Kubeflow Shows Promise in Standardizing the AI Devops Pipeline
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Migration Toward Safer, Secure Data Management
Cloud Database Trend Report Migration toward safer, secure data management BROUGHT TO YOU IN PARTNERSHIP WITH Table of Contents Highlights and Introduction 3 BY MELISSA HABIT Key Research Findings 4 BY MATT LEGER Leaders in Cloud Database 11 BY LINDSAY SMITH Ensuring SQL Server High Availability in the Cloud 16 BY DAVE BERMINGHAM Data Safety in Cloud-Based Databases 21 BY GRANT FRITCHEY 28 Diving Deeper Into Cloud Databases To sponsor a Trend Report: Call: (919) 678-0300 Email: [email protected] DZONE TREND REPORT: CLOUD DATABASES PAGE 2 Highlights and Introduction By Melissa Habit, Publications Manager at DZone Trends in cloud data storage continue to accelerate at a rapid pace. Now more than ever, organizations must evaluate their current and future data storage needs to find solutions that align with business goals. While cloud databases are relatively new to the scene, they show tremendous prospect in securing and managing data. In selecting our topic for this Trend Report, we found the amount of promise and advancement in the space to be unparalleled. This report highlights DZone’s original research on cloud databases and contributions from the community, as well as introduces new offerings within DZone Trend Reports. While you may know her as your friendly Java Zone copy editor, Lindsay Smith has stepped into the role of DZone’s Publications Content Manager. Among many new endeavors, she’s spearheading our new strategy for Executive Insights — a series we’ve titled, “Leaders in Tech,” which serves to complement our original research. The series focuses on the viewpoints of industry frontrunners, tech evangelists, and DZone members who share their insights into research findings and outlooks for the future. -

WORLD FINTECH REPORT 2018 Contents 4 Preface
in collaboration with WORLD FINTECH REPORT 2018 Contents 4 Preface 8 Executive Summary FinTechs Are Redefining the Financial Services Customer Journey 13 Competition and Rising Expectations Spur 14 Customer-Centricity Push – Identify gaps left by traditional Financial Services providers and explore changing customer expectations. Emerging Technologies Enable Customer 19 Journey Transformation – Data and insights are reshaping personalized experiences through automation and distributed ledger technology. Alignment with Customer Goals, Creation of 27 Trust, and Delivery of Digital, Agile, and Efficient Processes Are Catalysts for Success – Firms are driving innovation and operational excellence through agile and digital teams. World FinTech Report 2018 The Symbiotic Relationship between FinTechs and Traditional Financial Institutions 35 FinTech and Incumbent Firms’ Respective 36 Competitive Advantages and Shortcomings Make Collaboration a Logical Fit – A partnership ecosystem of FinTechs, incumbents, and other vendors fosters a win-win for stakeholders. Finding the Right Partners for Collaboration 44 Is Essential – Maintaining and accelerating scale is a common FinTech firm struggle, so the right collaboration partner is critical. Successful Collaboration Requires Commitment 49 and Agility from FinTechs and Incumbents – Selection of the appropriate engagement model boosts FinTech scale-up efforts. The Path Forward: An Impending Role for BigTechs? 60 – BigTechs could have massive impact on the Financial Services industry. Preface Once rather homogenous and somewhat staid, the financial services marketplace has transformed into a dynamic milieu of bar-raising specialists. These new-age professionals are devoted to meeting and exceeding the expectations of consumers who have become accustomed to personalized services from industries such as retail, travel, and electronics. Financial services customers no longer rely on one or two firms. -

