Microelectronic Systems Albert Heuberger • Günter Elst • Randolf Hanke Editors
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
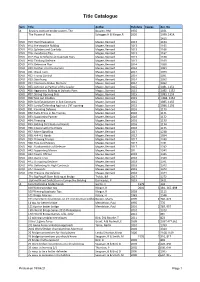
WABC Library by Title April 2021
Title Catalogue Sym Title Author Pub date Copies Acc. No A Beasley contract bridge system, The Beasley, HM 1935 1031 The Power of Pass Schogger,H & Klinger,R 2020 1399, 1414, 1415 DVD #13: Hand Evaluation Magee, Bernard 2013 1164 DVD #14: Pre-emptive Bidding Magee, Bernard 2013 1165 DVD #15: Splinters and Cue-bids Magee, Bernard 2013 1166 DVD #16: Avoidance Play Magee, Bernard 2013 1167 DVD #17: Play & Defence at Duplicate Pairs Magee, Bernard 2013 1168 DVD #18: Thinking Defence Magee, Bernard 2013 1169 DVD #19: Defensive Plan Magee, Bernard 2014 1088 DVD #20: Further into the Auction Magee, Bernard 2014 1089 DVD #21: Weak Twos Magee, Bernard 2014 1090 DVD #22: Trump Control Magee, Bernard 2014 1091 DVD #23: Sacrificing Magee, Bernard 2014 1092 DVD #24: Improving Bridge Memory Magee, Bernard 2014 1093 DVD #25: Defence as Partner of the Leader Magee, Bernard 2015 2 1081, 1151 DVD #26: Aggressive Bidding at Dulicate Pairs Magee, Bernard 2015 2 1082, 1152 DVD #27: Strong Opening Bids Magee, Bernard 2015 2 1083, 1153 DVD #28:Take out Doubles Magee, Bernard 2015 2 1084, 1154 DVD #29: Suit Establisment in Suit Contracts Magee, Bernard 2015 1085, 1155 DVD #30: Landy/Defending Against a 1NT opening Magee, Bernard 2015 2 1086, 1156 DVD #31: Counting Defence Magee, Bernard 2016 1170 DVD #32: Extra Tricks in No-Trumps Magee, Bernard 2016 1171 DVD #33: Supporting Partner Magee, Bernard 2016 1172 DVD #34; Finessing Magee, Bernard 2016 1173 DVD #35: Bidding Distributional Hands Magee, Bernard 2016 1174 DVD #36: Coping with Pre-Empts Magee, Bernard -

OTHER OPENING BIDS 1 15+ 0 15+, Any Distribution (A) 1 9-14 4
OTHER OPENING BIDS COMPETITIVE AUCTIONS Agreements after opening of one of a suit and overcall by opponents HCP see Min CONVENTIONAL SPECIAL Notes Note length MEANING RESPONSES Level to which negative doubles apply All levels 1♣ 15+ F 0 15+, any distribution (a) Special meaning of bids Natural, forcing 1♦ 9-14 F 4♥ 4+♥, possible canapé (b) Exceptions / other agreements 1♦ – (1♥) – X, 1♥ – (1♠) – X = relays 1♥ 9-14 F 4♠ 4+♠, possible canapé (c) 1♦ – (1♠) – X/2♣/2♦ = transfers 1♠ 9-14 F 4♦ 6+♦ or 5/4 in minors (d) Agreements after opponents double for takeout: See note (m) 3 bids Pre F 6 minor bids constructive (l) Redouble New suit Jump in new suit 4 bids Pre F 6 Jump raise 2NT Other *(Please enter your normal HCP range in the HCP column. Please tick box if you have any special agreements involving different values in particular positions (e.g. light openings in third seat) and include Other agreements concerning doubles and redoubles further details under Supplementary Details). Double generally for takeout until a fit has been found. See also note (g) DEFENSIVE METHODS AFTER OPPONENTS OPEN Lead directing doubles of slams and 3NT, asking for an unusual lead. OPPONENTS OPEN A CONVENTIONAL SPECIAL Notes NATURAL ONE OF A SUIT MEANING RESPONSES (1♥)-1♠-(2♣)-X shows a minimum raise but is anti-lead directional if 2♣ is F. Simple overcall Natural (1♥)-2♠-(3♣/3♥)-X suggests partner sacrifice if suitable (when 3♣ is F). Jump overcall Weak OTHER CONVENTIONS Cue bid Michaels 3NT opening shows a quality 7+ card major with little outside. -

