European Processor Initiative & RISC-V
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

An Operational Perspective on a Hybrid and Heterogeneous Cray XC50 System
An Operational Perspective on a Hybrid and Heterogeneous Cray XC50 System Sadaf Alam, Nicola Bianchi, Nicholas Cardo, Matteo Chesi, Miguel Gila, Stefano Gorini, Mark Klein, Colin McMurtrie, Marco Passerini, Carmelo Ponti, Fabio Verzelloni CSCS – Swiss National Supercomputing Centre Lugano, Switzerland Email: {sadaf.alam, nicola.bianchi, nicholas.cardo, matteo.chesi, miguel.gila, stefano.gorini, mark.klein, colin.mcmurtrie, marco.passerini, carmelo.ponti, fabio.verzelloni}@cscs.ch Abstract—The Swiss National Supercomputing Centre added depth provides the necessary space for full-sized PCI- (CSCS) upgraded its flagship system called Piz Daint in Q4 e daughter cards to be used in the compute nodes. The use 2016 in order to support a wider range of services. The of a standard PCI-e interface was done to provide additional upgraded system is a heterogeneous Cray XC50 and XC40 system with Nvidia GPU accelerated (Pascal) devices as well as choice and allow the systems to evolve over time[1]. multi-core nodes with diverse memory configurations. Despite Figure 1 clearly shows the visible increase in length of the state-of-the-art hardware and the design complexity, the 37cm between an XC40 compute module (front) and an system was built in a matter of weeks and was returned to XC50 compute module (rear). fully operational service for CSCS user communities in less than two months, while at the same time providing significant improvements in energy efficiency. This paper focuses on the innovative features of the Piz Daint system that not only resulted in an adaptive, scalable and stable platform but also offers a very high level of operational robustness for a complex ecosystem. -

A Scheduling Policy to Improve 10% of Communication Time in Parallel FFT
A scheduling policy to improve 10% of communication time in parallel FFT Samar A. Aseeri Anando Gopal Chatterjee Mahendra K. Verma David E. Keyes ECRC, KAUST CC, IIT Kanpur Dept. of Physics, IIT Kanpur ECRC, KAUST Thuwal, Saudi Arabia Kanpur, India Kanpur, India Thuwal, Saudi Arabia [email protected] [email protected] [email protected] [email protected] Abstract—The fast Fourier transform (FFT) has applications A. FFT Algorithm in almost every frequency related studies, e.g. in image and signal Forward Fourier transform is given by the following equa- processing, and radio astronomy. It is also used to solve partial differential equations used in fluid flows, density functional tion. 3 theory, many-body theory, and others. Three-dimensional N X (−ikxx) (−iky y) (−ikz z) 3 f^(k) = f(x; y; z)e e e (1) FFT has large time complexity O(N log2 N). Hence, parallel algorithms are made to compute such FFTs. Popular libraries kx;ky ;kz 3 perform slab division or pencil decomposition of N data. None The beauty of this sum is that k ; k ; and k can be summed of the existing libraries have achieved perfect inverse scaling x y z of time with (T −1 ≈ n) cores because FFT requires all-to-all independent of each other. These sums are done at different communication and clusters hitherto do not have physical all- to-all connections. With advances in switches and topologies, we now have Dragonfly topology, which physically connects various units in an all-to-all fashion. -

Towards Exascale Computing
TowardsTowards ExascaleExascale Computing:Computing: TheThe ECOSCALEECOSCALE ApproachApproach Dirk Koch, The University of Manchester, UK ([email protected]) 1 Motivation: let’s build a 1,000,000,000,000,000,000 FLOPS Computer (Exascale computing: 1018 FLOPS = one quintillion or a billion billion floating-point calculations per sec.) 2 1,000,000,000,000,000,000 FLOPS . 10,000,000,000,000,000,00 FLOPS 1975: MOS 6502 (Commodore 64, BBC Micro) 3 Sunway TaihuLight Supercomputer . 2016 (fully operational) . 12,543,6000,000,000,000,00 FLOPS (125.436 petaFLOPS) . Architecture Sunway SW26010 260C (Digital Alpha clone) 1.45GHz 10,649,600 cores . Power “The cooling system for TaihuLight uses a closed- coupled chilled water outfit suited for 28 MW with a custom liquid cooling unit”* *https://www.nextplatform.com/2016/06/20/look-inside-chinas-chart-topping-new-supercomputer/ . Cost US$ ~$270 million 4 TOP500 Performance Development We need more than all the performance of all TOP500 machines together! 5 TaihuLight for Exascale Computing? We need 8x the worlds fastest supercomputer: . Architecture Sunway SW26010 260C (Digital Alpha clone) @1.45GHz: > 85M cores . Power 224 MW (including cooling) costs ~ US$ 40K/hour, US$ 340M/year from coal: 2,302,195 tons of CO2 per year . Cost US$ 2.16 billion We have to get at least 10x better in energy efficiency 2-3x better in cost Also: scalable programming models 6 Alternative: Green500 Shoubu supercomputer (#1 Green500 in 2015): . Cores: 1,181,952 . Theoretical Peak: 1,535.83 TFLOPS/s . Memory: 82 TB . Processor: Xeon E5-2618Lv3 8C 2.3GHz . -