Department of Defense Enterprise Devsecops Initiative
Headquarters U.S. Air Force I n t e g r i t y - S e r v i c e - E x c e l l e n c e How did the Department of Defense move to Kubernetes and Istio? Mr. Nicolas Chaillan Chief Software Officer, U.S. Air Force Co-Lead, DoD Enterprise DevSecOps Initiative V2.5 – UNCLASSFIED Must Adapt to Challenges Must Rapidly Adapt To Challenges I n t e g r i t y - S e r v i c e - E x c e l l e n c e 2 Must Adapt to Challenges Work as a Team! Must Adapt To Challenges I n t e g r i t y - S e r v i c e - E x c e l l e n c e 3 Must Adapt to Challenges Work as a Team! A Large Team! Must Adapt To Challenges I n t e g r i t y - S e r v i c e - E x c e l l e n c e 4 Must Adapt to Challenges With Various TechnologiesWork as a Team! A Large Team! Must Adapt To Challenges I n t e g r i t y - S e r v i c e - E x c e l l e n c e 5 Must Adapt to Challenges With Various Technologies Work as a Team! A Large Team! Must AdaptBring To Challenges It With Us! I n t e g r i t y - S e r v i c e - E x c e l l e n c e 6 Must Adapt to Challenges With Various Technologies Work as a Team! Even To Space! A Large Team! Must AdaptBring To Challenges It With Us! I n t e g r i t y - S e r v i c e - E x c e l l e n c e 7 Must Adapt to Challenges With Various Technologies Work as a Team! To Space! A Large Team! MustWith Adapt a FewBring To Sensors! Challenges It With Us! I n t e g r i t y - S e r v i c e - E x c e l l e n c e 8 With Their Help! Must Adapt to Challenges With Various Technologies Work as a Team! To Space! A Large Team! MustWith Adapt a FewBring To Sensors! Challenges It With Us! I n t e g r i t y - S e r v i c e - E x c e l l e n c e 9 What is the DoD Enterprise DevSecOps Initiative? Joint Program with OUSD(A&S), DoD CIO, U.S. -

Kubernetes & AI with Run:AI, Red Hat & Excelero
Kubernetes & AI with Run:AI, Red Hat & Excelero AI WEBINAR Date/Time: Tuesday, June 9 | 9 am PST What’s next in technology and innovation? Kubernetes & AI with Run:AI, Red Hat & Excelero AI WEBINAR Your Host: Presenter: Presenter: Presenter: Tom Leyden Omri Geller Gil Vitzinger William Benton VP Marketing CEO & Co-Founder Software Developer Engineering Manager Kubernetes for AI Workloads Omri Geller, CEO and co-founder, Run:AI A Bit of History Needed flexibility Reproducibility and and better utilization portability Bare Metal Virtual Machines Containers Containers scale easily, they’re lightweight and efficient, they can run any workload, are flexible and can be isolated …But they need orchestration 2 Enter Kubernetes Track, Create Efficient Execute Across Schedule and Cluster Different Operationalize Utilization Hardware 3 Today, 60% of Those Who Deploy Containers Use K8s for Orchestration* *CNCF 4 Now let’s talk about AI Computing Power Fuels Development of AI Deep Learning Classical Machine Learning Manual Engineering 6 Artificial Intelligence is a Completely Different Ballgame New Distributed Experimentation accelerators computing R&D 7 Data Science Workflows and Hardware Accelerators are Highly Coupled Data Hardware scientists accelerators Constant Workflow Under-utilized hassles Limitations GPUs 8 This Leads to Frustration on Both Sides Data Scientists are IT leaders are frustrated – speed and frustrated – GPU productivity are low utilization is low 9 AI Workloads are Also Built on Containers NGC – Nvidia pre-trained models for -

CNCF Webinar Taming Your AI/ML Workloads with Kubeflow
CNCF Webinar Taming Your AI/ML Workloads with Kubeflow The Journey to Version 1.0 David Aronchick (Microsoft) - @aronchick Elvira Dzhuraeva (Cisco) - @elvirafortune Johnu George (Cisco) - @johnugeorge SNARC Maze Solver Minsky / Edmonds (1951) 2000 3 2006 4 2007 5 2008 6 2010 7 2013 8 2014 9 2015 10 Today 11 One More ML ???Solution??? 12 One More ML ???Solution??? 13 14 GitHub Natural Language Search Prototype MVP With Demo In Jupyter Demo with front-end mockup with Experiments.Github.Com: +3 Months Notebook: 2 Weeks blog post: +3 Days https://github.com/hamelsmu/code_search https://towardsdatascience.com/semantic-code-se https://experiments.github.com/ arch-3cd6d244a39c 15 Resource Provisioning Numpy Scheduling Experiment Tracking Jupyter Access Control Declarative Deployment TF.Transform Drivers HP Tuning TF.Estimator Orchestration Profiling Docker Lifecycle Management Validation Seldon Networking KubeCon 2017 17 Resource Provisioning Numpy Scheduling Experiment Tracking Jupyter Access Control Declarative Deployment TF.Transform Drivers HP Tuning TF.Estimator Orchestration Profiling Docker Lifecycle Management Validation Seldon Networking Mission (2017) Make it Easy for Everyone to Develop, Deploy and Manage Portable, Distributed ML on Kubernetes 20 Kubeflow 2018 Mission (2018) Make it Easy for Everyone to Develop, Deploy and Manage Portable, Distributed ML on Kubernetes 23 Kubeflow 2019 Mission (2019) Make it Easy for Everyone to Develop, Deploy and Manage Portable, Distributed ML on Kubernetes 26 Mission (2020) Make it Easy for Everyone -

