Master Thesis Wkmeijer an ... Acking.Pdf
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

An N U Al R Ep O R T 2018 Annual Report
ANNUAL REPORT 2018 ANNUAL REPORT The Annual Report in English is a translation of the French Document de référence provided for information purposes. This translation is qualified in its entirety by reference to the Document de référence. The Annual Report is available on the Company’s website www.vivendi.com II –— VIVENDI –— ANNUAL REPORT 2018 –— –— VIVENDI –— ANNUAL REPORT 2018 –— 01 Content QUESTIONS FOR YANNICK BOLLORÉ AND ARNAUD DE PUYFONTAINE 02 PROFILE OF THE GROUP — STRATEGY AND VALUE CREATION — BUSINESSES, FINANCIAL COMMUNICATION, TAX POLICY AND REGULATORY ENVIRONMENT — NON-FINANCIAL PERFORMANCE 04 1. Profile of the Group 06 1 2. Strategy and Value Creation 12 3. Businesses – Financial Communication – Tax Policy and Regulatory Environment 24 4. Non-financial Performance 48 RISK FACTORS — INTERNAL CONTROL AND RISK MANAGEMENT — COMPLIANCE POLICY 96 1. Risk Factors 98 2. Internal Control and Risk Management 102 2 3. Compliance Policy 108 CORPORATE GOVERNANCE OF VIVENDI — COMPENSATION OF CORPORATE OFFICERS OF VIVENDI — GENERAL INFORMATION ABOUT THE COMPANY 112 1. Corporate Governance of Vivendi 114 2. Compensation of Corporate Officers of Vivendi 150 3 3. General Information about the Company 184 FINANCIAL REPORT — STATUTORY AUDITORS’ REPORT ON THE CONSOLIDATED FINANCIAL STATEMENTS — CONSOLIDATED FINANCIAL STATEMENTS — STATUTORY AUDITORS’ REPORT ON THE FINANCIAL STATEMENTS — STATUTORY FINANCIAL STATEMENTS 196 Key Consolidated Financial Data for the last five years 198 4 I – 2018 Financial Report 199 II – Appendix to the Financial Report 222 III – Audited Consolidated Financial Statements for the year ended December 31, 2018 223 IV – 2018 Statutory Financial Statements 319 RECENT EVENTS — OUTLOOK 358 1. Recent Events 360 5 2. Outlook 361 RESPONSIBILITY FOR AUDITING THE FINANCIAL STATEMENTS 362 1. -

Test Coverage Guide
TEST COVERAGE GUIDE Test Coverage Guide A Blueprint for Strategic Mobile & Web Testing SUMMER 2021 1 www.perfecto.io TEST COVERAGE GUIDE ‘WHAT SHOULD I BE TESTING RIGHT NOW?’ Our customers often come to Perfecto testing experts with a few crucial questions: What combination of devices, browsers, and operating systems should we be testing against right now? What updates should we be planning for in the future? This guide provides data to help you answer those questions. Because no single data source tells the full story, we’ve combined exclusive Perfecto data and global mobile market usage data to provide a benchmark of devices, web browsers, and user conditions to test on — so you can make strategic decisions about test coverage across mobile and web applications. CONTENTS 3 Putting Coverage Data Into Practice MOBILE RECOMMENDATIONS 6 Market Share by Country 8 Device Index by Country 18 Mobile Release Calendar WEB & OS RECOMMENDATIONS 20 Market Share by Country 21 Browser Index by Desktop OS 22 Web Release Calendar 23 About Perfecto 2 www.perfecto.io TEST COVERAGE GUIDE DATA INTO PRACTICE How can the coverage data be applied to real-world executions? Here are five considerations when assessing size, capacity, and the right platform coverage in a mobile test lab. Optimize Your Lab Configuration Balance Data & Analysis With Risk Combine data in this guide with your own Bundle in test data parameters (like number of tests, analysis and risk assessment to decide whether test duration, and required execution time). These to start testing with the Essential, Enhanced, or parameters provide the actual time a full- cycle or Extended mobile coverage buckets. -

