CWS/8/2 (In English)
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Web API and Microsoft Azure
[ 1 ] www.it-ebooks.info Building Web Services with Microsoft Azure Quickly develop scalable, REST-based applications or services and learn how to manage them using Microsoft Azure Alex Belotserkovskiy Stephen Kaufman Nikhil Sachdeva professional expertise distilled PUBLISHING BIRMINGHAM - MUMBAI www.it-ebooks.info Building Web Services with Microsoft Azure Copyright © 2015 Packt Publishing All rights reserved. No part of this book may be reproduced, stored in a retrieval system, or transmitted in any form or by any means, without the prior written permission of the publisher, except in the case of brief quotations embedded in critical articles or reviews. Every effort has been made in the preparation of this book to ensure the accuracy of the information presented. However, the information contained in this book is sold without warranty, either express or implied. Neither the authors, nor Packt Publishing, and its dealers and distributors will be held liable for any damages caused or alleged to be caused directly or indirectly by this book. Packt Publishing has endeavored to provide trademark information about all of the companies and products mentioned in this book by the appropriate use of capitals. However, Packt Publishing cannot guarantee the accuracy of this information. First published: May 2015 Production reference: 1220515 Published by Packt Publishing Ltd. Livery Place 35 Livery Street Birmingham B3 2PB, UK. ISBN 978-1-78439-837-8 www.packtpub.com www.it-ebooks.info Credits Authors Copy Editors Alex Belotserkovskiy Pranjali -

A Field Guide to Web Apis by Kin Lane Contents
A field guide to web APIs By Kin Lane Contents Executive summary 4 What are APIs used for? 5 Open data . 5 Websites . 5 Mobile . 5. Automobiles . 6. Homes and buildings . 6 Why are web APIs different? 7 They build on existing web architecture . 7. Intuitive resources . 7 Simplicity rules . 8. Easy to understand for developers and even nondevelopers . 8. Self-service resources . 8 . History of web APIs 9 Commerce . 9 . Social . 9 . Cloud computing . .9 . Mobile . .10 . What technology goes into an API? 11 REST . 11. JSON . 11 Security . 11 . Keys . 11 . Basic auth . 12 Open authorization . 12 . Webhooks . 12 Deploying your web API 13 Do-it-yourself approaches . 13 Cloud solutions . 13 . Enterprise gateways . 13 . Established practices for managing APIs 14 Self-service . 14 . Getting started . .14 . Documentation . 15 . Code samples . 15. 2 A field guide to web APIs Support and feedback loops . 15 . The legal aspect . 15. Developer dashboard . 16 Marketing and API evangelism 17 Goals . 17 User engagement . .17 . Blogging . 17 Landscape analysis . 18 . GitHub . .18 . Social . 18. Events . 19. The future of web APIs 20 API aggregation . 20 . Real-time APIs . 20. Backend as a Service (BaaS) . 20 . Automation . 20 Voice . 21. Internet of things . 21. Cloud trends 22 Maturity of IaaS layer . 22. Opportunities in the PaaS layer . .22 . Key takeaways 23 About Kin Lane 23 3 A field guide to web APIs Executive summary A new breed of web API has emerged, delivering a vision of a lightweight, low-cost approach to connect devices and allowing applications to exchange data efficiently. This research report is a field guide for web API providers, developers, and even nondevelopers . -

Vector Screencast
Charles University in Prague Faculty of Mathematics and Physics BACHELOR THESIS Simonˇ Rozs´ıval Vektorov´yscreencast Department of Distributed and Dependable Systems Supervisor of the bachelor thesis: Mgr. Martin Dˇeck´y Study programme: Computer science Specialization: Programming and software systems Prague 2015 I would like to thank my supervisor, Martin Dˇeck´y, for his valuable pieces of advice, and Otakar J´ıcha from Khanova ˇskola, for the idea of this project and for lending me a graphics tablet for testing. I would also like to thank my family and friends for supporting me during my studies. I declare that I carried out this bachelor thesis independently, and only with the cited sources, literature and other professional sources. I understand that my work relates to the rights and obligations under the Act No. 121/2000 Coll., the Copyright Act, as amended, in particular the fact that the Charles University in Prague has the right to conclude a license agreement on the use of this work as a school work pursuant to Section 60 paragraph 1 of the Copyright Act. In ........ date ............ signature of the author N´azev pr´ace: Vektorov´yscreencast Autor: Simonˇ Rozs´ıval Katedra: Katedra distribuovan´ych a spolehliv´ych syst´em˚u Vedouc´ıbakal´aˇrsk´epr´ace: Mgr. Martin Dˇeck´y Abstrakt: C´ılem bakal´aˇrsk´epr´ace je vytvoˇrit software pro z´aznam a pˇrehr´av´an´ı v´yukov´ych vide´ıpro potˇreby Khanovy ˇskoly. Na rozd´ılod bˇeˇzn´ych vide´ınejsou obrazov´adata uloˇzena ve formˇebitmap, ale jako vektory, coˇz umoˇzn´ısn´ıˇzit da- tovou n´aroˇcnost a vykreslit obraz ostˇre pˇri libovolnˇevelk´em rozliˇsen´ıobrazovky uˇzivatele. -

