Optimal Top-K Generation of Attribute Combinations Based on Ranked Lists
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Cowboy Basketball Game Center Game 29 ► March 2, 2019 ► 11 A.M
2 NCAA CHAMPIONSHIPS • 6 FINAL FOURS • 11 ELITE EIGHTS • 11 SWEET SIXTEENS • 34 ALL-AMERICA SELECTIONS COWBOY BASKETBALL GAME CENTER GAME 29 ► MARCH 2, 2019 ► 11 A.M. CT ► CBS ► Gallagher-Iba Arena Opponent: No. 15/16 Kansas (21-7, 10-5 Big 12) Date / Tipoff: March 2, 2019 / 11 a.m. CT Site: Gallagher-Iba Arena (13,611) 15/16 KANSAS Tickets: okstate.com/tickets or 877-ALL-4-OSU 21-7, 10-5 Big 12 ► Head Coach: Bill Self Series: KU leads 115-59 (36-35 in Stillwater) TV: CBS (Brad Nessler, Jim Spanarkel) Webcast: cbs.com/all-access or CBS All-Access app Radio: Cowboy Radio Network (Dave Hunziker, John Holcomb) OKLAHOMA STATE Satellite Radio: Sirius 119, XM 200 10-18, 3-12 Big 12 ► Head Coach: Mike Boynton, Jr. Live Stats: okstate.statbroadcast.com 2018-19TEAM TEAM STATS/NCAA STATS/NCAA RANKING RANKING OKLAHOMA STATE PROBABLE STARTERS Guard 13 isaac likekele | 6-4 | 210 | fr. | Arlington, TX Category NCAA Rank Value NCAA Rank Value Min. PPG RPG APG BPG SPG FG% 3FG% FT% Scoring Offense 299 67.5 99 75.9 Scoring Defense 183 71.5 139 69.9 28.3 8.4 4.6 3.7 0.3 1.3 46.2 27.3 65.2 Scoring Margin 286 -4.0 81 6.1 ►1 of just 2 Big 12 players with 8.4+ ppg, 4.6+ rpg, 3.7+ apg ... 3.7 apg ranks 4th in the Big 12. Field-Goal Percentage 289 42.1 56 46.9 Field-Goal Percentage Defense 129 43.0 29 40.5 Guard Three-Point Field-Goal Percentage 29 38.2 90 36.2 4 thomas dziagwa | 6-4 | 180 | jr. -
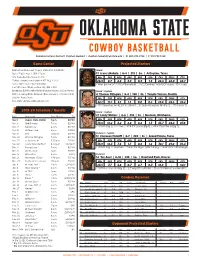
Game Center 2019-20 Schedule / Results Projected Starters Cowboy
Communications Contact: Stephen Howard I [email protected] | O: 405.744.7756 | C: 817.793.5199 Game Center Projected Starters Exbhibition Opponent: Rogers State (0-0, 0-0 MIAA) Guard Date / Tipoff: Nov. 1, 2019 / 7 p.m. 13 Isaac Likekele | 6-4 | 215 | So. | Arlington, Texas Site: Gallagher-Iba Arena (13,611) Min. PPG RPG APG BPG SPG FG% 3FG% FT% Tickets: okstate.com/tickets or 877-ALL-4-OSU 28.9 8.7 4.8 3.9 0.3 1.3 46.6 24.0 65.7 Series: OSU leads 2-0 (2-0 in GIA) • Won gold with U19 USA Basketball ... 1 of 2 Cowboys with 120+ assists, 40+ steals. Last: OSU won 101-85 on Nov. 30, 2016 in GIA Broadcast: ESPN+ (Mike Wolfe, Bryndon Manzer, Jessica Morrey) Guard • Captain Radio: Cowboy Radio Network (Dave Hunziker, John Holcomb) 4 Thomas Dziagwa | 6-4 | 190 | Sr. | Temple Terrace, Florida Satellite Radio: None Min. PPG RPG APG BPG SPG FG% 3FG% FT% Live Stats: okstate.statbroadcast.com 32.1 11.7 3.1 1.1 0.0 0.5 39.6 42.5 76.2 • 105 3-pointers on 42.5% in 2018-19 ... 1st team Academic All-Big 12 ... 175 career 3s. 2019-20 Schedule / Results Guard • Captain Date Opponent Time/Result TV 21 Lindy Waters | 6-6 | 210 | Sr. | Norman, Oklahoma Nov. 1 Rogers State (Exhib) 7 p.m. ESPN+ Min. PPG RPG APG BPG SPG FG% 3FG% FT% Nov. 6 Oral Roberts 7 p.m. ESPN+ 33.8 12.2 4.2 2.8 0.2 1.3 43.7 44.8 87.8 Nov. -

