Proceedings of LAW VIII
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Diagramming Interpretation
Comment Diagramming Interpretation James Durlingt Sentence diagramming a method of showing the relationship between different parts of a sentence-has long been used by judges to interpret legal texts. This Comment documents how judges employ sentence diagrams in constitutional, statutory, and contract cases. Itfinds that diagrammingplays an important role in constitutionaland statutory cases, complementing traditional canons of legal interpretation, but that diagramming is less often used in contractcases forfear of disadvantaginggrammatically unsophisticatedparties. In addition, this Comment defends the practiceofjudicial diagramming as a way of improving textualist interpretation andpromoting broader values ofjudicial opinion writing. Introduction .................................................... 325 I. A Primer on Sentence Diagramming ................... ....... 329 II. Diagramming Judicial Interpretation ................... ....... 330 A. DiagrammingStatutes and Constitutions .................... 330 B. DiagrammingContracts. ........................ ...... 334 III.Diagramming as Interpretive Principle .................... 337 A. Why Diagram? ................................ ..... 337 1. Diagramming as Textualism ................. ...... 338 2. Diagramming as Legal Imagery ............. ........ 339 B. When to Diagram? ......................... ......... 341 Conclusion ..................................................... 341 Introduction Sentence diagramming-a method of showing the relationship between different parts of a sentence-may -

Sentence Diagraming
GLENCOE LANGUAGE ARTS Sentence Diagraming To the Teacher Sentence Diagraming is a blackline master workbook that offers samples, exercises, and step-by-step instructions to expand students’ knowledge of grammar and sentence structure. Each lesson teaches a part of a sentence and then illustrates a way to diagram it. Designed for students at all levels, Sentence Diagraming provides students with a tool for understanding written and spoken English. Glencoe/McGraw-Hill Copyright © The McGraw-Hill Companies, Inc. All rights reserved. Permission is granted to reproduce the material contained herein on the condition that such material be reproduced only for classroom use; be provided to students, teachers, and families without charge; and be used solely in conjunction with Glencoe Language Arts products. Any other reproduction, for use or sale, is prohibited without written permission of the publisher. Send all inquiries to: Glencoe/McGraw-Hill 8787 Orion Place Columbus, Ohio 43240 ISBN 0-07-824702-0 Printed in the United States of America. 1 2 3 4 5 6 7 8 9 10 045 04 03 02 01 00 PART I Simple Sentences . 1 Lesson 1 Simple Subjects and Simple Predicates I. 2 Simple subject and simple predicate Understood subject Lesson 2 Simple Subjects and Simple Predicates II . 3 Simple subject or simple predicate having more than one word Simple subject and simple predicate in inverted order Lesson 3 Compound Subjects and Compound Predicates I . 5 Compound subject Lesson 4 Compound Subjects and Compound Predicates II . 6 Compound predicate Lesson 5 Compound Subjects and Compound Predicates III . 7 Compound subject and compound predicate Lesson 6 Direct Objects and Indirect Objects I . -

Simple Sentence Diagramming
How to Diagram Sentences: Three 10-Minute Lessons Sentence diagramming can be a useful tool to make the abstract components of English grammar more concrete. Most students find that the visual image helps them better understand and remember grammatical terms, the parts of a sentence, and the basic rules of grammar. With practice, writers can use diagramming to diagnose their own grammatical errors and fix them. My Teaching Grammar and Mechanics Grades 4, 5, 6, 7, 8, and High School programs include a simple sentence diagram for each lesson (plus a mentor text, error analysis, practice in the writing context, and a formative assessment). The sentence diagrams are “simple,” because instead of requiring students to construct the entire diagram of a given sentence from scratch (takes too much class time), the simple sentence diagrams provide the drawing (the lines) and the words of the sentence that are not the focus of the grammar lesson. Check out how much students can learn about grammar with these two simple sentence diagrams from my programs. Both examples focus on adverbs. Simple Sentence Diagram Examples Easy Lesson Focus: An adverb can modify a verb and answer How? An adverb may be placed before or after the verb that it modifies. Modifies means to identify, define, describe, or limit. Examples: Carefully she answered. He walked slowly. Complete the sentence diagram for this sentence: They happily played video games. They played games happily video Compare your diagram to that on the display. Use a different color pen or pencil to place a √ above each correctly placed answer and change any errors. -