Health Care and Satellite Radio Communication in Village Alaska
DOCUMENT RESUME ED 094.721 IR 000 917 AUTHOR Kreimer, Osvaldo; And Others TITLE Health Care and Satellite Radio Communication in Village Alaska. Final Report of the ATS-1 Biomedical Satellite Experiment Evaluation. INSTITUTION Lister Hill National Center for Biomedical Communications, Bethesda, Md.; Stanford Univ., Calif. Inst. for Communication Research. SPONS AGENCY National Library of Medicine (DHEW), Bethesda, Md. PUB DATE Jun 74 NOTE 429p. EDRS PRICE MF-$0.75 HC-$21.00 PLUS POSTAGE DESCRIPTORS *Communication Satellites; Equipment Evaluation; Health Conditions; Health Education; Health Facilities; Health Needs; Health Programs; *Health Services; Medical Evaluation; Medical Services; *Program Evaluation; *Radio; Telecommunication IDENTIFIERS *Alaska; ATS 1; Health Aides ABSTRACT The executive summary is the first section of this final report of the evaluation of the ATS-1 medical communication system in Alaska. The second section introduces the background of these studies and the sociogeographic setting and health situation of the Alaska natives. The third section presents the main research findings about both the aides-to-doctor and doctor-to-doctor exchanges, about use of the system for medical education, and about its social impact on Bush Alaska. A fourth section is devoted to a cost analysis of alternative systems and recommendations. The attachments (charts, tables, data gathering instruments, etc.). comprise a fifth section. (WCM) HEALTH CARE AND SATELLITERADIO commuNICATION IN V1ILACE ALASKA Final Report of the ATS-I Biomedical Satellite Experiment Evaluation a report of the INSTITUTE FOR COMMUNICATION RESEARCH STANFORD UNIVERSITY U S DERARTN5ENIOf HEALTM. EVOCATION & WELFARE NATION AL INSTItutE Of COUCATiON 0C7C. VINT rya'., ;LEN REPRO 0 ExaCILY RECtrvED FROM ,At s't RSON CR OR3AN,ZATION ORIGIN ! NT y CO. -

Perceptual Audio Coding
Perceptual Audio Coding Sources: Kahrs, Brandenburg, (Editors). (1998). ”Applications of digital signal processing to audio and acoustics”. Kluwer Academic. Bernd Edler. (1997). ”Low bit rate audio tools”. MPEG meeting. Contents: q Overview of perceptual q Introduction audio coding q Requiremens for audio q Description of coding tools codecs q Filterbankds q Perceptual coding vs. q Perceptual models source coding q Quantization and coding q Measuring audio quality q Stereo coding q Facts from psychoacoustics q Real coding systems 1 Introduction n Transmission bandwidth increases continuously, but the demand increases even more à need for compression technology n Applications of audio coding – audio streaming and transmission over the internet – mobile music players – digital broadcasting – soundtracks of digital video (e.g. digital television and DVD) Requirements for audio coding systems n Compression efficiency: sound quality vs. bit-rate n Absolute achievable quality – often required: given sufficiently high bit-rate, no audible difference compared to CD-quality original audio n Complexity – computational complexity: main factor for general purpose computers – storage requirements: main factor for dedicated silicon chips – encoder vs. decoder complexity • the encoder is usually much more complex than the decoder • encoding can be done off-line in some applications Requirements (cont.) n Algorithmic delay – depending on the application, the delay is or is not an important criterion – very important in two way communication (~ 20 ms OK) – not important in storage applications – somewhat important in digital TV/radio broadcasting (~ 100 ms) n Editability – a certain point in audio signal can be accessed from the coded bitstream – requires that the decoding can start at (almost) any point of the bitstream n Error resilience – susceptibility to single or burst errors in the transmission channel – usually combined with error correction codes, but that costs bits Source coding vs. -

