Center for Studies in Demography and Ecology
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

An Exploratory Study of Factors Influencing Examing-Into Xuchang University Ming Guan
Available online at www.sciencedirect.com ScienceDirect Procedia - Social and Behavioral Sciences 116 ( 2014 ) 2664 – 2669 5th World Conference on Educational Sciences - WCES 2013 An exploratory study of factors influencing examing-into Xuchang University Ming Guan School of Economics,Henan University, Kaifeng and 475004,China Xuchang University,, Xuchang and 461000,China Abstract This case study seeks to explain why students choose to pursue advanced education at Xuchang University, and to assess the strengths and dynamics of the factors influencing the enrollment decision. This study used a combination of quantitative and qualitative research methods to explain the factors and process. Quantitative data from a survey questionnaire were used to identify the factors and to measure their significance in influencing or determining the choice of Xuchang University. Qualitative data from in-person interviews were used to gain insights into how freshmen decide to pursue higher education at Xuchang University. The research findings reveal the significant influence of academic, economic, environmental, and job offer /settledown pulling factors as well as a set of negative pushing factors. This research suggests that to attract top freshmen, Xuchang University should focus on investing in research and ensuring the quality of higher education, while crafting a strategy to enhance awareness of and the overall image of their higher education institutions and programs. © 2013 The Authors. Published by Elsevier Ltd. Selection and/or peer-review under responsibility of Academic World Education and Research Center. Keywords: Higher education, enrollment, decision-making, Xuchang University 1. Introduction Xuchang University (XU), located in Xuchang City which is a medium-sized city far from the capital of Henan Province. -

54401-001: Asia Cube Wastewater Treatment Upgrade Project
Environment and Social Compliance Audit Report Project Number: 54401-001 Asset-Level Report - Yongcheng No. 2 April 2021 People’s Republic of China: Asia Cube Wastewater Treatment Upgrade Project Prepared by Stantec Environmental Engineering (Shanghai) Co., Ltd. (“Stantec”) for the China Cube Water Company (the “Client”) and the Asian Development Bank. This environment and social compliance audit report is a document of the borrower. The views expressed herein do not necessarily represent those of ADB's Board of Directors, Management, or staff, and may be preliminary in nature. In preparing any country program or strategy, financing any project, or by making any designation of or reference to a particular territory or geographic area in this document, the Asian Development Bank does not intend to make any judgments as to the legal or other status of any territory or area. ASSET-LEVEL E&S AUDIT REPORT – YONGCHENG NO.2 This document entitled Asset-level E&S audit report – Yongcheng No.2 was prepared by Stantec Environmental Engineering (Shanghai) Co., Ltd. (“Stantec”) for the account of China Cube Water Limited (the “Client”). Any reliance on this document by any third party is strictly prohibited. The material in it reflects Stantec’s professional judgment in light of the scope, schedule and other limitations stated in the document and in the contract between Stantec and the Client. The opinions in the document are based on conditions and information existing at the time the document was published and do not take into account any subsequent changes. In preparing the document, Stantec did not verify information supplied to it by others. -
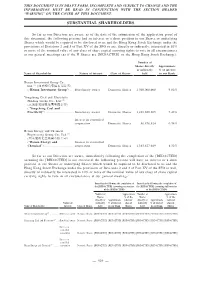
Substantial Shareholders
THIS DOCUMENT IS IN DRAFT FORM, INCOMPLETE AND SUBJECT TO CHANGE AND THE INFORMATION MUST BE READ IN CONJUNCTION WITH THE SECTION HEADED “WARNING” ON THE COVER OF THIS DOCUMENT. SUBSTANTIAL SHAREHOLDERS So far as our Directors are aware, as of the date of the submission of the application proof of this document, the following persons had an interest or a short position in our Shares or underlying Shares which would be required to be disclosed to us and the Hong Kong Stock Exchange under the provisions of Divisions 2 and 3 of Part XV of the SFO or are, directly or indirectly, interested in 10% or more of the nominal value of any class of share capital carrying rights to vote in all circumstances at our general meetings (as if the H Shares are [REDACTED] on the Hong Kong Stock Exchange): Number of Shares directly Approximate or indirectly % of interest Name of Shareholder Nature of interest Class of Shares held in our Bank Henan Investment Group Co., Ltd.(1) (河南投資集團有限公司) (“Henan Investment Group”) .... Beneficiary owner Domestic Shares 1,500,000,000 9.02% Yongcheng Coal and Electricity Holding Group Co., Ltd.(2) (永城煤電控股集團有限公司) (“Yongcheng Coal and Electricity”) .............................. Beneficiary owner Domestic Shares 1,232,960,305 7.42% Interest in controlled corporation Domestic Shares 56,876,624 0.34% Henan Energy and Chemical Engineering Group Co., Ltd.(3) (河南能源化工集團有限公司) (“Henan Energy and Interest in controlled Chemical”)................................. corporation Domestic Shares 1,383,827,049 8.32% So far as our Directors -

