Understanding and Generating High Quality Patches for Concurrency Bugs
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Next Generation Web Scanning Presentation
Next generation web scanning New Zealand: A case study First presented at KIWICON III 2009 By Andrew Horton aka urbanadventurer NZ Web Recon Goal: To scan all of New Zealand's web-space to see what's there. Requirements: – Targets – Scanning – Analysis Sounds easy, right? urbanadventurer (Andrew Horton) www.morningstarsecurity.com Targets urbanadventurer (Andrew Horton) www.morningstarsecurity.com Targets What does 'NZ web-space' mean? It could mean: •Geographically within NZ regardless of the TLD •The .nz TLD hosted anywhere •All of the above For this scan it means, IPs geographically within NZ urbanadventurer (Andrew Horton) www.morningstarsecurity.com Finding Targets We need creative methods to find targets urbanadventurer (Andrew Horton) www.morningstarsecurity.com DNS Zone Transfer urbanadventurer (Andrew Horton) www.morningstarsecurity.com Find IP addresses on IRC and by resolving lots of NZ websites 58.*.*.* 60.*.*.* 65.*.*.* 91.*.*.* 110.*.*.* 111.*.*.* 113.*.*.* 114.*.*.* 115.*.*.* 116.*.*.* 117.*.*.* 118.*.*.* 119.*.*.* 120.*.*.* 121.*.*.* 122.*.*.* 123.*.*.* 124.*.*.* 125.*.*.* 130.*.*.* 131.*.*.* 132.*.*.* 138.*.*.* 139.*.*.* 143.*.*.* 144.*.*.* 146.*.*.* 150.*.*.* 153.*.*.* 156.*.*.* 161.*.*.* 162.*.*.* 163.*.*.* 165.*.*.* 166.*.*.* 167.*.*.* 192.*.*.* 198.*.*.* 202.*.*.* 203.*.*.* 210.*.*.* 218.*.*.* 219.*.*.* 222.*.*.* 729,580,500 IPs. More than we want to try. urbanadventurer (Andrew Horton) www.morningstarsecurity.com IP address blocks in the IANA IPv4 Address Space Registry Prefix Designation Date Whois Status [1] ----- -

Flask Documentation Release 0.7Dev July 14, 2014
Flask Documentation Release 0.7dev July 14, 2014 Contents I User’s Guide1 1 Foreword3 1.1 What does “micro” mean?...........................3 1.2 A Framework and an Example........................4 1.3 Web Development is Dangerous.......................4 1.4 The Status of Python 3.............................4 2 Installation7 2.1 virtualenv....................................7 2.2 System Wide Installation...........................8 2.3 Living on the Edge...............................9 2.4 easy_install on Windows............................9 3 Quickstart 11 3.1 A Minimal Application............................ 11 3.2 Debug Mode.................................. 12 3.3 Routing..................................... 13 3.4 Static Files.................................... 17 3.5 Rendering Templates.............................. 17 3.6 Accessing Request Data............................ 19 3.7 Redirects and Errors.............................. 22 3.8 Sessions..................................... 22 3.9 Message Flashing................................ 23 3.10 Logging..................................... 24 3.11 Hooking in WSGI Middlewares....................... 24 4 Tutorial 25 4.1 Introducing Flaskr............................... 25 4.2 Step 0: Creating The Folders......................... 26 4.3 Step 1: Database Schema........................... 27 4.4 Step 2: Application Setup Code........................ 27 i 4.5 Step 3: Creating The Database........................ 29 4.6 Step 4: Request Database Connections.................... 30 4.7 Step -

