Privacy and Cooperation in Peer-To-Peer Systems
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Uila Supported Apps
Uila Supported Applications and Protocols updated Oct 2020 Application/Protocol Name Full Description 01net.com 01net website, a French high-tech news site. 050 plus is a Japanese embedded smartphone application dedicated to 050 plus audio-conferencing. 0zz0.com 0zz0 is an online solution to store, send and share files 10050.net China Railcom group web portal. This protocol plug-in classifies the http traffic to the host 10086.cn. It also 10086.cn classifies the ssl traffic to the Common Name 10086.cn. 104.com Web site dedicated to job research. 1111.com.tw Website dedicated to job research in Taiwan. 114la.com Chinese web portal operated by YLMF Computer Technology Co. Chinese cloud storing system of the 115 website. It is operated by YLMF 115.com Computer Technology Co. 118114.cn Chinese booking and reservation portal. 11st.co.kr Korean shopping website 11st. It is operated by SK Planet Co. 1337x.org Bittorrent tracker search engine 139mail 139mail is a chinese webmail powered by China Mobile. 15min.lt Lithuanian news portal Chinese web portal 163. It is operated by NetEase, a company which 163.com pioneered the development of Internet in China. 17173.com Website distributing Chinese games. 17u.com Chinese online travel booking website. 20 minutes is a free, daily newspaper available in France, Spain and 20minutes Switzerland. This plugin classifies websites. 24h.com.vn Vietnamese news portal 24ora.com Aruban news portal 24sata.hr Croatian news portal 24SevenOffice 24SevenOffice is a web-based Enterprise resource planning (ERP) systems. 24ur.com Slovenian news portal 2ch.net Japanese adult videos web site 2Shared 2shared is an online space for sharing and storage. -

The Wealth of Networks How Social Production Transforms Markets and Freedom
Name /yal05/27282_u00 01/27/06 10:25AM Plate # 0-Composite pg 3 # 3 The Wealth of Networks How Social Production Transforms Markets and Freedom Yochai Benkler Yale University Press Ϫ1 New Haven and London 0 ϩ1 Name /yal05/27282_u00 01/27/06 10:25AM Plate # 0-Composite pg 4 # 4 Copyright ᭧ 2006 by Yochai Benkler. All rights reserved. Subject to the exception immediately following, this book may not be repro- duced, in whole or in part, including illustrations, in any form (beyond that copy- ing permitted by Sections 107 and 108 of the U.S. Copyright Law and except by reviewers for the public press), without written permission from the publishers. The author has made an online version of the book available under a Creative Commons Noncommercial Sharealike license; it can be accessed through the author’s website at http://www.benkler.org. Printed in the United States of America. Library of Congress Cataloging-in-Publication Data Benkler, Yochai. The wealth of networks : how social production transforms markets and freedom / Yochai Benkler. p. cm. Includes bibliographical references and index. ISBN-13: 978-0-300-11056-2 (alk. paper) ISBN-10: 0-300-11056-1 (alk. paper) 1. Information society. 2. Information networks. 3. Computer networks—Social aspects. 4. Computer networks—Economic aspects. I. Title. HM851.B457 2006 303.48'33—dc22 2005028316 A catalogue record for this book is available from the British Library. The paper in this book meets the guidelines for permanence and durability of the Committee on Production Guidelines for Book Longevity of the Council on Library Resources. -

