Least Squares: Fitting a Curve to Data Points
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Estimating Confidence Regions of Common Measures of (Baseline, Treatment Effect) On
Estimating confidence regions of common measures of (baseline, treatment effect) on dichotomous outcome of a population Li Yin1 and Xiaoqin Wang2* 1Department of Medical Epidemiology and Biostatistics, Karolinska Institute, Box 281, SE- 171 77, Stockholm, Sweden 2Department of Electronics, Mathematics and Natural Sciences, University of Gävle, SE-801 76, Gävle, Sweden (Email: [email protected]). *Corresponding author Abstract In this article we estimate confidence regions of the common measures of (baseline, treatment effect) in observational studies, where the measure of baseline is baseline risk or baseline odds while the measure of treatment effect is odds ratio, risk difference, risk ratio or attributable fraction, and where confounding is controlled in estimation of both baseline and treatment effect. To avoid high complexity of the normal approximation method and the parametric or non-parametric bootstrap method, we obtain confidence regions for measures of (baseline, treatment effect) by generating approximate distributions of the ML estimates of these measures based on one logistic model. Keywords: baseline measure; effect measure; confidence region; logistic model 1 Introduction Suppose that one conducts a randomized trial to investigate the effect of a dichotomous treatment z on a dichotomous outcome y of certain population, where = 0, 1 indicate the 푧 1 active respective control treatments while = 0, 1 indicate positive respective negative outcomes. With a sufficiently large sample,푦 covariates are essentially unassociated with treatments z and thus are not confounders. Let R = pr( = 1 | ) be the risk of = 1 given 푧 z. Then R is marginal with respect to covariates and thus푦 conditional푧 on treatment푦 z only, so 푧 R is also called marginal risk. -

Unsupervised Contour Representation and Estimation Using B-Splines and a Minimum Description Length Criterion Mário A
IEEE TRANSACTIONS ON IMAGE PROCESSING, VOL. 9, NO. 6, JUNE 2000 1075 Unsupervised Contour Representation and Estimation Using B-Splines and a Minimum Description Length Criterion Mário A. T. Figueiredo, Member, IEEE, José M. N. Leitão, Member, IEEE, and Anil K. Jain, Fellow, IEEE Abstract—This paper describes a new approach to adaptive having external/potential energy, which is a func- estimation of parametric deformable contours based on B-spline tion of certain features of the image The equilibrium (min- representations. The problem is formulated in a statistical imal total energy) configuration framework with the likelihood function being derived from a re- gion-based image model. The parameters of the image model, the (1) contour parameters, and the B-spline parameterization order (i.e., the number of control points) are all considered unknown. The is a compromise between smoothness (enforced by the elastic parameterization order is estimated via a minimum description nature of the model) and proximity to the desired image features length (MDL) type criterion. A deterministic iterative algorithm is (by action of the external potential). developed to implement the derived contour estimation criterion. Several drawbacks of conventional snakes, such as their “my- The result is an unsupervised parametric deformable contour: it adapts its degree of smoothness/complexity (number of control opia” (i.e., use of image data strictly along the boundary), have points) and it also estimates the observation (image) model stimulated a great amount of research; although most limitations parameters. The experiments reported in the paper, performed of the original formulation have been successfully addressed on synthetic and real (medical) images, confirm the adequacy and (see, e.g., [6], [9], [10], [34], [38], [43], [49], and [52]), non- good performance of the approach. -

