Using Deep Learning to Understand Patterns of Player Movement in the NBA
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

2-6-14 a Section.Indd
A6 The Orlando Times FEBRUARY 6 - 12, 2014 Client: Allstate Bleed: NA Region: US Campaign: Insurance/AA Trim: 8.31” x 18” Language: English Agency Job #: 610-ALAAMNP4002 Live: NA Notes: None AD #/AD ID: AHAA0445 *******Magic News******Date Modified: 01/16/14 2:59 PM Keyline Scale: 1”= 1” CR: Output at: 100% AD Round: Page: 1 of 1 NOT TO BE USED FOR COLOR APPROVAL Despite A Breakout AD: S. Block Year P: E. Garber AM: J. Norman, BM: D. Scampini PC: J. Jenkins Affl alo Still Not An All-Star BY CLINTON ************************************************************************************************** REYES, TIMES SPORTS WRITER Orlando Magic - Amway Center, Orlando ORLANDO – In the per- fect world, Orlando would be 38-11 and leading the NBA into the All-Star break, and in do- ing so, undoubtedly secure an All-Star roster selection for SG Aaron Affl alo. Playing like one, Affl alo is having quite the year and his play has brought many to believe in his worthiness of a fi rst All-Star appearance. But, the NBA we have all come to un- derstand is not one to commend a great player, on a bad team. Give it up for @nhnets Despite having a career year and ranking among the top shooting guards in practically every sta- #GiveItUpForGood tistical category, Affl alo’s hopes of making his fi rst NBA All-Star team were dashed on Thursday when he was left off the team. Clearly, Orlando’s 12-35 record factored into the decision to pick the likes of DerMar DeRo- zan and Joe Johnson ahead of Orlando’s standout guard. -

College Hoops Scoops Stony Brook, Hofstra, LIU Set to Go
Newsday.com 11/12/11 10:17 AM http://www.newsday.com/sports/college/college-hoops-scoops-1.1620561/stony-brook-hofstra-liu-set-to-go-1.3314160 College hoops scoops Stony Brook, Hofstra, LIU set to go Friday November 11, 2011 2:47 PM By Marcus Henry We’re not even technically through the first week of college basketball an already there are a couple of matchups the that should be paid attention to. Local Matchups Friday LIU at Hofstra, 7:00: After LIU’s fabulous run to the NCAA Tournament last, the Blackbirds have become one of the hottest programs in the NY Metro area. With six of its top eight players back, led by junior forward Julian Boyd the Blackbirds could he a handful for Hofstra. As for the Pride, Mo Cassara’s group could be one of the most underrated in the area. Sure, Charles Jenkins and Greg Washington are gone, but Mike Moore, David Imes, Stevie Mejia, Nathaniel Lester and Shemiye McLendon are all experienced players. It should be a good one in Hempstead. Stony Brook at Indiana, 7:00: Stony Brook and its followers have waited an entire off season for this matchup. With so much talent back and several newcomers expected to create an immediate impact, no one would be shocked to see the Seawolves win this game. Senior guard Bryan Dougher, redshirt junior forward Tommy Brenton and senior Dallis Joyner have been the key elements to Stony Brook’s rise. The Seawolves have had winning seasons two of the last three years and have finished .500 or better in the America East the last three years. -

Publication: Ajc Date: 5/12/14
PUBLICATION: AJC DATE: 5/12/14 How close were the Hawks to the Eastern finals? By Mark Bradley The history of the Atlanta Hawks is strewn with what-ifs. What if they’d kept Julius Erving, who played three exhibition games for them in 1972 before a judge ordered him back to the old ABA? What if they hadn’t traded Pete Maravich? What if Dominique Wilkins, as opposed to Cliff Levingston, had taken the last shot in Game 6 against Boston? What if — stop me if you’ve heard this one — they’d drafted Chris Paul? Today we have a new one. What if the Hawks had closed out the Indiana Pacers in six games? Would they be sitting where the Pacers are — one game from the Eastern Conference finals? The Atlanta Hawks have never won two playoff series in any year, nor have they ever reached the Eastern finals.(They did reach the conference finals in 1969 and 1970, when they were based in the West, but it took only one series win to get there. They lost in five games to the Lakers in 1969 and were swept in 1970. Game 1 of the latter series, played in Alexander Memorial Coliseum, remains a sore point in Hawks history. The Lakers of West, Baylor and Wilt shot 60 free throws to the Hawks’ 32. The Lakers won 119-115.) The latest band of Hawks led the top-seeded Pacers by five points with three minutes remaining in Game 6 at Philips Arena. Had they won that night — or two nights later in Indianapolis, where they were routed — they’d have faced fifth-seeded Washington in Round 2. -

