Divergence Measures and Message Passing
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Curl, Divergence and Laplacian
Curl, Divergence and Laplacian What to know: 1. The definition of curl and it two properties, that is, theorem 1, and be able to predict qualitatively how the curl of a vector field behaves from a picture. 2. The definition of divergence and it two properties, that is, if div F~ 6= 0 then F~ can't be written as the curl of another field, and be able to tell a vector field of clearly nonzero,positive or negative divergence from the picture. 3. Know the definition of the Laplace operator 4. Know what kind of objects those operator take as input and what they give as output. The curl operator Let's look at two plots of vector fields: Figure 1: The vector field Figure 2: The vector field h−y; x; 0i: h1; 1; 0i We can observe that the second one looks like it is rotating around the z axis. We'd like to be able to predict this kind of behavior without having to look at a picture. We also promised to find a criterion that checks whether a vector field is conservative in R3. Both of those goals are accomplished using a tool called the curl operator, even though neither of those two properties is exactly obvious from the definition we'll give. Definition 1. Let F~ = hP; Q; Ri be a vector field in R3, where P , Q and R are continuously differentiable. We define the curl operator: @R @Q @P @R @Q @P curl F~ = − ~i + − ~j + − ~k: (1) @y @z @z @x @x @y Remarks: 1. -

Calculus Terminology
AP Calculus BC Calculus Terminology Absolute Convergence Asymptote Continued Sum Absolute Maximum Average Rate of Change Continuous Function Absolute Minimum Average Value of a Function Continuously Differentiable Function Absolutely Convergent Axis of Rotation Converge Acceleration Boundary Value Problem Converge Absolutely Alternating Series Bounded Function Converge Conditionally Alternating Series Remainder Bounded Sequence Convergence Tests Alternating Series Test Bounds of Integration Convergent Sequence Analytic Methods Calculus Convergent Series Annulus Cartesian Form Critical Number Antiderivative of a Function Cavalieri’s Principle Critical Point Approximation by Differentials Center of Mass Formula Critical Value Arc Length of a Curve Centroid Curly d Area below a Curve Chain Rule Curve Area between Curves Comparison Test Curve Sketching Area of an Ellipse Concave Cusp Area of a Parabolic Segment Concave Down Cylindrical Shell Method Area under a Curve Concave Up Decreasing Function Area Using Parametric Equations Conditional Convergence Definite Integral Area Using Polar Coordinates Constant Term Definite Integral Rules Degenerate Divergent Series Function Operations Del Operator e Fundamental Theorem of Calculus Deleted Neighborhood Ellipsoid GLB Derivative End Behavior Global Maximum Derivative of a Power Series Essential Discontinuity Global Minimum Derivative Rules Explicit Differentiation Golden Spiral Difference Quotient Explicit Function Graphic Methods Differentiable Exponential Decay Greatest Lower Bound Differential -

The Divergence of a Vector Field.Doc 1/8
9/16/2005 The Divergence of a Vector Field.doc 1/8 The Divergence of a Vector Field The mathematical definition of divergence is: w∫∫ A(r )⋅ds ∇⋅A()rlim = S ∆→v 0 ∆v where the surface S is a closed surface that completely surrounds a very small volume ∆v at point r , and where ds points outward from the closed surface. From the definition of surface integral, we see that divergence basically indicates the amount of vector field A ()r that is converging to, or diverging from, a given point. For example, consider these vector fields in the region of a specific point: ∆ v ∆v ∇⋅A ()r0 < ∇ ⋅>A (r0) Jim Stiles The Univ. of Kansas Dept. of EECS 9/16/2005 The Divergence of a Vector Field.doc 2/8 The field on the left is converging to a point, and therefore the divergence of the vector field at that point is negative. Conversely, the vector field on the right is diverging from a point. As a result, the divergence of the vector field at that point is greater than zero. Consider some other vector fields in the region of a specific point: ∇⋅A ()r0 = ∇ ⋅=A (r0) For each of these vector fields, the surface integral is zero. Over some portions of the surface, the normal component is positive, whereas on other portions, the normal component is negative. However, integration over the entire surface is equal to zero—the divergence of the vector field at this point is zero. * Generally, the divergence of a vector field results in a scalar field (divergence) that is positive in some regions in space, negative other regions, and zero elsewhere. -

