Building Test Data from Real Outbreaks for Evaluating
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
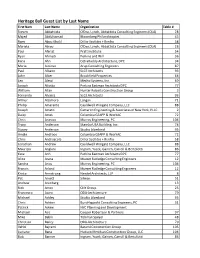
Guest List by Last Name.Xlsx
Heritage Ball Guest List by Last Name First Nam Last Name Organization Table # Steven Abbattista O'Dea, Lynch, Abbattista Consulting Engineers (OLA) 28 Majed Abdulsamad Bloomberg Philanthropies 43 Rami Abou Khalil Diller Scofidio + Renfro 58 Mariela Abreu O'Dea, Lynch, Abbattista Consulting Engineers (OLA) 28 Paul Aferiat Pratt Institute 54 Ryan Ahmadi Perkins and Will 36 Kana Ahn CetraRuddy Architecture, DPC 34 Maria Aiolova Arup Consulting Engineers 87 Paul Albano SLCE Architects 93 John Alber Brookfield Properties 64 Leo Alessi Mecho Systems, Inc. 69 Joseph Aliotta Perkins Eastman Architects DPC 77 William Allan Hunter Roberts Construction Group 3 Fernando Alvarez SLCE Architects 93 Arthur Alzamora Langan 71 Philip Amarante Cauldwell Wingate Company, LLC 88 Joseph Amato Cameron Engineering & Associates of New York, PLLC 2 Daisy Ames Columbia GSAPP & WorkAC 72 Chris Anastos Murray Engineering, PC 104 Tracy Anderson Skanska USA Building, Inc. 74 Stacey Anderson Studio Libeskind 95 Amale Andraos Columbia GSAPP & WorkAC 72 Chris Andreacola Diller Scofidio + Renfro 58 Jonathan Andrew Cauldwell Wingate Company, LLC 88 Maurizio Anglani Ingram, Yuzek, Gainen, Carroll & Bertolotti 86 Kate Anh Perkins Eastman Architects DPC 77 Alice Arana Mueser Rutledge Consulting Engineers 12 Sandra Arias Murray Engineering, PC 104 Francis Arland Mueser Rutledge Consulting Engineers 12 Krista Armstrong Handel Architects, LLP 8 Pat Arnett Silman 51 Andrew Aronberg 13 Rick Arroy CNY Group 25 Francesco Asaro ODA-Architecture 79 Michael Ashley Studio Libeskind 95 Chris Ashton BuroHappold Consulting Engineers, PC 31 Patrick Askew NYC Planning and Development Michael Aziz Cooper Robertson & Partners 97 Mike Babik Tishman Speyer 48 Christian Bailey ODA-Architecture 79 Vehbi Bajrami Barami Construction Group 105 Luciano Bana Hudson Meridian Construction Group, LLC 104 Bob Banner Ingram, Yuzek, Gainen, Carroll & Bertolotti 86 Zach Bark Studios Architecture 70 Alex Barmas DeSimone Consulting Engineers P.L.L.C. -

Report and Recommendation of the Lease Negotiation Committee on One Elk Street
Report and Recommendation of the Lease Negotiation Committee on One Elk Street June 10, 2021 David P. Miranda, Chair Michael J. McNamara Sandra D. Rivera House of Delegates Agenda Item #6 Whereas, the New York State Bar Association and The New York Bar Foundation are parties to a lease, as tenant and landlord respectively, for property at One Elk Street, Albany, New York, that ends on December 31, 2021; and Whereas, the Association and Foundation have concluded negotiations regarding future use of One Elk Street; and Whereas, the Association President signed a Memorandum of Understanding with the Foundation on May 20, 2021 calling for the transfer of One Elk Street from the Foundation to the Association subject to, inter alia, the approval of the Association's House of Delegates; Now, therefore, it is Resolved, that the House of Delegates hereby approves the May 20, 2021 Memorandum of Understanding, subject to the terms and conditions set forth therein and the provisions of this Resolution: Further resolved, that the Association President is authorized to conduct necessary due diligence, including but not limited to obtaining the written opinions of counsel regarding any tax implications, fundraising matters, and approval of the Attorney General concerning the proposed transaction; Further resolved, that the Association President is authorized to enter into a final agreement regarding the property transfer as outlined in the Memorandum of Understanding. Report of the Lease Negotiation Committee on the Status of the Lease at One Elk Street and Necessary Renovations David P. Miranda, Chair Michael J. McNamara Sandra D. Rivera 1 NEW Y O R K ST AT E B AR ASSO C I AT I O N One Elk Street, Albany, New York 12207 • PH 518.463.3200 • www.nysba.org INTRODUCTION The Association leases the Bar Center at One Elk Street from The New York Bar Foundation (Foundation). -