Computational PHYSICS Shuai Dong
Computational physiCs Shuai Dong Evolution: Is this our final end-result? Outline • Brief history of computers • Supercomputers • Brief introduction of computational science • Some basic concepts, tools, examples Birth of Computational Science (Physics) The first electronic general-purpose computer: Constructed in Moore School of Electrical Engineering, University of Pennsylvania, 1946 ENIAC: Electronic Numerical Integrator And Computer ENIAC Electronic Numerical Integrator And Computer • Design and construction was financed by the United States Army. • Designed to calculate artillery firing tables for the United States Army's Ballistic Research Laboratory. • It was heralded in the press as a "Giant Brain". • It had a speed of one thousand times that of electro- mechanical machines. • ENIAC was named an IEEE Milestone in 1987. Gaint Brain • ENIAC contained 17,468 vacuum tubes, 7,200 crystal diodes, 1,500 relays, 70,000 resistors, 10,000 capacitors and around 5 million hand-soldered joints. It weighed more than 27 tons, took up 167 m2, and consumed 150 kW of power. • This led to the rumor that whenever the computer was switched on, lights in Philadelphia dimmed. • Input was from an IBM card reader, and an IBM card punch was used for output. Development of micro-computers modern PC 1981 IBM PC 5150 CPU: Intel i3,i5,i7, CPU: 8088, 5 MHz 3 GHz Floppy disk or cassette Solid state disk 1984 Macintosh Steve Jobs modern iMac Supercomputers The CDC (Control Data Corporation) 6600, released in 1964, is generally considered the first supercomputer. Seymour Roger Cray (1925-1996) The father of supercomputing, Cray-1 who created the supercomputer industry. Cray Inc. -

View Annual Report
Fellow Shareholders, Headlined by strong growth in revenue and profitability, we had one of our best years ever in 2015, executing across each of our major focus areas and positioning our company for continued growth into the future. We achieved another year of record revenue, growing by nearly 30 percent compared to 2014. In fact, our revenue in 2015 was more than three times higher than just four years prior — driven by growth in both our addressable market and market share. Over the last five years, we have transformed from a company solely focused on the high-end of the supercomputing market — where we are now the clear market leader — to a company with multiple product lines serving multiple markets. We provide our customers with powerful computing, storage and analytics solutions that give them the tools to advance their businesses in ways never before possible. During 2015, we installed supercomputing and storage solutions at a number of customers around the world. In the U.S., we completed the first phase of the massive new “Trinity” system at Los Alamos National Laboratory. This Cray XC40 supercomputer with Sonexion storage serves as the National Nuclear Security Administration’s flagship supercomputer, supporting all three of the NNSA’s national laboratories. We installed the first petaflop supercomputer in India at the Indian Institute of Science. In Europe, we installed numerous XC and storage solutions, including a significant expansion of the existing XC40 supercomputer at the University of Stuttgart in Germany. This new system nearly doubles their computing capacity and is currently the fastest supercomputer in Germany. -