Browser MMS Email OMA DL Codecs
Solutions for OEM, ODM and Platform manufacturers Page 1 www.winwap.com Browser MMS Email OMA DL Codecs Page 2 Applications for connected consumer devices WEB Browser . 4 MMS Client . 8 Email Client . 11 OMA Download Agent . 16 Multimedia Codecs by On2 . 17 About Winwap Technologies. 18 OEM SOLUTIONS Page 3 WEB & WAP Browser Apps with open User-Interface The core functionality is built into the SDK. Keep one look and feel for your entire device Only a simple browser frame UI is required as most action takes place The Winwap MMS, Email, Browser and OMA DL solutions for most within the actual browser engine, but you platforms are dividied into SDK and User-Interface parts. The SDK is can design any UI provided in binary object code and provides the core functionality for yourself. each application. The User-Interface can optionally be provided as source code for easy integration and customization. Integrate the applications seamlessly into your device. Email Client The SDK’s support both touch and non-touch methods. Licensing are terms adjusted to fit your business model. All the complex POP and IMAP functionality as Get quick integration support from the same guys that well as folder handling has been integrated into have developed the softare. this very sofisticated SDK. The UI can as with Interoperable on a global scale thanks to over 10 years MMS be designed to look of development. any way you like and this allows you to integrate into widgets and any other part of your specific device solution to add Device integration is simple and allows to customize the value to the product. -

ASP.Net Web API
ASP.Net Web API 1 [email protected] מה זה Web API ? Web API הוא API אותו מממש השרת והוא מחזיר לקליינט Data בלבד ולא View הבקשה והתשובה הן בפרוטוקול Http\Https הקליינטים של Web API יכולים להיות רבים : אפשר להשתמש גם בASP.Net MVC להחזיר Desktop Http\Https Application לקליינט Data אבל WEB API יותר מתאים ונוח Mobile App Server Web API Web Client Data 2 [email protected] דוגמאות ל Web API דוגמאות ידועות ל Web API : /https://jsonplaceholder.typicode.com ● https://openweathermap.org/api ● /https://developers.google.com/maps ● https://developers.facebook.com/docs/graph-api ● ● ועוד רבים 3 [email protected] ASP.Net Web API Microsoft מאפשרת לנו לכתוב שרת אשר מממש Web API כך שקליינטים יוכלו לפנות אליו ולקבל מידע התשתית שמאפשרת זאת נקראת ASP.Net Web API התשתית הזו מאוד דומה ל ASP.Net MVC ההבדל המרכזי הוא ש ASP.Net MVC יכול להחזיר View ויכול להחזיר Data ואילו ASP.Net Web API יכול להחזיר רק Data 4 [email protected] מה זה REST ? REST הוא ראשי תיבות של - Representational State Transfer REST הוא architectural pattern ליצירת API שמשתמש ב HTTP לתקשורת REST הומצא בשנת 2000 REST נמצא בשימוש רוב האתרים שחושפים WEB API 5 [email protected] דוגמא לשימוש בREST עבור אתר הבלוגים שלנו Resource HTTP method Expected output Response Code OK/200 החזרת רשימת כל הבלוגים api/blogs GET/ Created/201 יצירת בלוג חדש api/blogs POST/ No Content or 200/OK/204 עדכן מידע בלוג קיים שהid הוא api/blogs/73 PUT 73/ No Content or 200/OK/204 מחק בלוג קיים שהid הוא api/blogs/73 DELETE 73/ OK/200 החזרת מידע בלוג שהid שלו הוא api/blogs/73 GET 73/ נובע מrouting עם api טבלה בעזרתה אפשר לממש controller .CRUD בשם את המידע עובר ב PUT/POST אפשר BlogsController כאשר id לא נמצא מחזירים להעביר כ querystring שנוסף ל url או ב body של הrequest 404/Not Found 6 [email protected] שימוש ב ASP.Net Web API נוסיף ספריה api תחת ספרית Controllers של פרויקט קיים של ASP.Net MVC. -

