Statistical Inference for Dynamical Systems: a Review Kevin Mcgoff, Sayan Mukherjee, Natesh S
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
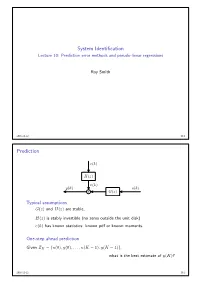
Prediction Error Methods and Pseudo-Linear Regressions
System Identification Lecture 10: Prediction error methods and pseudo-linear regressions Roy Smith 2016-11-22 10.1 Prediction e k p q H z p q v k y k p q u k p q G z p q ` p q Typical assumptions G z and H z are stable, p q p q H z is stably invertible (no zeros outside the unit disk) p q e k has known statistics: known pdf or known moments. p q One-step ahead prediction Given ZK u 0 , y 0 , . , u K 1 , y K 1 , “ t p q p q p ´ q p ´ qu what is the best estimate of y K ? p q 2016-11-22 10.2 Prediction v k e k p q H z p q p q Noise model invertibility Given, v k , k 0,...,K 1, can we determine e k , k 0,...,K 1? p q “ ´ p q “ ´ 8 Inverse filter: Hinv z : e k hinv i v k i p q p q “ i 0 p q p ´ q ÿ“ We also want the inverse filter to be causal and stable: 8 hinv k 0, k 0, and hinv k . p q “ ă k 0 | p q| ă 8 ÿ“ If H z has no zeros for z 1, then, p q | | ě 1 Hinv z . p q “ H z p q 2016-11-22 10.3 Prediction v k e k p q H z p q p q One step ahead prediction Given measurements of v k , k 0,...,K 1, can we predict v K ? p q “ ´ p q Assume that we know H z , how much can we say about v K ? p q p q Assume also that H z is monic (h 0 1). -

BERNOULLI NEWS, Vol 24 No 1 (2017)
Vol. 24 (1), May 2017 Published twice per year by the Bernoulli Society ISSN 1360–6727 CONTENTS News from the Bernoulli Society p. 1 Awards and Prizes p. 2 New Executive Members A VIEW FROM THE PRESIDENT in the Bernoulli Society Dear Members of the Bernoulli Society, p. 3 As we all seem to agree, the role and image of statistics has changed dramatically. Still, it takes ones breath when realizing the huge challenges ahead. Articles and Letters Statistics has not always been considered as being very necessary. In 1848 the Dutch On Bayesian Measures of Ministry of Home Affairs established an ofŮice of statistics. And then, thirty years later Uncertainty in Large or InŮinite minister Kappeyne van de Coppelo abolishes the “superŮluous” ofŮice. The ofŮice was Dimensional Models p. 4 quite rightly put back in place in 1899, as “Centraal Bureau voor de Statistiek” (CBS). Statistics at the CBS has evolved from “simple” counting to an art requiring a broad range On the Probability of Co-primality of competences. Of course counting remains important. For example the CBS reports in of two Natural Numbers Chosen February 2017 that almost 1 out of 4 people entitled to vote in the Netherlands is over the at Random p. 7 age of 65. But clearly, knowing this generates questions. What is the inŮluence of this on the outcome of the elections? This calls for more data. Demographic data are combined with survey data and nowadays also with data from other sources, in part to release the “survey pressure” that Ůirms and individuals are facing. -