Recommendations and Reports of the CCIR (Dubrovnik, 1986)
This electronic version (PDF) was scanned by the International Telecommunication Union (ITU) Library & Archives Service from an original paper document in the ITU Library & Archives collections. La présente version électronique (PDF) a été numérisée par le Service de la bibliothèque et des archives de l'Union internationale des télécommunications (UIT) à partir d'un document papier original des collections de ce service. Esta versión electrónica (PDF) ha sido escaneada por el Servicio de Biblioteca y Archivos de la Unión Internacional de Telecomunicaciones (UIT) a partir de un documento impreso original de las colecciones del Servicio de Biblioteca y Archivos de la UIT. (ITU) ﻟﻼﺗﺼﺎﻻﺕ ﺍﻟﺪﻭﻟﻲ ﺍﻻﺗﺤﺎﺩ ﻓﻲ ﻭﺍﻟﻤﺤﻔﻮﻇﺎﺕ ﺍﻟﻤﻜﺘﺒﺔ ﻗﺴﻢ ﺃﺟﺮﺍﻩ ﺍﻟﻀﻮﺋﻲ ﺑﺎﻟﻤﺴﺢ ﺗﺼﻮﻳﺮ ﻧﺘﺎﺝ (PDF) ﺍﻹﻟﻜﺘﺮﻭﻧﻴﺔ ﺍﻟﻨﺴﺨﺔ ﻫﺬﻩ .ﻭﺍﻟﻤﺤﻔﻮﻇﺎﺕ ﺍﻟﻤﻜﺘﺒﺔ ﻗﺴﻢ ﻓﻲ ﺍﻟﻤﺘﻮﻓﺮﺓ ﺍﻟﻮﺛﺎﺋﻖ ﺿﻤﻦ ﺃﺻﻠﻴﺔ ﻭﺭﻗﻴﺔ ﻭﺛﻴﻘﺔ ﻣﻦ ﻧﻘﻼ ً◌ 此电子版(PDF版本)由国际电信联盟(ITU)图书馆和档案室利用存于该处的纸质文件扫描提供。 Настоящий электронный вариант (PDF) был подготовлен в библиотечно-архивной службе Международного союза электросвязи путем сканирования исходного документа в бумажной форме из библиотечно-архивной службы МСЭ. © International Telecommunication Union INTERNATIONAL TELECOMMUNICATION UNION CCIR INTERNATIONAL RADIO CONSULTATIVE COMMITTEE RECOMMENDATIONS AND REPORTS OF THE CCIR, 1986 (ALSO QUESTIONS, STUDY PROGRAMMES, RESOLUTIONS, OPINIONS AND DECISIONS) XVIth PLENARY ASSEMBLY DUBROVNIK, 1986 VOLUMES X AND XI - PART 2 BROADCASTING-SATELLITE SERVICE (SOUND AND TELEVISION) Geneva, 1986 CCIR 1. The International Radio Consultative Committee (CCIR) is the permanent organ of the International Telecommunication Union responsible under the International Telecommunication Convention "... to study technical and operating questions relating specifically to radiocommunications without limit of frequency range, and to issue recommendations on them..." (Inter national Telecommunication Convention, Nairobi 1982, First Part, Chapter I, Art. -