The Evolution to Cloud-Native Nfv: Early Adoption Brings Benefits with a Flexible Approach
THE EVOLUTION TO CLOUD-NATIVE NFV: EARLY ADOPTION BRINGS BENEFITS WITH A FLEXIBLE APPROACH NOVEMBER 2017 Caroline Chappell Ref: 2011421-463 analysysmason.com The evolution to cloud-native NFV: Early adoption brings benefits with a flexible approach | i Contents 1. Executive summary 1 2. What is cloud-native network virtualisation? 2 Drivers for the cloud-native network 2 The IT cloud community has pioneered cloud-native computing 3 Telco industry progress towards cloud-native NFV 4 Cloud native is an urgent goal, but most vendors are moving slowly towards it 5 3. Key principles of cloud-native computing in a telco context 6 CSPs should evaluate VNFs from three perspectives to ensure they are future-proofed for cloud-native computing 6 Designing VNFs for the cloud 7 Cloud-native deployment of VNFs 8 Cloud-native automation and management of VNFs 9 4. Cloud-native network use cases and migration strategy 11 When should cloud-native computing be applied? 11 Applying cloud-native computing: mitigating organisational and operational impacts 11 5. Huawei’s cloud-native core network solutions 12 6. Conclusion 13 About the author 15 About Analysys Mason 16 Research from Analysys Mason 17 Consulting from Analysys Mason 18 List of figures Figure 2.1: Drivers for applying cloud-native computing to the network ........................................................ 2 Figure 2.2: The evolution of cloud-native computing in the IT industry .......................................................... 3 Figure 2.3: How containers differ from virtual machines ................................................................................. 4 Figure 2.4: Progress towards cloud-native VNFs ............................................................................................. 6 Figure 3.1: Vertical and horizontal decomposition of VNFs ............................................................................ 8 Figure 3.2: Deployment options in different NFV data centres ....................................................................... -
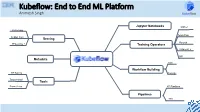
Kubeflow: End to End ML Platform Animesh Singh
Kubeflow: End to End ML Platform Animesh Singh Jupyter Notebooks MXNet KFServing Tensorflow Seldon Core Serving Pytorch TFServing, + Training Operators XGBoost, + MPI Metadata Kale Workflow Building HP Tuning Fairing Tensorboard Tools Prometheus KF Pipelines Pipelines TFX Your Speaker Today: CODAIT 2 Animesh Singh Kubeflow STSM and Chief Architect - Data and AI Open Source github.com/kubeflow Platform o CTO, IBM RedHat Data and AI Open Source Alignment o IBM Kubeflow Engagement Lead, Kubeflow Committer o Chair, Linux Foundation AI - Trusted AI o Chair, CD Foundation MLOps Sig o Ambassador, CNCF o Member of IBM Academy of Technology (IBM AoT) © 2019 IBM Corporation Kubeflow: Current IBM Contributors Untrained Model Christian Kadner Weiqiang Zhuang Tommy Li Andrew Butler Prepared Preparedand Trained AnalyzedData Model Data Deployed Model Jin Chi He Feng Li Ke Zhu Kevin Yu IBM is the 2nd Largest Contributor IBM is the 2nd Largest Contributor IBMers contributing across projects in Kubeflow Kubeflow Services kubectl apply -f tfjob High Level Kubernetes API Server Services Notebooks Low Level APIs / Services Pipelines TFJob PyTorchJob Pipelines CR KFServing Argo Jupyter CR MPIJob Katib Seldon CR Study Job Spark Job Istio Mesh and Gateway Kubebench TFX Developed By Kubeflow Developed Outside Kubeflow Adapted from Kubeflow Contributor Summit 2019 talk: Kubeflow and ML Landscape (Not all components are shown) Community is growing! 8 Multi-User Isolation ML Lifecycle: Build: Development, Training and HPO Untrained Model Prepared Preparedand Trained -