National Basketball Association Official
NATIONAL BASKETBALL ASSOCIATION OFFICIAL SCORER'S REPORT FINAL BOX 10/11/2012 MasterCard Center, Beijing, China, Officials: #17 Joe Crawford, #42 Eric Lewis, #7 Kevin Fehr Time of Game: 2:16 Attendance: 17,006 (Sellout) VISITOR: Miami Heat (1-1) NO PLAYER MIN FG FGA 3P 3PA FT FTA OR DR TOT A PF ST TO BS PTS 6 LeBron James F 26:12 6 11 0 0 8 9 2 3 5 5 1 1 2 0 20 31 Shane Battier F 22:56 2 2 2 2 0 0 1 2 3 2 0 0 1 0 6 1 Chris Bosh C 21:42 3 5 0 2 4 4 1 3 4 1 5 1 1 1 10 3 Dwyane Wade G 23:14 2 9 0 0 1 2 0 4 4 2 4 4 2 2 5 30 Norris Cole G 24:00 4 9 2 2 1 2 0 2 2 1 2 1 2 0 11 34 Ray Allen 26:12 5 11 4 8 1 1 1 0 1 1 0 0 1 0 15 9 Rashard Lewis 14:21 1 2 0 1 3 4 0 1 1 1 4 1 1 0 5 32 Mickell Gladness 15:03 1 4 0 0 1 2 1 3 4 0 4 0 1 2 3 51 Rodney Carney 13:01 3 4 3 4 2 2 0 1 1 0 2 1 0 1 11 17 Garrett Temple 24:00 1 5 0 2 0 0 0 3 3 5 2 1 1 0 2 7 Robert Dozier 9:10 1 5 0 0 0 0 1 2 3 1 0 2 0 0 2 55 Josh Harrellson 11:15 2 8 0 2 0 0 2 1 3 0 3 0 0 0 4 14 Terrel Harris 8:54 0 2 0 0 0 0 0 0 0 0 1 0 0 0 0 50 Joel Anthony DNP - Coach's Decision 15 Mario Chalmers DNP - Coach's Decision 40 Udonis Haslem DNP - Coach's Decision 22 James Jones DNP - Coach's Decision 13 Mike Miller DNP - Coach's Decision 45 Dexter Pittman DND - Right Toe 24 Jarvis Varnado DNP - Coach's Decision TOTALS: 31 77 11 23 21 26 9 25 34 19 28 12 12 6 94 PERCENTAGES: 40.3% 47.8% 80.8% TM REB: 7 TOT TO: 12 (15 PTS) HOME: LOS ANGELES CLIPPERS (0-2) NO PLAYER MIN FG FGA 3P 3PA FT FTA OR DR TOT A PF ST TO BS PTS 5 Caron Butler F 22:33 5 9 2 3 1 1 0 2 2 2 2 0 2 0 13 32 Blake Griffin F 31:38 8 -

Dynamic Player Significance (DPS): a New Comprehensive Basketball Statistic
Dynamic Player Significance (DPS): A new comprehensive basketball statistic David Hill Media Lab, Massachusetts Institute of Technology Cambridge, Massachusetts, USA [email protected] 15.071 (The Analytics Edge) Final Project May 13, 2013 Abstract Dynamic player significance is a new basketball metric designed to measure each NBA player's importance, or significance, to his franchise. This metric attempts to clearly define each player's role on the team and how it fits with the team's identity. Its key aspect is that it is influenced by the on-court identity of each franchise, which is defined as the collection of factors that contribute most to a win by a given team. These factors differ for every NBA team. Therefore, two players with completely identical stats/skillsets, but different teams, will most likely have different significance values. Alternatively, if a player is traded from one team to another, his significance will differ on the new team even if his production remains constant. Hence, dynamic player significance. Here, I have broken down the components of the model and explored three case studies that clearly show how teams’ identities deviate. Additionally, player evaluations have been explored to show tendencies in the model across multiple conditions. The proposed statistic could help inform team personnel decisions and coaching strategies, in addition to gauging player effectiveness. Motivation In the NBA, one of the most important things for any team to establish is an identity. These are the traits that define a team. Often, identity is the major factor that governs all transactions, whether the team is looking for players, hiring a coach, or filling front office positions. -