10. Prediction Error Methods (PEM)
EE531 - System Identification Jitkomut Songsiri 6. Prediction Error Methods (PEM) • description • optimal prediction • examples • statistical results • computational aspects 6-1 Description idea: determine the model parameter θ such that "(t; θ) = y(t) − y^(tjt − 1; θ) is small y^(tjt − 1; θ) is a prediction of y(t) given the data up to time t − 1 and based on θ general linear predictor: y^(tjt − 1; θ) = N(L; θ)y(t) + M(L; θ)u(t) where M and N must contain one pure delay, i.e., N(0; θ) = 0;M(0; θ) = 0 example: y^(tjt − 1; θ) = 0:5y(t − 1) + 0:1y(t − 2) + 2u(t − 1) Prediction Error Methods (PEM) 6-2 Elements of PEM one has to make the following choices, in order to define the method • model structure: the parametrization of G(L; θ);H(L; θ) and Λ(θ) as a function of θ • predictor: the choice of filters N; M once the model is specified • criterion: define a scalar-valued function of "(t; θ) that will assess the performance of the predictor we commonly consider the optimal mean square predictor the filters N and M are chosen such that the prediction error has small variance Prediction Error Methods (PEM) 6-3 Loss function let N be the number of data points sample covariance matrix: 1 XN R(θ) = "(t; θ)"T (t; θ) N t=1 R(θ) is a positive semidefinite matrix (and typically pdf when N is large) loss function: scalar-valued function defined on positive matrices R f(R(θ)) f must be monotonically increasing, i.e., let X ≻ 0 and for any ∆X ⪰ 0 f(X + ∆X) ≥ f(X) Prediction Error Methods (PEM) 6-4 Example 1 f(X) = tr(WX) where W ≻ 0 is a weighting matrix f(X + ∆X) = tr(WX) + tr(W ∆X) ≥ f(X) (tr(W ∆X) ≥ 0 because if A ⪰ 0;B ⪰ 0, then tr(AB) ≥ 0) Example 2 f(X) = det X f(X + ∆X) − f(X) = det(X1/2(I + X−1/2∆XX−1/2)X1/2) − det X = det X[det(I + X−1/2∆XX−1/2) − 1] " # Yn −1/2 −1/2 = det X (1 + λk(X ∆XX )) − 1 ≥ 0 k=1 −1/2 −1/2 the last inequalty follows from X ∆XX ⪰ 0, so λk ≥ 0 for all k both examples satisfy f(X + ∆X) = f(X) () ∆X = 0 Prediction Error Methods (PEM) 6-5 Procedures in PEM 1. -

5 Identification Using Prediction Error Methods
5 Identification using Prediction Error Methods The previous chapters have shown how the dynamic behaviour of a civil engineering structure can be modelled by a discrete-time ARMAV model or an equivalent stochastic state space realization. The purpose of this chapter is to investigate how an estimate of a p-variate discrete-time model can be obtained from measurements of the response y(tkk). It is assumed that y(t ) is a realization of a Gaussian stochastic process and thus assumed stationary. The stationarity assumption implies that the behaviour of the underlying system can be represented by a time-invariant model. In the following, the general ARMAV(na,nc), for na nc, model will be addressed. In chapter 2, it was shown that this model can be equivalently represented by an m- dimensional state space realization of the innovation form, with m na#p. No matter how the discrete-time model is represented, all adjustable parameters of the model are assembled in a parameter vector , implying that the transfer function description of the discrete-time model becomes y(tk ) H(q, )e(tk ), k 1, 2, ... , N (5.1) T E e(tk )e (tks ) ( ) (s) The dimension of the vectors y(tkk) and e(t ) are p × 1. Since there is no unique way of computing an estimate of (5.1), it is necessary to select an appropriate approach that balances between the required accuracy and computational effort. The approach used in this thesis is known as the Prediction Error Method (PEM), see Ljung [71]. The reason for this choice is that the PEM for Gaussian distributed prediction errors is asymptotic unbiased and efficient. -

