Hierarchical Multi-Label Classification of Social Text Streams
Total Page:16
File Type:pdf, Size:1020Kb

Load more
Recommended publications
-

Synaptics Onetouch(TM) Solution Showcased in New LG Chocolate Mobile Phone
Synaptics OneTouch(TM) Solution Showcased in New LG Chocolate Mobile Phone Configurable capacitive solution provides superior tools and support in the design of the LG VX8550 phone's user interface SANTA CLARA, Calif., Aug 27, 2007 /PRNewswire-FirstCall via COMTEX News Network/ -- Synaptics Inc. (Nasdaq: SYNA), a leading developer of capacitive interface solutions for mobile computing, communications and entertainment devices, today announced that its configurable OneTouch solution is shipping in the new LG Chocolate (VX8550) slider phone. The second-generation LG Chocolate phone has a four-button user interface enabled by Synaptics' OneTouch capacitive solution that provides navigation and function keys. Synaptics' technology allows OEMs to create sleek and desirable industrial designs for consumers by enabling thin, flexible and under-plastic solutions. "Synaptics' OneTouch development kit, tools and support greatly reduced the cycle time from design to development to production," said Woo-Young Kwak, head of LG Electronics mobile handset R&D center. "LG strives to bring innovative products to market while ensuring consumer satisfaction through an enjoyable user experience and Synaptics' OneTouch solution allowed us to incorporate a reliable interface in our new chocolate phone that we expect will delight users." With a focus on reliability and usability considerations, Synaptics' OneTouch is a chip-based solution for OEMs wanting to incorporate capacitive touch interfaces in their products. OEMs reduce their time to market as they go from concept to production using Synaptics' best-in-class design tools and expert technical support while taking advantage of superior product features and performance. "Synaptics' OneTouch offering is a complete end-to-end solution, engineered specifically to help our customers design intuitive and superior capacitive interfaces tailored to their products," said RK Parthasarathy, product line director at Synaptics. -

LG-BL40) October 2009
LG Releases New Chocolate Model (LG- BL40) 4 September 2009 “The new LG Chocolate will dramatically change the way we interact with our phones,” said Dr. Skott Ahn, CEO of LG Electronics Mobile Communications Company. “The new Chocolate reflects the originality and sophistication of the Black Label Series and like its predecessor, we are confident that the new Chocolate will create its own legacy and further enhance our standing in the market.” Beginning from the UK, the new LG Chocolate will be released across the Europe in September and will be expanded to the rest of the world from LG Chocolate (LG-BL40) October 2009. Source: LG LG Electronics today announced the worldwide retail release of the highly anticipated new Chocolate (LG-BL40). The stunning fourth handset of the Black Label Series will be available in Europe from mid-September before making its way around the world. With the introduction of this bold new shape, the new Chocolate is essentially reinventing the way consumers view and use mobile phones. Designed with sleek sophistication, the strikingly unconventional 4-inch wide screen opens up an enlarged and more optimal space for “on-the-go” computing, allowing for an entirely new mobile experience that raises the bar of innovation. Users will see things differently with the widened 21:9 panoramic display that establishes a new level of visual comfort for the reading of web pages and e-mail and dramatically brings videos and games to life with cinematic flair. Going wide also allows for the dual screen era to finally be brought to handsets for enhanced usability, which when combined with LG’s upgraded and intuitive S- Class UI brings a whole new meaning to the words “user friendly”. -
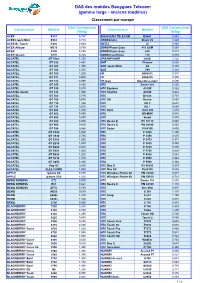
DAS Des Mobiles Bouygues Telecom (Gamme Large - Anciens Modèles) Classement Par Marque
DAS des mobiles Bouygues Telecom (gamme large - anciens modèles) Classement par marque DAS Constructeur DAS Constructeur Constructeur Modèle Constructeur Modèle (W/kg) (W/kg) ACER E101 0,747 BOUYGUES TELECOM BS401 0,542 ACER Liquid Mini E310 0,719 CROSSCALL Shark V2 1,460 ACER Be Touch E400 0,949 DBTEL J6 0,960 ACER Allegro M310 0,780 DORO Phone Easy 410 GSM 0,263 ACER S100 0,725 DORO Phone Easy 610 0,313 ACER Stream S110 0,760 DORO EasyPhone 715 0,389 ALCATEL OT View 1,350 DREAMPHONE G500i 1,120 ALCATEL OT 292 0,487 GHT Chrome 0,636 ALCATEL OT 303 1,300 GHT Jason Mraz G3 0,559 ALCATEL OT 304 1,000 GHT T99 0,316 ALCATEL OT 305 1,200 HP HW6515 0,391 ALCATEL OT 311 0,600 HP HW6915 0,390 ALCATEL OT 332 0,490 HP Ipaq Data Messenger 0,590 ALCATEL OT 355 0,850 HTC Desire 601 0,530 ALCATEL OT 535 0,570 HTC Explorer A310E 0,526 ALCATEL Sénior OT 536 1,090 HTC ChaCha A810E 0,822 ALCATEL OT 565 0,720 HTC Desire 0,752 ALCATEL OT 708 0,660 HTC HD Desire 0,826 ALCATEL OT 710 1,100 HTC HD 2 0,631 ALCATEL OT 735 0,570 HTC HD 7 0,659 ALCATEL OT 800 1,080 HTC Hero Hero 100 1,210 ALCATEL OT 802 0,800 HTC HD-MINI 0,985 ALCATEL OT 808 0,800 HTC Smart 0,990 ALCATEL OT 880 0,900 HTC Desire Z PC 10110 0,863 ALCATEL OT 980 0,640 HTC Desire S PG 88100 0,353 ALCATEL OT 995 0,586 HTC Radar PI 06100 0,400 ALCATEL OT C550 0,560 HTC P 3300 1,100 ALCATEL OT C630 0,790 HTC P 3450 0,635 ALCATEL OT E160 1,000 HTC P 3470 0,371 ALCATEL OT E230 1,000 HTC P 3600 0,980 ALCATEL OT E260 0,530 HTC P 3650 0,890 ALCATEL OT E801 1,000 HTC P 3700 0,854 ALCATEL OT E805 1,000 HTC P -

