Leveraging Large Genomic Datasets to Illuminate the Pathobiology of Autism Spectrum Disorders
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

The RNA Response to DNA Damage
ÔØ ÅÒÙ×Ö ÔØ The RNA response to DNA damage Luciana E. Giono, Nicol´as Nieto Moreno, Adri´an E. Cambindo Botto, Gwendal Dujardin, Manuel J. Mu˜noz, Alberto R. Kornblihtt PII: S0022-2836(16)00177-7 DOI: doi: 10.1016/j.jmb.2016.03.004 Reference: YJMBI 65022 To appear in: Journal of Molecular Biology Received date: 10 December 2015 Revised date: 1 March 2016 Accepted date: 7 March 2016 Please cite this article as: Giono, L.E., Moreno, N.N., Botto, A.E.C., Dujardin, G., Mu˜noz, M.J. & Kornblihtt, A.R., The RNA response to DNA damage, Journal of Molec- ular Biology (2016), doi: 10.1016/j.jmb.2016.03.004 This is a PDF file of an unedited manuscript that has been accepted for publication. As a service to our customers we are providing this early version of the manuscript. The manuscript will undergo copyediting, typesetting, and review of the resulting proof before it is published in its final form. Please note that during the production process errors may be discovered which could affect the content, and all legal disclaimers that apply to the journal pertain. ACCEPTED MANUSCRIPT The RNA response to DNA damage Luciana E. Giono1, Nicolás Nieto Moreno1, Adrián E. Cambindo Botto1, Gwendal Dujardin1,2, Manuel J. Muñoz1, and Alberto R. Kornblihtt1* 1Instituto de Fisiología, Biología Molecular y Neurociencias (IFIBYNE-UBA-CONICET) and Departamento de Fisiología, Biología Molecular y Celular, Facultad de Ciencias Exactas y Naturales, Universidad de Buenos Aires, Ciudad Universitaria, Pabellón 2, C1428EHA Buenos Aires, Argentina 2Centre for GenomicACCEPTED Regulation. Dr. -

The Rise and Fall of the Bovine Corpus Luteum
University of Nebraska Medical Center DigitalCommons@UNMC Theses & Dissertations Graduate Studies Spring 5-6-2017 The Rise and Fall of the Bovine Corpus Luteum Heather Talbott University of Nebraska Medical Center Follow this and additional works at: https://digitalcommons.unmc.edu/etd Part of the Biochemistry Commons, Molecular Biology Commons, and the Obstetrics and Gynecology Commons Recommended Citation Talbott, Heather, "The Rise and Fall of the Bovine Corpus Luteum" (2017). Theses & Dissertations. 207. https://digitalcommons.unmc.edu/etd/207 This Dissertation is brought to you for free and open access by the Graduate Studies at DigitalCommons@UNMC. It has been accepted for inclusion in Theses & Dissertations by an authorized administrator of DigitalCommons@UNMC. For more information, please contact [email protected]. THE RISE AND FALL OF THE BOVINE CORPUS LUTEUM by Heather Talbott A DISSERTATION Presented to the Faculty of the University of Nebraska Graduate College in Partial Fulfillment of the Requirements for the Degree of Doctor of Philosophy Biochemistry and Molecular Biology Graduate Program Under the Supervision of Professor John S. Davis University of Nebraska Medical Center Omaha, Nebraska May, 2017 Supervisory Committee: Carol A. Casey, Ph.D. Andrea S. Cupp, Ph.D. Parmender P. Mehta, Ph.D. Justin L. Mott, Ph.D. i ACKNOWLEDGEMENTS This dissertation was supported by the Agriculture and Food Research Initiative from the USDA National Institute of Food and Agriculture (NIFA) Pre-doctoral award; University of Nebraska Medical Center Graduate Student Assistantship; University of Nebraska Medical Center Exceptional Incoming Graduate Student Award; the VA Nebraska-Western Iowa Health Care System Department of Veterans Affairs; and The Olson Center for Women’s Health, Department of Obstetrics and Gynecology, Nebraska Medical Center. -

