Debugging Database Queries: a Survey of Tools, Techniques, And
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

E2 Studio Integrated Development Environment User's Manual: Getting
User’s Manual e2 studio Integrated Development Environment User’s Manual: Getting Started Guide Target Device RX, RL78, RH850 and RZ Family Rev.4.00 May 2016 www.renesas.com Notice 1. Descriptions of circuits, software and other related information in this document are provided only to illustrate the operation of semiconductor products and application examples. You are fully responsible for the incorporation of these circuits, software, and information in the design of your equipment. Renesas Electronics assumes no responsibility for any losses incurred by you or third parties arising from the use of these circuits, software, or information. 2. Renesas Electronics has used reasonable care in preparing the information included in this document, but Renesas Electronics does not warrant that such information is error free. Renesas Electronics assumes no liability whatsoever for any damages incurred by you resulting from errors in or omissions from the information included herein. 3. Renesas Electronics does not assume any liability for infringement of patents, copyrights, or other intellectual property rights of third parties by or arising from the use of Renesas Electronics products or technical information described in this document. No license, express, implied or otherwise, is granted hereby under any patents, copyrights or other intellectual property rights of Renesas Electronics or others. 4. You should not alter, modify, copy, or otherwise misappropriate any Renesas Electronics product, whether in whole or in part. Renesas Electronics assumes no responsibility for any losses incurred by you or third parties arising from such alteration, modification, copy or otherwise misappropriation of Renesas Electronics product. 5. Renesas Electronics products are classified according to the following two quality grades: “Standard” and “High Quality”. -

Events in 2013
Events in 2013 The 16.5 metre-high yellow Rubber Duck, a floating sculpture created by Dutch artist Florentijn Hofman, arrives at Ocean Terminal/Harbour City in Kowloon in May on its world tour. 1 1. The Chief Executive, Mr C Y Leung (second from left), rings the closing bell at the New York Stock Exchange in June. 2. The Ceremonial Opening of the Legal Year in January. 3. The Chief Executive meets the President of Mexico, Mr Enrique Peña Nieto, at Government House in April. 4. The Secretary for Justice, Mr Rimsky Yuen, SC (left), the Chief Secretary for Administration, Mrs Carrie Lam, and the Secretary for Constitutional and Mainland Affairs, Mr Raymond Tam, launch the public consultation on electoral reform in December. 5. The Financial Secretary, Mr John C Tsang (right), meets the French Minister of the 3 Economy and Finance, Mr Pierre Moscovici, in Paris in November. 2 5 4 1 2 1. Sarah Lee Wai-sze wins gold in the Women’s 500 metre time trial race at the UCI Track Cycling World Championships in Minsk, Belarus, in February. (Photo courtesy of Hong Kong Cycling Association) 2. The Mariner of the Seas is welcomed at the inaugural berthing at the Kai Tak Cruise Terminal in June. 3. ‘Big Waster’ headlined the year’s ‘Food Wise Hong Kong’ campaign to reduce food waste. 4. The Hong Kong Maritime Museum opened in February. 3 4 4 1 1. Visitors enjoy the ‘Journey to Hong Kong’ exhibition in Moscow in October. 2. Hong Kong cartoon characters McDull and McMug at the City of London Lord Mayor’s Show in November. -

SAS® Debugging 101 Kirk Paul Lafler, Software Intelligence Corporation, Spring Valley, California
PharmaSUG 2017 - Paper TT03 SAS® Debugging 101 Kirk Paul Lafler, Software Intelligence Corporation, Spring Valley, California Abstract SAS® users are almost always surprised to discover their programs contain bugs. In fact, when asked users will emphatically stand by their programs and logic by saying they are bug free. But, the vast number of experiences along with the realities of writing code says otherwise. Bugs in software can appear anywhere; whether accidentally built into the software by developers, or introduced by programmers when writing code. No matter where the origins of bugs occur, the one thing that all SAS users know is that debugging SAS program errors and warnings can be a daunting, and humbling, task. This presentation explores the world of SAS bugs, providing essential information about the types of bugs, how bugs are created, the symptoms of bugs, and how to locate bugs. Attendees learn how to apply effective techniques to better understand, identify, and repair bugs and enable program code to work as intended. Introduction From the very beginning of computing history, program code, or the instructions used to tell a computer how and when to do something, has been plagued with errors, or bugs. Even if your own program code is determined to be error-free, there is a high probability that the operating system and/or software being used, such as the SAS software, have embedded program errors in them. As a result, program code should be written to assume the unexpected and, as much as possible, be able to handle unforeseen events using acceptable strategies and programming methodologies. -