Generalized Stokes' Theorem
Chapter 4 Generalized Stokes’ Theorem “It is very difficult for us, placed as we have been from earliest childhood in a condition of training, to say what would have been our feelings had such training never taken place.” Sir George Stokes, 1st Baronet 4.1. Manifolds with Boundary We have seen in the Chapter 3 that Green’s, Stokes’ and Divergence Theorem in Multivariable Calculus can be unified together using the language of differential forms. In this chapter, we will generalize Stokes’ Theorem to higher dimensional and abstract manifolds. These classic theorems and their generalizations concern about an integral over a manifold with an integral over its boundary. In this section, we will first rigorously define the notion of a boundary for abstract manifolds. Heuristically, an interior point of a manifold locally looks like a ball in Euclidean space, whereas a boundary point locally looks like an upper-half space. n 4.1.1. Smooth Functions on Upper-Half Spaces. From now on, we denote R+ := n n f(u1, ... , un) 2 R : un ≥ 0g which is the upper-half space of R . Under the subspace n n n topology, we say a subset V ⊂ R+ is open in R+ if there exists a set Ve ⊂ R open in n n n R such that V = Ve \ R+. It is intuitively clear that if V ⊂ R+ is disjoint from the n n n subspace fun = 0g of R , then V is open in R+ if and only if V is open in R . n n Now consider a set V ⊂ R+ which is open in R+ and that V \ fun = 0g 6= Æ. -

Metrics Defined by Bregman Divergences †
1 METRICS DEFINED BY BREGMAN DIVERGENCES y PENGWEN CHEN z AND YUNMEI CHEN, MURALI RAOx Abstract. Bregman divergences are generalizations of the well known Kullback Leibler diver- gence. They are based on convex functions and have recently received great attention. We present a class of \squared root metrics" based on Bregman divergences. They can be regarded as natural generalization of Euclidean distance. We provide necessary and sufficient conditions for a convex function so that the square root of its associated average Bregman divergence is a metric. Key words. Metrics, Bregman divergence, Convexity subject classifications. Analysis of noise-corrupted data, is difficult without interpreting the data to have been randomly drawn from some unknown distribution with unknown parameters. The most common assumption on noise is Gaussian distribution. However, it may be inappropriate if data is binary-valued or integer-valued or nonnegative. Gaussian is a member of the exponential family. Other members of this family for example the Poisson and the Bernoulli are better suited for integer and binary data. Exponential families and Bregman divergences ( Definition 1.1 ) have a very intimate relationship. There exists a unique Bregman divergence corresponding to every regular exponential family [13][3]. More precisely, the log-likelihood of an exponential family distribution can be represented by a sum of a Bregman divergence and a parameter unrelated term. Hence, Bregman divergence provides a likelihood distance for exponential family in some sense. This property has been used in generalizing principal component analysis to the Exponential family [7]. The Bregman divergence however is not a metric, because it is not symmetric, and does not satisfy the triangle inequality. -
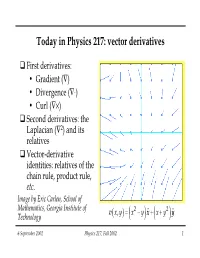
Today in Physics 217: Vector Derivatives
Today in Physics 217: vector derivatives First derivatives: • Gradient (—) • Divergence (—◊) •Curl (—¥) Second derivatives: the Laplacian (—2) and its relatives Vector-derivative identities: relatives of the chain rule, product rule, etc. Image by Eric Carlen, School of Mathematics, Georgia Institute of 22 vxyxy, =−++ x yˆˆ x y Technology ()()() 6 September 2002 Physics 217, Fall 2002 1 Differential vector calculus df/dx provides us with information on how quickly a function of one variable, f(x), changes. For instance, when the argument changes by an infinitesimal amount, from x to x+dx, f changes by df, given by df df= dx dx In three dimensions, the function f will in general be a function of x, y, and z: f(x, y, z). The change in f is equal to ∂∂∂fff df=++ dx dy dz ∂∂∂xyz ∂∂∂fff =++⋅++ˆˆˆˆˆˆ xyzxyz ()()dx() dy() dz ∂∂∂xyz ≡⋅∇fdl 6 September 2002 Physics 217, Fall 2002 2 Differential vector calculus (continued) The vector derivative operator — (“del”) ∂∂∂ ∇ =++xyzˆˆˆ ∂∂∂xyz produces a vector when it operates on scalar function f(x,y,z). — is a vector, as we can see from its behavior under coordinate rotations: I ′ ()∇∇ff=⋅R but its magnitude is not a number: it is an operator. 6 September 2002 Physics 217, Fall 2002 3 Differential vector calculus (continued) There are three kinds of vector derivatives, corresponding to the three kinds of multiplication possible with vectors: Gradient, the analogue of multiplication by a scalar. ∇f Divergence, like the scalar (dot) product. ∇⋅v Curl, which corresponds to the vector (cross) product. ∇×v 6 September 2002 Physics 217, Fall 2002 4 Gradient The result of applying the vector derivative operator on a scalar function f is called the gradient of f: ∂∂∂fff ∇f =++xyzˆˆˆ ∂∂∂xyz The direction of the gradient points in the direction of maximum increase of f (i.e. -