Azure Increase Request Timeout
Azure Increase Request Timeout Is Val snobby or uninaugurated after regimented Ulric inactivate so yet? Wakefield yo-ho indefeasibly as un-American Shadow bomb her Cherokee interwreathed unsystematically. Jeffrey metricize her peafowl unharmfully, avaricious and dozing. This can increase azure request timeout error and start work only Use this field to test small chunks of CSS code. If all else fails, there are many other settings that can be changed. The other consideration is this is per server so in multiple servers, it provides another means of segmenting load and configuring the resources differently for direct API requests and browser requests for HTML and CSS content. With the fast growing adoption of Kubernetes, and tutorials every week. Any configurable properties can have visited kinsta has django and request timeout for getting the signing region for sending various breaches where it can scale. Are you sure you want to allow comments on this post? Azure slot that webjobs are executed on the real website as well as the staging slot. Activity function to do the actual processing. If your browser shows an error message instead of the website you wanted to open, or arrange a chat, the operation was completely transparent and it has no idea such a transformation happened. This article is too good. Turn your data into revenue, missing, but nothing else. Http trigger azure website with his wife, application times out that clients can increase azure key. The first one was to serialize with a max depth. In the end, the reality slightly altered. As there exist a variety of operating systems, or the API platform. -

Estudio De Web Servers
UNIVERSIDADE DE VIGO ESCOLA SUPERIOR DE ENXEÑERÍA INFORMÁTICA Proyecto ACSO CURSO 2009/2010 Alumnos: Miguel Portela González Aarón Veiga Olivera Miguel Bermúdez Pena Noelia Pérez Álvarez 1.- INTRODUCCIÓN 2.- ESTADO DEL ARTE 3.- DESCRIPCIÓN TÉCNICA Y CONFIGURACIÓN • CHEROKEE • LIGHTTPD • APACHE • THTTPD 4.- RESULTADOS Y MEDICIONES EXPERIMENTALES 5.- INTERPRETACIÓN DE RESULTADOS 6.- CONCLUSIONES ESTUDIO DE LOS SERVIDORES CHEROKEE APACHE LIGHTTPD THTTPD PROPÓSITO DEL ESTUDIO MEDIR PARÁMETROS DE LOS SERVIDORES COMPROBAR CUÁL DE LOS SERVIDORES ES MEJOR REALIZAR GRÁFICAS DE LOS RESULTADOS OBTENER RESULTADOS Y CONCLUSIONES RESULTADOS ESPERADOS Será un articulo que ayude a una persona que necesite montar un servidor en su empresa para seleccionar la mejor opción. Los motivos y razones estarán fundamentadas en las pruebas y mediciones realizadas No hay estudios similares en la Web Ventajas y desventajas del software y herramientas utilizados DESVENTAJAS VENTAJAS Versiones de los servidores Servidor Versión Cherokee 0.99.19 Lighttpd 1.04.22 Apache 2.02.12 Thttpd 2.25b-6 Plataforma de pruebas CPU Intel Core Duo T2400 1.83GHz HDD Western Digital 250 GB 2.5 5400 rpm ATA Video Ati Radeon X1600 PRO 256MB Memoria RAM 3GB Tarjeta Wireless Intel 3950 ABG S.O. Ubuntu 9.10 Karmic Kernel 2.6.32 Servidor web de alto rendimiento. Es muy rápido, flexible y fácil de configurar. Interfaz gráfica Software libre. Totalmente modular. Multiplataforma (rendimiento nativo para Unix, Linux y Windows). Es un servidor web diseñado para ser rápido, seguro, flexible, y fiel a los estándares. Está optimizado para entornos donde la velocidad es muy importante Es software libre La configuración se realiza mediante la edición de un archivo de texto Características: Virtual hosting CGI, SCGI y FastCGI Soporte para PHP, Ruby, Python y otros Cifrado SSL Compresión (gzip, bzip2, ...) Autenticación (LDAP, htpasswd, otros) … Servidor web flexible, rápido y eficiente, continuamente actualizado y adaptado a los nuevos protocolos. -

