is the single greatest attempt of mankind to produce an artificial, sentient being. It is only in recent years that manufacturers are making robotics increasingly available and attainable to the general public. The focus of this timeline is to provide the reader with a general overview of robotics (with a focus more on mobile robots) and to give an appreciation for the inventors and innovators in this field who have helped robotics to become what it is today. RobotShop Distribution Inc., 2008 www.robotshop.ca www.robotshop.us Greek Times Some historians affirm that Talos, a giant creature written about in ancient greek literature, was a creature (either a man or a bull) made of bronze, given by Zeus to Europa. [6] According to one version of the myths he was created in Sardinia by Hephaestus on Zeus' command, who gave him to the Cretan king Minos. In another version Talos came to Crete with Zeus to watch over his love Europa, and Minos received him as a gift from her. There are suppositions that his name Talos in the old Cretan language meant the "Sun" and that Zeus was known in Crete by the similar name of Zeus Tallaios. -
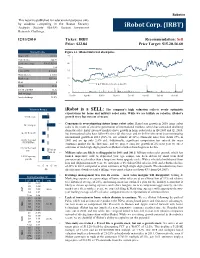
Robotics Irobot Corp. (IRBT)
Robotics This report is published for educational purposes only by students competing in the Boston Security Analysts Society (BSAS) Boston Investment iRobot Corp. (IRBT) Research Challenge. 12/13/2010 Ticker: IRBT Recommendation: Sell Price: $22.84 Price Target: $15.20-16.60 Market Profile Figure 1.1: iRobot historical stock price Shares O/S 25 mm 25 Current price $22.84 52 wk price range $14.45-$23.00 20 Beta 1.86 iRobot 3 mo ADTV 0.14 mm 15 Short interest 2.1 mm Market cap $581mm 10 Debt 0 S & P 500 (benchmarked Jan-09) P/10E 25.2x 5 EV/10 EBITDA 13.5x Instl holdings 57.8% 0 Jan-09 Apr-09 Jul-09 Oct-09 Jan-10 Apr-10 Jul-10 Oct-10 Insider holdings 12.5% Valuation Ranges iRobot is a SELL: The company’s high valuation reflects overly optimistic expectations for home and military robot sales. While we are bullish on robotics, iRobot’s 52 wk range growth story has run out of steam. • Consensus is overestimating future home robot sales: Rapid yoy growth in 2010 home robot Street targets sales is the result of one-time penetration of international markets, which has concealed declining domestic sales. Entry into new markets drove growth in home robot sales in Q4 2009 and Q1 2010, 20-25x P/2011E but international sales have fallen 4% since Q1 this year, and we believe the street is overestimating international growth in 2011 (30% vs. our estimate of 18%). Domestic sales were down 29% in 8-12x Terminal 2009 and are up only 2.5% ytd. -

Service Robots in the Domestic Environment
Service Robots in the Domestic Environment: A Study of the Roomba Vacuum in the Home Jodi Forlizzi Carl DiSalvo Carnegie Mellon University Carnegie Mellon University HCII & School of Design School of Design 5000 Forbes Ave. 5000 Forbes Ave. Pittsburgh, PA 15213 Pittsburgh, PA 15213 [email protected] [email protected] ABSTRACT to begin to develop a grounded understanding of human-robot Domestic service robots have long been a staple of science fiction interaction (HRI) in the home and inform the future development and commercial visions of the future. Until recently, we have only of domestic robotic products. been able to speculate about what the experience of using such a In this paper, we report on an ethnographic design-focused device might be. Current domestic service robots, introduced as research project on the use of the Roomba Discovery Vacuum consumer products, allow us to make this vision a reality. (www.irobot.com) (Figure 1). The Roomba is a “robotic floor This paper presents ethnographic research on the actual use of vac” capable of moving about the home and sweeping up dirt as it these products, to provide a grounded understanding of how goes along. The Roomba is a logical merging of vacuum design can influence human-robot interaction in the home. We technology and intelligent technology. More than 15 years ago, used an ecological approach to broadly explore the use of this large companies in Asia, Europe, and North America began to technology in this context, and to determine how an autonomous, develop mobile robotic vacuum cleaners for industrial and mobile robot might “fit” into such a space. -