Wavelet Analysis for System Identification∗
Wavelet analysis for system identification∗ 大阪教育大学・数理科学 芦野 隆一 (Ryuichi Ashino) Mathematical Sciences, Osaka Kyoiku University 大阪電気通信大学・数理科学研究センター 萬代 武史 (Takeshi Mandai) Research Center for Physics and Mathematics, Osaka Electro-Communication University 大阪教育大学・情報科学 守本 晃 (Akira Morimoto) Information Science, Osaka Kyoiku University Abstract By the Schwartz kernel theorem, to every continuous linear sys- tem there corresponds a unique distribution, called kernel distribution. Formulae using wavelet transform to access time-frequency informa- tion of kernel distributions are deduced. A new wavelet based system identification method for health monitoring systems is proposed as an application of a discretized formula. 1 System Identification A system L illustrated in Figure 1 is an object in which variables of different kinds interact and produce observable signals. The observable signals g that are of interest to us are called outputs. The system is also affected by external stimuli. External signals f that can be manipulated by the observer are called inputs. Others are called disturbances and can be divided into those, denoted by w, that are directly measured, and those, denoted by v, that are only observed through their influence on the output. Mathematically, a system can be regarded as a mapping which relates inputs to outputs. Hereafter, we will use the terminology “system” rather ∗This research was partially supported by the Japanese Ministry of Education, Culture, Sports, Science and Technology, Grant-in-Aid for Scientific Research (C), 15540170 (2003– 2004), and by the Japan Society for the Promotion of Science, Japan-U.S. Cooperative Science Program (2003–2004). 1 Unmeasured Measured disturbance v disturbance w System L Output g Input f Figure 1: System L. -

Localization and System Identification of a Quadcopter AU V
Western Michigan University ScholarWorks at WMU Master's Theses Graduate College 6-2014 Localization and System Identification of a Quadcopter AU V Kenneth Befus Follow this and additional works at: https://scholarworks.wmich.edu/masters_theses Part of the Aeronautical Vehicles Commons, Navigation, Guidance, Control and Dynamics Commons, and the Propulsion and Power Commons Recommended Citation Befus, Kenneth, "Localization and System Identification of a Quadcopter AU V" (2014). Master's Theses. 499. https://scholarworks.wmich.edu/masters_theses/499 This Masters Thesis-Open Access is brought to you for free and open access by the Graduate College at ScholarWorks at WMU. It has been accepted for inclusion in Master's Theses by an authorized administrator of ScholarWorks at WMU. For more information, please contact [email protected]. LOCALIZATION AND SYSTEM IDENTIFICATION OF A QUADCOPTER UAV by Kenneth Befus A thesis submitted to the Graduate College in partial fulfillment of the requirements for the degree of Master of Science in Engineering Department of Mechanical and Aeronautical Engineering Western Michigan University June 2014 Doctoral Committee: Kapseong Ro, Ph.D., Chair Koorosh Naghshineh, Ph.D. James W. Kamman, Ph.D. LOCALIZATION AND SYSTEM IDENTIFICATION OF A QUADCOPTER UAV Kenneth Befus, M.S.E. Western Michigan University, 2014 The research conducted explores the comparison of several trilateration algorithms as they apply to the localization of a quadcopter micro air vehicle (MAV). A localization system is developed employing a network of combined ultrasonic/radio frequency sensors used to wirelessly provide range (distance) measurements defining the location of the quadcopter in 3-dimensional space. A Monte Carlo simulation is conducted using the extrinsic parameters of the localization system to evaluate the adequacy of each trilateration method as it applies to this specific quadcopter application. -

Sequential Monte Carlo Methods for System Identification (A Talk About
Sequential Monte Carlo methods for system identification (a talk about strategies) \The particle filter provides a systematic way of exploring the state space" Thomas Sch¨on Division of Systems and Control Department of Information Technology Uppsala University. Email: [email protected], www: user.it.uu.se/~thosc112 Joint work with: Fredrik Lindsten (University of Cambridge), Johan Dahlin (Link¨opingUniversity), Johan W˚agberg (Uppsala University), Christian A. Naesseth (Link¨opingUniversity), Andreas Svensson (Uppsala University), and Liang Dai (Uppsala University). [email protected] IFAC Symposium on System Identification (SYSID), Beijing, China, October 20, 2015. Introduction A state space model (SSM) consists of a Markov process x ≥ f tgt 1 that is indirectly observed via a measurement process y ≥ , f tgt 1 x x f (x x ; u ); x = a (x ; u ) + v ; t+1 j t ∼ θ t+1 j t t t+1 θ t t θ;t y x g (y x ; u ); y = c (x ; u ) + e ; t j t ∼ θ t j t t t θ t t θ;t x µ (x ); x µ (x ); 1 ∼ θ 1 1 ∼ θ 1 (θ π(θ)): (θ π(θ)): ∼ ∼ Identifying the nonlinear SSM: Find θ based on y y ; y ; : : : ; y (and u ). Hence, the off-line problem. 1:T , f 1 2 T g 1:T One of the key challenges: The states x1:T are unknown. Aim of the talk: Reveal the structure of the system identification problem arising in nonlinear SSMs and highlight where SMC is used. 1 / 14 [email protected] IFAC Symposium on System Identification (SYSID), Beijing, China, October 20, 2015. -

