(WCSV-1), a Novel Soymovirus in Water Chestnuts (Eleocharis Dulcis) Fangpeng Zhang1,2, Zuokun Yang1,2, Ni Hong1,2, Guoping Wang1,2, Aiming Wang3 and Liping Wang1,2*
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
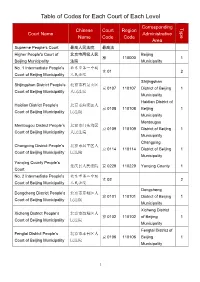
Table of Codes for Each Court of Each Level
Table of Codes for Each Court of Each Level Corresponding Type Chinese Court Region Court Name Administrative Name Code Code Area Supreme People’s Court 最高人民法院 最高法 Higher People's Court of 北京市高级人民 Beijing 京 110000 1 Beijing Municipality 法院 Municipality No. 1 Intermediate People's 北京市第一中级 京 01 2 Court of Beijing Municipality 人民法院 Shijingshan Shijingshan District People’s 北京市石景山区 京 0107 110107 District of Beijing 1 Court of Beijing Municipality 人民法院 Municipality Haidian District of Haidian District People’s 北京市海淀区人 京 0108 110108 Beijing 1 Court of Beijing Municipality 民法院 Municipality Mentougou Mentougou District People’s 北京市门头沟区 京 0109 110109 District of Beijing 1 Court of Beijing Municipality 人民法院 Municipality Changping Changping District People’s 北京市昌平区人 京 0114 110114 District of Beijing 1 Court of Beijing Municipality 民法院 Municipality Yanqing County People’s 延庆县人民法院 京 0229 110229 Yanqing County 1 Court No. 2 Intermediate People's 北京市第二中级 京 02 2 Court of Beijing Municipality 人民法院 Dongcheng Dongcheng District People’s 北京市东城区人 京 0101 110101 District of Beijing 1 Court of Beijing Municipality 民法院 Municipality Xicheng District Xicheng District People’s 北京市西城区人 京 0102 110102 of Beijing 1 Court of Beijing Municipality 民法院 Municipality Fengtai District of Fengtai District People’s 北京市丰台区人 京 0106 110106 Beijing 1 Court of Beijing Municipality 民法院 Municipality 1 Fangshan District Fangshan District People’s 北京市房山区人 京 0111 110111 of Beijing 1 Court of Beijing Municipality 民法院 Municipality Daxing District of Daxing District People’s 北京市大兴区人 京 0115 -

Sequences and Phylogenies of Plant Pararetroviruses, Viruses and Transposable Elements
Hansen and Heslop-Harrison. 2004. Adv.Bot.Res. 41: 165-193. Page 1 of 34. FROM: 231. Hansen CN, Heslop-Harrison JS. 2004 . Sequences and phylogenies of plant pararetroviruses, viruses and transposable elements. Advances in Botanical Research 41 : 165-193. Sequences and Phylogenies of 5 Plant Pararetroviruses, Viruses and Transposable Elements CELIA HANSEN AND JS HESLOP-HARRISON* DEPARTMENT OF BIOLOGY 10 UNIVERSITY OF LEICESTER LEICESTER LE1 7RH, UK *AUTHOR FOR CORRESPONDENCE E-MAIL: [email protected] 15 WEBSITE: WWW.MOLCYT.COM I. Introduction ............................................................................................................2 A. Plant genome organization................................................................................2 20 B. Retroelements in the genome ............................................................................3 C. Reverse transcriptase.........................................................................................4 D. Viruses ..............................................................................................................5 II. Retroelements........................................................................................................5 A. Viral retroelements – Retrovirales....................................................................6 25 B. Non-viral retroelements – Retrales ...................................................................7 III. Viral and non-viral elements................................................................................7 -

