The Acoustics of Uvulars in Tlingit
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Mehri Ejective Fricatives: an Acoustic Study Rachid Ridouane, Cédric Gendrot, Rajesh Khatiwada
Mehri ejective fricatives: an acoustic study Rachid Ridouane, Cédric Gendrot, Rajesh Khatiwada To cite this version: Rachid Ridouane, Cédric Gendrot, Rajesh Khatiwada. Mehri ejective fricatives: an acoustic study. 18th International Congress of Phonetic Sciences, Aug 2015, Glasgow, United Kingdom. halshs- 01287685 HAL Id: halshs-01287685 https://halshs.archives-ouvertes.fr/halshs-01287685 Submitted on 15 Mar 2016 HAL is a multi-disciplinary open access L’archive ouverte pluridisciplinaire HAL, est archive for the deposit and dissemination of sci- destinée au dépôt et à la diffusion de documents entific research documents, whether they are pub- scientifiques de niveau recherche, publiés ou non, lished or not. The documents may come from émanant des établissements d’enseignement et de teaching and research institutions in France or recherche français ou étrangers, des laboratoires abroad, or from public or private research centers. publics ou privés. Mehri ejective fricatives: an acoustic study Rachid Ridouane, Cédric Gendrot, Rajesh Khatiwada Laboratoire de Phonétique et Phonologie (CNRS/Sorbonne Nouvelle), Paris ABSTRACT sequence of a pulmonic fricative followed by a glottal stop [3]. The second strategy, observed in Ejective consonants are not very common cross- Tlingit, was to produce ejective fricatives with a linguistically. Even less common is the occurrence much narrower constriction than was used in their of ejective fricatives. This infrequency is generally pulmonic counterparts [4]. This allowed for glottal attributed to the incompatibility of two aerodynamic closure to overlap the entire frication duration while requirements: a continuing flow of air to create noise producing high intra-oral pressure, suggesting that frication and an increasing intraoral air pressure to they were indeed ejective fricatives. -

LINGUISTICS 221 LECTURE #3 the BASIC SOUNDS of ENGLISH 1. STOPS a Stop Consonant Is Produced with a Complete Closure of Airflow
LINGUISTICS 221 LECTURE #3 Introduction to Phonetics and Phonology THE BASIC SOUNDS OF ENGLISH 1. STOPS A stop consonant is produced with a complete closure of airflow in the vocal tract; the air pressure has built up behind the closure; the air rushes out with an explosive sound when released. The term plosive is also used for oral stops. ORAL STOPS: e.g., [b] [t] (= plosives) NASAL STOPS: e.g., [m] [n] (= nasals) There are three phases of stop articulation: i. CLOSING PHASE (approach or shutting phase) The articulators are moving from an open state to a closed state; ii. CLOSURE PHASE (= occlusion) Blockage of the airflow in the oral tract; iii. RELEASE PHASE Sudden reopening; it may be accompanied by a burst of air. ORAL STOPS IN ENGLISH a. BILABIAL STOPS: The blockage is made with the two lips. spot [p] voiceless baby [b] voiced 1 b. ALVEOLAR STOPS: The blade (or the tip) of the tongue makes a closure with the alveolar ridge; the sides of the tongue are along the upper teeth. lamino-alveolar stops or Check your apico-alveolar stops pronunciation! stake [t] voiceless deep [d] voiced c. VELAR STOPS: The closure is between the back of the tongue (= dorsum) and the velum. dorso-velar stops scar [k] voiceless goose [g] voiced 2. NASALS (= nasal stops) The air is stopped in the oral tract, but the velum is lowered so that the airflow can go through the nasal tract. All nasals are voiced. NASALS IN ENGLISH a. BILABIAL NASAL: made [m] b. ALVEOLAR NASAL: need [n] c. -