Interim Report 2005 Characteristics of the Growth Enterprise Market (“Gem”) of the Stock Exchange of Hong Kong Limited (The “Stock Exchange”)
(incorporated in the Cayman Islands with limited liability) (Stock Code: 8070) INTERIM REPORT 2005 CHARACTERISTICS OF THE GROWTH ENTERPRISE MARKET (“GEM”) OF THE STOCK EXCHANGE OF HONG KONG LIMITED (THE “STOCK EXCHANGE”) GEM has been established as a market designed to accommodate companies to which a high investment risk may be attached. In particular, companies may list on GEM with neither a track record of profitability nor any obligation to forecast future profitability. Furthermore, there may be risks arising out of the emerging nature of companies listed on GEM and the business sectors or countries in which the companies operate. Prospective investors should be aware of the potential risks of investing in such companies and should make the decision to invest only after due and careful consideration. The greater risk profile and other characteristics of GEM mean that it is a market more suited to professional and other sophisticated investors. Given the emerging nature of companies listed on GEM, there is a risk that securities traded on GEM may be more susceptible to high market volatility than securities traded on the Main Board and no assurance is given that there will be a liquid market in the securities traded on GEM. The principal means of information dissemination on GEM is publication on the internet website at www.hkgem.com operated by the Stock Exchange. Listed companies are not generally required to issue paid announcements in gazetted newspapers. Accordingly, prospective investors should note that they need to have access to the GEM website in order to obtain up-to-date information on GEM-listed issuers. -

Enzyme Activity and Morphological Change in the Spleens of Crucian Carp in the Yongcheng Coal Mine Subsidence Area, China
Enzyme activity and morphological change in the spleens of crucian carp in the Yongcheng coal mine subsidence area, China Y.F. Yan1, J.Y. Yang2 and J.Y. Lin2 1School of Life Sciences, Shangqiu Normal University, Shangqiu, Henan, China 2School of Physical Education, Henan Normal University, Xinxiang, Henan, China Corresponding author: J.Y. Yang E-mail: [email protected] Genet. Mol. Res. 15 (2): gmr.15027782 Received December 14, 2015 Accepted January 15, 2016 Published April 26, 2016 DOI http://dx.doi.org/10.4238/gmr.15027782 ABSTRACT. The goal of the current study was to investigate the effects of pollution on aquatic organisms in the Yongcheng coal mine subsidence area. Crucian carp (Carassius auratus) were collected from Yongcheng natural fishpond (experimental group) and Tianmu Lake (control group), and the spleens were isolated for analysis. Subsequently, histological changes, DNA damage, and antioxidant enzyme activity were assessed. The result showed that there were more vacuoles, widened blood sinus cavities, increased partial dot necrosis, and a larger number of brown-yellow nodules in splenic sections stained with hematoxylin and eosin in the experimental group than in the control group. Additionally, it was not easy to distinguish red pulp from white pulp in the experimental group. The antioxidant enzyme activity in the experimental group was significantly lower than that in the control group (P < 0.01). Comet assay results showed varying degrees of tailing and DNA chain breaks in the experimental group, and further analysis demonstrated that the tail length and tail moment Genetics and Molecular Research 15 (2): gmr.15027782 ©FUNPEC-RP www.funpecrp.com.br Y.F. -