ICTV Code Assigned: 2011.001Ag Officers)
This form should be used for all taxonomic proposals. Please complete all those modules that are applicable (and then delete the unwanted sections). For guidance, see the notes written in blue and the separate document “Help with completing a taxonomic proposal” Please try to keep related proposals within a single document; you can copy the modules to create more than one genus within a new family, for example. MODULE 1: TITLE, AUTHORS, etc (to be completed by ICTV Code assigned: 2011.001aG officers) Short title: Change existing virus species names to non-Latinized binomials (e.g. 6 new species in the genus Zetavirus) Modules attached 1 2 3 4 5 (modules 1 and 9 are required) 6 7 8 9 Author(s) with e-mail address(es) of the proposer: Van Regenmortel Marc, [email protected] Burke Donald, [email protected] Calisher Charles, [email protected] Dietzgen Ralf, [email protected] Fauquet Claude, [email protected] Ghabrial Said, [email protected] Jahrling Peter, [email protected] Johnson Karl, [email protected] Holbrook Michael, [email protected] Horzinek Marian, [email protected] Keil Guenther, [email protected] Kuhn Jens, [email protected] Mahy Brian, [email protected] Martelli Giovanni, [email protected] Pringle Craig, [email protected] Rybicki Ed, [email protected] Skern Tim, [email protected] Tesh Robert, [email protected] Wahl-Jensen Victoria, [email protected] Walker Peter, [email protected] Weaver Scott, [email protected] List the ICTV study group(s) that have seen this proposal: A list of study groups and contacts is provided at http://www.ictvonline.org/subcommittees.asp . -

Ribosome Shunting, Polycistronic Translation, and Evasion of Antiviral Defenses in Plant Pararetroviruses and Beyond Mikhail M
Ribosome Shunting, Polycistronic Translation, and Evasion of Antiviral Defenses in Plant Pararetroviruses and Beyond Mikhail M. Pooggin, Lyuba Ryabova To cite this version: Mikhail M. Pooggin, Lyuba Ryabova. Ribosome Shunting, Polycistronic Translation, and Evasion of Antiviral Defenses in Plant Pararetroviruses and Beyond. Frontiers in Microbiology, Frontiers Media, 2018, 9, pp.644. 10.3389/fmicb.2018.00644. hal-02289592 HAL Id: hal-02289592 https://hal.archives-ouvertes.fr/hal-02289592 Submitted on 16 Sep 2019 HAL is a multi-disciplinary open access L’archive ouverte pluridisciplinaire HAL, est archive for the deposit and dissemination of sci- destinée au dépôt et à la diffusion de documents entific research documents, whether they are pub- scientifiques de niveau recherche, publiés ou non, lished or not. The documents may come from émanant des établissements d’enseignement et de teaching and research institutions in France or recherche français ou étrangers, des laboratoires abroad, or from public or private research centers. publics ou privés. Distributed under a Creative Commons Attribution - ShareAlike| 4.0 International License fmicb-09-00644 April 9, 2018 Time: 16:25 # 1 REVIEW published: 10 April 2018 doi: 10.3389/fmicb.2018.00644 Ribosome Shunting, Polycistronic Translation, and Evasion of Antiviral Defenses in Plant Pararetroviruses and Beyond Mikhail M. Pooggin1* and Lyubov A. Ryabova2* 1 INRA, UMR Biologie et Génétique des Interactions Plante-Parasite, Montpellier, France, 2 Institut de Biologie Moléculaire des Plantes, Centre National de la Recherche Scientifique, UPR 2357, Université de Strasbourg, Strasbourg, France Viruses have compact genomes and usually translate more than one protein from polycistronic RNAs using leaky scanning, frameshifting, stop codon suppression or reinitiation mechanisms. -

Plant Virus Evolution
Marilyn J. Roossinck Editor Plant Virus Evolution Plant Virus Evolution Marilyn J. Roossinck Editor Plant Virus Evolution Dr. Marilyn J. Roossinck The Samuel Roberts Noble Foundation Plant Biology Division P.O. Box 2180 Ardmore, OK 73402 USA Cover Photo: Integrated sequences of Petunia vein cleaning virus (in red) are seen in a chromosome spread of Petunia hybrida (see Chapter 4). ISBN: 978-3-540-75762-7 e-ISBN: 978-3-540-75763-4 Library of Congress Control Number: 2007940847 © 2008 Springer-Verlag Berlin Heidelberg This work is subject to copyright. All rights are reserved, whether the whole or part of the material is concerned, specifically the rights of translation, reprinting, reuse of illustrations, recitation, broadcasting, reproduction on microfilm or in any other way, and storage in data banks. Duplication of this publication or parts thereof is permitted only under the provisions of the German Copyright Law of September 9, 1965, in its current version, and permission for use must always be obtained from Springer. Violations are liable to prosecution under the German Copyright Law. The use of general descriptive names, registered names, trademarks, etc. in this publication does not imply, even in the absence of a specific statement, that such names are exempt from the relevant protective laws and regulations and therefore free for general use. Cover design: WMXDesign GmbH, Heidelberg, Germany Printed on acid-free paper 9 8 7 6 5 4 3 2 1 springer.com Preface The evolution of viruses has been a topic of intense investigation and theoretical development over the past several decades. Numerous workshops, review articles, and books have been devoted to the subject. -