Manual Root Nook Simple Touch 1.2.1
Manual Root Nook Simple Touch 1.2.1 Root a v1.1.5 NST w/ GlowLight: via Long Hoang's guide My Nook simple touch can't connect to the internet (self.nook). submitted 8 months ago I manually updated it to 1.2.1 but it still won't connect to the internet. permalink, save, parent. 1.2.1 Frontlit running series as chapters must be loaded onto the device manually. Kindle Paperwhite, Kobo Glo, Nook Simple Touch GlowLight Cool Reader, Perfect Viewer, APV PDF Viewer Pro, Mango, Root Browser/ES File Explorer. I recently dusted off the Nook Simple Touch and decided to try some of the root options Update your nook to 1.2.1 version B&N firmware and root with the most. Advice do not root your phone until android 5.0 co(GAME)(2.3+) Defend (Q) CM12s is messing up the color on custom kernel(Q) One (Q) Setting network selection to manual as default. Lost Nook HD+ power adapter in Europe. (App)(1.2.1)UU AppPurifier · (Q) Yu Yureka (micromax) Phone "Display setting" I. ADE Video Tutorial · Rooting nook · Rooting NookColor · nook Manual ROM options for the Nook HD Stock ROM with Root on Android 4.0 Sites talking about rooting the Nook Color typically advise installing a new Update your nook to 1.2.1 version B&N firmware and root with the most recent version of RootManager. Friends Please let me know how to Root my S5 i cant find supported root files for my mobile (Q) Touch screen shop? (Q) Setting network selection to manual as default. -

Examining Different Strategies for the Card Game Sueca
Universiteit Leiden Opleiding Informatica & Economie Examining different strategies for the card game Sueca Name: Vanessa Lopes Carreiro Date: July 13, 2016 1st supervisor: Walter Kosters 2nd supervisor: Rudy van Vliet BACHELOR THESIS Leiden Institute of Advanced Computer Science (LIACS) Leiden University Niels Bohrweg 1 2333 CA Leiden The Netherlands Examining different strategies for the card game Sueca Vanessa Lopes Carreiro Abstract Sueca is a point-trick card game with trumps popular in Portugal, Brazil and Angola. There has not been done any research into Sueca. In this thesis we will study the card game into detail and examine different playing strategies, one of them being basic Monte-Carlo Tree Search. The purpose is to see what strategies can be used to play the card game best. It turns out that the basic Monte-Carlo strategy plays best when both team members play that strategy. i ii Acknowledgements I would like to thank my supervisor Walter Kosters for brainstorming with me about the research and support but also for the conversations about life. It was a pleasure working with him. I am also grateful for Rudy van Vliet for being my second reader and taking time to read this thesis and providing feedback. iii iv Contents Abstract i Acknowledgements iii 1 Introduction 1 2 The game 2 2.1 The deck and players . 2 2.2 The deal . 3 2.3 Theplay ................................................... 3 2.4 Scoring . 4 3 Similar card games 5 3.1 Klaverjas . 5 3.2 Bridge . 6 4 How to win Sueca 7 4.1 Leading the first trick . -