June 7 Redemption Update
SET SUBSET/INSERT # PLAYER 2019 Donruss Baseball Signature Series Pink Firework 27 Jonathan Loaisiga 2019 Donruss Baseball Signature Series Pink Firework 7 Michael Kopech 2019 Diamond Kings Baseball DK 205 Signatures 15 Michael Kopech 2019 Diamond Kings Baseball DK 205 Signatures Holo Silver 15 Michael Kopech 2019 Diamond Kings Baseball DK Material Signatures 36 Michael Kopech 2019 Diamond Kings Baseball DK Signatures 67 Yusei Kikuchi 2019 Diamond Kings Baseball DK Signatures 36 Michael Kopech 2019 Diamond Kings Baseball DK Signatures Holo Blue 67 Yusei Kikuchi 2019 Diamond Kings Baseball DK Signatures Holo Gold 67 Yusei Kikuchi 2019 Diamond Kings Baseball DK Signatures Holo Silver 67 Yusei Kikuchi 2019 Diamond Kings Baseball DK Signatures Holo Silver 36 Michael Kopech Yusei Kikuchi 2019 Diamond Kings Baseball DK Signatures Purple 67 Yusei Kikuchi 2018 Chronicles Baseball Contenders Season Tickets Red 6 Gleyber Torres 2018 National Treasures Baseball Hometown Heroes 23 Aaron Judge 2018 National Treasures Baseball Hometown Heroes Platinum 23 Aaron Judge 2018 National Treasures Baseball Treasured Signatures 14 Aaron Judge 2018 National Treasures Baseball Treasured Signatures Platinum 14 Aaron Judge Ivan Rodriguez 2017 National Treasures Baseball NT Signature Dual Material Booklet 6 Johnny Bench Ivan Rodriguez 2017 National Treasures Baseball NT Signature Dual Material Booklet Holo Gold 6 Johnny Bench Ivan Rodriguez 2017 National Treasures Baseball NT Signature Dual Material Booklet Platinum 6 Johnny Bench 2013 Elite Extra Edition Baseball -

Open Andrew Bryant SHC Thesis.Pdf
THE PENNSYLVANIA STATE UNIVERSITY SCHREYER HONORS COLLEGE DEPARTMENT OF ECONOMICS REVISITING THE SUPERSTAR EXTERNALITY: LEBRON’S ‘DECISION’ AND THE EFFECT OF HOME MARKET SIZE ON EXTERNAL VALUE ANDREW DAVID BRYANT SPRING 2013 A thesis submitted in partial fulfillment of the requirements for baccalaureate degrees in Mathematics and Economics with honors in Economics Reviewed and approved* by the following: Edward Coulson Professor of Economics Thesis Supervisor David Shapiro Professor of Economics Honors Adviser * Signatures are on file in the Schreyer Honors College. i ABSTRACT The movement of superstar players in the National Basketball Association from small- market teams to big-market teams has become a prominent issue. This was evident during the recent lockout, which resulted in new league policies designed to hinder this flow of talent. The most notable example of this superstar migration was LeBron James’ move from the Cleveland Cavaliers to the Miami Heat. There has been much discussion about the impact on the two franchises directly involved in this transaction. However, the indirect impact on the other 28 teams in the league has not been discussed much. This paper attempts to examine this impact by analyzing the effect that home market size has on the superstar externality that Hausman & Leonard discovered in their 1997 paper. A road attendance model is constructed for the 2008-09 to 2011-12 seasons to compare LeBron’s “superstar effect” in Cleveland versus his effect in Miami. An increase of almost 15 percent was discovered in the LeBron superstar variable, suggesting that the move to a bigger market positively affected LeBron’s fan appeal. -