An Abstract of the Dissertation Of
AN ABSTRACT OF THE DISSERTATION OF Alfredo Diaz Lara for the degree of Doctor of Philosophy in Botany and Plant Pathology presented on December 16, 2016. Title: Identification of Endogenous and Exogenous Pararetroviruses in Red Raspberry (Rubus idaeus L.) and Blueberry (Vaccinium corymbosum L.). Abstract approved: ______________________________________________________ Robert R. Martin The Pacific Northwest (Oregon and Washington in the United States and British Columbia in Canada) is one of the major producers of red raspberry (Rubus idaeus L.) and blueberry (Vaccinium corymbosum L.) in the world. The expansion of growing area with these crops has resulted in the emergence of new virus diseases that cause serious economic losses. The majority of viruses affecting plants (including blueberry and red raspberry) contain RNA genomes. In contrast, plant viruses with DNA genomes are relatively rare and most of the time ignored in virus surveys. The family Caulimoviridae is a group of plant pararetroviruses (reverse-transcribing viruses) with the ability to integrate their DNA into the host genome, resulting in complex molecular interactions that lead to inconsistencies in terms of detection and disease symptoms. Albeit, few studies have been conducted to determine the nature of plant pararetroviruses and their relationships with the associated host. To investigate the presence of pararetroviruses in blueberry and red raspberry, and their possible integration events, different plant material suspected to be infected with viruses was collected in nurseries, commercial fields and clonal germplasm repositories for a period of four years. For blueberry, using rolling circle amplification (RCA) a new virus was identified and named Blueberry fruit drop-associated virus (BFDaV) because of its association with fruit-drop disorder. -

Genomic Characterization of the Cacao Swollen Shoot Virus Complex and Other Theobroma Cacao-Infecting Badnaviruses
Genomic Characterization of the Cacao Swollen Shoot Virus Complex and other Theobroma Cacao-Infecting Badnaviruses Item Type text; Electronic Dissertation Authors Chingandu, Nomatter Publisher The University of Arizona. Rights Copyright © is held by the author. Digital access to this material is made possible by the University Libraries, University of Arizona. Further transmission, reproduction or presentation (such as public display or performance) of protected items is prohibited except with permission of the author. Download date 29/09/2021 07:25:04 Link to Item http://hdl.handle.net/10150/621859 GENOMIC CHARACTERIZATION OF THE CACAO SWOLLEN SHOOT VIRUS COMPLEX AND OTHER THEOBROMA CACAO-INFECTING BADNAVIRUSES by Nomatter Chingandu __________________________ A Dissertation Submitted to the Faculty of the SCHOOL OF PLANT SCIENCES In Partial Fulfillment of the Requirements For the Degree of DOCTOR OF PHILOSOPHY WITH A MAJOR IN PLANT PATHOLOGY In the Graduate College THE UNIVERSITY OF ARIZONA 2016 1 THE UNIVERSITY OF ARIZONA GRADUATE COLLEGE As members of the Dissertation Committee, we certify that we have read the dissertation prepared by Nomatter Chingandu, entitled “Genomic characterization of the Cacao swollen shoot virus complex and other Theobroma cacao-infecting badnaviruses” and recommend that it be accepted as fulfilling the dissertation requirement for the Degree of Doctor of Philosophy. _______________________________________________________ Date: 7.27.2016 Dr. Judith K. Brown _______________________________________________________ Date: 7.27.2016 Dr. Zhongguo Xiong _______________________________________________________ Date: 7.27.2016 Dr. Peter J. Cotty _______________________________________________________ Date: 7.27.2016 Dr. Barry M. Pryor _______________________________________________________ Date: 7.27.2016 Dr. Marc J. Orbach Final approval and acceptance of this dissertation is contingent upon the candidate’s submission of the final copies of the dissertation to the Graduate College. -