Library Catalogue (January 2015) – Bunbury Bridge Club
Library Catalogue (January 2015) – Bunbury Bridge Club No. Author Title Comment AAA Duplicate decisions: club director’s guide 264 Amsbury Bridge conventions: control asking 244 Berthe & Lebely Step by step card play: No Trumps Bird & Bourke Defending No Trump contracts Bird & Bourke Planning No Trump contracts 340 Borin & Borin Our precision style (X2) 226 Cayley Contract Bridge bidding 316 Chua The history of Australian Bridge (X2) 201 Coffin Bridge play from A to Z 287 Cohen Basic Acol Acol 332 Cohen & Lederer The ABC of Contract Bridge 154 Cohen & Lederer All about Acol (X5) Acol 287 Cohen & Lederer Basic Acol Acol 228 Corn Play Bridge with the aces 248 Cotter The Financial Times book of Bridge 296 Cotter & Bridge play technique Rimington Crawford Men, Women & Bridge Culbertson Contract Bridge blue book 238 Culbertson Contract Bridge complete Culbertson Contract Bridge for everyone 236 Culbertson Contract Bridge made easy (X2) Culbertson Summary of Contract Bridge 326 Darvas & Hart Right through the pack 265 Darvas & Lukacs Spotlight on card play 308 Dutton Moscito Farrington Duplicate Bridge movements 210 Feldheim The weak two bid in Bridge Flint & North Bridge in the looking glass 266 Flint & North Bridge: the golden principles Francis, Francis The official encyclopedia of & Truscott Bridge 241 Fox Standard bidding 257 Gardner & Mollo Card play technique Goren Better Bridge for better players 233 Goren Bridge is my game Goren Championship Bridge 234 Goren Goren’s Bridge quizzes 218 Goren Goren’s Bridge complete Goren Goren’s New -

Forschungszentrum Karlsruhe in Der Helmholtz-Gemeinschaft Wissenschaftliche Berichte FZKA 6774
Forschungszentrum Karlsruhe in der Helmholtz-Gemeinschaft Wissenschaftliche Berichte FZKA 6774 Optimierung von Mikro- systemen für Diagnose- und Überwachungsanwendungen (Abschlussseminar des BMBF-Verbundprojektes OMID) Karlsruhe, 25. und 26. November 2002 H. Eggert, A. Reiffer (Hrsg.) Institut für Angewandte Informatik November 2002 Forschungszentrum Karlsruhe in der Helmholtz-Gemeinschaft Wissenschaftliche Berichte FZKA 6774 Optimierung von Mikrosystemen für Diagnose- und Überwachungsanwendungen (Abschlußseminar des BMBF-Verbundprojektes OMID) Karlsruhe, 25. und 26. November 2002 H. Eggert, A. Reiffer*) (Herausgeber) Institut für Angewandte Informatik *) InterConnect Software GmbH Am Fächerbad 3 67131 Karlsruhe Forschungszentrum Karlsruhe GmbH, Karlsruhe 2002 Für diesen Bericht behalten wir uns alle Rechte vor Forschungszentrum Karlsruhe GmbH Postfach 3640, 76021 Karlsruhe Mitglied der Hermann von Helmholtz-Gemeinschaft Deutscher Forschungszentren (HGF) ISSN 0947-8620 Optimierung von Mikrosystemen für Diagnose- und Überwachungsanwendungen (Abschlußseminar des BMBF-Verbundprojektes OMID) Zusammenfassung Im BMBF-Verbundprojekt OMID (Optimierung von MIkrosystemen für Diagnose- und Über- wachungsanwendungen) wurden Methoden und Werkzeuge zur automatisierten Designoptimie- rung entwickelt und an fünf innovativen vorwettbewerblichen Entwicklungen aus der Mikrosys- temtechnik erfolgreich erprobt. Modellbildung, Simulation und Optimierung lieferten qualitativ verläßliche Designs und diese ermöglichten wiederum eine gezielte Herstellung von Labormustern -

