Learning Geometric Concepts Via Gaussian Surface Area
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Gauss's Law II
Gauss’s law II If a lightning bolt strikes a car (unless it is a convertible), electrons would quickly (in the order of nano seconds) move to the surface, so it is almost an ideal conductive shell that you can hide inside during a lightning storm! Reading: Mazur 24.7-25.2 Deriving Gauss’s law Applying Gauss’s law Electric potential energy Electrostatic work LECTURE 7 1 24.7 Deriving Gauss’s law Gauss’s law states that the flux through a closed surface is proportional to the enclosed charge, �"#$, such that �"#$ Φ& = �) LECTURE 7 2 Question: 24.7-1 (Flux from point charge) Consider a spherical Gaussian surface of radius � with a point charge � at the center. � 1 ⃗ The flux through a surface is given by Φ& = ∮1 � ⋅ ��. Using this definition for flux and Coulomb's law, calculate the flux through the Gaussian surface in terms of �, �, � and any constants. LECTURE 7 3 Question: 24.7-1 (Flux from point charge) answer Consider a spherical Gaussian surface of radius � with a point charge � at the center. � 1 ⃗ The flux through a surface is given by Φ& = ∮1 � ⋅ ��. Using this definition for flux and Coulomb's law, calculate the flux through the Gaussian surface in terms of �, �, � and any constants. The electric field is always normal to the Gaussian surface and has equal magnitude at all points on the surface. Therefore 1 1 1 � Φ = 3 � ⋅ ��⃗ = 3 ��� = � 3 �� = � 4��6 = � 4��6 = 4��� & �6 1 1 1 7 From Gauss’s law Φ& = 89 7 : Therefore Φ& = = 4���, and �) = 89 ;<= LECTURE 7 4 Reading quiz (Problem 24.70) There is a Gauss's law for gravity analogous to Gauss's law for electricity. -

Maxwell's Equations
Maxwell’s Equations Matt Hansen May 20, 2004 1 Contents 1 Introduction 3 2 The basics 3 2.1 Static charges . 3 2.2 Moving charges . 4 2.3 Magnetism . 4 2.4 Vector operations . 5 2.5 Calculus . 6 2.6 Flux . 6 3 History 7 4 Maxwell’s Equations 8 4.1 Maxwell’s Equations . 8 4.2 Gauss’ law for electricity . 8 4.3 Gauss’ law for magnetism . 10 4.4 Faraday’s law . 11 4.5 Ampere-Maxwell law . 13 5 Conclusion 14 2 1 Introduction If asked, most people outside a physics department would not be able to identify Maxwell’s equations, nor would they be able to state that they dealt with electricity and magnetism. However, Maxwell’s equations have many very important implications in the life of a modern person, so much so that people use devices that function off the principles in Maxwell’s equations every day without even knowing it. 2 The basics 2.1 Static charges In order to understand Maxwell’s equations, it is necessary to understand some basic things about electricity and magnetism first. Static electricity is easy to understand, in that it is just a charge which, as its name implies, does not move until it is given the chance to “escape” to the ground. Amounts of charge are measured in coulombs, abbreviated C. 1C is an extraordi- nary amount of charge, chosen rather arbitrarily to be the charge carried by 6.41418 · 1018 electrons. The symbol for charge in equations is q, sometimes with a subscript like q1 or qenc. -

6.007 Lecture 5: Electrostatics (Gauss's Law and Boundary
Electrostatics (Free Space With Charges & Conductors) Reading - Shen and Kong – Ch. 9 Outline Maxwell’s Equations (In Free Space) Gauss’ Law & Faraday’s Law Applications of Gauss’ Law Electrostatic Boundary Conditions Electrostatic Energy Storage 1 Maxwell’s Equations (in Free Space with Electric Charges present) DIFFERENTIAL FORM INTEGRAL FORM E-Gauss: Faraday: H-Gauss: Ampere: Static arise when , and Maxwell’s Equations split into decoupled electrostatic and magnetostatic eqns. Electro-quasistatic and magneto-quasitatic systems arise when one (but not both) time derivative becomes important. Note that the Differential and Integral forms of Maxwell’s Equations are related through ’ ’ Stoke s Theorem and2 Gauss Theorem Charges and Currents Charge conservation and KCL for ideal nodes There can be a nonzero charge density in the absence of a current density . There can be a nonzero current density in the absence of a charge density . 3 Gauss’ Law Flux of through closed surface S = net charge inside V 4 Point Charge Example Apply Gauss’ Law in integral form making use of symmetry to find • Assume that the image charge is uniformly distributed at . Why is this important ? • Symmetry 5 Gauss’ Law Tells Us … … the electric charge can reside only on the surface of the conductor. [If charge was present inside a conductor, we can draw a Gaussian surface around that charge and the electric field in vicinity of that charge would be non-zero ! A non-zero field implies current flow through the conductor, which will transport the charge to the surface.] … there is no charge at all on the inner surface of a hollow conductor. -