FCMSSR Meeting 2018-01 All Slides
Federal Committee for Meteorological Services and Supporting Research (FCMSSR) Dr. Neil Jacobs Assistant Secretary for Environmental Observation and Prediction and FCMSSR Chair April 30, 2018 Office of the Federal Coordinator for Meteorology Services and Supporting Research 1 Agenda 2:30 – Opening Remarks (Dr. Neil Jacobs, NOAA) 2:40 – Action Item Review (Dr. Bill Schulz, OFCM) 2:45 – Federal Coordinator's Update (OFCM) 3:00 – Implementing Section 402 of the Weather Research And Forecasting Innovation Act Of 2017 (OFCM) 3:20 – Federal Meteorological Services And Supporting Research Strategic Plan and Annual Report. (OFCM) 3:30 – Qualification Standards For Civilian Meteorologists. (Mr. Ralph Stoffler, USAF A3-W) 3:50 – National Earth System Predication Capability (ESPC) High Performance Computing Summary. (ESPC Staff) 4:10 – Open Discussion (All) 4:20 – Wrap-Up (Dr. Neil Jacobs, NOAA) Office of the Federal Coordinator for Meteorology Services and Supporting Research 2 FCMSSR Action Items AI # Text Office Comment Status Due Date Responsible 2017-2.1 Reconvene JAG/ICAWS to OFCM, • JAG/ICAWS convened. Working 04/30/18 develop options to broaden FCMSSR • Options presented to FCMSSR Chairmanship beyond Agencies ICMSSR the Undersecretary of Commerce • then FCMSSR with a for Oceans and Atmosphere. revised Charter Draft a modified FCMSSR • Draft Charter reviewed charter to include ICAWS duties by ICMSSR. as outlined in Section 402 of the • Pending FCMSSR and Weather Research and Forecasting OSTP approval to Innovation Act of 2017 and secure finalize Charter for ICMSSR concurrence. signature. Recommend new due date: 30 June 2018. 2017-2.2 Publish the Strategic Plan for OFCM 1/12/18: Plan published on Closed 11/03/17 Federal Weather Coordination as OFCM website presented during the 24 October 2017 FCMMSR Meeting. -

This Is Your Presentation Title
Introduction to GPU/Parallel Computing Ioannis E. Venetis University of Patras 1 Introduction to GPU/Parallel Computing www.prace-ri.eu Introduction to High Performance Systems 2 Introduction to GPU/Parallel Computing www.prace-ri.eu Wait, what? Aren’t we here to talk about GPUs? And how to program them with CUDA? Yes, but we need to understand their place and their purpose in modern High Performance Systems This will make it clear when it is beneficial to use them 3 Introduction to GPU/Parallel Computing www.prace-ri.eu Top 500 (June 2017) CPU Accel. Rmax Rpeak Power Rank Site System Cores Cores (TFlop/s) (TFlop/s) (kW) National Sunway TaihuLight - Sunway MPP, Supercomputing Center Sunway SW26010 260C 1.45GHz, 1 10.649.600 - 93.014,6 125.435,9 15.371 in Wuxi Sunway China NRCPC National Super Tianhe-2 (MilkyWay-2) - TH-IVB-FEP Computer Center in Cluster, Intel Xeon E5-2692 12C 2 Guangzhou 2.200GHz, TH Express-2, Intel Xeon 3.120.000 2.736.000 33.862,7 54.902,4 17.808 China Phi 31S1P NUDT Swiss National Piz Daint - Cray XC50, Xeon E5- Supercomputing Centre 2690v3 12C 2.6GHz, Aries interconnect 3 361.760 297.920 19.590,0 25.326,3 2.272 (CSCS) , NVIDIA Tesla P100 Cray Inc. DOE/SC/Oak Ridge Titan - Cray XK7 , Opteron 6274 16C National Laboratory 2.200GHz, Cray Gemini interconnect, 4 560.640 261.632 17.590,0 27.112,5 8.209 United States NVIDIA K20x Cray Inc. DOE/NNSA/LLNL Sequoia - BlueGene/Q, Power BQC 5 United States 16C 1.60 GHz, Custom 1.572.864 - 17.173,2 20.132,7 7.890 4 Introduction to GPU/ParallelIBM Computing www.prace-ri.eu How do -
TECHNICAL GUIDELINES for APPLICANTS to PRACE 17Th CALL
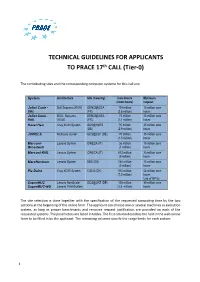
TECHNICAL GUIDELINES FOR APPLICANTS TO PRACE 17th CALL (T ier-0) The contributing sites and the corresponding computer systems for this call are: System Architecture Site (Country) Core Hours Minimum (node hours) request Joliot Curie - Bull Sequana X1000 GENCI@CEA 134 million 15 million core SKL (FR) (2.8 million) hours Joliot Curie - BULL Sequana GENCI@CEA 72 million 15 million core KNL X1000 (FR) (1,1 million) hours Hazel Hen Cray XC40 System GCS@HLRS 70 million 35 million core (DE) (2.9 million) hours JUWELS Multicore cluster GCS@JSC (DE) 70 million 35 million core (1.5 million) hours Marconi- Lenovo System CINECA (IT) 36 million 15 million core Broadwell (1 million) hours Marconi-KNL Lenovo System CINECA (IT) 612 million 30 million core (9 million) hours MareNostrum Lenovo System BSC (ES) 240 million 15 million core (5 million) hours Piz Daint Cray XC50 System CSCS (CH) 510 million 68 million core (7.5 million) hours Use of GPUs SuperMUC Lenovo NextScale/ GCS@LRZ (DE) 105 million 35 million core SuperMUC-NG Lenovo ThinkSystem (3.8 million) hours The site selection is done together with the specification of the requested computing time by the two sections at the beginning of the online form. The applicant can choose one or several machines as execution system, as long as proper benchmarks and resource request justification are provided on each of the requested systems. The parameters are listed in tables. The first column describes the field in the web online form to be filled in by the applicant. The remaining columns specify the range limits for each system. -