Tapestry Segmentation Reference Guide
Tapestry ™ Segmentation Reference Guide Seattle New York City Chicago Los Angeles Atlanta Dallas High Society Upscale Avenues Metropolis Solo Acts Senior Styles Scholars and Patriots Miami High Hopes Global Roots Family Portrait Traditional Living Factories and Farms American Quilt Esri’s Tapestry Segmentation divides US residential areas into 65 distinctive segments based on socioeconomic and demographic characteristics to provide an accurate, detailed description of US neighborhoods. Tapestry LifeMode Summary Groups Tapestry LifeMode Summary Segments in the 12 Tapestry™ Segmentation Groups in the US by County LifeMode Summary Groups are characterized by lifestyle and lifestage and share an experience High Society such as being born in the same time period or a Upscale Avenues trait such as affluence. Metropolis Solo Acts Senior Styles Scholars and Patriots High Hopes Global Roots Family Portrait Traditional Living Factories and Farms American Quilt Table of Contents IFC Tapestry LifeMode Summary Groups 50 27 Metro Renters 1 Segmentation 101 51 28 Aspiring Young Families 3 Tapestry Segmentation 52 29 Rustbelt Retirees 4 Tapestry Segmentation Methodology 53 30 Retirement Communities 7 Using Tapestry Segmentation to Grow Your Business 54 31 Rural Resort Dwellers 10 Success Story: Central Virginia Fire District 55 32 Rustbelt Traditions 11 Success Story: Arlington Food Assistance Center 56 33 Midlife Junction 12 Tapestry Segmentation Summary Groups 57 34 Family Foundations 13 Table 1: LifeMode Summary Groups by Segment Codes 58 35 International -

Nyc Green Codes Task Force a Report to Mayor Michael R
Executive Summary February 2010 NYC GREEN CODES TASK FORCE A REPORT TO MAYOR MICHAEL R. BLOOMBERG & SPEAKER CHRISTINE C. QUINN Katie Abbott/Rohit T. Aggarwala/Marc Albanese/ Michael C. Alfano/John Anderson/Robin Auchincloss/Jack Bailey/Dee Jay Bankhead/Kate Barton/Hilary Beber/Rick Bell/James Belluardo/ Bob Benazzi/Chris Benedict/Devon Berger/ Zachary Bernstein/Inder Bery/Michael Bierut/ Daniel Birkett/Karen Anne Blackman/Michael S. Blass/Les Bluestone/Catherine Bobenhausen/ Michael Bobker/Casimir Bognacki/Lee C. Bollinger/ Chris Boyd/Carlton A. Brown/Bill Browning/ Floris Keverling Buisman/Commissioner Amanda M. Burden/David Carlson/Stephen Cassell/James E. Cavanaugh/Scott Ceasar/Doug Chambers/ Kizzy M. Charles-Guzman/Stephanie Chiuminatto/ Nancy Clark/Ed Clerico/Amy Coffman/Daniel Colasuonno/Louis J. Coletti/Fiona Cousins/Elias F. Dagher/J. Christopher Daly/Marolyn Davenport/ Edward M. DePaola/Christopher Diamond/ Jonathan Dickinson/Markus Dochantschi/Susan Drew/Skye Duncan/Molly Dunham/Jody Durst/Jeff Eichenwald/Melissa Wright Ellis/Joseph Esposito/ Art Fasolino/Paul Fernandes/Bruce S. Fowle/ Robert F. Fox Jr./Scott Frank/Yetsuh Frank/Adam Freed/Charles Fritsch/Frederick Fucci/Peter Furst/ Shir Gale/Chris Garvin/Rocco Giannetti/ Henry Gifford/John J. Gilbert, III/Helen Gitelson/ Ed Goldberg/Tal Golumb/Piotr W. Grebski/Nicholas Grecco/Beth Greenberg/Jennifer Greenfeld/ Victoria Grimshaw/Ashok Gupta/Timothy Hauck/ Anne Haynes/ Robert Heintges/David W. Hess/ Adam Hinge/Commissioner Caswell F. Holloway/ Ellen Honigstock/Radley Horton/ Mark Husser/ Philip Jackier/Brook Jackson/Peter Jacobson/ Betsy Jenkins/Benjamin Jones/Ilana Judah/Susan D. Kaplan/Robert Kasdin/Daniel Kass/Greg Kelly/ Laurie Kerr/Jennifer Kinon/Hank Kita/Aaron Koch/ John Kovacs/Peter Krass/Joan Krevlin/Gary LaBarbera/Lorne LaMonica/Karen Lee/Val Lehr/ Richard Leigh/Richard Leland/Robert Leon/Murray L. -