What Is System Identification
What is System identification Using experimental data obtained from input/output relations to model dynamic systems. disturbances input output System Different approaches to system identification depending on model class Linear/Non-linear Parametric/Non-parametric ¾Non-parametric methods try to estimate a generic model. (step responses, impulse responses, frequency responses) ¾Parametric methods estimate parameters in a user-specified model. (transfer functions, state-space matrices) 1 System identification System identification includes the following steps: Experiment design: its purpose is to obtain good experimental data, and it includes the choice of the measured variables and of the character of the input Signals. Selection of model structure: A suitable model structure is chosen using prior knowledge and trial and error. Choice of the criterion to fit: A suitable cost function is chosen, which reflects how well the. model fits the experimental data. Parameter estimation: An optimisation problem is solved to obtain the numerical values of the model parameters. Model validation: The model is tested in order to reveal any inadequacies. 2 Procedure of system identification Experimental design Data collection Data pre-filtering Model structure selection Parameter estimation Model validation Model ok? No Yes 3 Different mathematical models Model description: Transfer functions State-space models Block diagrams (e.g. Simulink) Notation for continuous time models Complex Laplace variable ‘s’ and differential operator ‘p’ ∂x(t) x&()t -

BERNOULLI NEWS, Vol 22 No 2
Vol. 22 (2), 2015 Published twice per year by the Bernoulli Society ISSN 1360-6727 Contents News from the Bernoulli A VIEW FROM THE PRESIDENT Society p. 2 Prizes, Awards and Special Lectures p. 3 New Executive Members of the Bernoulli Society p. 4 Articles and Letters The Development of Modern Mathematics in Mongolia p. 6 Past Conferences, Sara van de Geer receives the Bernoulli Book from Wilfrid Kendall during the General MeetinGs and Workshops Assembly of the Bernoulli Society ISI World Congress in Rio de Janeiro, Brazil. p. 11 Dear Bernoulli Society Members, ForthcominG Conferences, MeetinGs and Workshops, It is an immense honour for me to write here as new president of the Bernoulli Society. The baton was handed over to me by Wilfrid Kendall, now our past-president, at the ISI World and Calendar of Events Statistics Congress in Rio de Janeiro. I am extremely grateful to Wilfrid for his perfect p. 17 handling of Bernoulli matters in the past two years. My thanks also goes to Ed Waymire, now past past-president. These two wise men helped me through president-electancy and I hope to be able to approximate their standards. Let me welcome Susan Murphy as our new president- elect. I am very much looking forward to work with Susan, with Wilfrid and with the Editor executive committee, council, standing committees and all of you as active Bernoulli Miguel de Carvalho supporters. The new members of council are Arup Bose, Valerie Isham, Victor Rivero, Akira Faculty oF Mathematics Sakai, Lorenzo Zambotti, and Johanna Ziegel. PUC, Chile To meet them, see elsewhere in this issue! Contact Looking at the famous Bernoulli book where pages are reserved for presidents to put their [email protected] signature, one sees there is one name standing much more to the right of the page (see __________________________________________ www.bernoulli-society.org/index.php/history). -

