Deep Dive: Innodb Transactions and Write Paths from the Client Connection to Physical Storage
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Query Optimization Techniques - Tips for Writing Efficient and Faster SQL Queries
INTERNATIONAL JOURNAL OF SCIENTIFIC & TECHNOLOGY RESEARCH VOLUME 4, ISSUE 10, OCTOBER 2015 ISSN 2277-8616 Query Optimization Techniques - Tips For Writing Efficient And Faster SQL Queries Jean HABIMANA Abstract: SQL statements can be used to retrieve data from any database. If you've worked with databases for any amount of time retrieving information, it's practically given that you've run into slow running queries. Sometimes the reason for the slow response time is due to the load on the system, and other times it is because the query is not written to perform as efficiently as possible which is the much more common reason. For better performance we need to use best, faster and efficient queries. This paper covers how these SQL queries can be optimized for better performance. Query optimization subject is very wide but we will try to cover the most important points. In this paper I am not focusing on, in- depth analysis of database but simple query tuning tips & tricks which can be applied to gain immediate performance gain. ———————————————————— I. INTRODUCTION Query optimization is an important skill for SQL developers and database administrators (DBAs). In order to improve the performance of SQL queries, developers and DBAs need to understand the query optimizer and the techniques it uses to select an access path and prepare a query execution plan. Query tuning involves knowledge of techniques such as cost-based and heuristic-based optimizers, plus the tools an SQL platform provides for explaining a query execution plan.The best way to tune performance is to try to write your queries in a number of different ways and compare their reads and execution plans. -

(DDL) Reference Manual
Data Definition Language (DDL) Reference Manual Abstract This publication describes the DDL language syntax and the DDL dictionary database. The audience includes application programmers and database administrators. Product Version DDL D40 DDL H01 Supported Release Version Updates (RVUs) This publication supports J06.03 and all subsequent J-series RVUs, H06.03 and all subsequent H-series RVUs, and G06.26 and all subsequent G-series RVUs, until otherwise indicated by its replacement publications. Part Number Published 529431-003 May 2010 Document History Part Number Product Version Published 529431-002 DDL D40, DDL H01 July 2005 529431-003 DDL D40, DDL H01 May 2010 Legal Notices Copyright 2010 Hewlett-Packard Development Company L.P. Confidential computer software. Valid license from HP required for possession, use or copying. Consistent with FAR 12.211 and 12.212, Commercial Computer Software, Computer Software Documentation, and Technical Data for Commercial Items are licensed to the U.S. Government under vendor's standard commercial license. The information contained herein is subject to change without notice. The only warranties for HP products and services are set forth in the express warranty statements accompanying such products and services. Nothing herein should be construed as constituting an additional warranty. HP shall not be liable for technical or editorial errors or omissions contained herein. Export of the information contained in this publication may require authorization from the U.S. Department of Commerce. Microsoft, Windows, and Windows NT are U.S. registered trademarks of Microsoft Corporation. Intel, Itanium, Pentium, and Celeron are trademarks or registered trademarks of Intel Corporation or its subsidiaries in the United States and other countries. -

Data Analysis Expressions (DAX) in Powerpivot for Excel 2010
Data Analysis Expressions (DAX) In PowerPivot for Excel 2010 A. Table of Contents B. Executive Summary ............................................................................................................................... 3 C. Background ........................................................................................................................................... 4 1. PowerPivot ...............................................................................................................................................4 2. PowerPivot for Excel ................................................................................................................................5 3. Samples – Contoso Database ...................................................................................................................8 D. Data Analysis Expressions (DAX) – The Basics ...................................................................................... 9 1. DAX Goals .................................................................................................................................................9 2. DAX Calculations - Calculated Columns and Measures ...........................................................................9 3. DAX Syntax ............................................................................................................................................ 13 4. DAX uses PowerPivot data types ......................................................................................................... -
PL/SQL 1 Database Management System
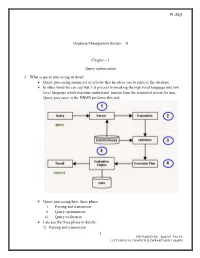
PL/SQL Database Management System – II Chapter – 1 Query optimization 1. What is query processing in detail: Query processing means set of activity that involves you to retrieve the database In other word we can say that it is process to breaking the high level language into low level language which machine understand and perform the requested action for user. Query processor in the DBMS performs this task. Query processing have three phase i. Parsing and transaction ii. Query optimization iii. Query evaluation Lets see the three phase in details : 1) Parsing and transaction : 1 PREPARED BY: RAHUL PATEL LECTURER IN COMPUTER DEPARTMENT (BSPP) PL/SQL . Check syntax and verify relations. Translate the query into an equivalent . relational algebra expression. 2) Query optimization : . Generate an optimal evaluation plan (with lowest cost) for the query plan. 3) Query evaluation : . The query-execution engine takes an (optimal) evaluation plan, executes that plan, and returns the answers to the query Let us discuss the whole process with an example. Let us consider the following two relations as the example tables for our discussion; Employee(Eno, Ename, Phone) Proj_Assigned(Eno, Proj_No, Role, DOP) where, Eno is Employee number, Ename is Employee name, Proj_No is Project Number in which an employee is assigned, Role is the role of an employee in a project, DOP is duration of the project in months. With this information, let us write a query to find the list of all employees who are working in a project which is more than 10 months old. SELECT Ename FROM Employee, Proj_Assigned WHERE Employee.Eno = Proj_Assigned.Eno AND DOP > 10; Input: . -