Warner and Sony Set for Battle
01 15FEB Cover_v3_cover template 12/02/13 17:38 Page 1 07 9 776669 776136 THE BUSINESS OF MUSIC www.musicweek.com 15.02.13 £5.15 NEWS BIG INTERVIEW ANALYSIS 05 12 27 The legendary Sir George UK bosses Jason Iley and Mike Music Week talks to pop Martin accepts his MPG Smith discuss a promising year songwriting golden boy Outstanding Contribution Award ahead for the Universal label Wayne Hector Warner and Sony set for battle PARLOPHONE BUYOUT WILL DRAMATICALLY CLOSE THE GAP BETWEEN RIVAL MAJOR LABELS ANALYSIS market headed by Universal with I BY PAUL WILLIAMS a 35.0% share and Sony second with 20.8%. arner’s £487m buyout However, had Warner W of Parlophone Label controlled the artists and Group (PLG) will put repertoire coming from PLG in it within touching distance of 2011 and 2012 it would have Sony as Universal’s biggest rival claimed around 17.5% of the in the UK. albums market, just one and a That’s according to exclusive half percentage points behind Music Week research, which Sony, while it would have been suggests the addition of around the same distance behind repertoire from the likes of Sony on singles with a market Coldplay, David Guetta and Pink share of about 19.5%. Floyd will sharply narrow the On the albums side, the most market share race for second obvious powerful addition to its place. However, Universal could ranks will be Coldplay whose end up being 80% or more ahead Mylo Xyloto was EMI’s second of both rival players. -

A Masterpiece M +++++ Mojomagazine U S I C W E E K
Cover11.01.13_cover template 07/01/13 15:49 Page 1 1 0 6 3 1 6 7 7 9 6 6 6 7 7 9 THE BUSINESS OF MUSIC www.musicweek.com 11.01.13 £5.15 A masterpiece +++++ Mojo Magazine Project1_Layout 1 07/01/2013 15:48 Page 1 the multi award winning album Re-released on January 28th On multiple formats DELUXE 3 CD DIGI PACK ;:9876548382:18350/.:/-:4,8:/30+0.6*:6*)(7 ;:'.38*86582:*018:&83-/376.%85:-3/7:4,8:$#"":4/(3 ;:'.38*86582:46!85:-3/7:4,8:9(7/(35:58550/.5 e '9:':: $$0.* ;:9876548382:18350/.:/-:4,8:/30+0.6*:6*)(7 ;:'.38*86582:*018:&83-/376.%85:-3/7:4,8:$#"":4/(3 ;:'.38*86582:46!85:-3/7:9(7/(35:58550/.5 ;:9/(+,5:6.2:(446!85:-3/7:4,8::38055(8 ;::/-:,8:9/58)(2:0*7 :): 0%,68*:/**0.5 ;:0.*: e 9 9: ' :/.: e : e ':': : e 9 9:6.2 DELUXE 18350/.5:6*5/:6160*6)*8: e **:18350/.5:6160*6)*8:-/3:5438670.+ ,8:6*)(7:0**:)8:*6(.%,82:04, 6:-(**:763!840.+::&3/7/40/.6*:%67&60+. 6%8)//!%/7*884//2 6% 0.%*(20.+::0.4831085:6.2:.640/.6* 884//276%%/7 :621834050.+:&3855:625/.*0.8 FM MW Inside Cover 2 indd 1 07/01/2013 15:32 Cover_v3_cover template 08/01/13 19:22 Page 1 01 9 776669 776136 THE BUSINESS OF MUSIC www.musicweek.com 11.01.13 £5.15 NEWS BIG INTERVIEW ANALYSIS 02 10 12 Newly-promoted Universal Petula Clark discusses seven Music Week’s six page Music International boss Max decades in showbiz - and what it’s investigation into last Hole on his ambitions for EMI like to meet Elvis and John Lennon year’s record sales BMG: we’re still majorly hungry MUTE AND VIRGIN BOUGHT OVER CHRISTMAS - BUT THE RIGHTS GROUP’S NOT DONE YET ACQUISITIONS A bigger shock was BMG’s acquisition of Mute Records, the David Bowie announced a TALKING MUTE I BY TIM INGHAM shock new album this label sold by founder Daniel week - but his catalogue is Mute founder Daniel Miller up for grabs in the licensed back the label’s name he battle to acquire Miller to EMI in 2002 for £23m. -

{PDF EPUB} Back to Black: Amy Winehouse's Only Masterpiece By