It's a Multi-Core World
It’s a Multicore World John Urbanic Pittsburgh Supercomputing Center Parallel Computing Scientist Moore's Law abandoned serial programming around 2004 Courtesy Liberty Computer Architecture Research Group Moore’s Law is not to blame. Intel process technology capabilities High Volume Manufacturing 2004 2006 2008 2010 2012 2014 2016 2018 Feature Size 90nm 65nm 45nm 32nm 22nm 16nm 11nm 8nm Integration Capacity (Billions of 2 4 8 16 32 64 128 256 Transistors) Transistor for Influenza Virus 90nm Process Source: CDC 50nm Source: Intel At end of day, we keep using all those new transistors. That Power and Clock Inflection Point in 2004… didn’t get better. Fun fact: At 100+ Watts and <1V, currents are beginning to exceed 100A at the point of load! Source: Kogge and Shalf, IEEE CISE Courtesy Horst Simon, LBNL Not a new problem, just a new scale… CPU Power W) Cray-2 with cooling tower in foreground, circa 1985 And how to get more performance from more transistors with the same power. RULE OF THUMB A 15% Frequency Power Performance Reduction Reduction Reduction Reduction In Voltage 15% 45% 10% Yields SINGLE CORE DUAL CORE Area = 1 Area = 2 Voltage = 1 Voltage = 0.85 Freq = 1 Freq = 0.85 Power = 1 Power = 1 Perf = 1 Perf = ~1.8 Single Socket Parallelism Processor Year Vector Bits SP FLOPs / core / Cores FLOPs/cycle cycle Pentium III 1999 SSE 128 3 1 3 Pentium IV 2001 SSE2 128 4 1 4 Core 2006 SSE3 128 8 2 16 Nehalem 2008 SSE4 128 8 10 80 Sandybridge 2011 AVX 256 16 12 192 Haswell 2013 AVX2 256 32 18 576 KNC 2012 AVX512 512 32 64 2048 KNL 2016 AVX512 512 64 72 4608 Skylake 2017 AVX512 512 96 28 2688 Putting It All Together Prototypical Application: Serial Weather Model CPU MEMORY First Parallel Weather Modeling Algorithm: Richardson in 1917 Courtesy John Burkhardt, Virginia Tech Weather Model: Shared Memory (OpenMP) Core Fortran: !$omp parallel do Core do i = 1, n Core a(i) = b(i) + c(i) enddoCore C/C++: MEMORY #pragma omp parallel for Four meteorologists in the samefor(i=1; room sharingi<=n; i++) the map. -

Cray XC40 Power Monitoring and Control for Knights Landing
Cray XC40 Power Monitoring and Control for Knights Landing Steven J. Martin, David Rush Matthew Kappel, Michael Sandstedt, Joshua Williams Cray Inc. Cray Inc. Chippewa Falls, WI USA St. Paul, MN USA {stevem,rushd}@cray.com {mkappel,msandste,jw}@cray.com Abstract—This paper details the Cray XC40 power monitor- This paper is organized as follows: In section II, we ing and control capabilities for Intel Knights Landing (KNL) detail blade-level Hardware Supervisory System (HSS) ar- based systems. The Cray XC40 hardware blade design for Intel chitecture changes introduced to enable improved telemetry KNL processors is the first in the XC family to incorporate enhancements directly related to power monitoring feedback gathering capabilities on Cray XC40 blades with Intel KNL driven by customers and the HPC community. This paper fo- processors. Section III provides information on updates to cuses on power monitoring and control directly related to Cray interfaces available for power monitoring and control that blades with Intel KNL processors and the interfaces available are new for Cray XC40 systems and the software released to users, system administrators, and workload managers to to support blades with Intel KNL processors. Section IV access power management features. shows monitoring and control examples. Keywords-Power monitoring; power capping; RAPL; energy efficiency; power measurement; Cray XC40; Intel Knights II. ENHANCED HSS BLADE-LEVEL MONITORING Landing The XC40 KNL blade incorporates a number of en- hancements over previous XC blade types that enable the I. INTRODUCTION collection of power telemetry in greater detail and with Cray has provided advanced power monitoring and control improved accuracy. -