Addendum User Manual Jack
MOSCITO 2005 The system with a bite Legend An=anchor; A=ask; CB=cuebid; M=major; m=minor; 2/1 is F1, N. It shows at least some interest in game. bal=balanced; Sh=Shortage; INV = invitation; R=relayer; However, responder’s next bid is NF. Eg: RR=relay Responder; RevR=reverse relay;w=with; 1}: 2{, 2}:2] ]QJxxx [x }x {AQxxxx N=natural. FS=fit showing; St=stopper; S=Step; H=HCP; 1[:2}, 2[:2] ]Kxx [xx }AJxxx {Qxx TS=trump suit. MS=mid shortage. SL=5+&4. LL=55+. 1}:2{, 2[:3{ ]Kx [x }Qxx {AQJxxxx 1[:2{, 2}:2NT ]xx [QJxx }xx {AKJxx 1. OPENING BIDS All continuations are natural, inc 4th suit. 1st & 2nd Opener’s weakest rebid is rebidding the M. e.g ]Q8654 1{= 15+H. [K65 }K4 {A43 1[:2{, bid 2], not 3{. With <15 H, 1}= 4+[& 1[= 4+S. Use rule of 19 w 5M & rule O’s JS is 55. Double jump is spl. 3m shows 5 (maybe 5-5). of 20 w no 5M. Open in longest suit unless 4M & 5m. W 2N is max with 5+M, no 5m. 3N is max no 5. 4M432 or 4M333, open in M with 13-14 & 1N w 11-12. 1] 6} & maybe 4M or 5-4+ {&}, 12-14 H if 5/5 Continuations 1N 11-14 bal. (if 4M, then 11-12 H). 1. 1}:2[, 2] =6331 type GT (2N=GT in ]) - step asks for 2{ 6+{ and maybe 4M (not 4}) shortage. 3X=LSGT; 1[:2], 2N is same. -

Report Describes the Workings of the Project Group: H.264 Codec
Just In Time Joint Encoding of Multiple Video Streams Master's thesis Henrik Juul Pedersen & Palle Ravn June 6, 2013 Department of Electronic Systems Fredrik Bajers Vej 7 DK-9220 Aalborg Øst Phone: +45 96 35 86 00 Internet: es.aau.dk Title: Just In Time Joint Encoding of Multiple Video Streams Theme: Synopsis: Master's thesis This master's thesis focuses on H.264 video compression of multiple streams Project period: to be transmitted over a limited channel. September 2012 - june 2013 The report describes the workings of the Project group: H.264 codec. Afterwards, proposals on 13gr1071 bitrate estimators are presented, and a predictor is chosen for later use in rate Members of the group: control. We design a rate controller set Henrik Juul Pedersen up as a constrained convex optimization Palle Ravn problem, and test it against a set of video sequences. Supervisors: Our results show that it is possible to Jan Østergaard encode video sequences jointly with re- Søren Holdt Jensen gard to their individual qualities, whilst Number of copies: 5 still keeping fluctuations in quality low. We conclude, that if a Just-In-Time en- Number of pages: 69 coder is created with regard to our pro- posed rate controller and bitrate predic- Attachments: CD tion, it could be used in realtime joint Appendices: 1 video coding. Project completed: June 6, 2013 Contents of this report is freely available but publication (with specification of source) may only be done upon arrangement with the authors. Institut for Elektroniske Systemer Fredrik Bajers Vej 7 9220 Aalborg Øst Telefon: 96 35 86 00 Internet: es.aau.dk Titel: Just In Time Joint Encoding of Multiple Video Streams Synopsis: Tema: Dette kandidatspeciale fokuserer p˚a Kandidatspeciale H.264 video komprimering af flere video Projektperiode: strømme til transmission over en be- September 2012 - juni 2013 grænset kanal. -

Instruktion Till Ifyllning Av SBF:S Systemdeklaration (”Blå Klubbversionen”)
Instruktion till ifyllning av SBF:s systemdeklaration (”blå klubbversionen”) vid tävlingar i Svenska Bridgeförbundet (Publicerad: 2021-07-06) 2021-07-01 | SVENSKA BRIDGEFÖRBUNDET | 1 av 7 INSTRUKTION TILL IFYLLNING AV SYSTEMDEKLARATION INNEHÅLLSFÖRTECKNING FÖRÄNDRINGAR SEDAN FÖRSTA PUBLICERING 2021-07-05 2 Slamkonventioner........................................................6 SYSTEMDEKLARATIONEN ............................................... 3 Övriga konventioner .................................................... 6 Syfte............................................................................. 3 Försvarsbud..................................................................6 Tillgänglighet................................................................ 3 Övriga försvarskonventioner........................................6 Språk............................................................................ 3 Utspel ........................................................................... 6 Tomma deklarationskort/Mallar ................................. 3 Vändor..........................................................................7 SYSTEMBESKRIVNING.................................................... 3 Markeringar .................................................................7 Allmänt ........................................................................ 3 Dubblingar....................................................................7 Prickar.......................................................................... 4 Öppningsbud -