Diagramming Worksheets Name
Diagramming Worksheets Name:_________________ Sentence Diagram - A sentence diagram is a chart that shows the relation of the words, phrases, and clauses in a sentence to analyze a fault in a sentence or whether the word “who” or “whom” is to be used. Subject Noun And Predicate Verb subject noun predicate verb I sing. You are singing. He has been singing. We have been singing. You had been singing. They had sung. PrintNPractice.com – 1 – Date:__________ Diagramming Worksheets Name:_________________ Compound Subject Simple Sentence subject noun predicate verb subject noun conjunction Joseph and Mary sing. James and John wrote. Matthew, Mark, Luke, and John evangelized. PrintNPractice.com – 2 – Date:__________ Diagramming Worksheets Name:_________________ Compound Predicate Simple Sentence predicate verb subject noun conjunction predicate verb I worked and left. You have come and gone. He will come or regret. PrintNPractice.com – 3 – Date:__________ Diagramming Worksheets Name:_________________ Dummy Subjects (Like direct address and exclamations) dummy subject subject noun predicate verb There fl ew a hawk. There arose a storm. It is encouraging to be together. v There grew a tree in the fi eld. PrintNPractice.com – 4 – Date:__________ Diagramming Worksheets Name:_________________ Direct Objects subject noun predicate verb direct object John wrote testimonials. Laura likes apples and bananas. Paul wrote letters. Joseph built tables. PrintNPractice.com – 5 – Date:__________ Diagramming Worksheets Name:_________________ Indirect Objects subject noun predicate verb direct object indirect object Dr. Brown brought Dad medicine. Sally sent my Mother fl owers. John took the coach equipment. Andrew gave Michael and Anthony pictures. PrintNPractice.com – 6 – Date:__________ Diagramming Worksheets Name:_________________ Predicate Complements subject noun predicate verb predicate noun or adjective Predicate Noun Or Pronouns This is milk. -

The Effect of Sentence Diagramming on a Middle Level Learner's Composition
Elizabethtown College JayScholar Education: Student Scholarship & Creative Works Education Spring 2020 The Effect of Sentence Diagramming on a Middle Level Learner's Composition Alyssa J. Van Lenten Elizabethtown College, [email protected] Follow this and additional works at: https://jayscholar.etown.edu/edstu Part of the Education Commons Recommended Citation Van Lenten, Alyssa J., "The Effect of Sentence Diagramming on a Middle Level Learner's Composition" (2020). Education: Student Scholarship & Creative Works. 25. https://jayscholar.etown.edu/edstu/25 This Student Research Paper is brought to you for free and open access by the Education at JayScholar. It has been accepted for inclusion in Education: Student Scholarship & Creative Works by an authorized administrator of JayScholar. For more information, please contact [email protected]. Honors Senior Thesis Release Agreement Form The High Library supports the preservation and dissemination of all papers and projects completed as part of the requirements for the Elizabethtown College Honors Program (Honors Senior Thesis). Your signature on the following form confirms your authorship of this work and your permission for the High Library to make this work available. By agreeing to make it available, you are also agreeing to have this work included in the institutional repository, JayScholar. If you partnered with others in the creation of this work, your signature also confirms that you have obtained their permission to make this work available. Should any concerns arise regarding making -

Chapter 4 Grammar and Graphical Semiotics in Early Syntactic Diagrams: Clark (1847) and Reed-Kellogg (1876)
Chapter 4 Grammar and graphical semiotics in early syntactic diagrams: Clark (1847) and Reed-Kellogg (1876) Nicolas Mazziotta Université de Liège This paper shows that the authors who first used diagrams to represent syntactic structures chose graphical conventions that constrained the way they could repre- sent their analyses. Some graphical conventions may look similar despite following different rationales. Conversely, they may also look different and yet be grounded in the same logic. This second possibility becomes obvious when comparing the dia- gramming systems proposed by Clark (who uses aggregated bubbles) and Reed & Kellogg (who use strokes). Nevertheless, two-dimensional objects such as bubbles offer more varied layout possibilities for drawing diagrams than one-dimensional objects such as strokes do. Consequently, authors have to add the representation for abstract concepts such as inclusion by means that are compatible with the basic objects they use. 1 Introduction This paper focuses on the graphical depiction of syntactic analysis. I will com- pare two early diagramming systems in order to show how graphical formalisms put constraints on what can be expressed, because of the spatial properties of the graphical units. I will focus on two aspects: how graphical devices represent linguistic units and how these graphical devices interact on the plane. The di- agrams under study were created in the United States, and date from the 19th century (Brittain 1973), thus preceding the advent of modern syntactic trees that Nicolas Mazziotta. 2020. Grammar and graphical semiotics in early syntactic dia- grams: Clark (1847) and Reed-Kellogg (1876). In Émilie Aussant & Jean-Michel Fortis (eds.), Historical journey in a linguistic archipelago: Descriptive concepts and case stud- ies, 67–81. -