The Violability of Backness in Retroflex Consonants
The violability of backness in retroflex consonants Paul Boersma University of Amsterdam Silke Hamann ZAS Berlin February 11, 2005 Abstract This paper addresses remarks made by Flemming (2003) to the effect that his analysis of the interaction between retroflexion and vowel backness is superior to that of Hamann (2003b). While Hamann maintained that retroflex articulations are always back, Flemming adduces phonological as well as phonetic evidence to prove that retroflex consonants can be non-back and even front (i.e. palatalised). The present paper, however, shows that the phonetic evidence fails under closer scrutiny. A closer consideration of the phonological evidence shows, by making a principled distinction between articulatory and perceptual drives, that a reanalysis of Flemming’s data in terms of unviolated retroflex backness is not only possible but also simpler with respect to the number of language-specific stipulations. 1 Introduction This paper is a reply to Flemming’s article “The relationship between coronal place and vowel backness” in Phonology 20.3 (2003). In a footnote (p. 342), Flemming states that “a key difference from the present proposal is that Hamann (2003b) employs inviolable articulatory constraints, whereas it is a central thesis of this paper that the constraints relating coronal place to tongue-body backness are violable”. The only such constraint that is violable for Flemming but inviolable for Hamann is the constraint that requires retroflex coronals to be articulated with a back tongue body. Flemming expresses this as the violable constraint RETRO!BACK, or RETRO!BACKCLO if it only requires that the closing phase of a retroflex consonant be articulated with a back tongue body. -

English Phonetic Vowel Shortening and Lengthening As Perceptually Active for the Poles
View metadata, citation and similar papers at core.ac.uk brought to you by CORE Title: English phonetic vowel shortening and lengthening as perceptually active for the Poles Author: Arkadiusz Rojczyk Citation style: Rojczyk Arkadiusz. (2007). English phonetic vowel shortening and lengthening as perceptually active for the Poles. W: J. Arabski (red.), "On foreign language acquisition and effective learning" (S. 237-249). Katowice : Wydawnictwo Uniwersytetu Śląskiego Phonological subsystem English phonetic vowel shortening and lengthening as perceptually active for the Poles Arkadiusz Rojczyk University of Silesia, Katowice 1. Introduction Auditory perception is one of the most thriving and active domains of psy cholinguistics. Recent years have witnessed manifold attempts to investigate and understand how humans perceive linguistic sounds and what principles govern the process. The major assumption underlying the studies on auditory perception is a simple fact that linguistic sounds are means of conveying meaning, encoded by a speaker, to a hearer. The speaker, via articulatory gestures, transmits a message encoded in acoustic waves. This is the hearer, on the other hand, who, using his perceptual apparatus, reads acoustic signals and decodes them into the meaning. Therefore, in phonetic terms, the whole communicative act can be divided into three stages. Articulatory - the speaker encodes the message by sound production. Acoustic - the message is transmitted to the hearer as acous tic waves. Auditory - the hearer perceives sounds and decodes them into the meaning. Each of the three stages is indispensable for effective communication. Of the three aforementioned stages of communication, the auditory percep tion is the least amenable to precise depiction and understanding. -

Part 1: Introduction to The
PREVIEW OF THE IPA HANDBOOK Handbook of the International Phonetic Association: A guide to the use of the International Phonetic Alphabet PARTI Introduction to the IPA 1. What is the International Phonetic Alphabet? The aim of the International Phonetic Association is to promote the scientific study of phonetics and the various practical applications of that science. For both these it is necessary to have a consistent way of representing the sounds of language in written form. From its foundation in 1886 the Association has been concerned to develop a system of notation which would be convenient to use, but comprehensive enough to cope with the wide variety of sounds found in the languages of the world; and to encourage the use of thjs notation as widely as possible among those concerned with language. The system is generally known as the International Phonetic Alphabet. Both the Association and its Alphabet are widely referred to by the abbreviation IPA, but here 'IPA' will be used only for the Alphabet. The IPA is based on the Roman alphabet, which has the advantage of being widely familiar, but also includes letters and additional symbols from a variety of other sources. These additions are necessary because the variety of sounds in languages is much greater than the number of letters in the Roman alphabet. The use of sequences of phonetic symbols to represent speech is known as transcription. The IPA can be used for many different purposes. For instance, it can be used as a way to show pronunciation in a dictionary, to record a language in linguistic fieldwork, to form the basis of a writing system for a language, or to annotate acoustic and other displays in the analysis of speech. -