An Overview of Query Optimization
An Overview of Query Optimization Why? Improving query processing time. Fast response is important in several db applications. Is it possible? Yes, but relative. A query can be evaluated in several ways. We can list all of them and then find the best among them. Sometime, we might not be able to do it because of the number of possible ways to evaluate the query is huge. We need to settle for a compromise: we try to find one that is reasonably good. Typical Query Evaluation Steps in DBMS. The DBMS has the following components for query evaluation: SQL parser, quey optimizer, cost estimator, query plan interpreter. The SQL parser accepts a SQL query and generates a relational algebra expression (sometime, the system catalog is considered in the generation of the expression). This expression is fed into the query optimizer, which works in conjunction with the cost estimator to generate a query execution plan (with hopefully a reasonably cost). This plan is then sent to the plan interpreter for execution. How? The query optimizer uses several heuristics to convert a relational algebra expression to an equivalent expres- sion which (hopefully!) can be computed efficiently. Different heuristics are (see explaination in textbook): (i) transformation between selection and projection; 1. Cascading of selection: σC1∧C2 (R) ≡ σC1 (σC2 (R)) 2. Commutativity of selection: σC1 (σC2 (R)) ≡ σC2 (σC1 (R)) 0 3. Cascading of projection: πAtts(R) = πAtts(πAtts0 (R)) if Atts ⊆ Atts 4. Commutativity of projection: πAtts(σC (R)) = σC (πAtts((R)) if Atts includes all attributes used in C. (ii) transformation between Cartesian product and join; 1. -

Rdbmss Why Use an RDBMS
RDBMSs • Relational Database Management Systems • A way of saving and accessing data on persistent (disk) storage. 51 - RDBMS CSC309 1 Why Use an RDBMS • Data Safety – data is immune to program crashes • Concurrent Access – atomic updates via transactions • Fault Tolerance – replicated dbs for instant failover on machine/disk crashes • Data Integrity – aids to keep data meaningful •Scalability – can handle small/large quantities of data in a uniform manner •Reporting – easy to write SQL programs to generate arbitrary reports 51 - RDBMS CSC309 2 1 Relational Model • First published by E.F. Codd in 1970 • A relational database consists of a collection of tables • A table consists of rows and columns • each row represents a record • each column represents an attribute of the records contained in the table 51 - RDBMS CSC309 3 RDBMS Technology • Client/Server Databases – Oracle, Sybase, MySQL, SQLServer • Personal Databases – Access • Embedded Databases –Pointbase 51 - RDBMS CSC309 4 2 Client/Server Databases client client client processes tcp/ip connections Server disk i/o server process 51 - RDBMS CSC309 5 Inside the Client Process client API application code tcp/ip db library connection to server 51 - RDBMS CSC309 6 3 Pointbase client API application code Pointbase lib. local file system 51 - RDBMS CSC309 7 Microsoft Access Access app Microsoft JET SQL DLL local file system 51 - RDBMS CSC309 8 4 APIs to RDBMSs • All are very similar • A collection of routines designed to – produce and send to the db engine an SQL statement • an original -
Introduction to Query Processing and Optimization
Introduction to Query Processing and Optimization Michael L. Rupley, Jr. Indiana University at South Bend [email protected] owned_by 10 No ABSTRACT All database systems must be able to respond to The drivers relation: requests for information from the user—i.e. process Attribute Length Key? queries. Obtaining the desired information from a driver_id 10 Yes database system in a predictable and reliable fashion is first_name 20 No the scientific art of Query Processing. Getting these last_name 20 No results back in a timely manner deals with the age 2 No technique of Query Optimization. This paper will introduce the reader to the basic concepts of query processing and query optimization in the relational The car_driver relation: database domain. How a database processes a query as Attribute Length Key? well as some of the algorithms and rule-sets utilized to cd_car_name 15 Yes* produce more efficient queries will also be presented. cd_driver_id 10 Yes* In the last section, I will discuss the implementation plan to extend the capabilities of my Mini-Database Engine program to include some of the query 2. WHAT IS A QUERY? optimization techniques and algorithms covered in this A database query is the vehicle for instructing a DBMS paper. to update or retrieve specific data to/from the physically stored medium. The actual updating and 1. INTRODUCTION retrieval of data is performed through various “low-level” operations. Examples of such operations Query processing and optimization is a fundamental, if for a relational DBMS can be relational algebra not critical, part of any DBMS. To be utilized operations such as project, join, select, Cartesian effectively, the results of queries must be available in product, etc. -