Lesson 11 Predicate Adjectives
Chapter 2 - Adjectives and Adverbs Lesson 11 Predicate Adjectives A predicate adjective is an adjective that follows a linking verb to describe the subject of the sentence. On a sentence diagram, place the predicate adjective on the same line with the subject and linking verb. The predicate adjective is separated from the linking verb by a short diagonal line that does not break through the horizontal line. subject linking verb predicate adjective Examples: Elizabeth is beautiful. ↑ ↑ ↑ Subject Linking Predicate Verb Adjective Elizabeth is beautiful The pizza tastes delicious. ↑ ↑ ↑ Subject Linking Predicate Verb Adjective pizza tastes delicious The Copyright 2012 Digging Into Diagramming. All Rights Reserved. 37 Chapter 2 - Adjectives and Adverbs A. Diagram the subject, linking verb, and predicate adjective in these sentences. Make sure to diagram any articles and adjectives in each sentence as well. 1. That tall dancer is graceful. 2. My younger sister seems sad. 3. Those boys are talented. 4. The yellow cheese smells fresh. Copyright 2012 Digging Into Diagramming. All Rights Reserved. 38 Chapter 2 - Adjectives and Adverbs On a sentence diagram, place each adjective of a compound predicate adjective after the diagonal line on horizontal lines, one above the other, joined by diagonal lines. Place the conjunction on a dotted line that connects the predicate adjective lines. predicate adjective conjunction subject linking verb predicate adjective Examples: That lasagna tastes hot and delicious. ↑ ↑ ↑ ↑ Subject Linking Predicate Predicate Verb Adjective Adjective hot lasagna tastes and That delicious Remember, if the sentence has more then two predicate adjectives, the conjunction is moved to the other side of the dotted line. -
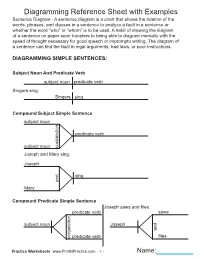
Diagramming Reference Sheet with Examples
Diagramming Reference Sheet with Examples Sentence Diagram - A sentence diagram is a chart that shows the relation of the words, phrases, and clauses in a sentence to analyze a fault in a sentence or whether the word “who” or “whom” is to be used. A habit of drawing the diagram of a sentence on paper soon transfers to being able to diagram mentally with the speed of thought necessary for good speech or impromptu writing. The diagram of a sentence can find the fault in legal arguments, bad laws, or poor instructions. DIAGRAMMING SIMPLE SENTENCES: Subject Noun And Predicate Verb subject noun predicate verb Singers sing. Singers sing Compound Subject Simple Sentence subject noun predicate verb subject noun conjunction Joseph and Mary sing. Joseph sing and Mary Compound Predicate Simple Sentence Joseph saws and files. predicate verb saws subject noun Joseph and files conjunction predicate verb Practice Worksheets www.PrintNPractice.com - 1 - Name: Diagramming Reference Sheet with Examples Dummy Subjects (Like direct address and exclamations) dummy subject subject noun predicate verb It is encouraging to be together. It to be together is encouraging There grew a tree in the field. There tree grew a in field the Direct Objects subject noun predicate verb direct object John wrote testimonials. John wrote testimonials Laura likes apples and bananas. apples Laura likes and bananas Practice Worksheets www.PrintNPractice.com - 2 - Name: Diagramming Reference Sheet with Examples Indirect Objects subject noun predicate verb direct object indirect object Dr. Brown brought Dad medicine. Dr. Brown brought medicine Dad Predicate Complements subject noun predicate verb predicate noun or adjective This is milk. -

High School English Diagraming a Sentence Flipped Lesson
High School English Diagraming a Sentence Flipped Lesson Objective: The learner will acquire the skills for sentence diagramming and appreciate how it helps them understand English grammar. "Diagramming gives you a tool to attack sentences globally, not in a fragmented approach. You get to see how parts interact. You see not only parts, but also their functions. When you diagram, you develop an eye for breaking down a sentence, so you can fix it more easily." – Paula H from http://www.redshift.com/~bonajo/diagram.htm The learner will be able to diagram a variety of compound and complex sentences and questions by the end of the unit, including sentences with a compound subject, compound predicate, direct object, indirect object, pronouns, appositive, adjective, adverb, prepositional phrase, gerund, understood subject, etc. Models of Instruction The Cooperative Learning Model is great for creating in students intrinsic motivation, positive interaction, and an attitude of helping each other learn. It has been proven to increase intellectual activity, mastery of material, positive feelings, social skills, and self-esteem. However, practice is needed for students to learn how to work cooperatively, efficiently, and interdependently. It is important to use fairly straightforward and familiar cognitive tasks for the initial training, to change partners for various activities, and to introduce more complex cognitive tasks and more complex cooperative sets later. The following cooperative structures are used in this lesson: Jigsaw (in groups of four): Each group member is becomes a specialist for a different part of the assignment. The specialists from each group meet together to learn the material. -