Theory Pest.Pdf
Theory for PEST Users Zhulu Lin Dept. of Crop and Soil Sciences University of Georgia, Athens, GA 30602 [email protected] October 19, 2005 Contents 1 Linear Model Theory and Terminology 2 1.1 Amotivationexample ...................... 2 1.2 General linear regression model . 3 1.3 Parameterestimation. 6 1.3.1 Ordinary least squares estimator . 6 1.3.2 Weighted least squares estimator . 7 1.4 Uncertaintyanalysis ....................... 9 1.4.1 Variance-covariance matrix of βˆ and estimation of σ2 . 9 1.4.2 Confidence interval for βj ................ 9 1.4.3 Confidence region for β ................. 10 1.4.4 Confidence interval for E(y0) .............. 10 1.4.5 Prediction interval for a future observation y0 ..... 11 2 Nonlinear regression model 13 2.1 Linearapproximation. 13 2.2 Nonlinear least squares estimator . 14 2.3 Numericalmethods ........................ 14 2.3.1 Steepest Descent algorithm . 16 2.3.2 Gauss-Newton algorithm . 16 2.3.3 Levenberg-Marquardt algorithm . 18 2.3.4 Newton’smethods . 19 1 2.4 Uncertainty analysis . 22 2.4.1 Confidence intervals for parameter and model prediction 22 2.4.2 Nonlinear calibration-constrained method . 23 3 Miscellaneous 27 3.1 Convergence criteria . 27 3.2 Derivatives computation . 28 3.3 Parameter estimation of compartmental models . 28 3.4 Initial values and prior information . 29 3.5 Parametertransformation . 30 1 Linear Model Theory and Terminology Before discussing parameter estimation and uncertainty analysis for nonlin- ear models, we need to review linear model theory as many of the ideas and methods of estimation and analysis (inference) in nonlinear models are essentially linear methods applied to a linear approximate of the nonlinear models. -

Random Vectors
Random Vectors x is a p×1 random vector with a pdf probability density function f(x): Rp→R. Many books write X for the random vector and X=x for the realization of its value. E[X]= ∫ x f.(x) dx = µ Theorem: E[Ax+b]= AE[x]+b Covariance Matrix E[(x-µ)(x-µ)’]=var(x)=Σ (note the location of transpose) Theorem: Σ=E[xx’]-µµ’ If y is a random variable: covariance C(x,y)= E[(x-µ)(y-ν)’] Theorem: For constants a, A, var (a’x)=a’Σa, var(Ax+b)=AΣA’, C(x,x)=Σ, C(x,y)=C(y,x)’ Theorem: If x, y are independent RVs, then C(x,y)=0, but not conversely. Theorem: Let x,y have same dimension, then var(x+y)=var(x)+var(y)+C(x,y)+C(y,x) Normal Random Vectors The Central Limit Theorem says that if a focal random variable x consists of the sum of many other independent random variables, then the focal random variable will asymptotically have a 2 distribution that is basically of the form e−x , which we call “normal” because it is so common. 2 ⎛ x−µ ⎞ 1 − / 2 −(x−µ) (x−µ) / 2 1 ⎜ ⎟ 1 2 Normal random variable has pdf f (x) = e ⎝ σ ⎠ = e σ 2πσ2 2πσ2 Denote x p×1 normal random variable with pdf 1 −1 f (x) = e−(x−µ)'Σ (x−µ) (2π)p / 2 Σ 1/ 2 where µ is the mean vector and Σ is the covariance matrix: x~Np(µ,Σ). -