Addition of Clopidogrel to Aspirin in 45 852 Patients with Acute Myocardial Infarction: Randomised Placebo-Controlled Trial
Articles Addition of clopidogrel to aspirin in 45 852 patients with acute myocardial infarction: randomised placebo-controlled trial COMMIT (ClOpidogrel and Metoprolol in Myocardial Infarction Trial) collaborative group* Summary Background Despite improvements in the emergency treatment of myocardial infarction (MI), early mortality and Lancet 2005; 366: 1607–21 morbidity remain high. The antiplatelet agent clopidogrel adds to the benefit of aspirin in acute coronary See Comment page 1587 syndromes without ST-segment elevation, but its effects in patients with ST-elevation MI were unclear. *Collaborators and participating hospitals listed at end of paper Methods 45 852 patients admitted to 1250 hospitals within 24 h of suspected acute MI onset were randomly Correspondence to: allocated clopidogrel 75 mg daily (n=22 961) or matching placebo (n=22 891) in addition to aspirin 162 mg daily. Dr Zhengming Chen, Clinical Trial 93% had ST-segment elevation or bundle branch block, and 7% had ST-segment depression. Treatment was to Service Unit and Epidemiological Studies Unit (CTSU), Richard Doll continue until discharge or up to 4 weeks in hospital (mean 15 days in survivors) and 93% of patients completed Building, Old Road Campus, it. The two prespecified co-primary outcomes were: (1) the composite of death, reinfarction, or stroke; and Oxford OX3 7LF, UK (2) death from any cause during the scheduled treatment period. Comparisons were by intention to treat, and [email protected] used the log-rank method. This trial is registered with ClinicalTrials.gov, number NCT00222573. or Dr Lixin Jiang, Fuwai Hospital, Findings Allocation to clopidogrel produced a highly significant 9% (95% CI 3–14) proportional reduction in death, Beijing 100037, P R China [email protected] reinfarction, or stroke (2121 [9·2%] clopidogrel vs 2310 [10·1%] placebo; p=0·002), corresponding to nine (SE 3) fewer events per 1000 patients treated for about 2 weeks. -

Zhengzhou Coal Mining Machinery Group Company Limited 鄭州煤礦機械集團股份有限公司
Hong Kong Exchanges and Clearing Limited and The Stock Exchange of Hong Kong Limited take no responsibility for the contents of this announcement, make no representation as to its accuracy or completeness and expressly disclaim any liability whatsoever for any loss howsoever arising from or in reliance upon the whole or any part of the contents of this announcement. Zhengzhou Coal Mining Machinery Group Company Limited 鄭州煤礦機械集團股份有限公司 (A joint stock limited company incorporated in the People’s Republic of China with limited liability) (Stock code: 00564) POLL RESULTS OF THE FIRST EXTRAORDINARY GENERAL MEETING HELD ON 10 FEBRUARY 2015 RETIREMENT OF DIRECTORS APPOINTMENT OF MEMBERS OF THE THIRD SESSION OF THE BOARD OF DIRECTORS RETIREMENT OF SUPERVISORS APPOINTMENT OF MEMBERS OF THE THIRD SESSION OF THE SUPERVISORY BOARD APPOINTMENT OF CHAIRMAN AND VICE CHAIRMAN OF THE THIRD SESSION OF THE BOARD OF DIRECTORS APPOINTMENT OF CHAIRMAN OF THE THIRD SESSION OF THE SUPERVISORY BOARD AND APPOINTMENT OF MEMBERS OF COMMITTEES UNDER THE THIRD SESSION OF THE BOARD OF DIRECTORS VOTING RESULTS OF THE FIRST EXTRAORDINARY GENERAL MEETING OF 2015 References are made to the notice of the first extraordinary general meeting of 2015 and the Announcement of Zhengzhou Coal Mining Machinery Group Company Limited (the “Company”) dated 24 December 2014 (the “Announcement”) and the supplemental notice of the first extraordinary general meeting of 2015 dated 15 January 2015 (the “Supplemental Notice”). Unless otherwise defined herein, terms used in this announcement shall have the same meanings as defined in the Announcement and Supplemental Notice. – 1 – The Board is pleased to announce that the first EGM of 2015 was held on 10 February 2015 at Convention Centre of Zhengzhou Coal Mining Machinery Group Company Limited, No. -
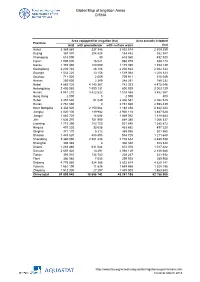
Global Map of Irrigation Areas CHINA
Global Map of Irrigation Areas CHINA Area equipped for irrigation (ha) Area actually irrigated Province total with groundwater with surface water (ha) Anhui 3 369 860 337 346 3 032 514 2 309 259 Beijing 367 870 204 428 163 442 352 387 Chongqing 618 090 30 618 060 432 520 Fujian 1 005 000 16 021 988 979 938 174 Gansu 1 355 480 180 090 1 175 390 1 153 139 Guangdong 2 230 740 28 106 2 202 634 2 042 344 Guangxi 1 532 220 13 156 1 519 064 1 208 323 Guizhou 711 920 2 009 709 911 515 049 Hainan 250 600 2 349 248 251 189 232 Hebei 4 885 720 4 143 367 742 353 4 475 046 Heilongjiang 2 400 060 1 599 131 800 929 2 003 129 Henan 4 941 210 3 422 622 1 518 588 3 862 567 Hong Kong 2 000 0 2 000 800 Hubei 2 457 630 51 049 2 406 581 2 082 525 Hunan 2 761 660 0 2 761 660 2 598 439 Inner Mongolia 3 332 520 2 150 064 1 182 456 2 842 223 Jiangsu 4 020 100 119 982 3 900 118 3 487 628 Jiangxi 1 883 720 14 688 1 869 032 1 818 684 Jilin 1 636 370 751 990 884 380 1 066 337 Liaoning 1 715 390 783 750 931 640 1 385 872 Ningxia 497 220 33 538 463 682 497 220 Qinghai 371 170 5 212 365 958 301 560 Shaanxi 1 443 620 488 895 954 725 1 211 648 Shandong 5 360 090 2 581 448 2 778 642 4 485 538 Shanghai 308 340 0 308 340 308 340 Shanxi 1 283 460 611 084 672 376 1 017 422 Sichuan 2 607 420 13 291 2 594 129 2 140 680 Tianjin 393 010 134 743 258 267 321 932 Tibet 306 980 7 055 299 925 289 908 Xinjiang 4 776 980 924 366 3 852 614 4 629 141 Yunnan 1 561 190 11 635 1 549 555 1 328 186 Zhejiang 1 512 300 27 297 1 485 003 1 463 653 China total 61 899 940 18 658 742 43 241 198 52 -