A Case Study in Greek Syntax
A Case Study in Greek Syntax: James 1.19-20 Logos Bible Software have commenced implementation of two different projects that encode levels of syntactic information in the Greek New Testament. One project, the OpenText.org Syntactically Analyzed Greek New Testament, provides information for the entire Greek New Testament. Another project, the Lexham Syntactic Greek New Testament, is being released in stages as it is completed. The first release will include the General Epistles (Hebrews-Jude) and likely Revelation. The first public release for both databases will likely be in the first quarter of 2006, with the next major release of Logos Bible Software. This paper works through aspects of James 1.19-20 using both Greek syntactic databases and provides a comparison of the information contained in each database.1 The Text: James 1.19-20 19 Ἴστε, ἀδελφοί μου ἀγαπητοί· ἔστω δὲ πᾶς 19 Know this, my beloved brothers: let every ἄνθρωπος ταχὺς εἰς τὸ ἀκοῦσαι, βραδὺς εἰς τὸ person be quick to hear, slow to speak, slow to λαλῆσαι, βραδὺς εἰς ὀργήν·20 ὀργὴ γὰρ ἀνδρὸς anger; 20 for the anger of man does not produce δικαιοσύνην θεοῦ οὐκ ἐργάζεται. (NA27) the righteousness that God requires. (ESV) These verses were chosen because the structure of the verses is (relatively) clear with repetition. Additionally, the verses form one sentence in the NA/UBS text. Evaluating the encoding of these verses in each database will allow a basis of comparison to see the strengths of each encoding as well as the differences between them. The Lexham Syntactic Greek New Testament The Lexham Syntactic Greek New Testament (Lexham SGNT) represents the ongoing work of Dr. -

Grammar Handout.Cwk
GRAMMAR A Magic Lens for Understanding Our Own Ideas Michael Clay Thompson [email protected] Royal Fireworks Press 845 726-4444 www.rfwp.com Selections from The Magic Lens, Copyright 2006, Royal Fireworks Press www.rfwp.com a term total 8 PARTS OF SPEECH 5 PARTS OF SENTENCE noun sentence proper / common fragment singular / plural subject pronoun predicate subject / object simple / complete relative direct object demonstrative indirect object person, 1, 2, 3 subject complement adjective predicate nom degree predicate adj pos, compar, superl article definite indefinite verb 2 CLAUSES tense independent perfect tenses dependent helping verb sentence structure singular / plural simple active / passive voice compound action / linking complex mood compound-complex adverb sentence purpose conjunction declarative coordinating imperative subordinating interrogative correlative exclamatory preposition object of prep interjection 3 PHRASES phrase prepositional appositive verbal gerund participle infinitive Selections from The Magic Lens, Copyright 2006, Royal Fireworks Press www.rfwp.com Magic Lens Unified Pronoun Rule A subject is a subject and an object is an object. Selections from The Magic Lens, Copyright 2006, Royal Fireworks Press www.rfwp.com AV DO IO subj LV SC The Logic of Sentence Analysis Find the subject/predicate set. Is the verb ACTION or LINKING? If the verb is action, then Do not look for a subject complement. Look for a direct object. If you find a direct object, then Look for an indirect object. If the verb is linking, then Do not look for a direct object. Look for a subject complement. Look for the next subject/predicate set and repeat. Selections from The Magic Lens, Copyright 2006, Royal Fireworks Press www.rfwp.com Four-Level Analysis Michael C. -

Diagramming Worksheets Name
Diagramming Worksheets Name:_________________ Sentence Diagram - A sentence diagram is a chart that shows the relation of the words, phrases, and clauses in a sentence to analyze a fault in a sentence or whether the word “who” or “whom” is to be used. Subject Noun And Predicate Verb subject noun predicate verb I sing. I sing. You are singing. You are singing. He has been singing. He has been singing. We have been singing. We have been singing. You had been singing. You had been singing They had sung. They had sung. PrintNPractice.com – 1 – Date:__________ Diagramming Worksheets Name:_________________ Compound Subject Simple Sentence subject noun predicate verb subject noun conjunction Joseph and Mary sing. Joseph and sing. Mary James and John wrote. James and wrote. John Matthew, Mark, Luke, and John evangelized. Matthew Mark and evangelized. Luke John PrintNPractice.com – 2 – Date:__________ Diagramming Worksheets Name:_________________ Compound Predicate Simple Sentence predicate verb subject noun conjunction predicate verb I worked and left. worked I and left. You have come and gone. have come You and (have) gone. He will come or regret. will come He or regret PrintNPractice.com – 3 – Date:__________ Diagramming Worksheets Name:_________________ Dummy Subjects (Like direct address and exclamations) dummy subject subject noun predicate verb There fl ew a hawk. There hawk. fl e w a There arose a storm. There storm. arose a It is encouraging to be together. It to be together. v is encouraging There grew a tree in the fi eld. There tree grew a in fi eld. the PrintNPractice.com – 4 – Date:__________ Diagramming Worksheets Name:_________________ Direct Objects subject noun predicate verb direct object John wrote testimonials.