Chapter 26: Mathcad-Data Analysis Functions
Lecture 3 MATHCAD-DATA ANALYSIS FUNCTIONS Objectives Graphs in MathCAD Built-in Functions for basic calculations: Square roots, Systems of linear equations Interpolation on data sets Linear regression Symbolic calculation Graphing with MathCAD Plotting vector against vector: The vectors must have equal number of elements. MathCAD plots values in its default units. To change units in the plot……? Divide your axis by the desired unit. Or remove the units from the defined vectors Use Graph Toolbox or [Shift-2] Or Insert/Graph from menu Graphing 1 20 2 28 time 3 min Temp 35 K time 4 42 Time min 5 49 40 40 Temp Temp 20 20 100 200 300 2 4 time Time Graphing with MathCAD 1 20 Plotting element by 2 28 element: define a time 3 min Temp 35 K 4 42 range variable 5 49 containing as many i 04 element as each of the vectors. 40 i:=0..4 Temp i 20 100 200 300 timei QuickPlots Use when you want to x 0 0.12 see what a function looks like 1 Create a x-y graph Enter the function on sin(x) 0 y-axis with parameter(s) 1 Enter the parameter on 0 2 4 6 x-axis x Graphing with MathCAD Plotting multiple curves:up to 16 curves in a single graph. Example: For 2 dependent variables (y) and 1 independent variable (x) Press shift2 (create a x-y plot) On the y axis enter the first y variable then press comma to enter the second y variable. On the x axis enter your x variable. -
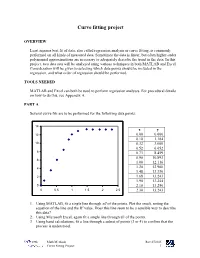
Curve Fitting Project
Curve fitting project OVERVIEW Least squares best fit of data, also called regression analysis or curve fitting, is commonly performed on all kinds of measured data. Sometimes the data is linear, but often higher-order polynomial approximations are necessary to adequately describe the trend in the data. In this project, two data sets will be analyzed using various techniques in both MATLAB and Excel. Consideration will be given to selecting which data points should be included in the regression, and what order of regression should be performed. TOOLS NEEDED MATLAB and Excel can both be used to perform regression analyses. For procedural details on how to do this, see Appendix A. PART A Several curve fits are to be performed for the following data points: 14 x y 12 0.00 0.000 0.10 1.184 10 0.32 3.600 0.52 6.052 8 0.73 8.459 0.90 10.893 6 1.00 12.116 4 1.20 12.900 1.48 13.330 2 1.68 13.243 1.90 13.244 0 2.10 13.250 0 0.5 1 1.5 2 2.5 2.30 13.243 1. Using MATLAB, fit a single line through all of the points. Plot the result, noting the equation of the line and the R2 value. Does this line seem to be a sensible way to describe this data? 2. Using Microsoft Excel, again fit a single line through all of the points. 3. Using hand calculations, fit a line through a subset of points (3 or 4) to confirm that the process is understood. -
Nonlinear Least-Squares Curve Fitting with Microsoft Excel Solver
Information • Textbooks • Media • Resources edited by Computer Bulletin Board Steven D. Gammon University of Idaho Moscow, ID 83844 Nonlinear Least-Squares Curve Fitting with Microsoft Excel Solver Daniel C. Harris Chemistry & Materials Branch, Research & Technology Division, Naval Air Warfare Center,China Lake, CA 93555 A powerful tool that is widely available in spreadsheets Unweighted Least Squares provides a simple means of fitting experimental data to non- linear functions. The procedure is so easy to use and its Experimental values of x and y from Figure 1 are listed mode of operation is so obvious that it is an excellent way in the first two columns of the spreadsheet in Figure 2. The for students to learn the underlying principle of least- vertical deviation of the ith point from the smooth curve is squares curve fitting. The purpose of this article is to intro- vertical deviation = yi (observed) – yi (calculated) (2) duce the method of Walsh and Diamond (1) to readers of = yi – (Axi + B/xi + C) this Journal, to extend their treatment to weighted least The least squares criterion is to find values of A, B, and squares, and to add a simple method for estimating uncer- C in eq 1 that minimize the sum of the squares of the verti- tainties in the least-square parameters. Other recipes for cal deviations of the points from the curve: curve fitting have been presented in numerous previous papers (2–16). n 2 Σ Consider the problem of fitting the experimental gas sum = yi ± Axi + B / xi + C (3) chromatography data (17) in Figure 1 with the van Deemter i =1 equation: where n is the total number of points (= 13 in Fig. -