N2N: a Layer Two Peer-To-Peer VPN
N2N: A Layer Two Peer-to-Peer VPN Luca Deri1, Richard Andrews2 ntop.org, Pisa, Italy1 Symstream Technologies, Melbourne, Australia2 {deri, andrews}@ntop.org Abstract. The Internet was originally designed as a flat data network delivering a multitude of protocols and services between equal peers. Currently, after an explosive growth fostered by enormous and heterogeneous economic interests, it has become a constrained network severely enforcing client-server communication where addressing plans, packet routing, security policies and users’ reachability are almost entirely managed and limited by access providers. From the user’s perspective, the Internet is not an open transport system, but rather a telephony-like communication medium for content consumption. This paper describes the design and implementation of a new type of peer-to- peer virtual private network that can allow users to overcome some of these limitations. N2N users can create and manage their own secure and geographically distributed overlay network without the need for central administration, typical of most virtual private network systems. Keywords: Virtual private network, peer-to-peer, network overlay. 1. Motivation and Scope of Work Irony pervades many pages of history, and computing history is no exception. Once personal computing had won the market battle against mainframe-based computing, the commercial evolution of the Internet in the nineties stepped the computing world back to a substantially rigid client-server scheme. While it is true that the today’s Internet serves as a good transport system for supplying a plethora of data interchange services, virtually all of them are delivered by a client-server model, whether they are centralised or distributed, pay-per-use or virtually free [1]. -

A Generic Data Exchange System for F2F Networks
The Retroshare project The GXS system Decentralize your app! A Generic Data Exchange System for F2F Networks Cyril Soler C.Soler The GXS System 03 Feb. 2018 1 / 19 The Retroshare project The GXS system Decentralize your app! Outline I Overview of Retroshare I The GXS system I Decentralize your app! C.Soler The GXS System 03 Feb. 2018 2 / 19 The Retroshare project The GXS system Decentralize your app! The Retroshare Project I Mesh computers using signed TLS over TCP/UDP/Tor/I2P; I anonymous end-to-end encrypted FT with swarming; I mail, IRC chat, forums, channels; I available on Mac OS, Linux, Windows, (+ Android). C.Soler The GXS System 03 Feb. 2018 3 / 19 The Retroshare project The GXS system Decentralize your app! The Retroshare Project I Mesh computers using signed TLS over TCP/UDP/Tor/I2P; I anonymous end-to-end encrypted FT with swarming; I mail, IRC chat, forums, channels; I available on Mac OS, Linux, Windows. C.Soler The GXS System 03 Feb. 2018 3 / 19 The Retroshare project The GXS system Decentralize your app! The Retroshare Project I Mesh computers using signed TLS over TCP/UDP/Tor/I2P; I anonymous end-to-end encrypted FT with swarming; I mail, IRC chat, forums, channels; I available on Mac OS, Linux, Windows. C.Soler The GXS System 03 Feb. 2018 3 / 19 The Retroshare project The GXS system Decentralize your app! The Retroshare Project I Mesh computers using signed TLS over TCP/UDP/Tor/I2P; I anonymous end-to-end encrypted FT with swarming; I mail, IRC chat, forums, channels; I available on Mac OS, Linux, Windows. -
NAT Traversal About
NAT Traversal About Some difficulties have been encountered with devices that have poor NAT support. FreeSWITCH goes to great lengths to repair broken NAT support in phones and gateway devices. In order to aid FreeSWITCH in traversing NAT please see the External profile page. Some routers offer an Application Layer Gateway feature which can prevent FreeSWITCH NAT traversal from working. See the ALG page for more information, including how to disable it. Using STUN to aid in NAT Traversal STUN is a method to allow an end host (i.e. phone) to discover its public IP address if it is located behind a NAT . Using this method requires a STUN server on the public internet and a client on the phone. The phone's STUN client queries the STUN server for it's own public IP and transmits the information it has received in it's connection information in the SIP packets it sends to the SIP server. Enable and configure STUN settings on your phone in order correctly to report your phone's contact information to FreeSWITCH when registering. Unfortunately, not all phones have a properly working STUN client. STUN servers This site contains a list of public STUN servers: https://gist.github.com/zziuni/3741933 stun.freeswitch.org is never guaranteed to be up and running so use it in production at your own risk. There are several open source projects to run your own STUN server, e.g. STUNTMAN Using FreeSWITCH built-in methods to aid in NAT Traversal nat-options-ping This parameter causes FreeSWITCH to regularly (every 20 - 40s) send an OPTIONS packet to NATed registered endpoints in order to keep the port on the clients firewall open. -