Agile Playbook V2.1—What’S New?
AGILE P L AY B O OK TABLE OF CONTENTS INTRODUCTION ..........................................................................................................4 Who should use this playbook? ................................................................................6 How should you use this playbook? .........................................................................6 Agile Playbook v2.1—What’s new? ...........................................................................6 How and where can you contribute to this playbook?.............................................7 MEET YOUR GUIDES ...................................................................................................8 AN AGILE DELIVERY MODEL ....................................................................................10 GETTING STARTED.....................................................................................................12 THE PLAYS ...................................................................................................................14 Delivery ......................................................................................................................15 Play: Start with Scrum ...........................................................................................15 Play: Seeing success but need more fexibility? Move on to Scrumban ............17 Play: If you are ready to kick of the training wheels, try Kanban .......................18 Value ......................................................................................................................19 -

Opportunities and Open Problems for Static and Dynamic Program Analysis Mark Harman∗, Peter O’Hearn∗ ∗Facebook London and University College London, UK
1 From Start-ups to Scale-ups: Opportunities and Open Problems for Static and Dynamic Program Analysis Mark Harman∗, Peter O’Hearn∗ ∗Facebook London and University College London, UK Abstract—This paper1 describes some of the challenges and research questions that target the most productive intersection opportunities when deploying static and dynamic analysis at we have yet witnessed: that between exciting, intellectually scale, drawing on the authors’ experience with the Infer and challenging science, and real-world deployment impact. Sapienz Technologies at Facebook, each of which started life as a research-led start-up that was subsequently deployed at scale, Many industrialists have perhaps tended to regard it unlikely impacting billions of people worldwide. that much academic work will prove relevant to their most The paper identifies open problems that have yet to receive pressing industrial concerns. On the other hand, it is not significant attention from the scientific community, yet which uncommon for academic and scientific researchers to believe have potential for profound real world impact, formulating these that most of the problems faced by industrialists are either as research questions that, we believe, are ripe for exploration and that would make excellent topics for research projects. boring, tedious or scientifically uninteresting. This sociological phenomenon has led to a great deal of miscommunication between the academic and industrial sectors. I. INTRODUCTION We hope that we can make a small contribution by focusing on the intersection of challenging and interesting scientific How do we transition research on static and dynamic problems with pressing industrial deployment needs. Our aim analysis techniques from the testing and verification research is to move the debate beyond relatively unhelpful observations communities to industrial practice? Many have asked this we have typically encountered in, for example, conference question, and others related to it. -
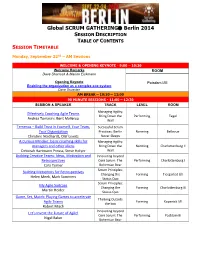
Global SCRUM GATHERING® Berlin 2014
Global SCRUM GATHERING Berlin 2014 SESSION DESCRIPTION TABLE OF CONTENTS SESSION TIMETABLE Monday, September 22nd – AM Sessions WELCOME & OPENING KEYNOTE - 9:00 – 10:30 Welcome Remarks ROOM Dave Sharrock & Marion Eickmann Opening Keynote Potsdam I/III Enabling the organization as a complex eco-system Dave Snowden AM BREAK – 10:30 – 11:00 90 MINUTE SESSIONS - 11:00 – 12:30 SESSION & SPEAKER TRACK LEVEL ROOM Managing Agility: Effectively Coaching Agile Teams Bring Down the Performing Tegel Andrea Tomasini, Bent Myllerup Wall Temenos – Build Trust in Yourself, Your Team, Successful Scrum Your Organization Practices: Berlin Norming Bellevue Christine Neidhardt, Olaf Lewitz Never Sleeps A Curious Mindset: basic coaching skills for Managing Agility: managers and other aliens Bring Down the Norming Charlottenburg II Deborah Hartmann Preuss, Steve Holyer Wall Building Creative Teams: Ideas, Motivation and Innovating beyond Retrospectives Core Scrum: The Performing Charlottenburg I Cara Turner Bohemian Bear Scrum Principles: Building Metaphors for Retrospectives Changing the Forming Tiergarted I/II Helen Meek, Mark Summers Status Quo Scrum Principles: My Agile Suitcase Changing the Forming Charlottenburg III Martin Heider Status Quo Game, Set, Match: Playing Games to accelerate Thinking Outside Agile Teams Forming Kopenick I/II the box Robert Misch Innovating beyond Let's Invent the Future of Agile! Core Scrum: The Performing Postdam III Nigel Baker Bohemian Bear Monday, September 22nd – PM Sessions LUNCH – 12:30 – 13:30 90 MINUTE SESSIONS - 13:30 -