Modes of Interaction of KMT2 Histone H3 Lysine 4 Methyltransferase/COMPASS Complexes with Chromatin
cells Review Modes of Interaction of KMT2 Histone H3 Lysine 4 Methyltransferase/COMPASS Complexes with Chromatin Agnieszka Bochy ´nska,Juliane Lüscher-Firzlaff and Bernhard Lüscher * ID Institute of Biochemistry and Molecular Biology, Medical School, RWTH Aachen University, Pauwelsstrasse 30, 52057 Aachen, Germany; [email protected] (A.B.); jluescher-fi[email protected] (J.L.-F.) * Correspondence: [email protected]; Tel.: +49-241-8088850; Fax: +49-241-8082427 Received: 18 January 2018; Accepted: 27 February 2018; Published: 2 March 2018 Abstract: Regulation of gene expression is achieved by sequence-specific transcriptional regulators, which convey the information that is contained in the sequence of DNA into RNA polymerase activity. This is achieved by the recruitment of transcriptional co-factors. One of the consequences of co-factor recruitment is the control of specific properties of nucleosomes, the basic units of chromatin, and their protein components, the core histones. The main principles are to regulate the position and the characteristics of nucleosomes. The latter includes modulating the composition of core histones and their variants that are integrated into nucleosomes, and the post-translational modification of these histones referred to as histone marks. One of these marks is the methylation of lysine 4 of the core histone H3 (H3K4). While mono-methylation of H3K4 (H3K4me1) is located preferentially at active enhancers, tri-methylation (H3K4me3) is a mark found at open and potentially active promoters. Thus, H3K4 methylation is typically associated with gene transcription. The class 2 lysine methyltransferases (KMTs) are the main enzymes that methylate H3K4. KMT2 enzymes function in complexes that contain a necessary core complex composed of WDR5, RBBP5, ASH2L, and DPY30, the so-called WRAD complex. -

Atrazine and Cell Death Symbol Synonym(S)
Supplementary Table S1: Atrazine and Cell Death Symbol Synonym(s) Entrez Gene Name Location Family AR AIS, Andr, androgen receptor androgen receptor Nucleus ligand- dependent nuclear receptor atrazine 1,3,5-triazine-2,4-diamine Other chemical toxicant beta-estradiol (8R,9S,13S,14S,17S)-13-methyl- Other chemical - 6,7,8,9,11,12,14,15,16,17- endogenous decahydrocyclopenta[a]phenanthrene- mammalian 3,17-diol CGB (includes beta HCG5, CGB3, CGB5, CGB7, chorionic gonadotropin, beta Extracellular other others) CGB8, chorionic gonadotropin polypeptide Space CLEC11A AW457320, C-type lectin domain C-type lectin domain family 11, Extracellular growth factor family 11, member A, STEM CELL member A Space GROWTH FACTOR CYP11A1 CHOLESTEROL SIDE-CHAIN cytochrome P450, family 11, Cytoplasm enzyme CLEAVAGE ENZYME subfamily A, polypeptide 1 CYP19A1 Ar, ArKO, ARO, ARO1, Aromatase cytochrome P450, family 19, Cytoplasm enzyme subfamily A, polypeptide 1 ESR1 AA420328, Alpha estrogen receptor,(α) estrogen receptor 1 Nucleus ligand- dependent nuclear receptor estrogen C18 steroids, oestrogen Other chemical drug estrogen receptor ER, ESR, ESR1/2, esr1/esr2 Nucleus group estrone (8R,9S,13S,14S)-3-hydroxy-13-methyl- Other chemical - 7,8,9,11,12,14,15,16-octahydro-6H- endogenous cyclopenta[a]phenanthren-17-one mammalian G6PD BOS 25472, G28A, G6PD1, G6PDX, glucose-6-phosphate Cytoplasm enzyme Glucose-6-P Dehydrogenase dehydrogenase GATA4 ASD2, GATA binding protein 4, GATA binding protein 4 Nucleus transcription TACHD, TOF, VSD1 regulator GHRHR growth hormone releasing -