Exploring the Visualization of Schemas for Aggregate-Oriented Nosql Databases?
Exploring the Visualization of Schemas for Aggregate-Oriented NoSQL Databases? Alberto Hernández Chillón, Severino Feliciano Morales, Diego Sevilla Ruiz, and Jesús García Molina Faculty of Computer Science, University of Murcia Campus Espinardo, Murcia, Spain {alberto.hernandez1,severino.feliciano,dsevilla,jmolina}@um.es Abstract. The lack of an explicit data schema (schemaless) is one of the most attractive NoSQL database features for developers. Being schema- less, these databases provide a greater flexibility, as data with different structure can be stored for the same entity type, which in turn eases data evolution. This flexibility, however, should not be obtained at the expense of losing the benefits provided by having schemas: When writ- ing code that deals with NoSQL databases, developers need to keep in mind at any moment some kind of schema. Also, database tools usu- ally require the knowledge of a schema to implement their functionality. Several approaches to infer an implicit schema from NoSQL data have been proposed recently, and some utilities that take advantage of inferred schemas are emerging. In this article we focus on the requisites for the vi- sualization of schemas for aggregate-oriented NoSQL Databases. Schema diagrams have proven useful in designing and understanding databases. Plenty of tools are available to visualize relational schemas, but the vi- sualization of NoSQL schemas (and the variation that they allow) is still in an immature state, and a great R&D effort is required to achieve tools with the desired capabilities. Here, we study the main challenges to be addressed, and propose some visual representations. Moreover, we outline the desired features to be supported by visualization tools. -

SQL: Triggers, Views, Indexes Introduction to Databases Compsci 316 Fall 2014 2 Announcements (Tue., Sep
SQL: Triggers, Views, Indexes Introduction to Databases CompSci 316 Fall 2014 2 Announcements (Tue., Sep. 23) • Homework #1 sample solution posted on Sakai • Homework #2 due next Thursday • Midterm on the following Thursday • Project mixer this Thursday • See my email about format • Email me your “elevator pitch” by Wednesday midnight • Project Milestone #1 due Thursday, Oct. 16 • See project description on what to accomplish by then 3 Announcements (Tue., Sep. 30) • Homework #2 due date extended to Oct. 7 • Midterm in class next Thursday (Oct. 9) • Open-book, open-notes • Same format as sample midterm (from last year) • Already posted on Sakai • Solution to be posted later this week 4 “Active” data • Constraint enforcement: When an operation violates a constraint, abort the operation or try to “fix” data • Example: enforcing referential integrity constraints • Generalize to arbitrary constraints? • Data monitoring: When something happens to the data, automatically execute some action • Example: When price rises above $20 per share, sell • Example: When enrollment is at the limit and more students try to register, email the instructor 5 Triggers • A trigger is an event-condition-action (ECA ) rule • When event occurs, test condition ; if condition is satisfied, execute action • Example: • Event : some user’s popularity is updated • Condition : the user is a member of “Jessica’s Circle,” and pop drops below 0.5 • Action : kick that user out of Jessica’s Circle http://pt.simpsons.wikia.com/wiki/Arquivo:Jessica_lovejoy.jpg 6 Trigger example -