Universal Transmission and Compression: Send the Model? Aline Roumy
Universal transmission and compression: send the model? Aline Roumy To cite this version: Aline Roumy. Universal transmission and compression: send the model?. Signal and Image processing. Université Rennes 1, 2018. tel-01916058 HAL Id: tel-01916058 https://hal.inria.fr/tel-01916058 Submitted on 8 Nov 2018 HAL is a multi-disciplinary open access L’archive ouverte pluridisciplinaire HAL, est archive for the deposit and dissemination of sci- destinée au dépôt et à la diffusion de documents entific research documents, whether they are pub- scientifiques de niveau recherche, publiés ou non, lished or not. The documents may come from émanant des établissements d’enseignement et de teaching and research institutions in France or recherche français ou étrangers, des laboratoires abroad, or from public or private research centers. publics ou privés. ANNEE´ 2018 HDR / UNIVERSITE´ DE RENNES 1 sous le sceau de l'Universit´eBretagne Loire Domaine : Signal, Image, Vision Ecole doctorale MathSTIC pr´esent´ee par Aline ROUMY pr´epar´eeau centre de recherche de Inria Rennes-Bretagne Atlantique soutenue `aRennes Universal le 26 novembre 2018 devant le jury compos´ede : transmission and Giuseppe CAIRE Professeur, TU Berlin / rapporteur compression: Pierre DUHAMEL DR, CNRS L2S / rapporteur send the model? B´eatricePESQUET-POPESCU Directrice Recherche Innovation, Thal`es/ rapportrice Inbar FIJALKOW Professeure, ENSEA / examinatrice Claude LABIT DR, Inria Rennes / examinateur Philippe SALEMBIER Professeur, UPC Barcelona / examinateur Vladimir STANKOVIC Professeur, Univ. Strathclyde, Glasgow / examinateur 2 Contents 1 Introduction5 2 Compression and universality9 2.1 Lossless data compression............................9 2.2 Universal source coding and its theoretical cost................ 11 2.3 Universal source coding in a wide set of distributions: the model selection problem and the minimum description length principle. -

Terr Mosc.Pdf
1 Terrorist's Moscito, or Major-Oriented Strong Club, with Intrepid Two Openers A Primer on Advanced System Construction Professor Bo-Yin Yang, a.k.a. terrorist Contributing authors: Dept. of Mathematics, Tamkang University Ruey-Lun Lin, Hsinchu Tamsui, Taipei County, Taiwan (25137) Jessica Y. Lee, Hsinchu [email protected], http://moscito.org David Morgan, Canberra March 28, 2000 Contents 1 Introduction 7 1.1 General Philosophy . 7 1.1.1 Action and Adventure . 7 1.1.2 Bondage vs. Discipline . 7 1.1.3 Canap´e:Fours, Fives, and mafia ......................................... 8 1.1.4 Distinct Design: Pride and Price . 8 1.1.5 Extremism or Moderation? . 9 1.1.6 Fixation on Fibonacci: on Relays . 9 1.2 History of Moscito . 9 1.2.1 The Symmetric Relay . 9 1.2.2 From Forcing Pass to Moscito . 9 1.2.3 A Unified Approach in Competition . 9 2 General Constructive Structures 10 2.1 No-trump Structures: Overview . 11 2.1.1 Development over 1N ................................................ 11 2.1.2 Normal bidding over limited 1N .......................................... 11 2.2 Choice of Contracts . 11 2.3 Slam Bidding: asking bids . 11 2.4 Slam Bidding: cue-bids . 11 3 Defensive Bidding 12 3.1 In 2nd chair over 1-level opening . 13 3.1.1 By hand-type: 2nd seat, 1-level . 13 3.1.2 By-call: 2nd seat, 1-level . 13 3.1.3 Adjustments for special circumstances . 14 3.2 Developing a 1-level Overcall . 14 3.2.1 Advancing a 1-level overcall . 14 3.2.2 Advancing over a \negative" double .