The Edonkey File-Sharing Network
The eDonkey File-Sharing Network Oliver Heckmann, Axel Bock, Andreas Mauthe, Ralf Steinmetz Multimedia Kommunikation (KOM) Technische Universitat¨ Darmstadt Merckstr. 25, 64293 Darmstadt (heckmann, bock, mauthe, steinmetz)@kom.tu-darmstadt.de Abstract: The eDonkey 2000 file-sharing network is one of the most successful peer- to-peer file-sharing applications, especially in Germany. The network itself is a hybrid peer-to-peer network with client applications running on the end-system that are con- nected to a distributed network of dedicated servers. In this paper we describe the eDonkey protocol and measurement results on network/transport layer and application layer that were made with the client software and with an open-source eDonkey server we extended for these measurements. 1 Motivation and Introduction Most of the traffic in the network of access and backbone Internet service providers (ISPs) is generated by peer-to-peer (P2P) file-sharing applications [San03]. These applications are typically bandwidth greedy and generate more long-lived TCP flows than the WWW traffic that was dominating the Internet traffic before the P2P applications. To understand the influence of these applications and the characteristics of the traffic they produce and their impact on network design, capacity expansion, traffic engineering and shaping, it is important to empirically analyse the dominant file-sharing applications. The eDonkey file-sharing protocol is one of these file-sharing protocols. It is imple- mented by the original eDonkey2000 client [eDonkey] and additionally by some open- source clients like mldonkey [mlDonkey] and eMule [eMule]. According to [San03] it is with 52% of the generated file-sharing traffic the most successful P2P file-sharing net- work in Germany, even more successful than the FastTrack protocol used by the P2P client KaZaa [KaZaa] that comes to 44% of the traffic. -

IPFS and Friends: a Qualitative Comparison of Next Generation Peer-To-Peer Data Networks Erik Daniel and Florian Tschorsch
1 IPFS and Friends: A Qualitative Comparison of Next Generation Peer-to-Peer Data Networks Erik Daniel and Florian Tschorsch Abstract—Decentralized, distributed storage offers a way to types of files [1]. Napster and Gnutella marked the beginning reduce the impact of data silos as often fostered by centralized and were followed by many other P2P networks focusing on cloud storage. While the intentions of this trend are not new, the specialized application areas or novel network structures. For topic gained traction due to technological advancements, most notably blockchain networks. As a consequence, we observe that example, Freenet [2] realizes anonymous storage and retrieval. a new generation of peer-to-peer data networks emerges. In this Chord [3], CAN [4], and Pastry [5] provide protocols to survey paper, we therefore provide a technical overview of the maintain a structured overlay network topology. In particular, next generation data networks. We use select data networks to BitTorrent [6] received a lot of attention from both users and introduce general concepts and to emphasize new developments. the research community. BitTorrent introduced an incentive Specifically, we provide a deeper outline of the Interplanetary File System and a general overview of Swarm, the Hypercore Pro- mechanism to achieve Pareto efficiency, trying to improve tocol, SAFE, Storj, and Arweave. We identify common building network utilization achieving a higher level of robustness. We blocks and provide a qualitative comparison. From the overview, consider networks such as Napster, Gnutella, Freenet, BitTor- we derive future challenges and research goals concerning data rent, and many more as first generation P2P data networks, networks. -