Hr9097-00 Page 1 of 2 House Resolution 1 A
FLORIDA HOUSE OF REP RESENTATIVE S HR 9097 2013 1 House Resolution 2 A resolution congratulating the Miami Heat Basketball 3 Team for winning the second National Basketball 4 Association Championship in state history. 5 6 WHEREAS, on June 21, 2012, the Miami Heat defeated the 7 Oklahoma City Thunder at Miami, 121 to 106, in a game that 8 showcased the team's athletic excellence and determination, and 9 WHEREAS, in this historic win, the Miami Heat earned the 10 franchise's and the state's second National Basketball 11 Association Championship, and 12 WHEREAS, after losing the first game of the National 13 Basketball Association Finals, the Miami Heat rallied to win 14 four consecutive games, clinching the National Title, and 15 WHEREAS, in just four seasons with the Miami Heat, Head 16 Coach Erik Spoelstra led the team to a championship win, and 17 WHEREAS, under Head Coach Erik Spoelstra and his coaching 18 staff, the Miami Heat, including LeBron James, who was named 19 Most Valuable Player, Dwayne Wade, Joel Anthony, Shane Battier, 20 Chris Bosh, Mario Chalmers, Udonis Haslem, Norris Cole, Eddy 21 Curry, Terrel Harris, Juwan Howard, James Jones, Mike Miller, 22 Dexter Pittman, and Ronny Turiaf united to form a championship 23 team, and 24 WHEREAS, it is with great pride that the Miami Heat is 25 recognized for the numerous accomplishments of its players, 26 coaches, and owner Micky Arison, NOW, THEREFORE, 27 Page 1 of 2 hr9097-00 FLORIDA HOUSE OF REP RESENTATIVE S HR 9097 2013 28 Be It Resolved by the House of Representatives of the State of 29 Florida: 30 31 That the Miami Heat Basketball Team is saluted and 32 congratulated for winning the 2012 National Basketball 33 Association Championship, the second such championship in the 34 state's history. -

Eighty-Eight Former NBA D-Leaguers Highlight 2011-12 NBA Opening Day Rosters
Eighty-Eight Former NBA D-Leaguers Highlight 2011-12 NBA Opening Day Rosters -- Eleven Players Earn Gatorade Call-Ups – -- Nets’ Horner’s Path Takes Him From Boost Mobile National Tryout to NBA Opening Day Roster -- NEW YORK, December 26, 2011 – An all-time high, 88 players with NBA Development League experience highlight 2011-12 NBA opening day rosters. That number of former NBA D-Leaguers on NBA opening day rosters surpasses the previous highs of 63 the previous two seasons. In just five years, the number of former NBA D-League players on NBA start-of-season rosters has more than doubled, going from 35 on opening day in 2006- 07 to 88 today. Twenty-nine of 30 NBA teams feature at least one player with NBA D-League experience, while the Cleveland Cavaliers and Houston Rockets each have six former NBA D-Leaguers on their respective rosters. Dennis Horner, a 6-9 forward out of N.C. State, made the New Jersey Nets in the same year in which he signed up to participate in the 2011 NBA D-League Boost Mobile National Tryout last June in Louisville, KY. He was selected by the Springfield Armor in the third round (47 th overall) in the 2011 NBA D-League Draft Presented by Cisco. Horner was selected by the Nets, the Armor’s affiliate, to participate in the teams 2011 NBA training camp after averaging 15.0 points and 7.7 rebounds per game in Springfield. Of the 88 former NBA D-League players in the NBA, eleven are earning a Gatorade Call-Up as the NBA begins the 2011-12 NBA season having played in the NBA D-League earlier this season. -