NBA Players Word Search
Name: Date: Class: Teacher: NBA Players Word Search CRMONT A ELLISIS A I A HTHOM A S XTGQDWIGHTHOW A RDIBZWLMVG VKEVINDUR A NTBL A KEGRIFFIN YQMJVURVDE A NDREJORD A NNTX CEQBMRRGBHPK A WHILEON A RDB TFJGOUTO A I A SDIRKNOWITZKI IGPOUSBIIYUDPKEVINLOVEXC MKHVSSTDOKL A YTHOMPSONXJF DMDDEESWLEMMP A ULGEORGEEK U A E A MLBYEMIISTEPHENCURRY NNRVJLW A BYL A ODLVIWJVHLER CUOI A WLNRKLNO A LHORFORDMI A GNDMEWEOESLVUBPZK A LSUYE NIWWESNWNG A IKTIMDUNC A NLI KNIESTR A JEPLU A QZPHESRJIR GOLSHBQD A K A LFKYLELOWRYNV HBLT A RDEMWR A ZSERGEIB A K A I DIIYROGDEM A RDEROZ A NGSJBN ZL A HDOKUSLGDCHRISP A ULUXG OIMSEKL A M A RCUS A LDRIDGEDZ VKSWNQXIDR A YMONDGREENYFZ TONYP A RKER A LECHRISBOSH A P AL HORFORD DWYANE WADE ISAIAH THOMAS DEMAR DEROZAN RUSSELL WESTBROOK TIM DUNCAN DAMIAN LILLARD PAUL GEORGE DRAYMOND GREEN LEBRON JAMES KLAY THOMPSON BLAKE GRIFFIN KYLE LOWRY LAMARCUS ALDRIDGE SERGE IBAKA KYRIE IRVING STEPHEN CURRY KEVIN LOVE DWIGHT HOWARD CHRIS BOSH TONY PARKER DEANDRE JORDAN DERON WILLIAMS JOSE BAREA MONTA ELLIS TIM DUNCAN KEVIN DURANT JAMES HARDEN JEREMY LIN KAWHI LEONARD DAVID WEST CHRIS PAUL MANU GINOBILI PAUL MILLSAP DIRK NOWITZKI Free Printable Word Seach www.AllFreePrintable.com Name: Date: Class: Teacher: NBA Players Word Search CRMONT A ELLISIS A I A HTHOM A S XTGQDWIGHTHOW A RDIBZWLMVG VKEVINDUR A NTBL A KEGRIFFIN YQMJVURVDE A NDREJORD A NNTX CEQBMRRGBHPK A WHILEON A RDB TFJGOUTO A I A SDIRKNOWITZKI IGPOUSBIIYUDPKEVINLOVEXC MKHVSSTDOKL A YTHOMPSONXJF DMDDEESWLEMMP A ULGEORGEEK U A E A MLBYEMIISTEPHENCURRY NNRVJLW A BYL A ODLVIWJVHLER -

HAPPY HALLOWEEN from Our Pee Wee and Mini-Kickers!
Calendar | Register | Website | Volunteer | Donate | SYC Store HAPPY HALLOWEEN from our Pee Wee and Mini-Kickers! OPEN REGISTRATIONS WINTER SPORTS Basketball Cheerleading Futsal - NEW! Lacrosse (Experienced Players Only) Track FEATURED SPORT Winter Indoor Lacrosse For Experienced SYC Lacrosse Players WINTER LACROSSE is open to SYC Players who have at least one prior regular SPRING season of lacrosse experience and are proficient at passing and catching. $70 now through December 10th. Read more about Winter Indoor Lacrosse REGISTER TODAY! NEWS AND SPECIAL EVENTS Fall Softball Season Wrap Up As the fall softball season is wrapping up, we want to thank all of the coaches and volunteers that made this season possible, especially the head coaches, Amy Sutton, Tyler Hunt, Stephanie Niner, Derek Lewis, Greg Viggiano. Also, thanks to some of our guest coaches: Suzie Willemssen (O’Connell HS head coach), Dan Cummins (Redline Athletics, formerly with the NY Mets!), Vanessa Hindle (Lee HS varsity pitcher and former SYC player), and Jess Kirby (West Springfield varsity and former SYC player). Read more WIZARDS TICKETS Friday, November 2 @ 8pm Oklahoma City Thunder vs Washington Wizards Tickets start at $34 Join us at Capital One Arena to see All-Stars Russell Westbrook & Paul George take on John Wall and the Wizards. Enjoy special ticket pricing for SYC that includes a Wizards T-shirt, and a portion of the proceeds benefiting the SYC Scholarship Fund. All ticket buyers will have the opportunity to enter the building early to watch team warm- ups. Tickets for this offer are only available at the link below: https://fevo.me/syc-wizvsthunder. -