A Fog Storage Software Architecture for the Internet of Things Bastien Confais, Adrien Lebre, Benoît Parrein
A Fog storage software architecture for the Internet of Things Bastien Confais, Adrien Lebre, Benoît Parrein To cite this version: Bastien Confais, Adrien Lebre, Benoît Parrein. A Fog storage software architecture for the Internet of Things. Advances in Edge Computing: Massive Parallel Processing and Applications, IOS Press, pp.61-105, 2020, Advances in Parallel Computing, 978-1-64368-062-0. 10.3233/APC200004. hal- 02496105 HAL Id: hal-02496105 https://hal.archives-ouvertes.fr/hal-02496105 Submitted on 2 Mar 2020 HAL is a multi-disciplinary open access L’archive ouverte pluridisciplinaire HAL, est archive for the deposit and dissemination of sci- destinée au dépôt et à la diffusion de documents entific research documents, whether they are pub- scientifiques de niveau recherche, publiés ou non, lished or not. The documents may come from émanant des établissements d’enseignement et de teaching and research institutions in France or recherche français ou étrangers, des laboratoires abroad, or from public or private research centers. publics ou privés. November 2019 A Fog storage software architecture for the Internet of Things Bastien CONFAIS a Adrien LEBRE b and Benoˆıt PARREIN c;1 a CNRS, LS2N, Polytech Nantes, rue Christian Pauc, Nantes, France b Institut Mines Telecom Atlantique, LS2N/Inria, 4 Rue Alfred Kastler, Nantes, France c Universite´ de Nantes, LS2N, Polytech Nantes, Nantes, France Abstract. The last prevision of the european Think Tank IDATE Digiworld esti- mates to 35 billion of connected devices in 2030 over the world just for the con- sumer market. This deep wave will be accompanied by a deluge of data, applica- tions and services. -

NAT and NAT Traversal Lecturer: Andreas Müller [email protected]
NAT and NAT Traversal lecturer: Andreas Müller [email protected] NetworkIN2097 - MasterSecurity, Course WS 2008/09, Computer Chapter Networks, 9 WS 2009/2010 39 NAT: Network Address Translation Problem: shortage of IPv4 addresses . more and more devices . only 32bit address field Idea: local network uses just one IP address as far as outside world is concerned: . range of addresses not needed from ISP: just one IP address for all devices . can change addresses of devices in local network without notifying outside world . can change ISP without changing addresses of devices in local network . devices inside local net not explicitly addressable, visible by outside world (a security plus). NetworkIN2097 - MasterSecurity, Course WS 2008/09, Computer Chapter Networks, 9 WS 2009/2010 40 NAT: Network Address (and Port) Translation rest of local network Internet (e.g., home network) 10.0.0/24 10.0.0.1 10.0.0.4 10.0.0.2 138.76.29.7 10.0.0.3 All datagrams leaving local Datagrams with source or network have same single source destination in this network NAT IP address: 138.76.29.7, have 10.0.0/24 address for different source port numbers source, destination (as usual) NetworkIN2097 - MasterSecurity, Course WS 2008/09, Computer Chapter Networks, 9 WS 2009/2010 41 NAT: Network Address Translation Implementation: NAT router must: . outgoing datagrams: replace (source IP address, port #) of every outgoing datagram to (NAT IP address, new port #) . remote clients/servers will respond using (NAT IP address, new port #) as destination addr. remember (in NAT translation table) every (source IP address, port #) to (NAT IP address, new port #) translation pair -> we have to maintain a state in the NAT . -