Read Ebook {PDF EPUB} Back To Black: Amy Winehouse's Only Masterpiece by Donald Brackett Back to Black by Donald Brackett is one of the best books about music I have ever read and for many reasons. First, no one can really sing the blues unless they have the blues, and this book captures Amy Winehouse’s meteoric rise to the top in musical terms and expresses her tragic story only insofar as it was part of what made her music the best we have heard from a brand new talent in decades.4.6/5(3)Format: Paperback, IllustratedAuthor: Donald BrackettBack to Black: Amy Winehouse's Only Masterpiece by Donald ...https://www.barnesandnoble.com/w/back- to-black-donald-brackett/1130529759Nov 01, 2016 · In this refreshing book which focuses solely on Amy Winehouse's musical artistry, stylistic influences, and creative collaborations with great producers and musicians, instead of her personal problems Donald Brackett explores pertinent questions about the importance of pop music in contemporary culture. In this incisive and fascinating study of Amy Winehouse's second, and last, album (released in 2006), Back to Black , he opens the door not only …ISBN: 1617136298Pages: 272Author: Donald BrackettFormat: PaperbackVideos of Back To Black: Amy Winehouse's Only Masterpiece By Do… bing.com/videosWatch video4:01Keith Urban "Wasted Time." Best.Cover.Ever. -Final Duet793K viewsDec 22, 2017YouTubeBest.Cover.Ever.Watch video5:52Beach Boys, Beatles, Beyoncé top Rolling Stone's new 500 Greatest Album…76 views7 months agoYouTubeWazza95Watch video5:52Beach Boys, Beatles, Beyoncé top Rolling Stone's new 500 Greatest Album…22 views6 months agoYouTubeThe Daily BestWatch video7:20Leonard Cohen - Hallelujah (Live In London)184M viewsOct 3, 2009YouTubeLeonardCohenVEVOSee more videos of Back To Black: Amy Winehouse's Only Masterpiece By Donald BrackettBack to Black: Amy Winehouse's Only Masterpiece - Kindle ...https://www.amazon.com/Back-Black-Winehouses-Only...Back to Black by Donald Brackett is one of the best books about music I have ever read and for many reasons. -
Downtown Master Plan.Pdf
Weaving the Tapestry of the City THE LAWRENCE GROUP TOWN PLANNERS + ARCHITECTS IN ASSOCIATION WITH KIMLEY-HORN & ASSOCIATES ROSE & ASSOCIATES DRAFT COLEJENEST & STONE 06.14.2007 partanburg SDowntown Acknowledgements Spartanburg City Council Lead Agency for the Master Plan Mayor William Barnet, III City of Spartanburg Economic Development Mayor Pro-Tem Joe Spigner , District 1 Julie Franklin, Director Council Member Renee Cariveau, District 2 Cate Ryba, Coordinator Council Member Robert Reeder, District 3 Anna Poole, Assistant Council Member Junie White, District 4 Council Member Kenneth Smith, District 5 Council Member, Linda Dogan, District 6 Downtown Plan Advisory Committee Philip Belcher, Mary Black Foundation Linda Bilanchone, Preservation Trust Royce Camp, Cantrell Wagons Shannon Emory, Carolina Gallery Freddy Foster, Sonny’s Brick Oven Pizza Darrin Goss, Wofford College We would like to thank the City of Ben Graves, Johnson Development Associates Spartanburg and the hundreds of citizens, Mike Henthorn, Beeson Henthorn Development property owners, businesses, and institutions Albert Jolly, Jr., Jolly & Associates Steve Jones, Spartanburg Memorial Auditorium who participated in this exciting downtown Julia Lyons Brooks, United Way of the Piedmont planning process. This Plan, as a reflection of Rev. Lewis A. Mills, Greater Hopewell Baptist Church the community’s aspirations, is intended to Harry Price, Price’s Menswear guide the visionary leaders of Spartanburg for Lee Raines, City of Spartanburg Police Department generations to come. Ricky Richardson, Citigroup SmithBarney Tim Satterfield, Spartanburg Downtown Association Project Team Ron Smith, McMillan Smith & Partners Architects Betsy Teter, Hub-Bub The Lawrence Group Mary Thomas, Spartanburg County Foundation Craig Lewis, AICP, CNU, LEED AP Betsy Fleming, Converse College Dave Malushizky, AIA, LEED AP David Walters, RIBA Downtown Plan Staff Team Paul Hubbman Mark Scott, City Manager Beth Weast, LEED AP Evelyn Tice, Deputy City Manager John Cock, AICP Ed Memmott, Assistant City Manager S. -