Datasheet Chocolate Touch LG:Datasheet Chocolate Touch LG Printer 10/2/09 9:50 AM Page 1
Datasheet_chocolate_Touch_LG:Datasheet_chocolate_Touch_LG Printer 10/2/09 9:50 AM Page 1 Meet the new LG Chocolate Touch: the stylish, feature-rich phone with Dolby® Mobile which delivers an BLUETOOTH® GENERAL • Version: 2.1 + EDR (Enhanced Data Rate) • Customizable Font Size and Type for Dialing, Menus, enhanced listening experience with • Save up to 20 Bluetooth Pairings Lists, and Messages • Supported Profiles: headset, handsfree*, dial-up networking, • Charging Screens: Desk Clock, Calendar stereo, phonebook access, basic printing, object push**, • Micro USB/Charging Port sparkling clarity. For music lovers, it’s file transfer, basic imaging, human interface • USB Charging via Computer • Listen to Music with Optional Stereo Bluetooth Headset*** • Clear Images, Text, and Fun Animations through Flash User • Send all Contacts and Calendar Events via Bluetooth Interface Support the sweetest LG Chocolate yet. • Print and Send User Generated Pictures (JPEG) via Bluetooth • GPS Support for Enhanced Location Accuracy *For Bluetooth vehicle/accessory compatibility, go to www.verizonwireless.com/bluetoothchart. • Airplane/Standalone Mode (RF Off) Bluetooth **Phone does not support all OBEX profiles. • Changeable Back Plates: Black and Purple **Accessories sold separately. VOICE/AUDIO SPECIFICATIONS • One-Touch Speakerphone • Technology: CDMA • Speaker-Independent Voice Commands • Frequency: 1.9 GHz CDMA PCS, 800 MHz CDMA (Digital Dual-Band) • Text to Speech • Data Transmission: EVDO† Rev. 0 • Voice-Activated Dialing up to 1,000 Entries • Dimensions: 4.30"(H) x 2.20"(W) x 0.47"(D) • Voice Recording Time: 1 min. or 1 hr.* (standby) for up to 1500 memos • Weight: 4.23 oz. SOUND • MP3 Music Ringer Support (clips from hit songs)† • Display: 262K Color TFT, 400 x 240 Pixels, 3.0" • 28 Unique Ringtones + Vibrate and Silent Modes • Standard Battery: 1,000 mAh • TTY/TDD Support • Usage Time: up to 306 Minutes* • Hearing Aid Compatible (M4/T4 - Rating) • Standby Time: up to 470 Hours* STYLING *Depends on available memory. -
Total Equipment Coverage Loss • Theft • Damage • Defects
pproved a laim c Date umber n laim c laim Filed laim c Date aim: L c a making r TE af W kno o T ion T ma R o F n i Date of Purchase of Date odel odel m Device ake ake m Device umber n Wireless aim: L c a making E r O f E b W kno o T ion T ma R o F n i Wireless store Wireless 1.866.406.5154 1.866.406.5154 Verizon any visit or all c • T: efec D L mechanica or L rica T ec L e for aim L c a e L fi Have a method of payment for your deductible on hand on deductible your for payment of method a Have • Have the make and model of your device available device your of model and make the Have • 1.888.881.2622 y Verizon account Verizon y m your to on log or isit phoneclaim.com/verizon isit v at Asurion call , • Device: D Damage or en, L o sT , T Los a for aim L c a e L i f must be filed within 60 days of incident. of days 60 within filed be must All claims claims All PT. m 10P and T, m m 11P T, c idnight m 12 idnight ET, ET, idnight m 12 by filed are claims when day next the as Receive a replacement as soon soon as replacement a Receive tracking. package and online or by phone. Receive emails with status updates updates status with emails Receive phone. -