Team Statistics Box Scores Vegas Sl Records Game
TEAM STATISTICS BOX SCORES VEGAS SL RECORDS GAME RECAPS FEATURE ARTICLES WARRIORS FINAL SUMMER LEAGUE ROSTER WARRIORS SUMMER LEAGUE RESULTS NO PLAYER POS HT WT DOB PRIOR TO NBA/FROM NBA EXP. DATE OPPONENT RESULT SCORE HIGH POINTS/REBOUNDS/ASSISTS OPPS HIGH POINTS/REBOUNDS/ASSISTS July 13 vs. LA Lakers W 90-50 Thompson 24/Green 9/Thompson 5 Goudelock 14/Majok 7/Morris 4 40 Harrison Barnes F 6-8 210 5/30/92 North Carolina/USA R July 14 vs. Denver W 95-74 Jenkins 24/Barnes & Ezeli 7/Thompson 4 Hamilton 18/Faried 8/Faried 3 July 18 vs. Miami W 65-62 Jenkins 17/Barnes 7/Three Players 2 Cole 15/Viney 8/Cole 4 20 Kent Bazemore G/F 6-5 195 7/1/89 Old Dominion/USA R July 20 vs. Chicago W 66-57 Barnes 20/Green 11/Ragland 3 Teague & Thomas 12/Thomas 16/Four Players 2 25 Justin Burrell F 6-8 244 4/18/88 St. John’s/USA R July 21 vs. New Orleans W 80-72 Jenkins 15/Three Players 6/Jenkins 4 Henry 21/Thomas 8/Roberts 5 31 Festus Ezeli C 6-11 255 10/21/89 Vanderbilt/Nigeria R 23 Draymond Green F 6-7 230 3/4/90 Michigan State/USA R WARRIORS SUMMER LEAGUE STATS 22 Charles Jenkins G 6-3 220 2/28/89 Hofstra/USA 1 PLAYER G GS MIN FGM FGA PCT 3FGM 3FGA PCT FTM FTA PCT OFF DEF TOT AST PF DQ STL TO BLK PTS AVG Klay Thompson 2 2 59 14 27 .519 10 14 .714 3 4 .750 2 10 12 9 5 0 3 9 3 41 20.5 52 Dallas Lauderdale F 6-8 260 9/11/88 Ohio State/USA R Harrison Barnes 5 5 168 30 76 .395 8 14 .571 16 22 .727 10 18 28 2 11 0 9 7 0 84 16.8 21 Joe Ragland G 6-0 185 11/11/89 Wichita State/USA R Charles Jenkins 5 5 139 22 43 .512 0 2 .000 27 28 .964 0 7 7 14 6 0 8 14 0 71 14.2 -

Senate the Senate Met at 10 A.M
E PL UR UM IB N U U S Congressional Record United States th of America PROCEEDINGS AND DEBATES OF THE 112 CONGRESS, SECOND SESSION Vol. 158 WASHINGTON, TUESDAY, JUNE 26, 2012 No. 97 Senate The Senate met at 10 a.m. and was COONS, a Senator from the State of Dela- We have accomplished a lot. Every- called to order by the Honorable CHRIS- ware, to perform the duties of the Chair. one knows how grateful I am to Sen- TOPHER A. COONS, a Senator from the DANIEL K. INOUYE, ators STABENOW and ROBERTS for work- State of Delaware. President pro tempore. ing their way and our way through Mr. COONS thereupon assumed the that very difficult farm bill. PRAYER chair as Acting President pro tempore. We are watching very closely the The Chaplain, Dr. Barry C. Black, of- f great work of Senator BOXER, Senator fered the following prayer: INHOFE, the Finance Committee, the RECOGNITION OF THE MAJORITY Commerce Committee, and the Bank- Let us pray. LEADER Gracious God, You have been faithful ing Committee on helping us work to help us when we have lifted our The ACTING PRESIDENT pro tem- through the highway bill. There is a possibility that we can get that bill hearts in prayer. Thank You for Your pore. The majority leader is recog- done. I think the chances today are providential care of this legislative nized. better than 50–50 that we can get a bill body. Open the eyes and hearts of our f done, but we are still looking at Speak- lawmakers so that they will know and SCHEDULE er BOEHNER to help us get that over the do Your will. -

2017 -2018 RGV VIPERS MEDIA GUIDE 2017-18 Rio Grande Valley Vipers Records Guide TABLE of CONTENTS TABLE of CONTENTS
2017 -2018 RGV VIPERS MEDIA GUIDE 2017-18 Rio Grande Valley Vipers Records Guide TABLE OF CONTENTS TABLE OF CONTENTS .............................................................................................................................................................................. 2 RGV VIPERS 2017-18 QUICK FACTS ....................................................................................................................................................... 3 ABOUT THE RIO GRANDE VALLEY VIPERS ........................................................................................................................................... 4 RGV VIPERS MEDIA RELATIONS ............................................................................................................................................................ 5 RGV VIPERS 2017-18 SCHEDULE ........................................................................................................................................................... 6 2017-18 RGV VIPERS ROSTER ................................................................................................................................................................ 7 RGV VIPERS 2015-16 ROSTER – MEET THE TEAM ............................................................................................................................... 8 RGV VIPERS COACHING STAFF .......................................................................................................................................................... -