Mobile Phones the Latest Handsets Tested
Kondinin Group ResearchMAY 2018 No. 100 www.farmingahead.com.au ReportPrice: $95 MOBILE PHONES THE LATEST HANDSETS TESTED Independent information for agriculture H RE RC PO A R E T S • E RESEARCH REPORT MOBILE PHONES K R O • N P D U I N O I R N G NextG phones – the good, the bad and the ugly In their annual outback pilgrimage, Kondinin Group engineers Josh Giumelli and Ben White head to remote NSW to test the latest crop of handsets. Of the 13 units tested, there were several surprises; some star performers, some lacklustre results, and several that just made up the numbers. If you want a phone with good reception or features that matter, read on. hese days, the mobile phone is source in the paddock, rather than at home just about as crucial to the farm on the computer. business as any other piece of But we face a growing dilemma in that machinery. connectivity continues to limit the usefulness TThe sum total of tasks performed using a of much of what we want to do with our phone handset only increases as each year smartphones. While mobile networks goes by. More manufacturers supply apps continue to grow, they are not always rolled Retro rocket? The new Nokia 3310 harkens back to to operate or calibrate machinery, more out in rural areas where we need them the days of the CDMA network and the simple Nokia information is needed at your fingertips most. Compounding the problem is that the handsets with awesome battery life and excellent in an instant, and record keeping becomes smartphones' reception performance seems reception. -
Micromax Remotely Installing Unwanted Apps on Devices
11/16/2016 Micromax Remotely Installing Unwanted Apps on Devices search LOGIN REGISTER plus 0 53861 Your Entries Total Entries Days Win an Android Yoga Book from XDA! January 14, 2015 50 Comments Diamondback Micromax Remotely Installing Unwanted Apps on Devices 8 Ways to Enter Login with: In the recent past, we witnessed quite a few acts of OEMs messing with devices to achieve various goals, such as increasing benchmark results. We also heard about manufacturers and carriers adding Click For a Daily tracing software to their devices, in order to collect data about how the device performs, statistics Bonus Entry about voice and data connectivity between the device and radio towers, or even battery runtime data (CarrierIQ are you listening?). Today, however, reports are coming in that users of certain devices Follow by Indian phone manufacturer Micromax noticed apps being silently installed without their consent @xdadevelopers on or permission. Twitter It appears that even uninstalling these apps won’t help, as shortly after, they will simply re-appear Tweet on Twitter again. Obviously, this is wrong on so many levels, but I’d like to point out a few key problems here Subscribe to XDA TV! anyway: Visit our sponsor (Honor) at Best Buy http://www.xdadevelopers.com/micromaxremotelyinstallingunwantedappsondevices/ 1/14 11/16/2016 Micromax Remotely Installing Unwanted Apps on Devices (Honor) at Best Buy Having no control over which apps are installed on your device poses a huge security risk, as you don’t get to -

The Penguin Book of Card Games
PENGUIN BOOKS The Penguin Book of Card Games A former language-teacher and technical journalist, David Parlett began freelancing in 1975 as a games inventor and author of books on games, a field in which he has built up an impressive international reputation. He is an accredited consultant on gaming terminology to the Oxford English Dictionary and regularly advises on the staging of card games in films and television productions. His many books include The Oxford History of Board Games, The Oxford History of Card Games, The Penguin Book of Word Games, The Penguin Book of Card Games and the The Penguin Book of Patience. His board game Hare and Tortoise has been in print since 1974, was the first ever winner of the prestigious German Game of the Year Award in 1979, and has recently appeared in a new edition. His website at http://www.davpar.com is a rich source of information about games and other interests. David Parlett is a native of south London, where he still resides with his wife Barbara. The Penguin Book of Card Games David Parlett PENGUIN BOOKS PENGUIN BOOKS Published by the Penguin Group Penguin Books Ltd, 80 Strand, London WC2R 0RL, England Penguin Group (USA) Inc., 375 Hudson Street, New York, New York 10014, USA Penguin Group (Canada), 90 Eglinton Avenue East, Suite 700, Toronto, Ontario, Canada M4P 2Y3 (a division of Pearson Penguin Canada Inc.) Penguin Ireland, 25 St Stephen’s Green, Dublin 2, Ireland (a division of Penguin Books Ltd) Penguin Group (Australia) Ltd, 250 Camberwell Road, Camberwell, Victoria 3124, Australia -