A PROJECT REPORT on Brand Preference of Mobile Phones Among Ghaziabad’S College Students
A PROJECT REPORT ON Brand Preference Of Mobile Phones Among Ghaziabad’s College Students Submitted To: Supervisor Submitted By: Your Name Roll No.- XXXXXXX COLLEGE NAME Ghaziabad, U.P. CERTIFICATE This is to certify that YOUR NAME, student of COLLEGE NAME has completed her project on the topic of “ Brand Preference of Mobile Phones Among Ghaziabad’s College Students” under the supervision and guidance of SUPERVISOR Faculty member of COLLEGE NAME. To best of my knowledge the report is original and has not been copied or submitted anywhere else. It is an independent work done by him. (YOUR SUPERVISOR) ACKNOWLEDGEMENT When I embarked this project, it appeared to me as onerous task. Slowly as I progressed I did realized that I was not alone after all. I wish to express my gratitude to DIRECTOR NAME, director, COLLEGE NAME, FACULTY MEMBER, Program co-ordinator who have extended their kind help, guidance and suggestion without which it could not have been possible for me to complete this project report. My sincere thanks to my all entire faculty members XXXXX, XXXXX and all staff members for offering me all kinds of support and help in preparing the project. I am deeply indebted to my guide NAME for not only her valuable and enlightened, guidance but also for the freedom she rendered me during this project work. I am thankful to my group member NAME and other classmates, well-wishers who with their magnanimous and generous help and support made it a relative easier affair. My heart goes out to my parents who bear with me all the trouble I caused then with smile during the entire study period and beyond. -

(12) United States Design Patent (10) Patent No.: US D684,571 S Akana Et Al
USOOD684571S (12) United States Design Patent (10) Patent No.: US D684,571 S Akana et al. (45) Date of Patent: Jun. 18, 2013 (54) ELECTRONIC DEVICE (56) References Cited (75) Inventors: Jody Akana, San Francisco, CA (US); U.S. PATENT DOCUMENTS Bartley K. Andre, Menlo Park, CA 2.424,630 A 7, 1947 Perez (US); Jeremy Bataillou, San Francisco, D262,151 S 12/1981 Sussman CA (US); Daniel J. Coster, San (Continued) Francisco, CA (US); Daniele De Iuliis, San Francisco, CA (US); M. Evans FOREIGN PATENT DOCUMENTS Hankey, San Francisco, CA (US); AU 315078 7/2007 Julian Hoenig, San Francisco, CA (US); CA 72548 5, 1993 Richard P. Howarth, San Francisco, CA (Continued) (US); Jonathan P. Ive, San Francisco, CA (US); Duncan Robert Kerr, San OTHER PUBLICATIONS Francisco, CA (US); Shin Nishibori, "A Day in the Life of InfoLink.” Stanford University Libraries, pub Kailua, HI (US); Matthew Dean lished May 1, 2003. Rohrbach, San Francisco, CA (US); Peter Russell-Clarke, San Francisco, (Continued) CA (US); Christopher J. Stringer, Woodside, CA (US); Eugene Antony Primary Examiner — Barbara Fox Whang, San Francisco, CA (US); Rico (74) Attorney, Agent, or Firm — Sterne, Kessler, Zorkendorfer, San Francisco, CA (US) Goldstein & Fox PLLC (57) CLAM (73) Assignee: Apple Inc., Cupertino, CA (US) The ornamental design for an electronic device, as shown and (**) Term: 14 Years described. (21) Appl. No.: 29/431,553 DESCRIPTION FIG. 1 is a bottom front perspective view of an electronic (22) Filed: Sep. 7, 2012 device showing our new design; (51) LOC (9) Cl. .................................................. 14-02 FIG. 2 is a bottom rear perspective view thereof; (52) U.S. -