National Basketball Association
NATIONAL BASKETBALL ASSOCIATION OFFICIAL SCORER'S REPORT FINAL BOX Wednesday, October 25, 2017 Chesapeake Energy Arena, Oklahoma City, OK Officials: #45 Brian Forte, #11 Derrick Collins, #12 CJ Washington Game Duration: 2:18 Attendance: 18203 (Sellout) VISITOR: Indiana Pacers (2-3) POS MIN FG FGA 3P 3PA FT FTA OR DR TOT A PF ST TO BS +/- PTS 44 Bojan Bogdanovic F 28:51 0 7 0 5 4 4 0 2 2 2 2 1 5 0 -19 4 21 Thaddeus Young F 33:29 5 12 3 6 1 2 1 3 4 0 2 2 2 0 -15 14 11 Domantas Sabonis C 18:44 1 9 0 0 2 2 8 3 11 2 5 0 1 0 -11 4 4 Victor Oladipo G 35:50 11 18 5 8 8 8 0 5 5 0 5 1 3 2 -20 35 2 Darren Collison G 37:49 5 12 2 4 6 6 0 2 2 3 2 2 4 0 -13 18 25 Al Jefferson 18:11 1 4 0 0 3 3 1 6 7 2 2 2 3 0 -3 5 1 Lance Stephenson 17:05 2 7 0 2 1 3 0 4 4 1 2 1 0 0 4 5 22 TJ Leaf 19:22 1 4 0 1 0 1 1 2 3 1 1 1 0 0 -4 2 6 Cory Joseph 21:11 1 6 0 2 4 4 1 0 1 2 2 2 0 0 -5 6 0 Alex Poythress 02:22 0 0 0 0 0 0 0 0 0 0 0 0 0 0 -1 0 3 Joe Young 02:22 1 2 0 0 1 2 1 0 1 0 0 0 0 0 -1 3 12 Damien Wilkins 02:22 0 1 0 1 0 0 0 0 0 0 0 0 0 0 -1 0 13 Ike Anigbogu 02:22 0 1 0 0 0 0 1 0 1 0 0 1 1 0 -1 0 240:00 28 83 10 29 30 35 14 27 41 13 23 13 19 2 -18 96 33.7% 34.5% 85.7% TM REB: 10 TOT TO: 19 (12 PTS) HOME: OKLAHOMA CITY THUNDER (2-2) POS MIN FG FGA 3P 3PA FT FTA OR DR TOT A PF ST TO BS +/- PTS 13 Paul George F 19:06 4 8 0 3 2 3 0 1 1 0 6 0 1 1 -2 10 7 Carmelo Anthony F 32:59 9 17 3 7 7 9 0 10 10 1 3 0 6 3 19 28 12 Steven Adams C 30:51 8 13 0 0 1 1 7 4 11 1 1 2 3 2 16 17 21 Andre Roberson G 20:40 2 5 0 1 0 0 2 0 2 1 3 0 1 1 11 4 0 Russell Westbrook G 35:09 10 18 -
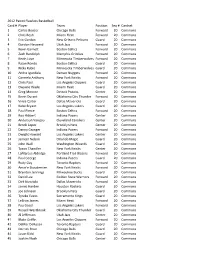
2012 Panini Flawless Basketball Card # Player Team Position Seq
2012 Panini Flawless Basketball Card # Player Team Position Seq # Cardset 1 Carlos Boozer Chicago Bulls Forward 20 Commons 2 Chris Bosh Miami Heat Forward 20 Commons 3 Eric Gordon New Orleans Pelicans Guard 20 Commons 4 Gordon Hayward Utah Jazz Forward 20 Commons 5 Kevin Garnett Boston Celtics Forward 20 Commons 6 Zach Randolph Memphis Grizzlies Forward 20 Commons 7 Kevin Love Minnesota Timberwolves Forward 20 Commons 8 Rajon Rondo Boston Celtics Guard 20 Commons 9 Ricky Rubio Minnesota Timberwolves Guard 20 Commons 10 Andre Iguodala Denver Nuggets Forward 20 Commons 11 Carmelo Anthony New York Knicks Forward 20 Commons 12 Chris Paul Los Angeles Clippers Guard 20 Commons 13 Dwyane Wade Miami Heat Guard 20 Commons 14 Greg Monroe Detroit Pistons Center 20 Commons 15 Kevin Durant Oklahoma City Thunder Forward 20 Commons 16 Vince Carter Dallas Mavericks Guard 20 Commons 17 Kobe Bryant Los Angeles Lakers Guard 20 Commons 18 Paul Pierce Boston Celtics Forward 20 Commons 19 Roy Hibbert Indiana Pacers Center 20 Commons 20 Anderson Varejao Cleveland Cavaliers Center 20 Commons 21 Brook Lopez Brooklyn Nets Center 20 Commons 22 Danny Granger Indiana Pacers Forward 20 Commons 23 Dwight Howard Los Angeles Lakers Center 20 Commons 24 Jameer Nelson Orlando Magic Guard 20 Commons 25 John Wall Washington Wizards Guard 20 Commons 26 Tyson Chandler New York Knicks Center 20 Commons 27 LaMarcus Aldridge Portland Trail Blazers Forward 20 Commons 28 Paul George Indiana Pacers Guard 20 Commons 29 Rudy Gay Toronto Raptors Forward 20 Commons 30 Amar'e Stoudemire -