Joaovicentesouto-Tcc.Pdf
UNIVERSIDADE FEDERAL DE SANTA CATARINA CENTRO TECNOLÓGICO DEPARTAMENTO DE INFORMÁTICA E ESTATÍSTICA CIÊNCIAS DA COMPUTAÇÃO João Vicente Souto An Inter-Cluster Communication Facility for Lightweight Manycore Processors in the Nanvix OS Florianópolis 6 de dezembro de 2019 João Vicente Souto An Inter-Cluster Communication Facility for Lightweight Manycore Processors in the Nanvix OS Trabalho de Conclusão do Curso do Curso de Graduação em Ciências da Computação do Centro Tecnológico da Universidade Federal de Santa Catarina como requisito para ob- tenção do título de Bacharel em Ciências da Computação. Orientador: Prof. Márcio Bastos Castro, Dr. Coorientador: Pedro Henrique Penna, Me. Florianópolis 6 de dezembro de 2019 Ficha de identificação da obra elaborada pelo autor, através do Programa de Geração Automática da Biblioteca Universitária da UFSC. Souto, João Vicente An Inter-Cluster Communication Facility for Lightweight Manycore Processors in the Nanvix OS / João Vicente Souto ; orientador, Márcio Bastos Castro , coorientador, Pedro Henrique Penna , 2019. 92 p. Trabalho de Conclusão de Curso (graduação) - Universidade Federal de Santa Catarina, Centro Tecnológico, Graduação em Ciências da Computação, Florianópolis, 2019. Inclui referências. 1. Ciências da Computação. 2. Sistema Operacional Distribuído. 3. Camada de Abstração de Hardware. 4. Processador Lightweight Manycore. 5. Kalray MPPA-256. I. , Márcio Bastos Castro. II. , Pedro Henrique Penna. III. Universidade Federal de Santa Catarina. Graduação em Ciências da Computação. IV. Título. João Vicente Souto An Inter-Cluster Communication Facility for Lightweight Manycore Processors in the Nanvix OS Este Trabalho de Conclusão do Curso foi julgado adequado para obtenção do Título de Bacharel em Ciências da Computação e aprovado em sua forma final pelo curso de Graduação em Ciências da Computação. -

Parallel Processing with the MPPA Manycore Processor
Parallel Processing with the MPPA Manycore Processor Kalray MPPA® Massively Parallel Processor Array Benoît Dupont de Dinechin, CTO 14 Novembre 2018 Outline Presentation Manycore Processors Manycore Programming Symmetric Parallel Models Untimed Dataflow Models Kalray MPPA® Hardware Kalray MPPA® Software Model-Based Programming Deep Learning Inference Conclusions Page 2 ©2018 – Kalray SA All Rights Reserved KALRAY IN A NUTSHELL We design processors 4 ~80 people at the heart of new offices Grenoble, Sophia (France), intelligent systems Silicon Valley (Los Altos, USA), ~70 engineers Yokohama (Japan) A unique technology, Financial and industrial shareholders result of 10 years of development Pengpai Page 3 ©2018 – Kalray SA All Rights Reserved KALRAY: PIONEER OF MANYCORE PROCESSORS #1 Scalable Computing Power #2 Data processing in real time Completion of dozens #3 of critical tasks in parallel #4 Low power consumption #5 Programmable / Open system #6 Security & Safety Page 4 ©2018 – Kalray SA All Rights Reserved OUTSOURCED PRODUCTION (A FABLESS BUSINESS MODEL) PARTNERSHIP WITH THE WORLD LEADER IN PROCESSOR MANUFACTURING Sub-contracted production Signed framework agreement with GUC, subsidiary of TSMC (world top-3 in semiconductor manufacturing) Limited investment No expansion costs Production on the basis of purchase orders Page 5 ©2018 – Kalray SA All Rights Reserved INTELLIGENT DATA CENTER : KEY COMPETITIVE ADVANTAGES First “NVMe-oF all-in-one” certified solution * 8x more powerful than the latest products announced by our competitors**