Fnac Reprise
FNAC REPRISE Liste des smartphones éligibles au programme de reprise au 19/08/2016 ACER LIQUID Z4 APPLE IPHONE 5 BLACK 64GB ACER INCORPORATED LIQUID Z530S APPLE IPHONE 5 WHITE 16GB ACER INCORPORATED LIQUID Z630S APPLE IPHONE 5 WHITE 32GB ALBA ALBA 4.5INCH 5MP 4G 8GB APPLE IPHONE 5 WHITE 64GB ALBA DUAL SIM APPLE IPHONE 5C ALCATEL IDOL 3 8GB APPLE IPHONE 5C BLUE 16GB ALCATEL ONE TOUCH 228 APPLE IPHONE 5C BLUE 32GB ALCATEL ONE TOUCH 903 APPLE IPHONE 5C BLUE 8GB ALCATEL ONE TOUCH 903X APPLE IPHONE 5C GREEN 16GB ALCATEL ONE TOUCH IDOL 2 MINI S APPLE IPHONE 5C GREEN 32GB ALCATEL ONE TOUCH TPOP APPLE IPHONE 5C GREEN 8GB ALCATEL ONETOUCH POP C3 APPLE IPHONE 5C PINK 16GB AMAZON FIRE PHONE APPLE IPHONE 5C PINK 32GB APPLE APPLE WATCH EDITION 42MM APPLE IPHONE 5C PINK 8GB APPLE IPHONE 3G APPLE IPHONE 5C WHITE 16GB APPLE IPHONE 3G BLACK 16GB APPLE IPHONE 5C WHITE 32GB APPLE IPHONE 3G BLACK 8GB APPLE IPHONE 5C WHITE 8GB APPLE IPHONE 3G WHITE 16GB APPLE IPHONE 5C YELLOW 16GB APPLE IPHONE 3GS APPLE IPHONE 5C YELLOW 32GB APPLE IPHONE 3GS 8GB APPLE IPHONE 5C YELLOW 8GB APPLE IPHONE 3GS BLACK 16GB APPLE IPHONE 5S APPLE IPHONE 3GS BLACK 32GB APPLE IPHONE 5S BLACK 16GB APPLE IPHONE 3GS WHITE 16GB APPLE IPHONE 5S BLACK 32GB APPLE IPHONE 3GS WHITE 32GB APPLE IPHONE 5S BLACK 64GB APPLE IPHONE 4 APPLE IPHONE 5S GOLD 16GB APPLE IPHONE 4 BLACK 16GB APPLE IPHONE 5S GOLD 32GB APPLE IPHONE 4 BLACK 32GB APPLE IPHONE 5S GOLD 64GB APPLE IPHONE 4 BLACK 8GB APPLE IPHONE 5S WHITE 16GB APPLE IPHONE 4 WHITE 16GB APPLE IPHONE 5S WHITE 32GB APPLE IPHONE 4 WHITE 32GB APPLE IPHONE -

Mesmerizing. It's
LG Electronics 2012 _wish USERS GUIDE What is your wish? Warning: Wishing is a powerful force. It can lead to amazing leaps of imagination. We are not responsible for the effects of this book on the reader. 01 LG Electronics 2012 _wish Our lawyers wish to include the following: All LG Electronics products and services mentioned in this publication are the property of LG Electronics. 02 My wish This is a book 12 LG’s wish 14 Message from the CEO 18 Four Pilars of Core Strategy about wishing. 22 My wish + LG’s wish 24 Home Entertainment Company And how one 30 Mobile Communications Company 36 Home Appliance Company 42 Air Conditioning & Energy Solution Company company has been 48 Wish + New Business 48 Solar Energy 50 Water Treatment listening to the 52 We wish 54 Environment wishes of people 56 Global Social Contributions 58 Sports Sponsorships 60 Marketing Campaign & Activity like you. 62 Leading the world in Innovation 64 Awards 66 Fact & Figures 76 Financial Statements Warning: Wishing is a powerful force. It can lead to amazing leaps of imagination. We are not responsible for the effects of this book on the reader. 01 LG Electronics 2012 _wish It is a story And how that about how inspiration is the your wishes very first step become the in the process inspiration for of innovation our engineers across all of our and designers. divisions. Warning: Wishing is a powerful force. It can lead to amazing leaps of imagination. We are not responsible for the effects of this book on the reader. -
![[Enter Post Title Here]](https://docslib.b-cdn.net/cover/0272/enter-post-title-here-3690272.webp)
[Enter Post Title Here]
[Enter Post Title Here] LG Corp Korean: LG ȶš) is the second largest Korean conglomerate company that produces electronics, chemicals, and telecommunications products and operates subsidiaries like LG Electronics, LG Display, LG Telecom and LG Chem in over 80 countries. LG Corp founder Koo In-Hwoi established Lak-Hui Chemical Industrial Corp. in 1947.[3] In 1952, Lak-Hui (pronounced "Lucky", currently LG Chem) became the first Korean company to enter the plastics industry. As the company expanded its plastics business, it established GoldStar Co., Ltd., (currently LG Electronics Inc.) in 1958. Goldstar produced South Korea's first radio. Many consumer electronics were sold under the brand name GoldStar, while some other household products (not available outside South Korea) were sold under the brand name of Lucky. The Lucky brand was famous for its line of hygiene products such as soaps and Hi-Ti laundry detergents, but most associated with its Lucky and Perioe toothpaste. In 1995, to better compete in the Western market, the company was renamed "LG", the abbreviation of "Lucky Goldstar". More recently, the company associates the letters LG with the company tagline "Life's Good". Since 2009, LG also owns the domain name LG.com.[4 Companies GoldStar logo, prominently used before the introduction of the LG logo Since 2001, LG has two joint ventures with Royal Philips Electronics: LG Philips Display and LG.Philips LCD, but Philips sold off its shares in late 2008.[5] Also LG has entered into a joint venture with Nortel Networks and has created LG-Nortel Co. Ltd. LG has a joint venture with Hitachi, Hitachi-LG Data Storage, which manufactures optical data storage products like DVD-ROM drives, CD writers, etc. -