Arduino® Tutorial
Arduino® Tutorial Power Serial I/O Powering an Arduino while leaving the USB port open for • To keep the Create 2 alive while you are talking to it, we programming is tricky. There are a few options; which is best recommend tying the Create BRC pin either to a spare depends on your circumstance. output on the Arduino which is kept low most of the time, or else directly to ground. 1. The recommended Vin input range on Arduino is 7 to 20V, • To hook up the TX and RX lines, see the Create®2to5VLogic due to its input regulator. When the robot is not charging, tutorial, taking note of the necessary PNP transistor if you you can plug this directly into Create’s main battery are using the hardware serial port. ® voltage, but while the Create 2 is charging, this bus • Depending on your Arduino, there are a few choices as to can get as high as 21V. If you choose this option, be sure which RX and TX lines you choose to use. Most Arduinos to unplug your circuit from the Create 2 when charging. have only one hardware serial port. This is shared We don’t recommend this option, as it could be easy to with the bootloader/programming port. It is possible to forget to unplug your circuit before you charge your robot. use this port to control the Create 2, but it may conflict with 2. One hack around this problem would be to “drop” a volt the robot when you are programming, and will conflict with from the robots Vbatt before feeding it into the Arduino. -

Repurposing a Roomba: Evaluating and Training Behavior in a Simple Agent
Virginia Commonwealth University VCU Scholars Compass Theses and Dissertations Graduate School 2007 Repurposing a Roomba: Evaluating and training behavior in a simple agent Donald Samuel Abbott-McCune Virginia Commonwealth University Follow this and additional works at: https://scholarscompass.vcu.edu/etd Part of the Computer Sciences Commons © The Author Downloaded from https://scholarscompass.vcu.edu/etd/1077 This Thesis is brought to you for free and open access by the Graduate School at VCU Scholars Compass. It has been accepted for inclusion in Theses and Dissertations by an authorized administrator of VCU Scholars Compass. For more information, please contact [email protected]. 2ii © Donald Samuel Abbott-McCune, 2007 All Rights Reserved Repurposing a Roomba: Evaluating and training behavior in a simple agent A thesis submitted in partial fulfillment of the requirements for the degree Master of Science at Virginia Commonwealth University By Donald Samuel Abbott-McCune Director: Dr. David Primeaux Associate Professor, Department of Computer Science Virginia Commonwealth University Richmond, Virginia May 2007 3iii Acknowledgements I would like to thank Dr. David Primeaux for his mentorship, advising, and for introducing me to new horizons of education. I would also express much thanks to the professors that guided me and taught me valuable lessons in Computer Science and to Deanna Pace for helping with scheduling and general counsel. Much appreciation goes to fellow graduate students whose bond and idea sharing helped create an ideal learning environment. To my wife Valerie and my daughter Rebecca, I cannot express the gratitude I have for your support while many hours were exhaustively used to research. -

Robot Ranger Sets Untethered 'Walking' Record A
Out of the gait: Robot ranger sets untethered 'walking' record a... http://www.sciencedaily.com/releases/2010/07/100722143905.htm News Articles Videos Images Books Health & Medicine Mind & Brain Plants & Animals Earth & Climate Space & Time Matter & Energy Science News Share Blog Cite Out of the Gait: Robot Ranger Sets Untethered 'Walking' Record at 14.3 Just In: Drug May Help Overwrite Bad Memories Miles Science Video News ScienceDaily (July 23, 2010) — The loneliness of enlarge the long-distance robot: A Cornell University robot named Ranger walked 14.3 miles in about 11 hours, setting an unofficial world record at Cornell's Barton Hall early on July 6. A human -- armed with nothing more than a standard remote control for toys -- steered the untethered robot. Computer Scientists Program Robots To Play Soccer, Communicate With Bees Ranger navigated 108.5 times See Also: around the indoor track in Cornell's Computational Neuroscientists And Engineers Barton Hall -- about 212 meters per Build Robot That Teaches Itself To Walk Up And Matter & Energy lap, and made about 70,000 steps Down Hills Robotics Research before it had a stop and recharge. The robot Ranger, which set an untethered walking Mimicking Insects to Avoid Sinking Using Surface Engineering record in Barton Hall. (Credit: Image courtesy of Tension Vehicles The 14.3-mile record beats the former world record set by Boston Cornell University) more science videos Computers & Math Dynamics' BigDog, which had Robotics claimed the record at 12.8 miles. Ads by Google Artificial Intelligence Internet A group of engineering students, led iRobot® Official Site — Learn More About the by Andy Ruina, Cornell professor of Newest Roomba & Scooba Floor Cleaning Robots Reference theoretical and applied mechanics, Now! Robotic surgery announced the robotic record at the www.iRobot.com Robot calibration Dynamic Walking 2010 meeting on Humanoid robot July 9, in Cambridge, Mass. -