List of Business Partners and Factories – October 2020
Otto Group – List of business partners and factories – October 2020 This list contains business partners (only private labels) as well as the final production factories, which have been active for the Otto Group companies bonprix, Otto, myToys, Heine, Schwab and/or Witt. A business partner/factory is considered active if it has been active within the past 12 months and remains active as of the date the list is created. Only factories that are located in so-called risk countries according to the amfori BSCI classification are included. The Otto Group also produces in non-risk countries, e.g. the EU. All factory related information is based on data that suppliers share with Otto Group companies. The list is updated regularly but not on a daily basis. Type of Supplier Name Country City Factory Address Type of Social Audit/Certificate Business Partner 3S IMPORT & EXPORT SHIJIA CO., LTD China Shijiazhuang n.a. n.a. Business Partner A&R MODEN GMBH Germany Loerrach n.a. n.a. Business Partner A.KUDRESOVO FIRMA Lithuania Kaunas n.a. n.a. Business Partner AANYA DESIGNS MANUFACTURERS & EXPORTERS India Moradabad n.a. n.a. Business Partner AB KAUNO BALDAI Lithuania Kaunas n.a. n.a. Business Partner ABG24 Spolka z ograniczona odpowiedzialnosic (0010053817) Poland Lodz n.a. n.a. Business Partner ACTONA COMPANY A/S Denmark Holstebro n.a. n.a. Business Partner ADALTEKS LTD Bulgaria Sofia n.a. n.a. Business Partner ADAM EXPORTS SYNTHOFINE IND. ESTATE, B (0020010395) India Mumbai n.a. n.a. Business Partner ADIYAMAN DENIZ TEKSTIL SAN VE DIS TIC. -

University of Oklahoma Graduate College Direct Metagenomic Detection and Analysis of Plant Viruses Using an Unbiased High-Throug
UNIVERSITY OF OKLAHOMA GRADUATE COLLEGE DIRECT METAGENOMIC DETECTION AND ANALYSIS OF PLANT VIRUSES USING AN UNBIASED HIGH-THROUGHPUT SEQUENCING APPROACH A DISSERTATION SUBMITTED TO THE GRADUATE FACULTY in partial fulfillment of the requirements for the Degree of DOCTOR OF PHILOSOPHY By GRAHAM BURNS WILEY Norman, Oklahoma 2009 DIRECT METAGENOMIC DETECTION AND ANALYSIS OF PLANT VIRUSES USING AN UNBIASED HIGH-THROUGHPUT SEQUENCING APPROACH A DISSERTATION APPROVED FOR THE DEPARTMENT OF CHEMISTRY AND BIOCHEMISTRY BY Dr. Bruce A. Roe, Chair Dr. Ann H. West Dr. Valentin Rybenkov Dr. George Richter-Addo Dr. Tyrell Conway ©Copyright by GRAHAM BURNS WILEY 2009 All Rights Reserved. Acknowledgments I would first like to thank my father, Randall Wiley, for his constant and unwavering support in my academic career. He truly is the “Winston Wolf” of my life. Secondly, I would like to thank my wife, Mandi Wiley, for her support, patience, and encouragement in the completion of this endeavor. I would also like to thank Dr. Fares Najar, Doug White, Jim White, and Steve Kenton for their friendship, insight, humor, programming knowledge, and daily morning coffee sessions. I would like to thank Hongshing Lai and Dr. Jiaxi Quan for their expertise and assistance in developing the TGPweb database. I would like to thank Dr. Marilyn Roossinck and Dr. Guoan Shen, both of the Noble Foundation, for their preparation of the samples for this project and Dr Rick Nelson and Dr. Byoung Min, also both of the Noble Foundation, for teaching me plant virus isolation techniques. I would like to thank Chunmei Qu, Ping Wang, Yanbo Xing, Dr. -

Evidence to Support Safe Return to Clinical Practice by Oral Health Professionals in Canada During the COVID-19 Pandemic: a Repo
Evidence to support safe return to clinical practice by oral health professionals in Canada during the COVID-19 pandemic: A report prepared for the Office of the Chief Dental Officer of Canada. November 2020 update This evidence synthesis was prepared for the Office of the Chief Dental Officer, based on a comprehensive review under contract by the following: Paul Allison, Faculty of Dentistry, McGill University Raphael Freitas de Souza, Faculty of Dentistry, McGill University Lilian Aboud, Faculty of Dentistry, McGill University Martin Morris, Library, McGill University November 30th, 2020 1 Contents Page Introduction 3 Project goal and specific objectives 3 Methods used to identify and include relevant literature 4 Report structure 5 Summary of update report 5 Report results a) Which patients are at greater risk of the consequences of COVID-19 and so 7 consideration should be given to delaying elective in-person oral health care? b) What are the signs and symptoms of COVID-19 that oral health professionals 9 should screen for prior to providing in-person health care? c) What evidence exists to support patient scheduling, waiting and other non- treatment management measures for in-person oral health care? 10 d) What evidence exists to support the use of various forms of personal protective equipment (PPE) while providing in-person oral health care? 13 e) What evidence exists to support the decontamination and re-use of PPE? 15 f) What evidence exists concerning the provision of aerosol-generating 16 procedures (AGP) as part of in-person -