SSC: the Science of Talking
SSC: The Science of Talking (for year 1 students of medicine) Week 3: Sounds of the World’s Languages (vowels and consonants) Michael Ashby, Senior Lecturer in Phonetics, UCL PLIN1101 Introduction to Phonetics and Phonology A Lecture 4 page 1 Vowel Description Essential reading: Ashby & Maidment, Chapter 5 4.1 Aim: To introduce the basics of vowel description and the main characteristics of the vowels of RP English. 4.2 Definition of vowel: Vowels are produced without any major obstruction of the airflow; the intra-oral pressure stays low, and vowels are therefore sonorant sounds. Vowels are normally voiced. Vowels are articulated by raising some part of the tongue body (that is the front or the back of the tongue notnot the tip or blade) towards the roof of the oral cavity (see Figure 1). 4.3 Front vowels are produced by raising the front of the tongue towards the hard palate. Back vowels are produced by raising the back of the tongue towards the soft palate. Central vowels are produced by raising the centre part of the tongue towards the junction of the hard and soft palates. 4.4 The height of a vowel refers to the degree of raising of the relevant part of the tongue. If the tongue is raised so as to be close to the roof of the oral cavity then a close or high vowel is produced. If the tongue is only slightly raised, so that there is a wide gap between its highest point and the roof of the oral cavity, then an open or lowlowlow vowel results. -

Word Study Guide for Parents
Descriptions of Word Study Patterns/Concepts Purpose of Word Study • It teaches students to examine words to discover the regularities, patterns, and conventions of the English language in order to read and spell. • It increases specific knowledge of words – the spelling and meaning of individual words. 3 Layers of word study • Alphabet – learning the relationship between letters and sounds • Pattern – learning specific groupings of letters and their sounds • Meaning – learning the meaning of groups of letters such as prefixes, suffixes, and roots. Vocabulary increases at this layer. Sorting – organizing words into groups based on similarities in their patterns or meaning. Oddballs – words that cannot be grouped into any of the identified categories of a sort. Students should be taught that there are always words that “break the rules” and do not follow the general pattern. Sound marks / / - Sound marks around a letter or pattern tell the student to focus only on the sound rather than the actual letters. (example: the word gem could be grouped into the /j/ category because it sounds like j at the beginning). Vowel (represented by V) – one of 6 letters causing the mouth to open when vocalized (a, e, i, o, u, and usually y). A single vowel sound is heard in every syllable of a word. Consonants (represented by C) – all letters other than the vowels. Consonant sounds are blocked by the lips, tongue, or teeth during articulation. Concepts in Order of Instruction Initial and final consonants – students are instructed to look at pictures and identify the beginning sound. They then connect the beginning sound to the letter that makes that sound. -

Chapter 9 Consonant Substitution in Child Language (Ikwere) Roseline I
Chapter 9 Consonant substitution in child language (Ikwere) Roseline I. C. Alerechi University of Port Harcourt The Ikwere language is spoken in four out of the twenty-three Local Government Areas (LGAs) of Rivers State of Nigeria, namely, Port Harcourt, Obio/Akpor, Emohua and Ikwerre LGAs. Like Kana, Kalabari and Ekpeye, it is one of the major languages of Rivers State of Nigeria used in broadcasting in the electronic media. The Ikwere language is classified asan Igboid language of the West Benue-Congo family of the Niger-Congo phylum of languages (Williamson 1988: 67, 71, Williamson & Blench 2000: 31). This paper treats consonant substi- tution in the speech of the Ikwere child. It demonstrates that children use of a language can contribute to the divergent nature of that language as they always strive for simplification of the target language. Using simple descriptive method of data analysis, the paper identifies the various substitutions of consonant sounds, which characterize the Ikwere children’s ut- terances. It stresses that the substitutions are regular and rule governed and hence implies the operation of some phonological processes. Some of the processes are strengthening and weakening of consonants, loss of suction of labial implosives causing them to become labial plosives, devoicing of voiced consonants, etc. While some of these processes are identical with the adult language, others are peculiar to children, demonstrating the relationships between the phonological processes in both forms of speech. It is worthy of note that high- lighting the relationships and differences will make for effective communication between children and adults. 1 Introduction The Ikwere language is spoken in four out of the twenty-three Local Government Areas (LGAs) of Rivers State of Nigeria, namely, Port Harcourt, Obio/Akpor, Emohua and Ik- werre LGAs. -