Symmetry • the Concept of Flux • Calculating Electric Flux • Gauss's
Topics: • Symmetry • The Concept of Flux • Calculating Electric Flux • Gauss’s Law • Using Gauss’s Law • Conductors in Electrostatic Equilibrium PHYS 1022: Chap. 28, Pg 2 1 New Topic PHYS 1022: Chap. 28, Pg 3 For uniform field, if E and A are perpendicular, define If E and A are NOT perpendicular, define scalar product General (surface integral) Unit of electric flux: N . m2 / C Electric flux is proportional to the number of field lines passing through the area. And to the total change enclosed PHYS 1022: Chap. 28, Pg 4 2 + + PHYS 1022: Chap. 28, Pg 5 + + PHYS 1022: Chap. 28, Pg 6 3 r + ½r + 2r PHYS 1022: Chap. 28, Pg 7 r + ½r + 2r PHYS 1022: Chap. 28, Pg 8 4 A metal block carries a net positive charge and put in an electric field. 1) 0 What is the electric field inside? 2) positive 3) Negative 4) Cannot be determined If there is an electric field inside the conductor, it will move the charges in the conductor to where each charge is in equilibrium. That is, net force = 0 therefore net field = 0! PHYS 1022: Chap. 28, Pg 9 A metal block carries a net charge and 1) All inside the conductor put in an electric field. Where does 2) All on the surface the net charge reside ? 3) Some inside the conductor, some on the surface The net field = 0 inside, and so the net flux through any surface drawn inside the conductor = 0. Therefore the net charge inside = 0! PHYS 1022: Chap. 28, Pg 10 5 PHYS 1022: Chap. -

A Problem-Solving Approach – Chapter 2: the Electric Field
chapter 2 the electric field 50 The Ekelric Field The ancient Greeks observed that when the fossil resin amber was rubbed, small light-weight objects were attracted. Yet, upon contact with the amber, they were then repelled. No further significant advances in the understanding of this mysterious phenomenon were made until the eighteenth century when more quantitative electrification experiments showed that these effects were due to electric charges, the source of all effects we will study in this text. 2·1 ELECTRIC CHARGE 2·1·1 Charginl by Contact We now know that all matter is held together by the aurae· tive force between equal numbers of negatively charged elec· trons and positively charged protons. The early researchers in the 1700s discovered the existence of these two species of charges by performing experiments like those in Figures 2·1 to 2·4. When a glass rod is rubbed by a dry doth, as in Figure 2-1, some of the electrons in the glass are rubbed off onto the doth. The doth then becomes negatively charged because it now has more electrons than protons. The glass rod becomes • • • • • • • • • • • • • • • • • • • • • , • • , ~ ,., ,» Figure 2·1 A glass rod rubbed with a dry doth loses some of iu electrons to the doth. The glau rod then has a net positive charge while the doth has acquired an equal amount of negative charge. The total charge in the system remains zero. £kctric Charge 51 positively charged as it has lost electrons leaving behind a surplus number of protons. If the positively charged glass rod is brought near a metal ball that is free to move as in Figure 2-2a, the electrons in the ball nt~ar the rod are attracted to the surface leaving uncovered positive charge on the other side of the ball. -

21. Maxwell's Equations. Electromagnetic Waves
University of Rhode Island DigitalCommons@URI PHY 204: Elementary Physics II -- Slides PHY 204: Elementary Physics II (2021) 2020 21. Maxwell's equations. Electromagnetic waves Gerhard Müller University of Rhode Island, [email protected] Robert Coyne University of Rhode Island, [email protected] Follow this and additional works at: https://digitalcommons.uri.edu/phy204-slides Recommended Citation Müller, Gerhard and Coyne, Robert, "21. Maxwell's equations. Electromagnetic waves" (2020). PHY 204: Elementary Physics II -- Slides. Paper 46. https://digitalcommons.uri.edu/phy204-slides/46https://digitalcommons.uri.edu/phy204-slides/46 This Course Material is brought to you for free and open access by the PHY 204: Elementary Physics II (2021) at DigitalCommons@URI. It has been accepted for inclusion in PHY 204: Elementary Physics II -- Slides by an authorized administrator of DigitalCommons@URI. For more information, please contact [email protected]. Dynamics of Particles and Fields Dynamics of Charged Particle: • Newton’s equation of motion: ~F = m~a. • Lorentz force: ~F = q(~E +~v ×~B). Dynamics of Electric and Magnetic Fields: I q • Gauss’ law for electric field: ~E · d~A = . e0 I • Gauss’ law for magnetic field: ~B · d~A = 0. I dF Z • Faraday’s law: ~E · d~` = − B , where F = ~B · d~A. dt B I dF Z • Ampere’s` law: ~B · d~` = m I + m e E , where F = ~E · d~A. 0 0 0 dt E Maxwell’s equations: 4 relations between fields (~E,~B) and sources (q, I). tsl314 Gauss’s Law for Electric Field The net electric flux FE through any closed surface is equal to the net charge Qin inside divided by the permittivity constant e0: I ~ ~ Qin Qin −12 2 −1 −2 E · dA = 4pkQin = i.e. -