Research Collection
Research Collection Doctoral Thesis Molecular and transcriptomic characterization of natural resistance to cassava brown streak viruses in cassava Author(s): Anjanappa, Ravi B. Publication Date: 2015 Permanent Link: https://doi.org/10.3929/ethz-a-010572922 Rights / License: In Copyright - Non-Commercial Use Permitted This page was generated automatically upon download from the ETH Zurich Research Collection. For more information please consult the Terms of use. ETH Library DISS. ETH NO. 22704 Molecular and transcriptomic characterization of natural resistance to cassava brown streak viruses in cassava (Manihot esculenta, Crantz) A thesis submitted to attain the degree of DOCTOR OF SCIENCES of ETH ZURICH (Dr. sc. ETH Zurich) Presented by Ravi Bodampalli Anjanappa Master of Science in Plant Biotechnology, University of Agricultural Sciences, Bangalore Born 12th August 1979 Citizen of India Accepted on the recommendation of Prof. Dr. Wilhelm Gruissem, examiner Prof. Dr. Hervé Vanderschuren, co-examiner Dr. Maruthi M. N. Gowda, co-examiner 2015 Table of Contents Abstract 1 Zusammenfassung 3 Abbreviations 5 General Introduction 7 Chapter 1: Natural Resistance to Plant Viruses 13 Chapter 2: Characterization of brown streak virus-resistant cassava 55 Chapter 3: Transcriptome modulation in susceptible and resistant cassava 82 varieties inoculated with cassava brown streak viruses Chapter 4: Identification and characterization of a resistance-breaking 131 Cassava brown streak virus isolate Chapter 5: Discussion and persceptives 159 Acknowledgements 169 Curriculum Vitae 170 Abstract Cassava (Manihot esculenta Crantz) production in eastern and central African countries is adversely impacted by cassava brown streak disease (CBSD), thereby threatening food security. CBSD is caused by two viral species, Cassava brown streak virus (CBSV) and Ugandan Cassava brown streak virus (UCBSV) which are collectively termed as cassava brown streak viruses (CBSVs). -

Characterization of Grapevine Vein Clearing Virus Expression
CHARACTERIZATION OF GRAPEVINE VEIN CLEARING VIRUS EXPRESSION STRATEGY AND DEVELOPMENT OF CAULIMOVIRUS INFECTIOUS CLONES _______________________________________ A Dissertation presented to the Faculty of the Graduate School at the University of Missouri-Columbia _______________________________________________________ In Partial Fulfillment of the Requirements for the Degree Doctor of Philosophy in Plant, Insect and Microbial Sciences _____________________________________________________ by YU ZHANG Dr. James E. Schoelz, Dissertation Supervisor DECEMBER 2016 The undersigned, appointed by the dean of the Graduate School, have examined the dissertation entitled CHARACTERIZATION OF GRAPEVINE VEIN CLEARING VIRUS EXPRESSION STRATEGY AND DEVELOPMENT OF CAULIMOVIRUS INFECTIOUS CLONES Presented by Yu Zhang A candidate for the degree of doctor of philosophy In Plant, Insect and Microbial Sciences And hereby certify that, in their opinion, it is worthy of acceptance. Dr. James E. Schoelz, PhD Dr. Wenping Qiu, PhD Dr. David G. Mendoza-Cózatl, PhD Dr. Trupti Joshi, PhD ACKNOWLEDGEMENTS I wish to express my appreciation to my advisor, Dr. James Schoelz, for his constant guidance and support during my doctoral studies. He is a role model to me as an enthusiastic and hard working scientist. Although I will leave MU, I will keep what I learnt from him with my future life. I owe thanks to members of my doctoral committee, Dr. Wenping Qiu, Dr. David G. Mendoza-Cózatl, and Dr. Trupti Joshi, for their helpful comments and suggestions. I also want to thank Dr. Dmitry Korkin, who served in my committee for one year and helped me with bioinformatics and data interpretation. Thanks are due to my colleagues in the lab, Dr. Carlos Angel, Dr. Andres Rodriguez, Mustafa Adhab, and Mohammad Fereidouni, who I really enjoyed working with.