Oracle Nosql Database EE Data Sheet
Oracle NoSQL Database 21.1 Enterprise Edition (EE) Oracle NoSQL Database is a multi-model, multi-region, multi-cloud, active-active KEY BUSINESS BENEFITS database, designed to provide a highly-available, scalable, performant, flexible, High throughput and reliable data management solution to meet today’s most demanding Bounded latency workloads. It can be deployed in on-premise data centers and cloud. It is well- Linear scalability suited for high volume and velocity workloads, like Internet of Things, 360- High availability degree customer view, online contextual advertising, fraud detection, mobile Fast and easy deployment application, user personalization, and online gaming. Developers can use a single Smart topology management application interface to quickly build applications that run in on-premise and Online elastic configuration cloud environments. Multi-region data replication Enterprise grade software Applications send network requests against an Oracle NoSQL data store to and support perform database operations. With multi-region tables, data can be globally distributed and automatically replicated in real-time across different regions. Data can be modeled as fixed-schema tables, documents, key-value pairs, and large objects. Different data models interoperate with each other through a single programming interface. Oracle NoSQL Database is a sharded, shared-nothing system which distributes data uniformly across multiple shards in a NoSQL database cluster, based on the hashed value of the primary keys. An Oracle NoSQL Database data store is a collection of storage nodes, each of which hosts one or more replication nodes. Data is automatically populated across these replication nodes by internal replication mechanisms to ensure high availability and rapid failover in the event of a storage node failure. -

KB SQL Database Administrator Guide a Guide for the Database Administrator of KB SQL
KB_SQL Database Administrator Guide A Guide for the Database Administrator of KB_SQL © 1988-2019 by Knowledge Based Systems, Inc. All rights reserved. Printed in the United States of America. No part of this manual may be reproduced in any form or by any means (including electronic storage and retrieval or translation into a foreign language) without prior agreement and written consent from KB Systems, Inc., as governed by United States and international copyright laws. The information contained in this document is subject to change without notice. KB Systems, Inc., does not warrant that this document is free of errors. If you find any problems in the documentation, please report them to us in writing. Knowledge Based Systems, Inc. 43053 Midvale Court Ashburn, Virginia 20147 KB_SQL is a registered trademark of Knowledge Based Systems, Inc. MUMPS is a registered trademark of the Massachusetts General Hospital. All other trademarks or registered trademarks are properties of their respective companies. Table of Contents Preface ................................................. vii Purpose ............................................. vii Audience ............................................ vii Conventions Used in this Manual ...................................................................... viii The Organization of this Manual ......................... ... x Additional Documentation .............................. xii Chapter 1: An Overview of the KB_SQL User Groups and Menus ............................................................................................................ -

Query Optimization for Dynamic Imputation
Query Optimization for Dynamic Imputation José Cambronero⇤ John K. Feser⇤ Micah J. Smith⇤ Samuel Madden MIT CSAIL MIT CSAIL MIT LIDS MIT CSAIL [email protected] [email protected] [email protected] [email protected] ABSTRACT smaller than the entire database. While traditional imputation Missing values are common in data analysis and present a methods work over the entire data set and replace all missing usability challenge. Users are forced to pick between removing values, running a sophisticated imputation algorithm over a tuples with missing values or creating a cleaned version of their large data set can be very expensive: our experiments show data by applying a relatively expensive imputation strategy. that even a relatively simple decision tree algorithm takes just Our system, ImputeDB, incorporates imputation into a cost- under 6 hours to train and run on a 600K row database. based query optimizer, performing necessary imputations on- Asimplerapproachmightdropallrowswithanymissing the-fly for each query. This allows users to immediately explore values, which can not only introduce bias into the results, but their data, while the system picks the optimal placement of also result in discarding much of the data. In contrast to exist- imputation operations. We evaluate this approach on three ing systems [2, 4], ImputeDB avoids imputing over the entire real-world survey-based datasets. Our experiments show that data set. Specifically,ImputeDB carefully plans the placement our query plans execute between 10 and 140 times faster than of imputation or row-drop operations inside the query plan, first imputing the base tables. Furthermore, we show that resulting in a significant speedup in query execution while the query results from on-the-fly imputation differ from the reducing the number of dropped rows.