Rosters Set for 2014-15 Nba Regular Season
ROSTERS SET FOR 2014-15 NBA REGULAR SEASON NEW YORK, Oct. 27, 2014 – Following are the opening day rosters for Kia NBA Tip-Off ‘14. The season begins Tuesday with three games: ATLANTA BOSTON BROOKLYN CHARLOTTE CHICAGO Pero Antic Brandon Bass Alan Anderson Bismack Biyombo Cameron Bairstow Kent Bazemore Avery Bradley Bojan Bogdanovic PJ Hairston Aaron Brooks DeMarre Carroll Jeff Green Kevin Garnett Gerald Henderson Mike Dunleavy Al Horford Kelly Olynyk Jorge Gutierrez Al Jefferson Pau Gasol John Jenkins Phil Pressey Jarrett Jack Michael Kidd-Gilchrist Taj Gibson Shelvin Mack Rajon Rondo Joe Johnson Jason Maxiell Kirk Hinrich Paul Millsap Marcus Smart Jerome Jordan Gary Neal Doug McDermott Mike Muscala Jared Sullinger Sergey Karasev Jannero Pargo Nikola Mirotic Adreian Payne Marcus Thornton Andrei Kirilenko Brian Roberts Nazr Mohammed Dennis Schroder Evan Turner Brook Lopez Lance Stephenson E'Twaun Moore Mike Scott Gerald Wallace Mason Plumlee Kemba Walker Joakim Noah Thabo Sefolosha James Young Mirza Teletovic Marvin Williams Derrick Rose Jeff Teague Tyler Zeller Deron Williams Cody Zeller Tony Snell INACTIVE LIST Elton Brand Vitor Faverani Markel Brown Jeffery Taylor Jimmy Butler Kyle Korver Dwight Powell Cory Jefferson Noah Vonleh CLEVELAND DALLAS DENVER DETROIT GOLDEN STATE Matthew Dellavedova Al-Farouq Aminu Arron Afflalo Joel Anthony Leandro Barbosa Joe Harris Tyson Chandler Darrell Arthur D.J. Augustin Harrison Barnes Brendan Haywood Jae Crowder Wilson Chandler Caron Butler Andrew Bogut Kentavious Caldwell- Kyrie Irving Monta Ellis -