State of Cloud Native Development Q4-2019
THE LATEST TRENDS FROM OUR Q4 2019 SURVEY OF 17,000+ DEVELOPERS Supported by TO BE PUBLISHED AUGUST 2020 We help the world understand developers We survey 40,000+ developers annually – across web, mobile, IoT, cloud, Machine Learning, AR/VR, games and desktop – to help companies understand who developers are, what they buy and where they are going next. WHO DEVELOPERS ARE WHAT THEY BUY WHERE THEY ARE GOING Developer population sizing Why developers are adopting Emerging platforms – augmented & Developer segmentation competitor products – and how you virtual reality, machine learning can fix that Trusted by the leading tech brands and media TABLE OF CONTENTS Key findings 1. Introduction A. Defining cloud native computing B. Market size C. Usage of cloud native technologies across regions 2. Where are cloud native developers running their code? A. Infrastructure usage by cloud native developers and non-cloud native developers B. Cloud native developers and their infrastructure usage by verticals 3. Usage of cloud service vendors A. Usage of cloud service vendors by cloud native, non-cloud native, and other developers B. Private cloud usage by cloud native and non-cloud native developers 4. Awareness and use of Kubernetes A. Kubernetes and containers: usage and awareness among backend developers B. Overlap of Kubernetes and CaaS users C. Solutions used by developers not indicating they use Kubernetes 5. Serverless usage and awareness A. Usage and awareness of serverless solutions B. Usage of serverless solutions by role Methodology License terms KEY INSIGHTS FOR THE CLOUD NATIVE COMPUTING FOUNDATION THE STATE OF CLOUD NATIVE DEVELOPMENT Q4 2019 4 KEY FINDINGS • 6.5 million cloud native developers exist around the globe, 1.8 million more than in Q2 2019. -

HBSAAL Newsletter December 2019
HBSAAL Newsletter December 2019 INTRODUCTION Dear Friends and Members, It is my pleasure to share with you the first HBS Alumni Angels of London (HBSAAL) newsletter. With over 5,000 alumni in London we play an important role in helping foster an increasingly vibrant and economically important start-up ecosystem. Our local Alumni chapter was launched in 2011, and in that time our members have made investments totalling £7.2M (excluding secondary investments) in over 40 companies. We all know that angel investing requires patience and a portfolio mindset, so we are delighted with notable exits such as Stupeflix and DogBuddy along with significant up-rounds from recent investments such as FlatFair, Seldon, Urban and Pavegen. This past July five companies that received investment from our members were shortlisted for the UK British Angel Association (UKBAA) awards. HBS alum Romi Savova of PensionBee won Best High Growth Woman Founder. Our investors bring more than just cash they also bring a strong network and valuable business experience. We are all committed to life-long learning and our educational events have covered topics ranging from thematic investing in artificial intelligence and fintech to practical tips on angel investing. We had a successful pitch event on Nov 19th, and on Nov 27th we hosted a panel discussion with some of the most successful angel investors in the UK. This was hosted at McKinsey & Co’s new UK headquarters. We will also shortly be introducing you to the wider HBS Alumni Global organisation where you can gain access to syndicated deals from HBSAA Chapters, such as New York, Silicon Valley, Beijing, Paris and Brazil along with access to global educational webinars. -