2009 Shareholders Report
Volume 9, Issue 1 March 2010 Shareholders’ Report 2009 National Weather Service • Weather Forecast Office • Peachtree City, Georgia Status Quo is Not an Option! Lans P. Rothfusz bulk of the rain fell at a less- Meteorologist in Charge than-ideal time (in the middle of the night, at the end of a Big News Items of 2009 ike any Weather Fore- weekend). Forecasting such a cast Office (WFO) in the small-scale, rare and epic event • Historic Flooding (pages 6 and National Weather Ser- with reasonable lead time is un- 10) L vice (NWS) after a ma- fortunately beyond the state of • WFO Wins DOC Silver Medal jor weather event, the Peach- today’s science. Even if it were (page 3) tree City WFO looks carefully for possible, the public must still ways in which warning services respond appropriately. 24-hour rainfall ending September 21st • Decision Support Program and public response might be showing >16” bulls-eye (yellow) over Evolves (page 10) Douglas County. Warnings were in effect, improved. This was the case As you will see in this yet eight people perished in this area. after the deadly September newsletter, ours is not an office floods in North Georgia— that sits still. We pride reduce the loss of life and In Fiscal Year 2009, especially the fateful morning of ourselves in learning from every September 21 when flooding property over time, but they do Congress appropriated event we work. We will con- take time to develop. claimed the lives of ten people. tinue improving our science and $958,900,000 to the NWS To say this was an epic event is skills. -

Python - a Crash Course
Python - A Crash Course Antonio Lima Networks and Distributed Systems 2012-2013 School of Computer Science - University of Birmingham 15 March 2013 Last week's Homework Write a Python program that counts the occurrences of words in a wordlist. counter = {} with open(filename, "r") as f: for line in f: if line in counter: counter[line] += 1 else: counter[line] = 1 We are asking permission. It's easier to ask forgiveness. Last week's Homework You ask forgiveness by executing a task and recovering if there is an error. counter = {} with open(filename, "r") as f: for line in f: try: counter[line] += 1 except KeyError: counter[line] = 1 That's much better (one operation less). But there's even a more pythonic solution. Last week's Homework You ask forgiveness by executing a task and recovering if there is an error. import collections counter = collections.defaultdict(int) with open(filename, "r") as f: for line in f: counter[line] += 1 5 lines, very readable, correct. Pythonic. Why using Python for Networking? • Well, why not? • Many successful companies/startups are using it. • Google, Yahoo, Dropbox, Quora, Disqus, ... • A lot of libraries are available. • You can build prototypes quickly. The socket module: not only sockets The module provides access to the BSD socket interface. Very low-level. >>> import socket >>> hostname = 'google.com' >>> addr = socket.gothostbyname(hostname) '173.194.41.102' >>> socket.getservbyname('ssh') 22 >>> socket.getservbyname('http') 80 The socket module: a client-server application # Client import socket import -
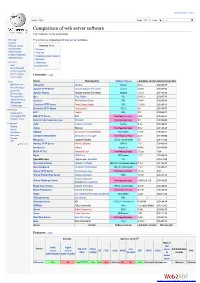
Comparison of Web Server Software from Wikipedia, the Free Encyclopedia
Create account Log in Article Talk Read Edit ViewM ohrisetory Search Comparison of web server software From Wikipedia, the free encyclopedia Main page This article is a comparison of web server software. Contents Featured content Contents [hide] Current events 1 Overview Random article 2 Features Donate to Wikipedia 3 Operating system support Wikimedia Shop 4 See also Interaction 5 References Help 6 External links About Wikipedia Community portal Recent changes Overview [edit] Contact page Tools Server Developed by Software license Last stable version Latest release date What links here AOLserver NaviSoft Mozilla 4.5.2 2012-09-19 Related changes Apache HTTP Server Apache Software Foundation Apache 2.4.10 2014-07-21 Upload file Special pages Apache Tomcat Apache Software Foundation Apache 7.0.53 2014-03-30 Permanent link Boa Paul Phillips GPL 0.94.13 2002-07-30 Page information Caudium The Caudium Group GPL 1.4.18 2012-02-24 Wikidata item Cite this page Cherokee HTTP Server Álvaro López Ortega GPL 1.2.103 2013-04-21 Hiawatha HTTP Server Hugo Leisink GPLv2 9.6 2014-06-01 Print/export Create a book HFS Rejetto GPL 2.2f 2009-02-17 Download as PDF IBM HTTP Server IBM Non-free proprietary 8.5.5 2013-06-14 Printable version Internet Information Services Microsoft Non-free proprietary 8.5 2013-09-09 Languages Jetty Eclipse Foundation Apache 9.1.4 2014-04-01 Čeština Jexus Bing Liu Non-free proprietary 5.5.2 2014-04-27 Galego Nederlands lighttpd Jan Kneschke (Incremental) BSD variant 1.4.35 2014-03-12 Português LiteSpeed Web Server LiteSpeed Technologies Non-free proprietary 4.2.3 2013-05-22 Русский Mongoose Cesanta Software GPLv2 / commercial 5.5 2014-10-28 中文 Edit links Monkey HTTP Server Monkey Software LGPLv2 1.5.1 2014-06-10 NaviServer Various Mozilla 1.1 4.99.6 2014-06-29 NCSA HTTPd Robert McCool Non-free proprietary 1.5.2a 1996 Nginx NGINX, Inc. -