Enabling Devops on Premise Or Cloud with Jenkins
Enabling DevOps on Premise or Cloud with Jenkins Sam Rostam [email protected] Cloud & Enterprise Integration Consultant/Trainer Certified SOA & Cloud Architect Certified Big Data Professional MSc @SFU & PhD Studies – Partial @UBC Topics The Context - Digital Transformation An Agile IT Framework What DevOps bring to Teams? - Disrupting Software Development - Improved Quality, shorten cycles - highly responsive for the business needs What is CI /CD ? Simple Scenario with Jenkins Advanced Jenkins : Plug-ins , APIs & Pipelines Toolchain concept Q/A Digital Transformation – Modernization As stated by a As established enterprises in all industries begin to evolve themselves into the successful Digital Organizations of the future they need to begin with the realization that the road to becoming a Digital Business goes through their IT functions. However, many of these incumbents are saddled with IT that has organizational structures, management models, operational processes, workforces and systems that were built to solve “turn of the century” problems of the past. Many analysts and industry experts have recognized the need for a new model to manage IT in their Businesses and have proposed approaches to understand and manage a hybrid IT environment that includes slower legacy applications and infrastructure in combination with today’s rapidly evolving Digital-first, mobile- first and analytics-enabled applications. http://www.ntti3.com/wp-content/uploads/Agile-IT-v1.3.pdf Digital Transformation requires building an ecosystem • Digital transformation is a strategic approach to IT that treats IT infrastructure and data as a potential product for customers. • Digital transformation requires shifting perspectives and by looking at new ways to use data and data sources and looking at new ways to engage with customers. -

Integrating the GNU Debugger with Cycle Accurate Models a Case Study Using a Verilator Systemc Model of the Openrisc 1000
Integrating the GNU Debugger with Cycle Accurate Models A Case Study using a Verilator SystemC Model of the OpenRISC 1000 Jeremy Bennett Embecosm Application Note 7. Issue 1 Published March 2009 Legal Notice This work is licensed under the Creative Commons Attribution 2.0 UK: England & Wales License. To view a copy of this license, visit http://creativecommons.org/licenses/by/2.0/uk/ or send a letter to Creative Commons, 171 Second Street, Suite 300, San Francisco, California, 94105, USA. This license means you are free: • to copy, distribute, display, and perform the work • to make derivative works under the following conditions: • Attribution. You must give the original author, Jeremy Bennett of Embecosm (www.embecosm.com), credit; • For any reuse or distribution, you must make clear to others the license terms of this work; • Any of these conditions can be waived if you get permission from the copyright holder, Embecosm; and • Nothing in this license impairs or restricts the author's moral rights. The software for the SystemC cycle accurate model written by Embecosm and used in this document is licensed under the GNU General Public License (GNU General Public License). For detailed licensing information see the file COPYING in the source code. Embecosm is the business name of Embecosm Limited, a private limited company registered in England and Wales. Registration number 6577021. ii Copyright © 2009 Embecosm Limited Table of Contents 1. Introduction ................................................................................................................ 1 1.1. Why Use Cycle Accurate Modeling .................................................................... 1 1.2. Target Audience ................................................................................................ 1 1.3. Open Source ..................................................................................................... 2 1.4. Further Sources of Information ......................................................................... 2 1.4.1. -

CPSC Import Stoppage Report+ Violative Products Seized at the Ports
CPSC Import Stoppage Report+ 4th Quarter, FY 2012 NOTE: Data are from samples collected from July 1, 2012 through September 30, 2012. The quantities below are approximate for all products that were determined to violate a CPSC regulation or have a defect posing a hazard. These products were either seized by CBP or reconditioned by the importer. Total number of screenings – 5,907 Total number of products stopped – 410 Total number of units stopped – 909,593 Children’s Products Total number of products stopped – 356 (87%) Total number of units stopped – 838,876 (92%) Products Stopped by Primary Violation/Defect Lead – 222 (paint 27; content 195) (62%) Small Parts – 52 (15%) Certification – 37 (10%) Phthalates – 16 (4%) Tracking Labels – 16 (4%) Durable Nursery Products – 5 (1%) The remaining 4 percent included battery-operated toys, art materials labeling, and misbranded balloons. Non-Children’s Products Total number of products stopped – 54 (13%) Total number of units stopped – 70,717 (8%) Products Stopped by Primary Violation/Defect Luminaries – 14 (26%) Cigarette and multi-purpose lighters – 10 (19%) Fireworks – 8 (15%) Bicycle Helmets – 3 (6%) Hairdryers – 3 (6%) Electric Aquarium Equipment – 3 (6%) Generator Labeling – 2 (4%) Mattresses – 2 (4%) The remaining 14 percent included electric fans, electric flat irons, portable electric lamps, and other substantial product hazards. Violative Products Seized at the Ports * The following list includes ONLY PRODUCTS SEIZED for violations of federal mandatory standards. Foreign Manufacturer Importer Product Name Model Number Country Of Origin Combined Lot Size ALISIOS Almar Sales Novelty Toys Compass Surv Taiwan Lead In Children's 6 INTERNATIONAL CORP. -