(PDF) What Can Cloud Native Do for Csps?
What Can Cloud Native Do for CSPs? Cloud Native Can Improve…. Development Cloud native is a way of approaching the development and deployment of applications in such a way that takes account of the characteristics and nature of the cloud—resulting in processes and workflows that fully take advantage of the platform. Operations Cloud native is an approach to building and running software applications that exploits the advantages of the cloud computing delivery model. Cloud-native is about how applications are created and deployed, not where. Infrastructure Cloud native platforms available “as a service” in the cloud can accommodate hybrid and multi-cloud environments. What are Cloud Native Core Concepts? Continuous Integration DevSecOps Microservices Containers and Deployment Not My Problem Release Once Every Tightly Coupled Directly Ported to a VM Separate tools, varied 6 Months Components Monolithic application incentives, opaque process More bugs in production Slow deployment cycles unable to leverage modern waiting on integrated tests cloud tools teams Shared Responsibility Release Early Loosely Coupled Packaged for Containers Common incentives, tools, and Often Components Focus on business process and culture Higher quality of code Automated deploy without software by leveraging waiting on individual the platform ecosystem components What are the Benefits of Cloud Native? Business Optimization Microservices architecture enables flexibility, agility, and reuse across various platforms. CAPEX and OPEX Reduction Service-based architecture allows integration with the public Cloud to handle overload capacity, offer new services with less development, and take advantage of other 3rd party services such as analytics, machine learning, and artificial intelligence. Service Agility Common services can be shared by all network functions deployed on the Cloud-Native Environment (CNE). -

Build an Event Driven Machine Learning Pipeline on Kubernetes
Assign Hyperparameters Initial Model and Train Create Model PreparedPrepared andand Trained AnalyzedAnalyzed Model DataData Monitor DeployedDeployed Validate and Deploy ModelModel Build an Event Driven Machine Learning Pipeline on Kubernetes Yasushi Osonoi Animesh Singh Developer Advocate IBM STSM, IBM kubeflow kfserving maintainer osonoi animeshsingh Center for Open Source Improving Enterprise AI lifecycle in Open Source Data and AI Technologies (CODAIT) Code – Build and improve practical frameworks to enable more developers to realize immediate value. Content – Showcase solutions for complex and real-world AI problems. Community – Bring developers and data scientists to engage with IBM • Team contributes to over 10 open source projects • 17 committers and many contributors in Apache projects • Over 1100 JIRAs and 66,000 lines of code committed to Apache Spark itself; over 65,000 LoC into SystemML • Over 25 product lines within IBM leveraging Apache Spark • Speakers at over 100 conferences, meetups, unconferences and more CODAIT codait.org 3 DEVELOPER ADVOCATE in TOKYO Tokyo Team is a part of Worldwide Developer Advocate Teams! Developer Advocate City Leader WW Developer Advocate WW Developer Advocate Client Developer Advocate AKIRA ONISHI NORIKO KATO KYOKO NISHITO YASUSHI OSONOI Program Manager WW Developer Advocate WW Developer Advocate Digital Developer Advocate TOSHIO YAMASHITA TAIJI HAGINO AYA TOKURA JUNKI SAGAWA @taiponrock https://developer.ibm.com/patterns/ https://developer.ibm.com/jp/ Please follow me @osonoi IBM’s history -

The AI Growth Capital of Europe 2 London: the AI Growth Capital of Europe London: the AI Growth Capital of Europe 3
London: The AI Growth Capital of Europe 2 London: The AI Growth Capital of Europe London: The AI Growth Capital of Europe 3 About CognitionX CognitionX is the AI advice platform that connects every organisation with a global on-demand network of AI experts. The platform allows experts in AI from around the world to share invaluable expertise with organisations of any size and sector who want to tap into that knowledge. Through the platform, organisations can find an answer to their AI question very quickly, regardless of where they are. AI experts can either share knowledge for free or charge a fee. Founded in 2015, CognitionX’s mission is to drive innovation in, and deployment of, AI by making expertise universally accessible, levelling the playing field for the millions of organisations who don’t have access to strategy consultants or advisory boards, while also giving AI experts a new outlet for, and a way to monetise, their expertise. CognitionX.com Report authors Stephen Allott James Kingston Mick Endsor Matthew Miller Tabitha Goldstaub Milan Sachania Ed Janvrin 4 London: The AI Growth Capital of Europe London: The AI Growth Capital of Europe 5 Mayor’s Foreword There are few areas of innovation that have the power to define our future economy and society more than artificial intelligence. As Mayor of London, it is my goal to ensure both that London is at the forefront of developing and capitalising on these new technologies, and that all Londoners can benefit from the opportunities they will create. I commissioned CognitionX to undertake this research in order to discover the facts behind what many already know to be true - that London is the AI capital of Europe, and that our supportive and welcoming tech ecosystem is the best place to build and scale an AI company.