Maxwell's Equations; Magnetism of Matter
Maxwell’s Equations; Magnetism of Matter 32.1 This chapter will cover ranges from the basic science of electric and magnetic fields to the applied science and engineering of magnetic materials. First, we conclude our basic discussion of electric and magnetic fields, finding that most of the physics principles in the last chapters from 21-31 can be summarized in only four equations, known as Maxwell’s equations. Maxwell's equations describe how electric charges and electric currents create electric and magnetic fields. Further, they describe how an electric field can generate a magnetic field, and vice versa. The first equation allows you to calculate the electric field created by a charge. The second allows you to calculate the magnetic field. The other two describe how fields 'circulate' around their sources. Magnetic fields 'circulate' around electric currents and time varying electric fields, Ampère's law with Maxwell's correction, while electric fields 'circulate' around time varying magnetic fields, Faraday's law. Magnetic materials Second, we examine the science and engineering of magnetic materials. The careers of many scientists and engineers are focused on understanding why some materials are magnetic and others are not and on how existing magnetic materials can be improved. These researchers wonder why Earth has a magnetic field but you do not. They find countless applications for inexpensive magnetic materials in cars, kitchens, offices, and hospitals and magnetic materials often show up in unexpected ways. For example, if you have a tattoo and undergo an MRI (magnetic resonance imaging) scan, the large magnetic field used in the scan may noticeably tug on your tattooed skin because some tattoo inks contain magnetic particles. -
![Arxiv:1208.5988V1 [Math.DG] 29 Aug 2012 flow Before It Becomes Extinct in finite Time](https://docslib.b-cdn.net/cover/1348/arxiv-1208-5988v1-math-dg-29-aug-2012-ow-before-it-becomes-extinct-in-nite-time-601348.webp)
Arxiv:1208.5988V1 [Math.DG] 29 Aug 2012 flow Before It Becomes Extinct in finite Time
MEAN CURVATURE FLOW AS A TOOL TO STUDY TOPOLOGY OF 4-MANIFOLDS TOBIAS HOLCK COLDING, WILLIAM P. MINICOZZI II, AND ERIK KJÆR PEDERSEN Abstract. In this paper we will discuss how one may be able to use mean curvature flow to tackle some of the central problems in topology in 4-dimensions. We will be concerned with smooth closed 4-manifolds that can be smoothly embedded as a hypersurface in R5. We begin with explaining why all closed smooth homotopy spheres can be smoothly embedded. After that we discuss what happens to such a hypersurface under the mean curvature flow. If the hypersurface is in general or generic position before the flow starts, then we explain what singularities can occur under the flow and also why it can be assumed to be in generic position. The mean curvature flow is the negative gradient flow of volume, so any hypersurface flows through hypersurfaces in the direction of steepest descent for volume and eventually becomes extinct in finite time. Before it becomes extinct, topological changes can occur as it goes through singularities. Thus, in some sense, the topology is encoded in the singularities. 0. Introduction The aim of this paper is two-fold. The bulk of it is spend on discussing mean curvature flow of hypersurfaces in Euclidean space and general manifolds and, in particular, surveying a number of very recent results about mean curvature starting at a generic initial hypersurface. The second aim is to explain and discuss possible applications of these results to the topology of four manifolds. In particular, the first few sections are spend to popularize a result, well known to older surgeons. -