S41467-020-18249-3.Pdf
ARTICLE https://doi.org/10.1038/s41467-020-18249-3 OPEN Pharmacologically reversible zonation-dependent endothelial cell transcriptomic changes with neurodegenerative disease associations in the aged brain Lei Zhao1,2,17, Zhongqi Li 1,2,17, Joaquim S. L. Vong2,3,17, Xinyi Chen1,2, Hei-Ming Lai1,2,4,5,6, Leo Y. C. Yan1,2, Junzhe Huang1,2, Samuel K. H. Sy1,2,7, Xiaoyu Tian 8, Yu Huang 8, Ho Yin Edwin Chan5,9, Hon-Cheong So6,8, ✉ ✉ Wai-Lung Ng 10, Yamei Tang11, Wei-Jye Lin12,13, Vincent C. T. Mok1,5,6,14,15 &HoKo 1,2,4,5,6,8,14,16 1234567890():,; The molecular signatures of cells in the brain have been revealed in unprecedented detail, yet the ageing-associated genome-wide expression changes that may contribute to neurovas- cular dysfunction in neurodegenerative diseases remain elusive. Here, we report zonation- dependent transcriptomic changes in aged mouse brain endothelial cells (ECs), which pro- minently implicate altered immune/cytokine signaling in ECs of all vascular segments, and functional changes impacting the blood–brain barrier (BBB) and glucose/energy metabolism especially in capillary ECs (capECs). An overrepresentation of Alzheimer disease (AD) GWAS genes is evident among the human orthologs of the differentially expressed genes of aged capECs, while comparative analysis revealed a subset of concordantly downregulated, functionally important genes in human AD brains. Treatment with exenatide, a glucagon-like peptide-1 receptor agonist, strongly reverses aged mouse brain EC transcriptomic changes and BBB leakage, with associated attenuation of microglial priming. We thus revealed tran- scriptomic alterations underlying brain EC ageing that are complex yet pharmacologically reversible. -

Association of Gene Ontology Categories with Decay Rate for Hepg2 Experiments These Tables Show Details for All Gene Ontology Categories
Supplementary Table 1: Association of Gene Ontology Categories with Decay Rate for HepG2 Experiments These tables show details for all Gene Ontology categories. Inferences for manual classification scheme shown at the bottom. Those categories used in Figure 1A are highlighted in bold. Standard Deviations are shown in parentheses. P-values less than 1E-20 are indicated with a "0". Rate r (hour^-1) Half-life < 2hr. Decay % GO Number Category Name Probe Sets Group Non-Group Distribution p-value In-Group Non-Group Representation p-value GO:0006350 transcription 1523 0.221 (0.009) 0.127 (0.002) FASTER 0 13.1 (0.4) 4.5 (0.1) OVER 0 GO:0006351 transcription, DNA-dependent 1498 0.220 (0.009) 0.127 (0.002) FASTER 0 13.0 (0.4) 4.5 (0.1) OVER 0 GO:0006355 regulation of transcription, DNA-dependent 1163 0.230 (0.011) 0.128 (0.002) FASTER 5.00E-21 14.2 (0.5) 4.6 (0.1) OVER 0 GO:0006366 transcription from Pol II promoter 845 0.225 (0.012) 0.130 (0.002) FASTER 1.88E-14 13.0 (0.5) 4.8 (0.1) OVER 0 GO:0006139 nucleobase, nucleoside, nucleotide and nucleic acid metabolism3004 0.173 (0.006) 0.127 (0.002) FASTER 1.28E-12 8.4 (0.2) 4.5 (0.1) OVER 0 GO:0006357 regulation of transcription from Pol II promoter 487 0.231 (0.016) 0.132 (0.002) FASTER 6.05E-10 13.5 (0.6) 4.9 (0.1) OVER 0 GO:0008283 cell proliferation 625 0.189 (0.014) 0.132 (0.002) FASTER 1.95E-05 10.1 (0.6) 5.0 (0.1) OVER 1.50E-20 GO:0006513 monoubiquitination 36 0.305 (0.049) 0.134 (0.002) FASTER 2.69E-04 25.4 (4.4) 5.1 (0.1) OVER 2.04E-06 GO:0007050 cell cycle arrest 57 0.311 (0.054) 0.133 (0.002) -