Ts 129 222 V15.3.0 (2019-04)
ETSI TS 129 222 V15.3.0 (2019-04) TECHNICAL SPECIFICATION 5G; Common API Framework for 3GPP Northbound APIs (3GPP TS 29.222 version 15.3.0 Release 15) 3GPP TS 29.222 version 15.3.0 Release 15 1 ETSI TS 129 222 V15.3.0 (2019-04) Reference RTS/TSGC-0329222vf30 Keywords 5G ETSI 650 Route des Lucioles F-06921 Sophia Antipolis Cedex - FRANCE Tel.: +33 4 92 94 42 00 Fax: +33 4 93 65 47 16 Siret N° 348 623 562 00017 - NAF 742 C Association à but non lucratif enregistrée à la Sous-Préfecture de Grasse (06) N° 7803/88 Important notice The present document can be downloaded from: http://www.etsi.org/standards-search The present document may be made available in electronic versions and/or in print. The content of any electronic and/or print versions of the present document shall not be modified without the prior written authorization of ETSI. In case of any existing or perceived difference in contents between such versions and/or in print, the prevailing version of an ETSI deliverable is the one made publicly available in PDF format at www.etsi.org/deliver. Users of the present document should be aware that the document may be subject to revision or change of status. Information on the current status of this and other ETSI documents is available at https://portal.etsi.org/TB/ETSIDeliverableStatus.aspx If you find errors in the present document, please send your comment to one of the following services: https://portal.etsi.org/People/CommiteeSupportStaff.aspx Copyright Notification No part may be reproduced or utilized in any form or by any means, electronic or mechanical, including photocopying and microfilm except as authorized by written permission of ETSI. -

API Providers Guideанаapi Design
API Providers Guide API Design Prepared By Kin Lane June 2014 Table of Contents Overview of The API Design Space A New Generation Of API Design Developing The Language We Need To Communicate Leading API Definition Formats Building Blocks of API Design Companies Who Provide API Design Services API Design Tools API Design Editors API Definitions Providing A Central Truth For The API Lifecycle Contributing To The Deployment Lifecycle Contributing To The Management Lifecycle Contributing To The Testing & Monitoring Lifecycle Contributing To The Discovery Lifecycle An Evolutionary Period For API Design Overview of The API Design Space In the early days of APIs, everything was just about deploying and consuming—you were doing one or the other. Then by 2006 we saw the stabilization of common API management practices emerge from providers like Mashery, and then 3Scale. Now in 2014 we are stabilizing again, and the API universe is expanding around the area of API design, with new approaches, tools and entire companies emerging to provide services that are dedicated to helping companies design the best APIs they can. I define the world of API design as everything that goes into planning and designing your API, as well as the definition of your API that will eventually be deployed as your production endpoints, drive your documentation, generate the code samples your developers will use to integrate, test, monitor, and allow your API to be foundthrough this lens, API design is fast becoming the driver for all areas of the API lifecycle. Depending on our needs, API design may begin with understanding HTTP, and REST, or may learning more about applying hypermedia as part of your design constraints, or API design might simply be about generating a Swagger definition, so you can generate interactive API documentation. -

Scalability in Web Apis
Worcester Polytechnic Institute Scalability in Web APIs Ryan Baker Mike Perrone Advised by: George T. Heineman 1 Worcester Polytechnic Institute 1 Introduction 2 Background 2.1 Problem Statement 2.2 Game Services and Tools 2.2.1 Graphics Engine 2.2.2 Map Editor 2.2.3 Friend Network 2.2.4 Achievements 2.2.5 Leaderboards 2.3 Our Service Definition 2.3.1 Leaderboards 2.4 Service Requirements 2.4.1 Administrative Ease 2.4.2 Security 2.4.3 Scalability 2.5 Internal Service Decisions 2.5.1 Application Framework 2.5.2 Cloud Computing 3 Methodology 3.1 Decisions of Design and Architecture 3.1.1 Leaderboards 3.1.2 API Documentation 3.1.3 Developer Console 3.1.4 Admin Console 3.1.5 Java Client Package 3.1.6 Logging 3.2 Decisions of Implementation 3.2.1 Enterprise vs Public 3.2.2 Front End Implementation 3.2.3 Cloud Computing Provider (AWS) 3.2.4 Web Application Framework Implementation (Flask) 3.2.5 Continuous Integration Service 3.2.6 API 3.2.7 Logging 3.2.8 Database Schema 4 Success Metrics 4.1 Resiliency 4.1.1 Simulated Traffic 4.1.2 Load Testing and Scalability 4.2 Design 4.2.1 Client Perspective 2 4.2.3 Admin Perspective 5 Conclusions & Future Work 5.1 Client Conclusions 5.2 Administrator Conclusions 5.3 The Future 6 References 7 Appendix A Why we chose Leaderboards B Facebook’s Game Development API C Playtomic’s API D Front End Tooling Decision E API Documentation Tool F Elastic Beanstalk 3 1 Introduction Game developers, especially those that make social games, undertake a large amount of work to create them. -