Discloseable Transaction (1) Disposal of a Subsidiary (2) Grant of Put Option
Hong Kong Exchanges and Clearing Limited and The Stock Exchange of Hong Kong Limited take no responsibility for the contents of this joint announcement, make no representation as to its accuracy or completeness and expressly disclaim any liability whatsoever for any loss howsoever arising from or in reliance upon the whole or any part of the contents of this joint announcement. GCL-Poly Energy Holdings Limited GCL New Energy Holdings Limited 保 利 協 鑫 能 源 控 股 有 限 公 司協鑫 新 能 源 控 股 有 限 公 司 (Incorporated in Cayman Islands with limited liability) (Incorporated in Bermuda with limited liability) (Stock code: 3800) (Stock code: 451) DISCLOSEABLE TRANSACTION (1) DISPOSAL OF A SUBSIDIARY (2) GRANT OF PUT OPTION THE SHARE PURCHASE AGREEMENT The GCL-Poly Board and the GNE Board jointly announce that on 7 May 2021 (after trading hours), Henan GCL New Energy, being an indirect subsidiary of GCL-Poly and GNE (as the seller) and State Power Investment Corporation Chongqing Electric Power Co., Ltd.* (國家電投集團重慶電力有 限公司) (as the purchaser) entered into the Share Purchase Agreement. Pursuant to the Share Purchase Agreement, the Seller agreed to sell the entire equity interest in Yongcheng Xin Neng to the Purchaser. Upon completion of the Disposal, Yongcheng Xin Neng will cease to be a subsidiary of GNE and GCL-Poly. Accordingly, the financial results of Yongcheng Xin Neng will no longer be consolidated into the financial statements of GCL-Poly and GNE upon Closing. USE OF PROCEEDS FROM THE TRANSACTIONS The net cash proceeds from the Transactions (being the sum of the Consideration and the Net Payable Amount as at the Reference Date minus the Rectification Cost) is expected to be approximately RMB251,700,915, which GNE intends to use for repayment of its debts. -