Technical Note, Appendix: an Analysis of Blood Processing Methods to Prepare Samples for Genechip® Expression Profiling (Pdf, 1
Appendix 1: Signature genes for different blood cell types. Blood Cell Type Source Probe Set Description Symbol Blood Cell Type Source Probe Set Description Symbol Fraction ID Fraction ID Mono- Lympho- GSK 203547_at CD4 antigen (p55) CD4 Whitney et al. 209813_x_at T cell receptor TRG nuclear cytes gamma locus cells Whitney et al. 209995_s_at T-cell leukemia/ TCL1A Whitney et al. 203104_at colony stimulating CSF1R lymphoma 1A factor 1 receptor, Whitney et al. 210164_at granzyme B GZMB formerly McDonough (granzyme 2, feline sarcoma viral cytotoxic T-lymphocyte- (v-fms) oncogene associated serine homolog esterase 1) Whitney et al. 203290_at major histocompatibility HLA-DQA1 Whitney et al. 210321_at similar to granzyme B CTLA1 complex, class II, (granzyme 2, cytotoxic DQ alpha 1 T-lymphocyte-associated Whitney et al. 203413_at NEL-like 2 (chicken) NELL2 serine esterase 1) Whitney et al. 203828_s_at natural killer cell NK4 (H. sapiens) transcript 4 Whitney et al. 212827_at immunoglobulin heavy IGHM Whitney et al. 203932_at major histocompatibility HLA-DMB constant mu complex, class II, Whitney et al. 212998_x_at major histocompatibility HLA-DQB1 DM beta complex, class II, Whitney et al. 204655_at chemokine (C-C motif) CCL5 DQ beta 1 ligand 5 Whitney et al. 212999_x_at major histocompatibility HLA-DQB Whitney et al. 204661_at CDW52 antigen CDW52 complex, class II, (CAMPATH-1 antigen) DQ beta 1 Whitney et al. 205049_s_at CD79A antigen CD79A Whitney et al. 213193_x_at T cell receptor beta locus TRB (immunoglobulin- Whitney et al. 213425_at Homo sapiens cDNA associated alpha) FLJ11441 fis, clone Whitney et al. 205291_at interleukin 2 receptor, IL2RB HEMBA1001323, beta mRNA sequence Whitney et al. -

Genome-Wide Transcriptional Sequencing Identifies Novel Mutations in Metabolic Genes in Human Hepatocellular Carcinoma DAOUD M
CANCER GENOMICS & PROTEOMICS 11 : 1-12 (2014) Genome-wide Transcriptional Sequencing Identifies Novel Mutations in Metabolic Genes in Human Hepatocellular Carcinoma DAOUD M. MEERZAMAN 1,2 , CHUNHUA YAN 1, QING-RONG CHEN 1, MICHAEL N. EDMONSON 1, CARL F. SCHAEFER 1, ROBERT J. CLIFFORD 2, BARBARA K. DUNN 3, LI DONG 2, RICHARD P. FINNEY 1, CONSTANCE M. CULTRARO 2, YING HU1, ZHIHUI YANG 2, CU V. NGUYEN 1, JENNY M. KELLEY 2, SHUANG CAI 2, HONGEN ZHANG 2, JINGHUI ZHANG 1,4 , REBECCA WILSON 2, LAUREN MESSMER 2, YOUNG-HWA CHUNG 5, JEONG A. KIM 5, NEUNG HWA PARK 6, MYUNG-SOO LYU 6, IL HAN SONG 7, GEORGE KOMATSOULIS 1 and KENNETH H. BUETOW 1,2 1Center for Bioinformatics and Information Technology, National Cancer Institute, Rockville, MD, U.S.A.; 2Laboratory of Population Genetics, National Cancer Institute, National Cancer Institute, Bethesda, MD, U.S.A.; 3Basic Prevention Science Research Group, Division of Cancer Prevention, National Cancer Institute, Bethesda, MD, U.S.A; 4Department of Biotechnology/Computational Biology, St. Jude Children’s Research Hospital, Memphis, TN, U.S.A.; 5Department of Internal Medicine, University of Ulsan College of Medicine, Asan Medical Center, Seoul, Korea; 6Department of Internal Medicine, University of Ulsan College of Medicine, Ulsan University Hospital, Ulsan, Korea; 7Department of Internal Medicine, College of Medicine, Dankook University, Cheon-An, Korea Abstract . We report on next-generation transcriptome Worldwide, liver cancer is the fifth most common cancer and sequencing results of three human hepatocellular carcinoma the third most common cause of cancer-related mortality (1). tumor/tumor-adjacent pairs. -