Locutour Guide to Letters, Sounds, and Symbols
LOCUTOUROUR® Guide to Letters, Sounds, and Symbols LOCUTOUR ABEL LASSIFICATION LACE OR RTICULATION PELLED AS XAMPLES S PELLINGP E L L I N G L C P A IPA S E Consonants p bilabial plosive voiceless lips /p/ p, pp pit, puppy b bilabial plosive voiced lips /b/ b, bb bat, ebb t lingua-alveolar plosive voiceless tongue tip + upper gum ridge /t/ t, ed, gth, th, tt, tw tan, tipped, tight, thyme, attic, two d lingua-alveolar plosive voiced tongue tip + upper gum ridge /d/ d, dd, ed dad, ladder, bagged k lingua-velar plosive voiceless back of tongue and soft palate /k/ c, cc, ch, ck cab, occur, school, duck que, k mosque, kit g lingua-velar plosive voiced back of tongue and soft palate /g/ g, gg, gh, gu, gue hug, bagged, Ghana, guy, morgue f labiodental fricative voiceless lower lip + upper teeth /f/ f, ff , gh, ph feet, fl u uff, enough, phone v labiodental fricative voiced lower lip + upper teeth /v/ v, vv, f, ph vet, savvy, of, Stephen th linguadental fricative voiceless tongue + teeth /T/ th thin th linguadental fricative voiced tongue + teeth /D/ th, the them, bathe s lingua-alveolar fricative voiceless tongue tip + upper gum ridge or /s/ s, ss, sc, ce, ci, sit, hiss, scenic, ace, city tongue tip + lower gum ridge cy, ps, z cycle, psychology, pizza z lingua-alveolar fricative voiced tongue tip + upper gum ridge or /z/ z, zz, s, ss, x, cz Zen, buzz, is, scissors, tongue tip + lower gum ridge Xerox, czar sh linguapalatal fricative voiceless tongue blade and hard palate /S/ sh, ce, ch, ci, sch, si, sheep, ocean, chef, glacier, kirsch ss, su, -

Characteristics of Non-Pre-Vocalic Ejectives in Yakima Sahaptin Sharon Hargus Virginia Beavert University of Washington University of Oregon
Characteristics of non-pre-vocalic ejectives in Yakima Sahaptin Sharon Hargus Virginia Beavert University of Washington University of Oregon NoWPhon, UO, Eugene, 5-13-16 1 Organization • Ejective background • Sahaptin • Word-final ejectives • Pre-consonantal ejectives • Conclusions and further research 2 Ejectives 3 Ejective types • Plosives [t’] • Affricates [ts’] • Fricatives [s’] 5 Some properties of pre-vocalic ejectives • f0 low or high at vowel onset • Silent period • Slow rise time 6 Lindau, Mona. 1984. Phonetic differences in glottalic consonants. Journal of Phonetics 12:147-155. Tlingit /χ/ vs. /χ’/ • /χaːt/ ‘spruce roots’ /χ’aːn’/ ‘fire’ Maddieson, Ian, Caroline L. Smith, and Nicola Bessell. 2001. 'Aspects of the Phonetics of Tlingit.' 7 Anthropological Linguistics 43:135-176. Ejective distribution • In most languages, ejectives only occur before vowels – Chipewyan, Witsuwit’en, etc. • In some languages, ejectives also occur before consonants and/or word-finally – Tlingit, Gitksan, Coast Tsimshian, Montana Salish, Ahtna, etc. – Ejectives in these environments less well described 8 Tlingit word-final ejective stops • “shorter and higher-amplitude noise than the pulmonic stops” glottal release h • /k’éːt/ ‘salmonberry bush; sprouts’ /k aːk’/ ‘forehead’ Maddieson, Ian, Caroline L. Smith, and Nicola Bessell. 2001. 'Aspects of the Phonetics of Tlingit.' 9 Anthropological Linguistics 43:135-176. Tlingit ejective fricatives • Pre-vocalic: Post-vocalic: • post-glottalized pre-glottalized [χ’aːn] ‘fire’ [khaːχ’] ‘chicken, grouse’ 10 Coast Tsimshian • Post-vocalic ejective stops and affricates are pre-glottalized: <’k, ’k, ’p, ’t, ’ts> – hanaa’k ‘woman’ – ~ hana’a Dunn, John Asher. 1979. Sm'algyax: A Reference Dictionary and Grammar for the Coast Tsimshian 11 Language. -