A Transport Layer Abstraction for Peer-To-Peer Networks Ronaldo A
A Transport Layer Abstraction for Peer-to-Peer Networks Ronaldo A. Ferreira, Christian Grothoff and Paul Ruth Department of Computer Sciences Purdue University g frf,grothoff,ruth @cs.purdue.edu http://www.gnu.org/software/GNUnet/ B Abstract— The initially unrestricted host-to-host communica- same peer-to-peer network. In fact, two peers A and may tion model provided by the Internet Protocol has deteriorated want to use differentmodes of communicationon the same link. due to political and technical changes caused by Internet growth. For example, suppose node B is behind a NAT box and cannot While this is not a problem for most client-server applications, peer-to-peer networks frequently struggle with peers that are be reached directly via UDP or TCP. In a system with multiple only partially reachable. We describe how a peer-to-peer frame- transport protocols, A could initiate a connection by sending an B A work can hide diversity and obstacles in the underlying Internet e-mail to B (SMTP) and then have contact via TCP, al- and provide peer-to-peer applications with abstractions that hide lowing A to continue further communication on a bidirectional transport specific details. We present the details of an implemen- TCP connection. tation of a transport service based on SMTP. Small-scale bench- marks are used to compare transport services over UDP, TCP, and We will use GNUnet as our reference peer-to-peer system, SMTP. but it should be clear that the idea of a transport abstraction can be applied to other systems. GNUnet is a peer-to-peer frame- work whose main focus is on security [1], [5]. -
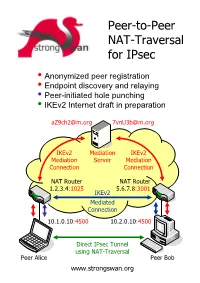
Peer-To-Peer NAT-Traversal for Ipsec
Peer-to-Peer NAT-Traversal for IPsec y Anonymized peer registration y Endpoint discovery and relaying y Peer-initiated hole punching y IKEv2 Internet draft in preparation [email protected] [email protected] IKEv2 Mediation IKEv2 Mediation Server Mediation Connection Connection NAT Router NAT Router 1.2.3.4:1025 5.6.7.8:3001 IKEv2 Mediated Connection 10.1.0.10:4500 10.2.0.10:4500 Direct IPsec Tunnel using NAT-Traversal Peer Alice Peer Bob www.strongswan.org The double NAT case - where punching holes counts! ● You are selling automation systems all over the world. In order to save on travel expenses you want to remotely diagnose and update your deployed systems via the Internet. But security counts – thus IPsec is a must! Unfortunately both you and your customer are behind NAT routers so that no direct VPN connection is possible. You are helplessly blocked! ● You own an apartment at home, in the mountains or even abroad. You want to remotely control the heating or your sophisticated intrusion detection system via ADSL or Cable access. But since you and your apartment are separated by two NAT routers your are helplessly blocked. How it works! ● Two peers want to set up a direct IPsec tunnel using the established NAT traversal mechanism of encapsulating ESP packets in UDP datagrams. Unfortunately they cannot achieve this by themselves because neither host is seen from the Internet under the standard IKE NAT-T port 4500. Therefore both peers need to set up a mediation connection with an IKEv2 mediation server. In order to prevent unsolicited connection attempts by foreign peers, the mediation connections use randomized pseudonyms as IKE peer identities. -

Recognition and Investigation of Listening in Anonymous Communication Systems 1 K
AEGAEUM JOURNAL ISSN NO: 0776-3808 Recognition and investigation of listening in anonymous communication systems 1 K. Balasubramanian, 2 Dr. S. Kannan, 3 S. Sharmila 1Associate Professor, Department of CSE, E.G.S Pillay Engineering College, Nagapattinam, Tamil Nadu, India. Email: [email protected] 2, Professor, Department of CSE, E.G.S Pillay Engineering College, Nagapattinam, Tamil Nadu, India. 3, P.G Student, Department of CSE, E.G.S Pillay Engineering College, Nagapattinam, Tamil Nadu, India. Abstract components through which client activity is steered can Mysterious correspondence systems similar to listen in and get delicate information, for example, user Tor, mostly secure the secrecy of client activity by verification qualifications. This circumstance can scrambling all interchanges inside the overlay system. conceivably decline when clients utilize intermediary based frameworks to get to similar administrations However, when the transferred activity achieves the without utilizing end-to-end encryption, as the quantity limits of the system, toward its end, the first client of hosts or hubs that can listen stealthily on their activity is definitely presented to the last node on the movement increments. Different open and private path. Accordingly, users sending sensitive information, systems may square access to interpersonal interaction similar to verification accreditations, over such and other prominent online administrations for systems, risk having their information between different reasons. Under these conditions, users accepted and uncovered, unless end-to-end encryption regularly depend on utilizing disseminated proxying frameworks to prevent their activity from being is utilized. Listening can be performed by malicious or filtered. They fall back on such mechanisms so as to compromised relay nodes, and additionally any rebel evade system activity filtering in light of source, goal, arrange substance on the way toward the actual end.