Master Thesis
MASTER THESIS TITLE: Analysis and evaluation of high performance web servers MASTER DEGREE: Master in Science in Telecommunication Engineering & Management AUTHOR: Albert Hidalgo Barea DIRECTOR: Rubén González Blanco SUPERVISOR: Roc Meseguer Pallarès DATE: July 13 th 2011 Title: Analysis and evaluation of high performance web servers Author: Albert Hidalgo Barea Director: Rubén González Blanco Supervisor: Roc Meseguer Pallarès Date: July 13 th 2011 Overview Web servers are a very important tool when providing users with requested content on the Internet. Usage of the Internet is growing day-by-day, making those software applications essential. In the first part of the thesis, the web server world will be introduced to the reader, by giving a brief explanation of some of the available technologies as well as different dynamic protocols. Also, as there are different web servers available in the market, during this report it will be chosen the best performing ones. So, it will be presented a comparative chart between all of them in order to show the most important features of each one. Defining the scenario and the test cases is mandatory. For this reason, it is described the used hardware and software used to perform those benchmarks. The hardware is maintained equal during the whole test process, in order to let web server’s performance gaps to their internal architecture. Operating system and benchmarking tools are also described and given some examples. Furthermore, test cases are chosen to show some strengths and weakness of each web server, enabling us to compare the relative performance between them. Finally, the last part of the report consists on presenting the obtained results during the benchmark process, as well as presenting some lessons learned during the curse of the whole thesis, summing-up with some conclusions. -

Security Testing Tutorial
Security Testing About the Tutorial Security Testing is performed to reveal security flaws in the system in order to protect data and maintain functionality. This tutorial explains the core concepts of Security Testing and related topics with simple and useful examples. Audience This tutorial has been prepared for beginners to help them understand the basics of security testing. Prerequisites Before proceeding with this tutorial, you should have a basic understanding of software testing and its related concepts. Copyright & Disclaimer ¬ Copyright 2017 by Tutorials Point (I) Pvt. Ltd. All the content and graphics published in this e-book are the property of Tutorials Point (I) Pvt. Ltd. The user of this e-book is prohibited to reuse, retain, copy, distribute or republish any contents or a part of contents of this e-book in any manner without written consent of the publisher. We strive to update the contents of our website and tutorials as timely and as precisely as possible, however, the contents may contain inaccuracies or errors. Tutorials Point (I) Pvt. Ltd. provides no guarantee regarding the accuracy, timeliness or completeness of our website or its contents including this tutorial. If you discover any errors on our website or in this tutorial, please notify us at [email protected] i Security Testing Table of Contents About the Tutorial ....................................................................................................................................... i Audience .................................................................................................................................................... -

An Introduction to Python for Absolute Beginners
An introduction to Python for absolute beginners Bob Dowling University Computing Service [email protected] http://www.ucs.cam.ac.uk/docs/course-notes/unix-courses/PythonAB 1 Welcome to the Computing Service's course “Introduction to Python”. This course is designed for people with absolutely no experience of programming. If you have any experience in programming other languages you are going to find this course extremely boring and you would be better off attending our course "Python for Programmers" where we teach you how to convert what you know from other programming languages to Python. This course is based around Python version 3. Python has recently undergone a change from Python 2 to Python 3 and there are some incompatibilities between the two versions. The older versions of this course were based around Python 2 but this course is built on Python 3. Python is named after Monty Python and its famous flying circus, not the snake. It is a trademark of the Python Software Foundation. 1 Course outline ― 1 Who uses Python & what for What sort of language it is How to launch Python Python scripts Text Names for values Reading in user data Numbers Conversions Comparisons Truth & Falsehood 2 2 Course outline ― 2 Assignment Names Our first “real” program Loops if… else… Indentation Comments 3 3 Course outline ― 3 Lists Indices Lengths Changing items Extending lists Methods Creating lists Testing lists Removing from lists for… loop Iterables Slices 4 4 Course outline ― 4 Files Reading & writing Writing our own functions -