(EU FP7 2013 - 612218/3D-NET) 3DNET Sops HOW-TO-DO PRACTICAL GUIDE
3D-NET (EU FP7 2013 - 612218/3D-NET) 3DNET SOPs HOW-TO-DO PRACTICAL GUIDE Curve fitting This is intended to be an aid-memoir for those involved in fitting biological data to dose response curves in why we do it and how to best do it. So why do we use non linear regression? Much of the data generated in Biology is sigmoidal dose response (E/[A]) curves, the aim is to generate estimates of upper and lower asymptotes, A50 and slope parameters and their associated confidence limits. How can we analyse E/[A] data? Why fit curves? What’s wrong with joining the dots? Fitting Uses all the data points to estimate each parameter Tell us the confidence that we can have in each parameter estimate Estimates a slope parameter Fitting curves to data is model fitting. The general equation for a sigmoidal dose-response curve is commonly referred to as the ‘Hill equation’ or the ‘four-parameter logistic equation”. (Top Bottom) Re sponse Bottom EC50hillslope 1 [Drug]hillslpoe The models most commonly used in Biology for fitting these data are ‘model 205 – Dose response one site -4 Parameter Logistic Model or Sigmoidal Dose-Response Model’ in XLfit (package used in ActivityBase or Excel) and ‘non-linear regression - sigmoidal variable slope’ in GraphPad Prism. What the computer does - Non-linear least squares Starts with an initial estimated value for each variable in the equation Generates the curve defined by these values Calculates the sum of squares Adjusts the variables to make the curve come closer to the data points (Marquardt method) Re-calculates the sum of squares Continues this iteration until there’s virtually no difference between successive fittings. -

Statistical Data Analysis Stat 4: Confidence Intervals, Limits, Discovery
Statistical Data Analysis Stat 4: confidence intervals, limits, discovery London Postgraduate Lectures on Particle Physics; University of London MSci course PH4515 Glen Cowan Physics Department Royal Holloway, University of London [email protected] www.pp.rhul.ac.uk/~cowan Course web page: www.pp.rhul.ac.uk/~cowan/stat_course.html G. Cowan Statistical Data Analysis / Stat 4 1 Interval estimation — introduction In addition to a ‘point estimate’ of a parameter we should report an interval reflecting its statistical uncertainty. Desirable properties of such an interval may include: communicate objectively the result of the experiment; have a given probability of containing the true parameter; provide information needed to draw conclusions about the parameter possibly incorporating stated prior beliefs. Often use +/- the estimated standard deviation of the estimator. In some cases, however, this is not adequate: estimate near a physical boundary, e.g., an observed event rate consistent with zero. We will look briefly at Frequentist and Bayesian intervals. G. Cowan Statistical Data Analysis / Stat 4 2 Frequentist confidence intervals Consider an estimator for a parameter θ and an estimate We also need for all possible θ its sampling distribution Specify upper and lower tail probabilities, e.g., α = 0.05, β = 0.05, then find functions uα(θ) and vβ(θ) such that: G. Cowan Statistical Data Analysis / Stat 4 3 Confidence interval from the confidence belt The region between uα(θ) and vβ(θ) is called the confidence belt. Find points where observed estimate intersects the confidence belt. This gives the confidence interval [a, b] Confidence level = 1 - α - β = probability for the interval to cover true value of the parameter (holds for any possible true θ). -

A Grid Algorithm for High Throughput Fitting of Dose-Response Curve Data Yuhong Wang*, Ajit Jadhav, Noel Southal, Ruili Huang and Dac-Trung Nguyen
Current Chemical Genomics, 2010, 4, 57-66 57 Open Access A Grid Algorithm for High Throughput Fitting of Dose-Response Curve Data Yuhong Wang*, Ajit Jadhav, Noel Southal, Ruili Huang and Dac-Trung Nguyen National Institutes of Health, NIH Chemical Genomics Center, 9800 Medical Center Drive, Rockville, MD 20850, USA Abstract: We describe a novel algorithm, Grid algorithm, and the corresponding computer program for high throughput fitting of dose-response curves that are described by the four-parameter symmetric logistic dose-response model. The Grid algorithm searches through all points in a grid of four dimensions (parameters) and finds the optimum one that corre- sponds to the best fit. Using simulated dose-response curves, we examined the Grid program’s performance in reproduc- ing the actual values that were used to generate the simulated data and compared it with the DRC package for the lan- guage and environment R and the XLfit add-in for Microsoft Excel. The Grid program was robust and consistently recov- ered the actual values for both complete and partial curves with or without noise. Both DRC and XLfit performed well on data without noise, but they were sensitive to and their performance degraded rapidly with increasing noise. The Grid program is automated and scalable to millions of dose-response curves, and it is able to process 100,000 dose-response curves from high throughput screening experiment per CPU hour. The Grid program has the potential of greatly increas- ing the productivity of large-scale dose-response data analysis and early drug discovery processes, and it is also applicable to many other curve fitting problems in chemical, biological, and medical sciences. -