Divergence and Integral Tests Handout Reference: Brigg’S “Calculus: Early Transcendentals, Second Edition” Topics: Section 8.4: the Divergence and Integral Tests, P
Lesson 17: Divergence and Integral Tests Handout Reference: Brigg's \Calculus: Early Transcendentals, Second Edition" Topics: Section 8.4: The Divergence and Integral Tests, p. 627 - 640 Theorem 8.8. p. 627 Divergence Test P If the infinite series ak converges, then lim ak = 0. k!1 P Equivalently, if lim ak 6= 0, then the infinite series ak diverges. k!1 Note: The divergence test cannot be used to conclude that a series converges. This test ONLY provides a quick mechanism to check for divergence. Definition. p. 628 Harmonic Series 1 1 1 1 1 1 The famous harmonic series is given by P = 1 + + + + + ··· k=1 k 2 3 4 5 Theorem 8.9. p. 630 Harmonic Series 1 1 The harmonic series P diverges, even though the terms of the series approach zero. k=1 k Theorem 8.10. p. 630 Integral Test Suppose the function f(x) satisfies the following three conditions for x ≥ 1: i. f(x) is continuous ii. f(x) is positive iii. f(x) is decreasing Suppose also that ak = f(k) for all k 2 N. Then 1 1 X Z ak and f(x)dx k=1 1 either both converge or both diverge. In the case of convergence, the value of the integral is NOT equal to the value of the series. Note: The Integral Test is used to determine whether a series converges or diverges. For this reason, adding or subtracting a finite number of terms in the series or changing the lower limit of the integration to another finite point does not change the outcome of the test. -

Divergence, Gradient and Curl Based on Lecture Notes by James
Divergence, gradient and curl Based on lecture notes by James McKernan One can formally define the gradient of a function 3 rf : R −! R; by the formal rule @f @f @f grad f = rf = ^{ +| ^ + k^ @x @y @z d Just like dx is an operator that can be applied to a function, the del operator is a vector operator given by @ @ @ @ @ @ r = ^{ +| ^ + k^ = ; ; @x @y @z @x @y @z Using the operator del we can define two other operations, this time on vector fields: Blackboard 1. Let A ⊂ R3 be an open subset and let F~ : A −! R3 be a vector field. The divergence of F~ is the scalar function, div F~ : A −! R; which is defined by the rule div F~ (x; y; z) = r · F~ (x; y; z) @f @f @f = ^{ +| ^ + k^ · (F (x; y; z);F (x; y; z);F (x; y; z)) @x @y @z 1 2 3 @F @F @F = 1 + 2 + 3 : @x @y @z The curl of F~ is the vector field 3 curl F~ : A −! R ; which is defined by the rule curl F~ (x; x; z) = r × F~ (x; y; z) ^{ |^ k^ = @ @ @ @x @y @z F1 F2 F3 @F @F @F @F @F @F = 3 − 2 ^{ − 3 − 1 |^+ 2 − 1 k:^ @y @z @x @z @x @y Note that the del operator makes sense for any n, not just n = 3. So we can define the gradient and the divergence in all dimensions. However curl only makes sense when n = 3. Blackboard 2. The vector field F~ : A −! R3 is called rotation free if the curl is zero, curl F~ = ~0, and it is called incompressible if the divergence is zero, div F~ = 0. -

6 Integration on Manifolds, Lecture 6
6 Integration on manifolds, Lecture 6 To formulate the divergence theorem we need one final ingredient: Let D be an open subset of X and D¯ its closure. Definition 1. D is a smooth domain if (a) its boundary is an (n − 1)-dimensional submanifold of X and (b) the boundary of D coincides with the boundary of D¯. Examples. 2 2 2 2 1. The n-ball, x1 + · · · + xn < 1, whose boundary is the sphere, x1 + · · · + xn = 1. 2. The n-dimensional annulus, 2 2 1 < x1 + · · · + xn < 2 whose boundary consists of the spheres, 2 2 2 2 x1 + · · · + xn = 1 and x1 + · · · + xn = 2 : n−1 2 2 n n−1 3. Let S be the unit sphere, x1 + · · · + x2 = 1 and let D = R − S . Then the boundary of D is Sn−1 but D is not a smooth domain since the boundary of D¯ is empty. The simplest example of a smooth domain is the half-space (5.15). We will show that every bounded domain looks locally like this example. Theorem 1. Let D be a smooth domain and p a boundary point of D. Then there n exists a neighborhood, U, of p in X, an open set, U0, in R and a diffeomorphism, n '0 : U0 ! U such that '0 maps U0 \ H onto U \ D. Proof. Let Z be the boundary of D. Then by Theorem 5.5 there exists a neigh- n n borhood, U of p in X, an open ball, U0 in R , with center at q 2 BdH , and a diffeomorphism, ' : (U0; q) ! (U; p) n −1 mapping U0 \ BdH onto U \ Z. -