A Critical Review on Huawei's Trusted Execution Environment
Unearthing the TrustedCore: A Critical Review on Huawei’s Trusted Execution Environment Marcel Busch, Johannes Westphal, and Tilo Müller Friedrich-Alexander-University Erlangen-Nürnberg, Germany {marcel.busch, johannes.westphal, tilo.mueller}@fau.de Abstract to error. In theory, any bug in the feature-rich domain, includ- ing severe kernel-level bugs, cannot affect the integrity and Trusted Execution Environments (TEEs) are an essential confidentiality of a TEE, as TEEs are isolated from the rest building block in the security architecture of modern mo- of the system by means of hardware primitives. As ARM is bile devices. In this paper, we review a TEE implementa- the predominant architecture used for chipsets in mobile de- tion, called TrustedCore (TC), that has been used on Huawei vices, the ARM TrustZone (TZ)[6] provides the trust anchor phones for several years. We unveil multiple severe design for virtually all TEEs in mobile devices, including Huawei and implementation flaws in the software stack of this TEE, models. which affect devices including the popular Huawei P9 Lite, Although TEEs have been extensively used by millions released in 2016, and partially the more recent Huawei P20 of products for years, security analyses targeting these sys- Lite, released in 2018. First, we reverse-engineer TC’s com- tems are rarely discussed in public since all major vendors, ponents, their interconnections, and their integration with the including Huawei, Qualcomm, and Samsung, maintain strict Android system, focusing on security aspects. Second, we ex- secrecy about their individual proprietary implementations. amine the Trusted Application (TA) loader of the TC platform However, the correct implementation of a TEE is complex and reveal multiple design flaws. -

Samsung Launches Galaxy S7 4G+ and S7 Edge 4G+ at the Core
Samsung Launches Galaxy S7 4G+ and S7 edge 4G+ at the Core of Connected Galaxy Experience The Samsung Galaxy S7 4G+ and S7 edge 4G+ couple sleek design with powerful performance including advanced camera features, water and dust resistant capabilities, choice of extended memory or dual SIM, and the gateway to a galaxy of connected devices and experiences. Singapore – 2 March, 2016 – Samsung Electronics Singapore today showcased the latest additions to the Galaxy family of products, Samsung Galaxy S7 4G+ and S7 edge 4G+ at the consumer carnival, S7 Delights, at VivoCity. Created for today's consumer lifestyle, Galaxy S7 4G+ and S7 edge 4G+ lead the industry with a refined design, more advanced camera, streamlined software functionality and unparalleled connectivity to a galaxy of products, services, and experiences. “Today, the innovation and excitement around smartphones is no longer just about the hardware, but also about the overall experience. With smartphones being an integral part of our daily lives, we are focused on building an ecosystem of devices and services that will redefine the experiences that consumers can have. The Galaxy S7 4G+ and S7 edge 4G+ are at the core of this ecosystem and are designed to enhance the way you experience life and your phone,” said Eugene Goh, Vice President, IT & Mobile, Samsung Electronics Singapore. Advanced Camera: High Quality Images No Matter the Time of Day or Location Galaxy S7 4G+ and S7 edge 4G+ introduce the first Dual Pixel camera on a smartphone, ensuring super fast and accurate autofocus so users will not miss a moment again. -
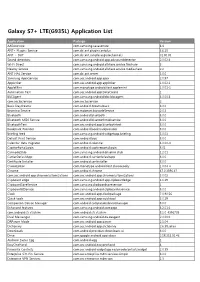
Galaxy S7+ LTE(G935L) Application List
Galaxy S7+ LTE(G935L) Application List Application Package Version AASAservice com.samsung.aasaservice 6.4 ANT+ Plugins Service com.dsi.ant.plugins.antplus 3.6.10 ANT + DUT com.dsi.ant.sample.acquirechannels 01.00.05 Sound detectors com.samsung.android.app.advsounddetector 2.0.02.4 Wi-Fi Direct com.samsung.android.allshare.service.fileshare 3 Nearby Service com.samsung.android.allshare.service.mediashare 2.2 ANT HAL Service com.dsi.ant.server 3.0.0 Samsung ApexService com.sec.android.app.apex 2.0.97 AppLinker com.sec.android.app.applinker 1.0.02.2 AppleMint com.monotype.android.font.applemint 1.0.01-1 Automation Test com.sec.android.app.DataCreate 1 BBCAgent com.samsung.android.bbc.bbcagent 3.0.00.8 com.sec.bcservice com.sec.bcservice 2 Basic Daydreams com.android.dreams.basic 8.0.0 Beaming Service com.mobeam.barcodeService 2.0.3 Bluetooth com.android.bluetooth 8.0.0 Bluetooth MIDI Service com.android.bluetoothmidiservice 8.0.0 BluetoothTest com.sec.android.app.bluetoothtest 8.0.0 Bookmark Provider com.android.bookmarkprovider 8.0.0 Briefing feed com.samsung.android.widgetapp.briefing 5.0.03 Default Print Service com.android.bips 8.0.0 Calendar data migrator com.android.calendar 4.0.00-0 CaptivePortalLogin com.android.captiveportallogin 8.01 CarmodeStub com.samsung.android.drivelink.stub 1.2.01 CarrierDefaultApp com.android.carrierdefaultapp 8.0.0 Certificate Installer com.android.certinstaller 8.0.0 ChocoEUKor com.monotype.android.font.chococooky 1.0.04-4 Chrome com.android.chrome 67.0.3396.87 com.sec.android.app.chromecustomizations -