Fitting Conics to Noisy Data Using Stochastic Linearization
Fitting Conics to Noisy Data Using Stochastic Linearization Marcus Baum and Uwe D. Hanebeck Abstract— Fitting conic sections, e.g., ellipses or circles, to LRF noisy data points is a fundamental sensor data processing problem, which frequently arises in robotics. In this paper, we introduce a new procedure for deriving a recursive Gaussian state estimator for fitting conics to data corrupted by additive Measurements Gaussian noise. For this purpose, the original exact implicit measurement equation is reformulated with the help of suitable Fig. 1: Laser rangefinder (LRF) scanning a circular object. approximations as an explicit measurement equation corrupted by multiplicative noise. Based on stochastic linearization, an efficient Gaussian state estimator is derived for the explicit measurement equation. The performance of the new approach distributions for the parameter vector of the conic based is evaluated by means of a typical ellipse fitting scenario. on Bayes’ rule. An explicit description of the parameter uncertainties with a probability distribution is in particular I. INTRODUCTION important for performing gating, i.e., dismissing unprobable In this work, the problem of fitting a conic section such measurements, and tracking multiple conics. Furthermore, as an ellipse or a circle to noisy data points is considered. the temporal evolution of the state can be captured with This fundamental problem arises in many applications related a stochastic system model, which allows to propagate the to robotics. A traditional application is computer vision, uncertainty about the state to the next time step. where ellipses and circles are fitted to features extracted A. Contributions from images [1]–[4] in order to detect, localize, and track objects. -

Confidence Intervals for Functions of Variance Components Kok-Leong Chiang Iowa State University
Iowa State University Capstones, Theses and Retrospective Theses and Dissertations Dissertations 2000 Confidence intervals for functions of variance components Kok-Leong Chiang Iowa State University Follow this and additional works at: https://lib.dr.iastate.edu/rtd Part of the Statistics and Probability Commons Recommended Citation Chiang, Kok-Leong, "Confidence intervals for functions of variance components " (2000). Retrospective Theses and Dissertations. 13890. https://lib.dr.iastate.edu/rtd/13890 This Dissertation is brought to you for free and open access by the Iowa State University Capstones, Theses and Dissertations at Iowa State University Digital Repository. It has been accepted for inclusion in Retrospective Theses and Dissertations by an authorized administrator of Iowa State University Digital Repository. For more information, please contact [email protected]. INFORMATION TO USERS This manuscript has been reproduced from the microfilm master. UMI films the text directly from the original or copy submitted. Thus, some thesis and dissertation copies are in typewriter face, while ottiers may be f^ any type of computer printer. The quality of this reproduction is dependent upon the quality of ttw copy submitted. Broken or indistinct print, colored or poor quality illustrations and photographs, print bleedthrough, substandard margins, and improper alignment can adversely affect reproduction. In the unlikely event that the author dkl not send UMI a complete manuscript and there are missing pages, these will be noted. Also, if unauthorized copyright material had to be removed, a note will indicate the deletion. Oversize materials (e.g.. maps, drawings, charts) are reproduced by sectioning the original, beginning at the upper left-hand comer and continuing from left to right in equal sections with small overiaps.