Wade Elects for Surgery, Health Over Olympics
Wade elects for surgery, health over Olympics 3 out of 5 Make Scary good Now what? stars yourself at home Wade elects for surgery, health over Olympics HEADLINES HEAT FS FL FS.COM Bosh at center could give Heat 3 All-Star starters Allen not bothered by barbs from Celtics Dwyane Wade says he is in the process of scheduling surgery and will not be Healing, re-tooled Heat want to healthy enough for the Olympics. (Alan Diaz/Associated Press) win again LeBron James won't lack for ARCHIVE | EMAIL motivation Chris Tomasson is a general assignment columnist for FOX Sports and FOX Sports Florida, bringing fans an inside look at their Juwan Howard's agent hopeful favorite teams in South Florida. Chris spent the last decade for Heat return covering the NBA, most recently as a Senior NBA writer for AOL Like Bosh puts injury behind as camp 166 FanHouse. opens Dooling confirms retirement, no interest in Heat Like Tweet 41 Recommend comment(0) email print Facebook Miami Heat sign center Josh Harrellson June 28, 2012 LeBron James hires longtime MIAMI — Miami guard Dwyane Wade is out of the London Games, and his Olympic career is over. friend as agent Wade, who battled a left knee problem during the playoffs while helping the Heat to the title, called Heat sign Terrel Harris to non- USA Basketball Chairman Jerry Colangelo and coach Mike Krzyzewski on Thursday to tell them he guaranteed deal would be dropping out of the games due to needing knee surgery. Wade, a 2004 bronze medalist and 2008 gold medalist, had first told FOX Sports Florida last January the London Olympics would be his last. -

The Value of a Basketball Player
1 The value of a basketball player J.A.Hartigan Yale University September 2013 1 Money In 2012-2013, the top salary in the National Baseball Association was 30 million dollars for Kobe Bryant, Los Angeles Lakers; the top ten player each receive more than 18 million dollars. The starting salary for a rookie player was 0.5 million dollars. The EWA( Estimated Wins Added) is a statistic developed by John Hollinger that puts the price of a win at 1.6 million dollars, and estimates for each player how many wins he adds to a team. His salary is regarded as good for the team if the number of wins added multiplied by 1.6 million exceeds his salary. See http://www.sonicscentral.com/statsite.html as a source for many different theoretical approaches to basketball. Many of them are based on "play by play" statistics, the basketball events that occur during each "matchup" between a particular 5 players on one team with a particular 5 players on the other team. The play by play data is available up to the end of the 2012 season at http://basketballvalue.com/downloads.php We develop a value measure predicting each player’s contribution to the point difference between his team’s score and the opponent’s team score, after adjusting for home court advantage and possession advantage. This statistic is routinely produced for evaluating players, for example, at http://www.82games.com/1112/1112NYK1.HTM. 2 We copy and paste the following partial table for 6 March 2012. The production scores are for a 48 minute game. -

Kyrie Irving 0
2. 2. 2. 2. 1. 2.2 2. 1. 2. 2.2 1. 1. 1. 2. 1. 0 9 0 1. 2.5 2. 0 0 9 7 1 1. 2.5 1 7 7 2. 7 1.5 2.8 3 7 1.5 3 6 2.8 1. 2.8 7 1. 2. 4 1. 4 2. 1. A. 3. 9 1. Dann DeAndr Wi 1 Ta Jamaal Da DeS 1. 0 Bi Ed Scot | Power forward 9 Jo | Point guard Jerry All-LeBron Team Br All-LeBron Team Juw 0 3. 0 Joel 0. J. Darnell 3. Bruno 0 Ze lly re 0. 3. Jer Alan dy vid sh 1 ll Lo 9 Erick Pr 0. 3 Dw 3. Lu endan agana Mik nc 9 5 Joe ndon 0. Scot t 3. an y Th St Cherry ome re 8 5 0. ic An Michael De Harr ke Cu St Wi 7 4 We 3. Jiri Tr e Gr 0. 5 ay e Lanc ephen nz e Magloir 6 3. Gr Hender omas e 0. 7 xt Sundo Ho Lo Ro thon ackhous Ki ey rry Harris Jacks Dampier 4 11. 3. Ale KEVIN LOVE een ne Liggins lliams Jacks KYRIE IRVING 0. 7 Wi Te We en eg sle Po Deme 3 4. Hamilt ells er Mois Ben ns uis 8 ger wa 0. Diop Cedric Johns 3 4. Ro Ha .4 e 0 rr 0.0 x Jone Ka llar lks y Wr Pi 2 Jas Oden ey The Cavs’ fourth- ls y At this stage, it’s Jarvis 4.