Community Tapestry Handbook
Community™ Tapestry™ Handbook Industrious Urban Fringe Connoisseurs The Elders Community Tapestry LifeMode Summary Groups by County Segments in the 12 Community™ Tapestry™ LifeMode summary groups are characterized by lifestyle and lifestage and share an experience such as being born in the same time period or a trait such as affluence. Table of Contents IFC Community Tapestry LifeMode Summary Groups 51 30 Retirement Communities by County 52 31 Rural Resort Dwellers 1 Segmentation 101 53 32 Rustbelt Traditions 3 Community Tapestry 54 33 Midlife Junction 4 Community Tapestry Methodology Statement 55 34 Family Foundations 5 Using Community Tapestry to Enhance Your Business 56 35 International Marketplace 10 Community Tapestry Summary Groups 57 36 Old and Newcomers 11 Table 1 LifeMode Groups by Segment Codes 58 37 Prairie Living 12 Community Tapestry LifeMode Group Descriptions 59 38 Industrious Urban Fringe 15 Income Range of the LifeMode Groups 60 39 Young and Restless 16 Table 2 Urbanization Groups by Segment Codes 61 40 Military Proximity 17 Community Tapestry Urbanization Group Descriptions 62 41 Crossroads 20 Urbanization Levels of the Urbanization Groups 63 42 Southern Satellites 21 Segment Legend 64 43 The Elders 22 01 Top Rung 65 44 Urban Melting Pot 23 02 Suburban Splendor 66 45 City Strivers 24 03 Connoisseurs 67 46 Rooted Rural 25 04 Boomburbs 68 47 Las Casas 26 05 Wealthy Seaboard Suburbs 69 48 Great Expectations 27 06 Sophisticated Squires 70 49 Senior Sun Seekers 28 07 Exurbanites 71 50 Heartland Communities 29 08 Laptops and -

Oroville Retail Leakage Analysis FINAL R1 06-15-07
Oroville Taxable Retail Potential Analysis Analysis of Retail Potential and Leakage in the City of Oroville, California June, 2007 For questions or comments, please contact Warren Jensen at the following organization: Center for Economic Development California State University, Chico Chico, California 95929-0765 Phone: 530-898-4598 Fax: 530-898-4734 www.csuchico.edu/cedp/ Oroville Taxable Retail Potential Analysis Table of Contents Page Summary of Results 1 The Oroville Retail Market Area 1 The Retail Spending Model 3 Potential Taxable Sales and Leakage 7 Sources of Retail Leakage (What Does Retail Leakage Mean?) 10 Psychographic Profile of the Oroville Market Area 11 Appendix A: Retail Sector Definitions 15 Appendix B: ESRI Consumer Spending Estimates for the Oroville Market Area and California 20 Appendix C: ESRI Consumer Spending by Commodity Matched to Retail Sectors Available for Analysis 26 Appendix D: Psychographic Profile Category Descriptions 29 Center for Economic Development California State University, Chico Oroville Taxable Retail Potential Analysis Summary of Results There was a net taxable sales leakage of $195 million in the city of Oroville in 2006. This leakage occurred within sixty-two retail sectors: twelve that could be analyzed directly plus fifty additional sectors where disclosure of the data would have presented issues with business confidentiality. Leakage in a particular sector could be due to people in the Oroville Retail Market Area spending money in other communities, spending money in the market area outside of Oroville’s corporate boundary, less household demand for specific retail goods compared to the average for California consumers (adjusted for income differential), or substituting spending in one retail sector for spending in a competing sector. -