Knockdown Resistance of Anopheles Sinensis in Henan Province, China
Zhang et al. Malaria Journal (2015) 14:137 DOI 10.1186/s12936-015-0662-y RESEARCH Open Access Knockdown resistance of Anopheles sinensis in Henan province, China Hong-wei Zhang1*†, Ying Liu1†, Tao Hu2†, Rui-min Zhou1, Jian-she Chen1, Dan Qian1, Cheng-yun Yang1, Yu-ling Zhao1, Su-hua Li1, Jing Cui3, Zhong-quan Wang3, Zhanchun Feng2 and Bian-li Xu1* Abstract Background: Vivax malaria was historically epidemic in Henan Province of China and Anopheles sinensis was the main vectors and poor farming communities bare the greatest burden of disease. Knockdown resistance in An. sinensis is one of the mechanisms of resistance against pyrethroids. In the present study, the frequency of mutations from An. sinensis was examined in Henan province, China. Methods: Anopheles was collected from Kaifeng, Tongbai, Tanghe, Pingqiao, Shihe, and Yongcheng counties of Henan province in 2013. Molecular identification of Anopheles species was conducted by polymerase chain reaction (PCR) amplifying the internal transcribed spacer 2 (ITS2). Part of the IIS6 domain of the para-type sodium channel protein gene was polymerase chain reaction-amplified and directly sequenced. Frequency and geographic difference of kdr gene mutant types were analysed. Results: 208 Anopheles were received molecular identification, of which 169 (81.25%) were An. sinensis, 25 (12.02%) were Anopheles yatsushiroensis, and 12 (5.77%) were Anopheles lesteri. A 325 bp fragment of the para-type sodium channel gene including position 1014 was successfully sequenced from 139 Anopheles, of which 125 (89.93%) were An. sinensis, 12 (8.63%) were An. yatsushiroensis, 2 (1.44%) were An. lesteri. The molecular analyses revealed that mutations existed at codon 1014 in An. -

Energy Markets in China and the Outlook for CMM Project
U.S. EP.NSII Coalbed Methane Energy Markets in China and the Outlook for CMM Project Development in Anhui, Chongqing, Henan, Inner Mongolia, and Guizhou Provinces Energy Markets in China and the Outlook for CMM Project Development in Anhui, Chongqing, Henan, Inner Mongolia, and Guizhou Provinces Revised, April 2015 Acknowledgements This publication was developed at the request of the U.S. Environmental Protection Agency (USEPA), in support of the Global Methane Initiative (GMI). In collaboration with the Coalbed Methane Outreach Program (CMOP), Raven Ridge Resources, Incorporated team members Candice Tellio, Charlee A. Boger, Raymond C. Pilcher, Martin Weil and James S. Marshall authored this report based on feasibility studies performed by Raven Ridge Resources, Incorporated, Advanced Resources International, and Eastern Research Group. 2 Disclaimer This report was prepared for the U.S. Environmental Protection Agency (USEPA). This analysis uses publicly available information in combination with information obtained through direct contact with mine personnel, equipment vendors, and project developers. USEPA does not: (a) make any warranty or representation, expressed or implied, with respect to the accuracy, completeness, or usefulness of the information contained in this report, or that the use of any apparatus, method, or process disclosed in this report may not infringe upon privately owned rights; (b) assume any liability with respect to the use of, or damages resulting from the use of, any information, apparatus, method, or process -

Model of Burnout, Depression, and Work Performance Among Nurses in China: a Questionnaire Survey
Model of burnout, depression, and work performance among nurses in China: a questionnaire survey. Li Li ( [email protected] ) Zhengzhou University First Aliated Hospital https://orcid.org/0000-0001-9990-0751 Yongcheng Yao Zhengxhou Normal University Xiaoping Lou Zhengzhou University First Aliated Hospital Nan Qin Zhengzhou University First Aliated Hospital Wu Yao Zhengzhou University Research article Keywords: burnout, depression, job performance, nurse, personality Posted Date: February 28th, 2020 DOI: https://doi.org/10.21203/rs.2.24856/v1 License: This work is licensed under a Creative Commons Attribution 4.0 International License. Read Full License Page 1/15 Abstract Background: To investigate the relationship of job burnout, depression, with job performance among nurses and to construct a job performance model. Methods: Questionnaires were administered to 792 nurses working in 5 hospitals in Zhengzhou, Henan province, China from July to August in 2015. Results: Of the 792 nurses, statistically signicant differences were found in the age, educational status, years working, department, job title, and personality types with respect to burnout, depression, and job performance ( P <0.05). The job burnout scores were positively correlated with the depression scores and negatively correlated with the job performance ( P <0.001). Nurses in the 25-29 years age group had the highest burnout scores ( P <0.01). The burnout scores were higher among those who worked 6-15 years than those who worked more than 15 years ( P <0.01). The job performance scores were higher in the ≥16-year than <6-year working group ( P <0.05). The burnout scores were lower among intermediate-level than junior-level nurses ( P <0.05), but the job performance scores were higher than those of junior-level nurses ( P <0.01).