The Study on the Smartphone Strategies of Samsung and LG
The study on the Smartphone strategies of Samsung and LG before and after the iPhone launch in Korea By Dae-Won Kim THESIS Submitted to KDI School of Public Policy and Management in partial fulfillment of the requirements for the degree of MASTER OF BUSINESS ADMINISTRATION 2010 The study on the Smartphone strategies of Samsung and LG before and after the iPhone launch in Korea By Dae-Won Kim THESIS Submitted to KDI School of Public Policy and Management in partial fulfillment of the requirements for the degree of MASTER OF BUSINESS ADMINISTRATION 2010 Professor Seung-Joo Lee ABSTRACT The study on the Smartphone strategies of Samsung and LG before and after the iPhone launch in Korea By Dae-Won Kim In Korea, domestic mobile phone brands take up almost 90% of market share. Such market dominance was mainly driven by high customer loyalty to Korean brands and advanced technological prowess of Korean handset manufacturers. However, upon its arrival, iPhone started to reshape the market landscape. Smartphones became a new market trend. Hit by so called ‘iPhone shock’, Korean mobile phone makers lost their market hegemony and ended up falling behind the trend. Against this backdrop, this thesis aims to study why Samsung and LG Electronics lost ground to Apple, a newcomer in the mobile phone business, by analyzing the competitiveness of iPhone, the mobile phone industry before and after the launch of iPhone, and relevant policies and the strategies of Samsung and LG. It was the absence of ability to create new market that made them underperform in the smartphone market at the beginning. -

It Is Hard to Miss How Passionate We Are About Technology, Design, the Environment, and Our Neighbors. and Now, That Passion Is Delivering
IT is hard to miss how passionate we are about technology, design, the environment, and our THE PERFECT HARMONY OF neighbors. And now, that passion is delivering... We shipped a record 80.5 million mobile phones in 2007, a remarkable consumers with stylish design and innovations in image capture, user It is hard to think of any consumer 27% improvement that boosted sales 20% to USD 11.2 billion. Operat- interface, and Internet connectivity. ing profit margin also continued to improve, rising from 6.8% to 8.1% electronics field that changes more as our premium handsets won over consumers around the globe. In 2008, many of our new phones will feature touch technology to make During the year, we expanded our product localization strategy from their advanced features easier to use. These will include high-tech rapidly and dramatically than the mobile North America, Europe, and Korea to include the CIS, India, and South handsets with advanced camera and Internet features such as the LG- MC phone space. Models seem to come and and Central America. We also sharpened our cost-competitiveness by KF510, LG-KF600, and LG-KF700. We will also launch the LG Secret, the Mobile Communications strengthening operations, increasing our number of global platforms, third phone in our Black Label series. Designed around the concept of Company and streamlining our global supply chain. In 2008, we are aiming to “style that lasts”, the LG Secret has a timeless and elegant design that is go overnight, and only a precious few grow sales volume, revenue, and operating profit by more than 20% enhanced by stylish materials such as carbon fiber and tempered glass.