Get.Com Oncotarget, 2018, Vol
www.oncotarget.com Oncotarget, 2018, Vol. 9, (No. 35), pp: 24122-24139 Research Paper Etoposide-induced DNA damage affects multiple cellular pathways in addition to DNA damage response Fengxiang Wei1, Peng Hao2, Xiangzhong Zhang3, Haiyan Hu4, Dan Jiang5, Aihua Yin6, Lijuan Wen1,7, Lihong Zheng8, Jeffrey Zheru He9, Wenjuan Mei10,12, Hui Zeng11,12 and Damu Tang12 1The Genetics Laboratory, Shenzhen Longgang District Maternity and Child Healthcare Hospital, Shenzhen, Guangdong, PR China 2Division of Nephrology, The First Affiliated Hospital of Jiamusi University, Jiamusi, Heilongjiang, PR China 3Department of Hematology, The Third Affiliated Hospital of Sun Yat-Sen University, Guangzhou, Guangdong, PR China 4Department of Obstetrics and Gynecology, Shenzhen Maternal and Child Healthcare Hospital, Southern Medical University, Shenzhen, Guangdong, PR China 5Shenzhen Hua Da Clinical Laboratory Center Co., Ltd., Shenzhen, Guangdong, PR China 6Maternal and Children Metabolic-Genetic Key Laboratory, Guangdong Women and Children Hospital, Guangzhou, PR China 7Zunyi Medical University, Zunyi, Guizhou, PR China 8Department of Biogenetics, Qiqihar Medical University, Qiqihar, Heilongjiang, PR China 9Harvard Medical School and Massachusetts General Hospital, Boston, MA, USA 10Department of Nephrology, The First Affiliated Hospital of Nanchang University, Nanchang, Jiangxi, PR China 11Department of Thoracic Surgery, Fourth Hospital of Hebei Medical University, Shijiazhuang City, Hebei, PR China 12Division of Nephrology, Department of Medicine, McMaster -

Open Data for Differential Network Analysis in Glioma
International Journal of Molecular Sciences Article Open Data for Differential Network Analysis in Glioma , Claire Jean-Quartier * y , Fleur Jeanquartier y and Andreas Holzinger Holzinger Group HCI-KDD, Institute for Medical Informatics, Statistics and Documentation, Medical University Graz, Auenbruggerplatz 2/V, 8036 Graz, Austria; [email protected] (F.J.); [email protected] (A.H.) * Correspondence: [email protected] These authors contributed equally to this work. y Received: 27 October 2019; Accepted: 3 January 2020; Published: 15 January 2020 Abstract: The complexity of cancer diseases demands bioinformatic techniques and translational research based on big data and personalized medicine. Open data enables researchers to accelerate cancer studies, save resources and foster collaboration. Several tools and programming approaches are available for analyzing data, including annotation, clustering, comparison and extrapolation, merging, enrichment, functional association and statistics. We exploit openly available data via cancer gene expression analysis, we apply refinement as well as enrichment analysis via gene ontology and conclude with graph-based visualization of involved protein interaction networks as a basis for signaling. The different databases allowed for the construction of huge networks or specified ones consisting of high-confidence interactions only. Several genes associated to glioma were isolated via a network analysis from top hub nodes as well as from an outlier analysis. The latter approach highlights a mitogen-activated protein kinase next to a member of histondeacetylases and a protein phosphatase as genes uncommonly associated with glioma. Cluster analysis from top hub nodes lists several identified glioma-associated gene products to function within protein complexes, including epidermal growth factors as well as cell cycle proteins or RAS proto-oncogenes. -