USA Basketball Men's Pan American Games Media Guide Table Of
2015 Men’s Pan American Games Team Training Camp Media Guide Colorado Springs, Colorado • July 7-12, 2015 2015 USA Men’s Pan American Games 2015 USA Men’s Pan American Games Team Training Schedule Team Training Camp Staffing Tuesday, July 7 5-7 p.m. MDT Practice at USOTC Sports Center II 2015 USA Pan American Games Team Staff Head Coach: Mark Few, Gonzaga University July 8 Assistant Coach: Tad Boyle, University of Colorado 9-11 a.m. MDT Practice at USOTC Sports Center II Assistant Coach: Mike Brown 5-7 p.m. MDT Practice at USOTC Sports Center II Athletic Trainer: Rawley Klingsmith, University of Colorado Team Physician: Steve Foley, Samford Health July 9 8:30-10 a.m. MDT Practice at USOTC Sports Center II 2015 USA Pan American Games 5-7 p.m. MDT Practice at USOTC Sports Center II Training Camp Court Coaches Jason Flanigan, Holmes Community College (Miss.) July 10 Ron Hunter, Georgia State University 9-11 a.m. MDT Practice at USOTC Sports Center II Mark Turgeon, University of Maryland 5-7 p.m. MDT Practice at USOTC Sports Center II July 11 2015 USA Pan American Games 9-11 a.m. MDT Practice at USOTC Sports Center II Training Camp Support Staff 5-7 p.m. MDT Practice at USOTC Sports Center II Michael Brooks, University of Louisville July 12 Julian Mills, Colorado Springs, Colorado 9-11 a.m. MDT Practice at USOTC Sports Center II Will Thoni, Davidson College 5-7 p.m. MDT Practice at USOTC Sports Center II USA Men’s Junior National Team Committee July 13 Chair: Jim Boeheim, Syracuse University NCAA Appointee: Bob McKillop, Davidson College 6-8 p.m. -

June 29 Redemption Update
SET SUBSET/INSERT # PLAYER 2014 Panini Prizm Baseball Autographs Mojo Prizms 48 Kris Bryant 2017 Donruss Donruss Optic Basketball Fast Break Signatures 89 Kyle Kuzma 2017 Donruss Donruss Optic Basketball Rookie Dominators Signatures 27 Kyle Kuzma 2017 Panini Ascension Basketball Base Set Autographs 3 Kawhi Leonard 2017 Panini Ascension Basketball Base Set Autographs Green 3 Kawhi Leonard 2017 Panini Ascension Basketball Rookie Ascent 7 Lauri Markkanen 2017 Panini Ascension Basketball Rookie Ascent Green 7 Lauri Markkanen 2017 Panini Ascension Basketball Rookie Ascent Purple 7 Lauri Markkanen 2017 Panini Ascension Basketball Rookie Ascent Red 7 Lauri Markkanen 2017 Panini Contenders Draft Picks Basketball RPS College Cracked Ice Ticket Variation A 57 Lauri Markkanen 2017 Panini Contenders Draft Picks Basketball RPS College Cracked Ice Ticket Variation B 57 Lauri Markkanen 2017 Panini Contenders Draft Picks Basketball RPS College Cracked Ice Ticket Variation C 57 Lauri Markkanen 2017 Panini Contenders Draft Picks Basketball RPS College Draft Ticket 57 Lauri Markkanen 2017 Panini Contenders Draft Picks Basketball RPS College Draft Ticket Variation A 57 Lauri Markkanen 2017 Panini Contenders Draft Picks Basketball RPS College Draft Ticket Variation B 57 Lauri Markkanen 2017 Panini Contenders Draft Picks Basketball RPS College Playoff Ticket Variation A 57 Lauri Markkanen 2017 Panini Contenders Draft Picks Basketball RPS College Playoff Ticket Variation C 57 Lauri Markkanen 2017 Panini Contenders Draft Picks Basketball RPS College Ticket 57