Do. Make. Innovate. Reinvent the Future
2019 Do. Make. Innovate. ANNUAL REPORT Reinvent the Future. BOARD OF TRUSTEES PRESIDENT’S COUNCIL ACADEMIC LEADERSHIP Catherine A. Allen Nada Anid, Ph.D. Junius J. Gonzales, M.D., M.B.A. Founder and CEO Vice President for Strategic Communications Provost and Vice President for Academic Affairs The Santa Fe Group and External Affairs Maria R. Perbellini, M.Arch. Philip Fasano (B.S. ‘80) Jerry Balentine, D.O., FACOEP, FACEP School of Architecture and Design, Dean Chief Executive Officer Dean, College of Osteopathic Medicine Daniel Quigley, Ph.D. Bay Advisors, LLC Vice President, Health Sciences and College of Arts and Sciences, Dean Medical Affairs Peter A. Ferentinos Babak Beheshti, Ph.D. Chief Executive Officer Catherine R. Flickinger, J.D. College of Engineering and Qualco Inc. General Counsel and Vice President Computing Sciences, Dean for Human Resources Jess Boronico, Ph.D. Dan Ferrara (D.O. ‘86) School of Management, Dean Northeast Regional President Junius J. Gonzales, M.D., M.B.A. Alteon Health Provost and Vice President for Academic Affairs Jerry Balentine, D.O., FACOEP, FACEP Dean, College of Osteopathic Medicine Itzhak Fisher (B.S. ‘82) Barbara J. Holahan, CPA, M.B.A. Vice President, Health Sciences Founder and General Partner Vice President for Financial Affairs, and Medical Affairs Pereg Ventures Chief Financial Officer and Treasurer Gordon Schmidt, Ph.D. Henry C. Foley, Ph.D. Patrick Minson, M.B.A., M.P.A. School of Health Professions, Dean President Vice President for Development and New York Institute of Technology Alumni Relations Henry Iervolino (B.S. ‘82) Suzanne Musho, AIA, NCARB President and CEO Vice President and Chief Architect for Triton Capital Management, LLC Capital Planning and Facilities Management Michael J. -

Resum De Gestió 2013 Juny 2014 Índex
Resum de gestió 2013 Juny 2014 Índex Què és TMB? 6 Línies estratègiques de TMB 9 Òrgans d’administració Òrgans d’administració i gestió de TMB 12 i gestió de TMB Consell d’Administració de TB i FMB 13 Comissió executiva de TMB 14 El més destacat Ampliació de l’oferta en les línies de la fase 1 de la nova xarxa de bus 16 de l’any Segona fase de la nova xarxa d’autobusos amb cinc línies més 17 Posada en servei dels primers autobusos híbrids biarticulats a Barcelona 22 Projecte Retrofit GNC: transformació d’autobusos propulsats amb GNC en híbrids 24 Posada a prova del primer bus elèctric pur de la flota de TMB 25 Unificació de les línies 112 i 185 26 Conveni amb B:SM per a la cobertura d’esdeveniments a l’Anella Olímpica de Montjuïc 27 TMB rep les certificacions ISO 9001 i UNE-EN 13816 de qualitat per a l’Àrea Operativa de Metro 28 Obertura de nous vestíbuls adaptats a les estacions Bogatell (L4) i Virrei Amat (L5) 30 TMB és el primer operador europeu acreditat com a avaluador independent de seguretat ferroviària 31 Acord per prorrogar dos anys el conveni col·lectiu de metro fins al final de 2015 32 TMB assumeix la presidència d’ALAMYS (metro) 32 Signatura del contracte programa per a l’any 2013 33 Nivells màxims de valoració dels serveis de metro i bus 34 El Bus Turístic, guardonat amb un certificat d’excel·lència de TripAdvisor 36 El web corporatiu de TMB obté la certificació d’accessibilitat universal AA 36 Hola BCN!: la nova marca de les targetes de viatge per a visitants i turistes 37 TMB, la mobilitat i les ciutats 39 intel·ligents La mobilitat sostenible, Passatgers transportats per TMB 41 pilar de l’organització.