August 25-26, 1969
Fourth International Conference on Salish Languages University of Victoria August 25-26, 1969 LABIALIZATION IN NOOTKAN William H. Jacobsen Jr. University of Nevada A well-known phonological characteristic of most of the Indian languages of the Northwest is the presence of contrast ing pairs of plain and labialized dorsal consonants. In 1920 Boas observed: The study of phonetics indicates that certain features have a limited and well-defined distribution which, on the whole, is conttnuous. To give an example: the extra ordinary development of the series of k sounds and of laterals (1 sounds) is common to the most diverse languages of the NOrth Pacific coast, while in California and east of the Rocky mountains this characteristic feature disappears •••• The labialization of k sounds following an 0 or u is widely spread in the eftreme-Northwest, arid infrequent 'Outside of that territory. Later he elaborated on this statement, in the context of making comparisons to the phenomenon as occurring in Kwakiutl: The labialization of k sounds after 0 and u is a widely spread phenomenon on the Pacific coast~. Tn Chinook when a u vowel precedes a k sound and the latter is either followed oy a vowel or is a prefix, it must be labial~zed or followed by a vowel of the u group (HAIL I, 569). In Tlingit k sounds preceded by 0 or u-change the following i and e to 0 and u ~ibid. p. 16;). A similar type of labia~ization of-k after --a, 0, and -u occurs in Kutenai (IJAL IV, p. -
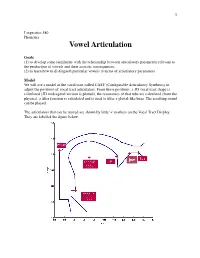
Vowel Articulation
1 Linguistics 580 Phonetics Vowel Articulation Goals (1) to develop some familiarity with the relationship between articulatory parameters relevant to the production of vowels and their acoustic consequences. (2) to learn how to distinguish particular vowels in terms of articulatory parameters. Model We will use a model of the vocal tract called CASY (Configurable Articulatory Synthesis) to adjust the positions of vocal tract articulators. From those positions, a 3D vocal tract shape is calculated (2D midsagittal version is plotted), the resonances of that tube are calculated (from the physics), a filter function is calculated and is used to filter a glottal-like buzz. The resulting sound can be played. The articulators that can be moved are shown by little '+' markers on the Vocal Tract Display. They are labelled the figure below. 2 The articulators can be moved by positioning the mouse pointer over one of these markers, then holding down the button and dragging it to a new position. As you are dragging, the articulator will move and the vocal tract shape will be updated appropriately. A new filter function and formants will also be displayed, and a new sound can be played. The articulator positions are defined relative to one another in a dependence hierarchy. The lower lip, tongue body, and tongue tip are dependent on the position of the jaw, so when the jaw moves, these articulators more along with it. The tongue tip is dependent on the position of the tongue body. The upper lip is dependent on the position of the lower lip. For this exercise with vowels, you should be able to produce decent approximations to English vowels by manipulating only the jaw, tongue body, and lips.