LNCS 4717, Pp
“My Roomba Is Rambo”: Intimate Home Appliances Ja-Young Sung, Lan Guo, Rebecca E. Grinter, and Henrik I. Christensen GVU Center & School of Interactive Computing College of Computing, Georgia Institute of Technology Atlanta, GA, USA 30308 {jsung,languo,beki,hic}@ cc.gatech.edu Abstract. Robots have entered our domestic lives, but yet, little is known about their impact on the home. This paper takes steps towards addressing this omission, by reporting results from an empirical study of iRobot’s Roomba™, a vacuuming robot. Our findings suggest that, by developing intimacy to the robot, our participants were able to derive increased pleasure from cleaning, and expended effort to fit Roomba into their homes, and shared it with others. These findings lead us to propose four design implications that we argue could increase people’s enthusiasm for smart home technologies. Keywords: Empirical study, home, robot, intimacy. 1 Introduction As robots enter the domestic sphere in the form of pets, caretakers, and vacuum cleaners, a growing body of research argues the need to make robots fit into people’s lives [5,7,12,22,31]. Yet, far fewer studies have sought to empirically understand (with the exception of [11]) whether robots change domesticity as people adopt them. In this paper, we address this omission by reporting the results of our study of one type of robot (iRobot’s Roomba™ shown in Fig. 1) to learn whether, and if so, how, householders responded to their presence. What we learned suggests that people do form strong intimate attachments to these technologies. Studying domestic robots is timely, given globally rising adoption [38], and the increasing popularity of Roomba itself as evidenced by the media123. -

Irobot Dips Toe Into Pool-Cleaning Market 11 April 2007
iRobot Dips Toe into Pool-Cleaning Market 11 April 2007 Pool boys, you're on notice. iRobot has, in brushes that double as wheels, while the 300 lacks conjunction with AquaJet LLC and Aquatron, Inc., a handle and uses four wheels. Each robot can roll introduced not one, but two pool-cleaning robotics. along the bottom of the pools and on the vertical surfaces. In the videos, they appear to expel air Unlike iRobot's Roomba , however, the Verros are bubbles to reach the bottom of the pool. not a home-grown automatons. They're actually Aquatron creations. Unlike the robotic floor vacuum market, which iRobot all but invented, automatic pool cleaners Aquatron has two pool cleaning robots on the have been around for decades. Still, iRobot's market, the Aquabot and the Aquajet. The first imprimatur raises the overall profile for robot pool looks very much like iRobot's new Verro 600 and cleaning. "There's a lot of opportunity in the pool the latter is a near match for the 300. iRobot's cleaning robots," the iRobot representative said. contribution is mainly the Scooba robotic floor- washing robot, its distinctive blue and white colors, The two robots are available today at iRobot.com . and its not-insignificant brand recognition and market reach. Copyright 2007 by Ziff Davis Media, Distributed by United Press International Like the Aquatron products, the Verro 300 and 600 – $799 and $1,199, respectively – can, according to iRobot officials, clean an entire 20-foot x 50-foot pool in 60 to 90 minutes. The somewhat more affordable 300 works on gunite and concrete pools and uses water jets to clean out the pores and cracks often found in these environments. -

The Changing Nature and Socio-Cultural Meanings of Robots and Automation Kat Jungnickel This Working Paper Contributes to Securing Australia’S Future (SAF) Project 05
This report can be found at www.acola.org.au © Australian Council of Learned Academies From Frankenstein to the Roomba: The changing nature and socio-cultural meanings of robots and automation Kat Jungnickel This working paper contributes to Securing Australia’s Future (SAF) Project 05. 1. What is automation? Automation is defined as ‘automatically controlled operation of an apparatus, process, or system by mechanical or electronic devices that take the place of human labour’ (Merriam-Webster 2014). The term automation was first used in 1912. Robot first appeared later, in 1921 in a Czech play by Karel Čapek to describe a mechanical man. Both terms have been and continue to be imbued with divergent meanings and affect. To understand the role and importance of automation and robots it is critical to look not only at their technical and industrial contexts but also at the social and imaginary that produces and surrounds them. Automation and especially robots have been present in Western popular culture for centuries – from Mary Shelly’s Frankenstein in 1818 to contemporary Terminator films - and in many instances associated with fear and destruction. Yet, in and around these forceful representations a diverse assembly of automation built-into mundane and ordinary interactions (photocopy machines, coffee makers, vacuum cleaners etc) that we take for granted in everyday life. Automation and Robots are also enduringly present in much Western discourse and technological imaginings of the future (such as hover boards and jetpacks). This paper will briefly address automation’s origins, promise and threats and how it continues to be imbued and influenced by a range of socio-technical actors which shape how we tell stories about, invent and use automation/robots in our everyday lives. -