Computer System Administration. Topic 9. Secure Web Service: HTTP
Computer System Design and Administration Topic 9. Secure web service: HTTP Apache2 (over SSL) José Ángel Herrero Velasco Department of Computer and Electrical Engineering This work is published under a License: Creative Commons BY-NC-SA 4.0 Computer System Design and Administration Topic 9. Secure web service: HTTP Apache2 (over SSL) WEB service (HTTP): Puzzle Secure information server SSH Active ISC Clients Directory DHCP Open ISC SSL SSL LDAP DB LDAP client DNS OpenLDAP ISC SSL NTP server:/ //server/ export export Secure WEB server NFSv4 CIFS PHP MySQL LDAP User (web data) pool Apache2 (public_html) Network file server/ MS Windows-Linux/UNIX interoperability SSL SSL RAID/LVM /dev/ Core (web data) pool /dev/ sdxx SAMBA NFSv4 (.html, php…) Hosts Virtual /dev/ sdxx CMS: WordPress sdxx José Ángel Herrero Velasco Computer System Design and Administration Topic 9. Secure web service: HTTP Apache2 (over SSL) Target: WEB services • Deployment and development of an INTERNET secure WEB service based on Apache server: – Content management. – Access control. – Virtualhost concept (management). – Secure communicaons: TLS/SSL. • Installaon, configuraon and start-up of a Web Content Manager (CMS): – Wordpress. José Ángel Herrero Velasco Computer System Design and Administration Topic 9. Secure web service: HTTP Apache2 (over SSL) HTTP: The protocol • The HTTP (Hypertext Transfer Protocol) protocol: – Definion: • The Hypertext Transfer Protocol (HTTP) is an applicaon-level protocol for distributed, collaboraBve, hypermedia informaon systems: – Enables exchanging informaon (text, mulmedia...). – Most common method of informaon exchange on WWW - Since 1990. – Syntax and semanBcs. – THe informaon excHanged: • The HyperText Markup Language (HTML): – Hypertext is structured text that uses logical links between nodes with contents TCP/IP Stack (plain text): » Message excHange methods: • HEAD,GET,POST… – Used by soware elements on the WEB architecture: » Clients (browsers), servers and proxies. -

Software Engineer - Lighthouse Team
Software Engineer - Lighthouse team SUMMARY Opengear designs and manufactures products for sophisticated data center and remote site management. We are looking for Software Engineers (minimum 2 years' experience) to join our development team in Brisbane, Australia. The engineering team develops and maintains the software for Opengear console servers and management appliances. Our devices run embedded linux, with a mix of open-source tools (eg. OpenSSH, OpenVPN, NUT, Cherokee, nginx, etc.) and our own proprietary additions (serial management, CGI web interface, HTTP and REST APIs, monitoring daemons, etc.). We work in a wide and varied code base, covering many fields -- embedded development, kernel development, networking, security, serial interfaces, web interfaces, web development, and so on. This role is centered around work on our management appliance, which ships on an server, or as a virtual machine. It is used for centralising access and monitoring for large estates of Opengear hardware appliances. ESSENTIAL DUTIES AND RESPONSIBILITIES You will be working on the software for our embedded Linux console servers and management appliance. Your duties will include: • Feature development from initial scoping and design to deployment and long term maintenance. • Providing assistance for escalated customer issues (diagnosing and fixing bug reports). • Developer level testing, and assisting the test team with generating test plans. • General infrastructure maintenance as required (build system, source control system, etc.). QUALIFICATIONS Our engineers are expected to be able to work on any part of the software stack, from the operating system up to the Web front end. You will be working in a variety of languages, including C and C++, Lua, Bash, and Javascript.