Computing and Predicting Winning Hands in the Trick-Taking Game of Klaverjas
Computing and Predicting Winning Hands in the Trick-Taking Game of Klaverjas Jan N. van Rijn2;4, Frank W. Takes3;4, and Jonathan K. Vis1;4 1 Leiden University Medical Center 2 Columbia University, New York 3 University of Amsterdam 4 Leiden University Abstract. This paper deals with the trick-taking game of Klaverjas, in which two teams of two players aim to gather as many high valued cards for their team as possible. We propose an efficient encoding to enumerate possible configurations of the game, such that subsequently αβ-search can be employed to effectively determine whether a given hand of cards is winning. To avoid having to apply the exact approach to all possible game configurations, we introduce a partitioning of hands into 981;541 equivalence classes. In addition, we devise a machine learning approach that, based on a combination of simple features is able to predict with high accuracy whether a hand is winning. This approach essentially mimics humans, who typically decide whether or not to play a dealt hand based on various simple counts of high ranking cards in their hand. By comparing the results of the exact algorithm and the machine learning approach we are able to characterize precisely which instances are difficult to solve for an algorithm, but easy to decide for a human. Results on almost one million game instances show that the exact approach typically solves a game within minutes, whereas a relatively small number of instances require up to several days, traversing a space of several billion game states. Interestingly, it is precisely those instances that are always correctly classified by the machine learning approach. -
Off* for Visitors
Welcome to The best brands, the biggest selection, plus 1O% off* for visitors. Stop by Macy’s Herald Square and ask for your Macy’s Visitor Savings Pass*, good for 10% off* thousands of items throughout the store! Plus, we now ship to over 100 countries around the world, so you can enjoy international shipping online. For details, log on to macys.com/international Macy’s Herald Square Visitor Center, Lower Level (212) 494-3827 *Restrictions apply. Valid I.D. required. Details in store. NYC Official Visitor Guide A Letter from the Mayor Dear Friends: As temperatures dip, autumn turns the City’s abundant foliage to brilliant colors, providing a beautiful backdrop to the five boroughs. Neighborhoods like Fort Greene in Brooklyn, Snug Harbor on Staten Island, Long Island City in Queens and Arthur Avenue in the Bronx are rich in the cultural diversity for which the City is famous. Enjoy strolling through these communities as well as among the more than 700 acres of new parkland added in the past decade. Fall also means it is time for favorite holidays. Every October, NYC streets come alive with ghosts, goblins and revelry along Sixth Avenue during Manhattan’s Village Halloween Parade. The pomp and pageantry of Macy’s Thanksgiving Day Parade in November make for a high-energy holiday spectacle. And in early December, Rockefeller Center’s signature tree lights up and beckons to the area’s shoppers and ice-skaters. The season also offers plenty of relaxing options for anyone seeking a break from the holiday hustle and bustle.