Physics 115 Lightning Gauss's Law Electrical Potential Energy Electric
Physics 115 General Physics II Session 18 Lightning Gauss’s Law Electrical potential energy Electric potential V • R. J. Wilkes • Email: [email protected] • Home page: http://courses.washington.edu/phy115a/ 5/1/14 1 Lecture Schedule (up to exam 2) Today 5/1/14 Physics 115 2 Example: Electron Moving in a Perpendicular Electric Field ...similar to prob. 19-101 in textbook 6 • Electron has v0 = 1.00x10 m/s i • Enters uniform electric field E = 2000 N/C (down) (a) Compare the electric and gravitational forces on the electron. (b) By how much is the electron deflected after travelling 1.0 cm in the x direction? y x F eE e = 1 2 Δy = ayt , ay = Fnet / m = (eE ↑+mg ↓) / m ≈ eE / m Fg mg 2 −19 ! $2 (1.60×10 C)(2000 N/C) 1 ! eE $ 2 Δx eE Δx = −31 Δy = # &t , v >> v → t ≈ → Δy = # & (9.11×10 kg)(9.8 N/kg) x y 2" m % vx 2m" vx % 13 = 3.6×10 2 (1.60×10−19 C)(2000 N/C)! (0.01 m) $ = −31 # 6 & (Math typos corrected) 2(9.11×10 kg) "(1.0×10 m/s)% 5/1/14 Physics 115 = 0.018 m =1.8 cm (upward) 3 Big Static Charges: About Lightning • Lightning = huge electric discharge • Clouds get charged through friction – Clouds rub against mountains – Raindrops/ice particles carry charge • Discharge may carry 100,000 amperes – What’s an ampere ? Definition soon… • 1 kilometer long arc means 3 billion volts! – What’s a volt ? Definition soon… – High voltage breaks down air’s resistance – What’s resistance? Definition soon.. -
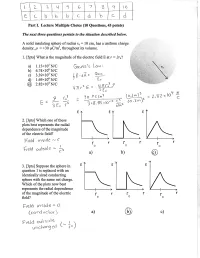
Here Or Line Charge
Name ______________________________________ Student ID _______________ Score________ last first IV. [20 points total] A cube has a charge +Qo spread uniformly throughout its volume. Gaussian A cube-shaped Gaussian surface encloses the cube of charge as shown. The surface centers of the cube of charge and the Gaussian surface are at the same point, and point P is at the center of the right face of the Gaussian surface. A. [6 pts] Is the magnitude of the electric field from the cube constant over any P face of the Gaussian surface? Explain how you can tell. +Qo No, the magnitude of the electric field is not constant over any face. The cube is not a point charge, so we need to break it up into small pieces and take the vector sum of the field from each piece. Different portions of the charged cube are at different distances to each point in a way that’s not symmetric in the same way as a sphere or line charge. For example, point P is the closest point to the center of the cube. A corner of the right face is farther from the center, but might be nearer to the vertex of the cube of charge. There’s no reason to expect the vector sum to have the same magnitude at different points. B. [7 pts] Can this Gaussian surface be used to find the magnitude of the electric field at point P due to the cube of charge? Explain why or why not. No, this surface can’t be used to find EP. -

Notes on Gauss'
2/3/2008 PHYS 2212 Read over Chapter 23 sections 1-9 Examples 1, 2, 3, 6 PHYS 1112 Look over Chapter 16 Section 10 Examples 11, 12, Good Things To Know 1) What a Gaussian surface is. 2) How to calculate the Electric field Flux for an object in an electric field. 3) How to find the electric field for symmetrical objects using Gaussian 1 2/3/2008 Law There is another formulation of Coulomb’s law derived by a German mathematician and physicist Carl Friedrich Gauss. This law called Gauss’ Law, can be used to take advantage of special symmetry situations. Gaussian Surface Central to Gauss’ law is a hypothetical closed surface called a Gaussian Surface. The Gaussian surface must always be a closed surface, so a clear distinction can be made between points that are inside the surface, on the surface, and outside the surface. Gaussian Surface If you have established a Gaussian surface around a distribution of charges then Gauss’ law comes into play. “Gauss” law relates the electric field at points on a (closed) Gaussian surface to the net charge enclosed by that surface” 2 2/3/2008 Flux Suppose you aim an airstream of velocity v at a small square loop of area A If we let Φ represent the Flux or volume flow rate (volume per unit time) at which air flows through the loop. This rate will depend upon 3 things: nThe size of the loop. oThe velocity of the air flow. pThe angle between the air flow velocity and the surface of the loop. -

AP Physics C Curriculum
Randolph Township Schools Randolph High School AP Physics C Curriculum “Nothing happens until something moves.” - Albert Einstein Department of Science, Technology, Engineering, and Math Anthony Emmons, Supervisor Curriculum Committee Alicia Gomez Andrew Palmer Curriculum Developed: July 13, 2020 Date of Board Approval: September 15th, 2020 1 Randolph Township Schools Randolph High School AP Physics C Curriculum Table of Contents Mission Statement ................................................................................................................................................................................................................................ 3 Affirmative Action Statement .............................................................................................................................................................................................................. 3 EDUCATIONAL GOALS ................................................................................................................................................................................................................... 4 Introduction .......................................................................................................................................................................................................................................... 5 Curriculum Pacing Chart ....................................................................................................................................................................................................................