Code Profilers Choosing a Tool for Analyzing Performance
Code Profilers Choosing a Tool for Analyzing Performance Freescale Semiconductor Author, Rick Grehan Document Number: CODEPROFILERWP Rev. 0 11/2005 A profiler is a development tool that lets you look inside your application to see how each component—each routine, each block, sometimes each line and even each instruction—performs. You can find and correct your application’s bottlenecks. How do they work this magic? CONTENTS 1. Passive Profilers ...............................................3 6. Comparing Passive and Active 1.1 How It Is Done—PC Sampling ................4 Profilers .................................................................9 1.2 It Is Statistical ................................................4 6.1 Passive Profilers—Advantages ...............9 6.2 Passive Profilers—Disadvantages .........9 2. Active Profilers ...................................................4 6.3 Active Profilers—Advantages ................10 2.1 Methods of Instrumentation .....................5 6.4 Active Profilers—Disadvantages ..........11 3. Source Code Instrumentation ...................5 7. Conclusion .........................................................12 3.1 Instrumenting by Hand ..............................5 8. Addendum: Recursion and 4. Object Code Instrumentation ....................5 Hierarchies ........................................................12 4.1 Direct Modification .......................................6 4.2 Indirect Modification ...................................7 5. Object Instrumentation vs. Source Instrumentation -

Debugging and Profiling with Arm Tools
Debugging and Profiling with Arm Tools [email protected] • Ryan Hulguin © 2018 Arm Limited • 4/21/2018 Agenda • Introduction to Arm Tools • Remote Client Setup • Debugging with Arm DDT • Other Debugging Tools • Break • Examples with DDT • Lunch • Profiling with Arm MAP • Examples with MAP • Obtaining Support 2 © 2018 Arm Limited Introduction to Arm HPC Tools © 2018 Arm Limited Arm Forge An interoperable toolkit for debugging and profiling • The de-facto standard for HPC development • Available on the vast majority of the Top500 machines in the world • Fully supported by Arm on x86, IBM Power, Nvidia GPUs and Arm v8-A. Commercially supported by Arm • State-of-the art debugging and profiling capabilities • Powerful and in-depth error detection mechanisms (including memory debugging) • Sampling-based profiler to identify and understand bottlenecks Fully Scalable • Available at any scale (from serial to petaflopic applications) Easy to use by everyone • Unique capabilities to simplify remote interactive sessions • Innovative approach to present quintessential information to users Very user-friendly 4 © 2018 Arm Limited Arm Performance Reports Characterize and understand the performance of HPC application runs Gathers a rich set of data • Analyses metrics around CPU, memory, IO, hardware counters, etc. • Possibility for users to add their own metrics Commercially supported by Arm • Build a culture of application performance & efficiency awareness Accurate and astute • Analyses data and reports the information that matters to users insight • Provides simple guidance to help improve workloads’ efficiency • Adds value to typical users’ workflows • Define application behaviour and performance expectations Relevant advice • Integrate outputs to various systems for validation (e.g. -

5 Key Considerations Towards the Adoption of a Mainframe Inclusive Devops Strategy
5 Key Considerations Towards the Adoption of a Mainframe Inclusive DevOps Strategy Key considaetrations towards the adoption of a mainframe inclusive devops strategy PLANNING FOR DEVOPS IN MAINFRAME ENVIRONMENTS – KEY CONSIDERATIONS – A mountain of information is available around the implementation and practice of DevOps, collectively encompassing people, processes and technology. This ranges significantly from the implementation of tool chains to discussions around DevOps principles, devoid of technology. While technology itself does not guarantee a successful DevOps implementation, the right tools and solutions can help companies better enable a DevOps culture. Unfortunately, the majority of conversations regarding DevOps center around distributed environments, neglecting the platform that still runs more than 70% of the business and transaction systems in the world; the mainframe. It is estimated that 5 billion lines of new COBOL code are added to live systems every year. Furthermore, 55% of enterprise apps and an estimated 80% of mobile transactions touch the mainframe at some point. Like their distributed brethren, mainframe applications benefit from DevOps practices, boosting speed and lowering risk. Instead of continuing to silo mainframe and distributed development, it behooves practitioners to increase communication and coordination between these environments to help address the pressure of delivering release cycles at an accelerated pace, while improving product and service quality. And some vendors are doing just that. Today, vendors are increasing their focus as it relates to the modernization of the mainframe, to not only better navigate the unavoidable generation shift in mainframe staffing, but to also better bridge mainframe and distributed DevOps cultures. DevOps is a significant topic incorporating community and culture, application and infrastructure development, operations and orchestration, and many more supporting concepts.