Deletions of Chromosome 7Q Affect Nuclear Organization And
cancers Article Deletions of Chromosome 7q Affect Nuclear Organization and HLXB9Gene Expression in Hematological Disorders Concetta Federico 1 , Temitayo Owoka 2, Denise Ragusa 2, Valentina Sturiale 1, Domenica Caponnetto 1, Claudia Giovanna Leotta 1, Francesca Bruno 1 , Helen A. Foster 3,5, Silvia Rigamonti 4, Giovanni Giudici 4, Giovanni Cazzaniga 4, Joanna M. Bridger 2, Cristina Sisu 5 , Salvatore Saccone 1,* and Sabrina Tosi 2,* 1 Department of Biological, Geological and Environmental Sciences, University of Catania, via Androne 81, 95124 Catania CT, Italy; [email protected] (C.F.); [email protected] (V.S.); [email protected] (D.C.); [email protected] (C.G.L.); [email protected] (F.B.) 2 Genome Engineering and Maintenance Network, Institute of Environment, Health and Societies, Brunel University London, Kingston Lane UB8 3PH, UK; [email protected] (T.O.); [email protected] (D.R.); [email protected] (J.M.B.) 3 Department of Biological and Environmental Sciences, School of Life and Medical Sciences, University of Hertfordshire, Hatfield AL10 9AB, UK; [email protected] 4 Associazione Italiana Ematologia Oncologia Pediatrica (AIEOP), Centro Ricerca Tettamanti, Pediatric Department, University of Milano-Bicocca, 20900 Monza, Italy; [email protected] (S.R.); [email protected] (G.G.); [email protected] (G.C.) 5 College of Health and Life Science, Brunel University London, Kingston Lane UB8 3PH, UK; [email protected] * Correspondence: [email protected] (S.S.); [email protected] (S.T.) Received: 12 March 2019; Accepted: 19 April 2019; Published: 25 April 2019 Abstract: The radial spatial positioning of individual gene loci within interphase nuclei has been associated with up- and downregulation of their expression. -
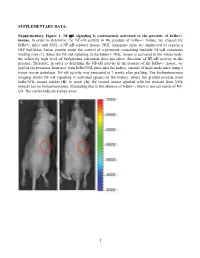
Activation of NF-Κb Signaling Promotes Prostate Cancer Progression in the Mouse and Predicts Poor Progression and Death in Pati
SUPPLEMENTARY DATA: Supplementary Figure 1. NF-B signaling is continuously activated in the prostate of - mouse. In order to determine the NF- '- mouse, we crossed the '- mice with NGL, a NF-B reporter mouse. NGL transgenic mice are engineered to express a GFP/luciferase fusion protein under the control of a promoter containing multiple NF-B consensus binding sites (1). Since the NF-'- NGL mouse is activated in the whole body, the relatively high level of background activation does not allow detection of NF- prostate. Therefore, in order to determine the NF-the '- mouse, we grafted the prostates from 'o the kidney capsule of male nude mice using a tissue rescue technique. NF-B activity was measured at 7 weeks after grafting. The bioluminescence imaging shows NF-B signaling is activated (green) in the kidney, where the grafted prostate from ' use resides (B). In panel (A), the control mouse (grafted with the prostate from NGL mouse) has no bioluminescence, illustrating that in the absence of '-, there is not activation of NF- B. The circles indicate kidney areas. 1 Supplementary Figure 2. NF-B signaling activated in the prostate of Myc/IB bigenic mouse. The prostates from Myc alone (Myc) and bigenic (Myc/IB) mice were harvested at 6 months of age. Activation of NF-B signaling in the prostate was determined by IHC staining of p65-pho antibody. 2 Supplementary Figure 3. Continuous activation of NF-B signaling promotes PCa progression in the Hi-Myc transgenic mouse. The prostates from Myc alone (Myc) and bigeneic (Myc/IB) mice were harvested at 6 months of age.