Elect New Council Members
Volume 43 • Issue 3 IMS Bulletin April/May 2014 Elect new Council members CONTENTS The annual IMS elections are announced, with one candidate for President-Elect— 1 IMS Elections 2014 Richard Davis—and 12 candidates standing for six places on Council. The Council nominees, in alphabetical order, are: Marek Biskup, Peter Bühlmann, Florentina Bunea, Members’ News: Ying Hung; 2–3 Sourav Chatterjee, Frank Den Hollander, Holger Dette, Geoffrey Grimmett, Davy Philip Protter, Raymond Paindaveine, Kavita Ramanan, Jonathan Taylor, Aad van der Vaart and Naisyin Wang. J. Carroll, Keith Crank, You can read their statements starting on page 8, or online at http://www.imstat.org/ Bani K. Mallick, Robert T. elections/candidates.htm. Smythe and Michael Stein; Electronic voting for the 2014 IMS Elections has opened. You can vote online using Stephen Fienberg; Alexandre the personalized link in the email sent by Aurore Delaigle, IMS Executive Secretary, Tsybakov; Gang Zheng which also contains your member ID. 3 Statistics in Action: A If you would prefer a paper ballot please contact IMS Canadian Outlook Executive Director, Elyse Gustafson (for contact details see the 4 Stéphane Boucheron panel on page 2). on Big Data Elections close on May 30, 2014. If you have any questions or concerns please feel free to 5 NSF funding opportunity e [email protected] Richard Davis contact Elyse Gustafson . 6 Hand Writing: Solving the Right Problem 7 Student Puzzle Corner 8 Meet the Candidates 13 Recent Papers: Probability Surveys; Stochastic Systems 15 COPSS publishes 50th Marek Biskup Peter Bühlmann Florentina Bunea Sourav Chatterjee anniversary volume 16 Rao Prize Conference 17 Calls for nominations 19 XL-Files: My Valentine’s Escape 20 IMS meetings Frank Den Hollander Holger Dette Geoffrey Grimmett Davy Paindaveine 25 Other meetings 30 Employment Opportunities 31 International Calendar 35 Information for Advertisers Read it online at Kavita Ramanan Jonathan Taylor Aad van der Vaart Naisyin Wang http://bulletin.imstat.org IMSBulletin 2 . -

Statistics Making an Impact
John Pullinger J. R. Statist. Soc. A (2013) 176, Part 4, pp. 819–839 Statistics making an impact John Pullinger House of Commons Library, London, UK [The address of the President, delivered to The Royal Statistical Society on Wednesday, June 26th, 2013] Summary. Statistics provides a special kind of understanding that enables well-informed deci- sions. As citizens and consumers we are faced with an array of choices. Statistics can help us to choose well. Our statistical brains need to be nurtured: we can all learn and practise some simple rules of statistical thinking. To understand how statistics can play a bigger part in our lives today we can draw inspiration from the founders of the Royal Statistical Society. Although in today’s world the information landscape is confused, there is an opportunity for statistics that is there to be seized.This calls for us to celebrate the discipline of statistics, to show confidence in our profession, to use statistics in the public interest and to champion statistical education. The Royal Statistical Society has a vital role to play. Keywords: Chartered Statistician; Citizenship; Economic growth; Evidence; ‘getstats’; Justice; Open data; Public good; The state; Wise choices 1. Introduction Dictionaries trace the source of the word statistics from the Latin ‘status’, the state, to the Italian ‘statista’, one skilled in statecraft, and on to the German ‘Statistik’, the science dealing with data about the condition of a state or community. The Oxford English Dictionary brings ‘statistics’ into English in 1787. Florence Nightingale held that ‘the thoughts and purpose of the Deity are only to be discovered by the statistical study of natural phenomena:::the application of the results of such study [is] the religious duty of man’ (Pearson, 1924). -

A4 -FINAL Report of the ISI Executive Committee to The
INTERNATIONAL STATISTICAL INSTITUTE Report of the ISI Executive Committee 2001-2003 to the General Assembly ISI Executive Committee 2001-2003: President: Dennis Trewin President-Elect: Stephen Stigler Vice Presidents: Denise Lievesley Jef Teugels Jae Chang Lee Director of the ISI Permanent Office: Marcel P.R. Van den Broecke Contents: Activities..................................................................................................................................................................................187 Meetings and Conferences ..................................................................................................................................................187 Publications ............................................................................................................................................................................189 Strengthening the ties between statistical disciplines .....................................................................................................190 Improving the quality of statistics ........................................................................................................................................190 Membership matters .............................................................................................................................................................191 The Future of the ISI .............................................................................................................................................................192