VISUALIZING EXTERIOR CALCULUS Contents Introduction 1 1. Exterior
VISUALIZING EXTERIOR CALCULUS GREGORY BIXLER Abstract. Exterior calculus, broadly, is the structure of differential forms. These are usually presented algebraically, or as computational tools to simplify Stokes' Theorem. But geometric objects like forms should be visualized! Here, I present visualizations of forms that attempt to capture their geometry. Contents Introduction 1 1. Exterior algebra 2 1.1. Vectors and dual vectors 2 1.2. The wedge of two vectors 3 1.3. Defining the exterior algebra 4 1.4. The wedge of two dual vectors 5 1.5. R3 has no mixed wedges 6 1.6. Interior multiplication 7 2. Integration 8 2.1. Differential forms 9 2.2. Visualizing differential forms 9 2.3. Integrating differential forms over manifolds 9 3. Differentiation 11 3.1. Exterior Derivative 11 3.2. Visualizing the exterior derivative 13 3.3. Closed and exact forms 14 3.4. Future work: Lie derivative 15 Acknowledgments 16 References 16 Introduction What's the natural way to integrate over a smooth manifold? Well, a k-dimensional manifold is (locally) parametrized by k coordinate functions. At each point we get k tangent vectors, which together form an infinitesimal k-dimensional volume ele- ment. And how should we measure this element? It seems reasonable to ask for a function f taking k vectors, so that • f is linear in each vector • f is zero for degenerate elements (i.e. when vectors are linearly dependent) • f is smooth These are the properties of a differential form. 1 2 GREGORY BIXLER Introducing structure to a manifold usually follows a certain pattern: • Create it in Rn. -

3.2. Differential Forms. the Line Integral of a 1-Form Over a Curve Is a Very Nice Kind of Integral in Several Respects
11 3.2. Differential forms. The line integral of a 1-form over a curve is a very nice kind of integral in several respects. In the spirit of differential geometry, it does not require any additional structure, such as a metric. In practice, it is relatively simple to compute. If two curves c and c! are very close together, then α α. c c! The line integral appears in a nice integral theorem. ≈ ! ! This contrasts with the integral c f ds of a function with respect to length. That is defined with a metric. The explicit formula involves a square root, which often leads to difficult integrals. Even! if two curves are extremely close together, the integrals can differ drastically. We are interested in other nice integrals and other integral theorems. The gener- alization of a smooth curve is a submanifold. A p-dimensional submanifold Σ M ⊆ is a subset which looks locally like Rp Rn. We would like to make sense of an expression⊆ like ω. "Σ What should ω be? It cannot be a scalar function. If we could integrate functions, then we could compute volumes, but without some additional structure, the con- cept of “the volume of Σ” is meaningless. In order to compute an integral like this, we should first use a coordinate system to chop Σ up into many tiny p-dimensional parallelepipeds (think cubes). Each of these is described by p vectors which give the edges touching one corner. So, from p vectors v1, . , vp at a point, ω should give a number ω(v1, . -

Differential Forms: Unifying the Theorems of Vector Calculus
Differential Forms: Unifying the Theorems of Vector Calculus In class we have discussed the important vector calculus theorems known as Green's Theorem, Divergence Theorem, and Stokes's Theorem. Interestingly enough, all of these results, as well as the fundamental theorem for line integrals (so in particular the fundamental theorem of calculus), are merely special cases of one and the same theorem named after George Gabriel Stokes (1819-1903). This all-including theorem is stated in terms of differential forms. Without giving exact definitions, let us use the language of differential forms to unify the theorems we have learned. A striking pattern will emerge. 0-forms. A scalar field (i.e. a real-valued function) is also called a 0-form. 1-forms. Recall the following notation for line integrals (in 3-space, say): Z Z b Z F(r) · dr = P x0(t)dt +Q y0(t)dt +R z0(t)dt = P dx + Qdy + Rdz; C a | {z } | {z } | {z } C dx dy dz where F = P i + Qj + Rk. The expression P (x; y; z)dx + Q(x; y; z)dy + R(x; y; z)dz is called a 1-form. 2-forms. In evaluating surface integrals we can introduce similar notation: ZZ F · n dS S ZZ @r × @r @r @r @u @v = F · × dudv Γ @r @r @u @v @u × @v ZZ @y @y ZZ @x @x ZZ @x @x @u @v @u @v @u @v = P @z @z dudv − Q @z @z dudv + R @y @y dudv Γ @u @v Γ @u @v Γ @u @v | {z } | {z } | {z } dy^dz dx^dz dx^dy ZZ = P dy ^ dz − Qdx ^ dz + Rdx ^ dy: S We call P (x; y; z)dy ^ dz − Q(x; y; z)dx ^ dz + R(x; y; z)dx ^ dy a 2-form.