A Literature Study of Indoor Positioning Systems and Map Building Software
A Literature Study of Indoor Positioning Systems and Map Building Software Robin Amstersa, Ali Bin Junaida, Samrat Roya, Peter Slaetsa, Peter Aertsb, Maarten Verheyenb, Eric Demeesterb, AIMP RESEARCH GROUP, KU LEUVEN,MECHANICAL ENGINEERING TECHNOLOGY CLUSTER TC, CAMPUS GROEP TLEUVEN,BELGIUM BACRO RESEARCH GROUP, KU LEUVEN,DEPARTMENT OF MECHANICAL ENGINEERING,CAMPUS DIEPENBEEK,WETENSCHAPSPARK 27, 3590 DIEPENBEEK,BELGIUM Juli 17, 2017 http://www.acro.be/adusumnavigantium/ Chapter 1 Introduction Positioning is not a particularly new problem. Mankind has attempted to determine its location for centuries, using instruments such as sextants, clocks, almanacs, maps, etc. One of the largest revolutions in this field is probably the advent of the global positioning system (GPS), which was originally launched in 1973 by the United States military. GPS can provide position information almost anywhere on earth to anyone with a GPS receiver. The position is determined via signals that originate from sattelites that orbit the earth. These carry atomic clocks that are synchronised to each other and to ground clocks. The location of the satellites is known very precisely, and is broadcasted continuously by them. By using the satellite location, the travel time of the signal and the propagation speed, it is possible to determine the distance from the sattelite to the receiver. When the distance to at least 4 satellites is known, the receiver position can be determined in 3 dimensions via multilateration. Besides GPS, a number of other global navigation sattelite systems also exist. Examples include the Galileo (Europe) and GLONASS systems (Russia). The low cost and global coverage make GPS a very attractive solution. -

Irobot Corporation's Intellectual Property∗
iRobot Corporation’s Intellectual Property∗ “At iRobot, we believe there is a better way to accomplish many of the dull, dirty and dangerous tasks that face us today.”1 iRobot designs, develops and markets robots that help people complete ‘dull, dirty or dangerous’ tasks in dynamic real-world situations. The company’s robots use behavior-based, artificial-intelligence systems to undertake complex tasks. In contrast, most robotic manufacturing equipment or entertainment systems are designed to repeat routine actions in specific, known environments. On March 23, 2010, iRobot celebrated 20 years of innovation in robotics. Despite its track record of innovation, iRobot reported an accumulated deficit of $7.6 million in their balance sheet as of yearend 2009 (Exhibit 4). While this deficit had decreased substantially due to annual profits in the recent years (Exhibit 9), management cautioned: Because we operate in a rapidly evolving industry, there are challenges to predicting our future operating results, and we cannot be certain that our revenues will grow at rates that will allow us to maintain profitability during every fiscal quarter, or even every fiscal year. In addition, we only have limited operating history on which you can base your evaluation of our business. Failure to maintain profitability may result in our inability to access capital under our existing credit arrangements. (2009 10-K, p. 19) Background iRobot was founded in 1990 by scientists at the Massachusetts Institute of Technology. Over the subsequent two decades, iRobot developed proprietary technologies incorporating advanced concepts of navigation, mobility, manipulation and artificial intelligence. “iRobot's mission is to change the world by building practical robots that make a difference, while delivering increased value to our shareholders.”2 iRobot became a public company in November 2005, when for the first time, a robot sounded the opening bell on the NASDAQ stock exchange. -

Irobot-Roomba-500-Manual.Pdf
Dear iRobot Roomba Owner, Thank you for purchasing an iRobot Roomba vacuum cleaning robot. You’ve joined the millions of people who clean with robots - the smarter way to get it done. Please take a few moments to read this manual and get acquainted with your Roomba, to get the best performance from your robot. If you have any questions, visit our website at www.irobot.com for more information. Register your robot to instantly activate your warranty and enjoy these exclusive benefits: • Take advantage of iRobot’s award-winning customer service Get support tailored to your specific robot, including answers to questions, maintenance tips, video demos, live chat and more. • Get product updates and other valuable information Be among the first to find out about new robots, exclusive discounts and special promotions. When you register, you can also tell us about your experience with your Roomba; iRobot listens to our customers and makes enhancements to our robots based on your valued feedback. We’d love to hear from you! Register your robot right now at www.irobot.com/register. On behalf of the entire team, thank you for choosing iRobot; we appreciate your business, feedback and loyalty. Here’s to robots that make a difference! Yours for less chores and more life, Colin Angle Chairman, CEO and Co-Founder iRobot Corporation P.S. Don’t miss out on your exclusive benefits! Register your Roomba online right now at www.irobot.com/register. Important Tips Table of Contents Before using Roomba the first iRobot Roomba Anatomy .............................................6 time, you need to activate Roomba by removing the battery pull tab.