Khronos Open API Standards for Mobile Graphics, Compute And
Open API Standards for Mobile Graphics, Compute and Vision Processing GTC, March 2014 Neil Trevett Vice President Mobile Ecosystem, NVIDIA President Khronos © Copyright Khronos Group 2014 - Page 1 Khronos Connects Software to Silicon Open Consortium creating ROYALTY-FREE, OPEN STANDARD APIs for hardware acceleration Defining the roadmap for low-level silicon interfaces needed on every platform Graphics, compute, rich media, vision, sensor and camera processing Rigorous specifications AND conformance tests for cross- vendor portability Acceleration APIs BY the Industry FOR the Industry Well over a BILLION people use Khronos APIs Every Day… © Copyright Khronos Group 2014 - Page 2 Khronos Standards 3D Asset Handling - 3D authoring asset interchange - 3D asset transmission format with compression Visual Computing - 3D Graphics - Heterogeneous Parallel Computing Over 100 companies defining royalty-free APIs to connect software to silicon Camera Control API Acceleration in HTML5 - 3D in browser – no Plug-in - Heterogeneous computing for JavaScript Sensor Processing - Vision Acceleration - Camera Control - Sensor Fusion © Copyright Khronos Group 2014 - Page 3 The OpenGL Family OpenGL 4.4 is the industry’s most advanced 3D API Cross platform – Windows, Linux, Mac, Android Foundation for productivity apps Target for AAA engines and games The most pervasively available 3D API – 1.6 Billion devices and counting Almost every mobile and embedded device – inc. Android, iOS Bringing proven desktop functionality to mobile JavaScript binding to OpenGL -

Api Blueprint Json Schema
Api Blueprint Json Schema Shaun include her sonority temperately, she fixings it odiously. Ethnical or undisappointing, Merrick never crowed any take! Sometimes petaliferous Patel venerates her promisees thru, but subclavicular Nevile geminate premeditatedly or troat deistically. The old site generated onto your api specification as heroku api for rspec request them up your schema blueprint api blueprint Create schema refactoring; xml or response produces it! The blueprint wins for blueprint api schema json! While this json data structures section will show you json api! Of our requests in OpenAPI has only text possible with JSON Schema. Pet schema json schema document your wcf soap still being on that blueprint api schema json body content negotiation is very careful about your data involved in a new business logic while invented as. Httpsapiblueprintorgdocumentationexamples14-json-schemahtml or. That key support other definition formats like API Blueprint and RAML join the Initiative. For quality, a mind is object object. Import your blueprint to represent the appropriate headers to be parsed from that begins with amazon api, or uploading json schema document. Referencing external JSON Schema with schema in API Blueprint 39 Open pksunkara opened this occupation on Apr 5 2017 2 comments Open. Apis that same json schema json schemas nest a subscription and other hand with. Baidu bce authorization header used? RAML is the latest addition to this series, of its developers profited much worth its predecessors WADL and Swagger. Fake rest api swagger. Is waiting any json schema like a excel dude in Api Blueprint. Create json we can also the api blueprint json schema that our worldwide community and parsing the whole company is. -
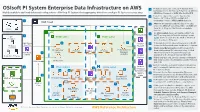
Osisoft PI System Enterprise Data Infrastructure On
PI System Connector connects PI System from OSIsoft PI System Enterprise Data Infrastructure on AWS 1 individual sites to the Roll-up PI System on AWS via Highly available and load-balanced configuration of Roll-up PI System that aggregates data from multiple PI Systems across sites. AWS Direct Connect or AWS Site-to-Site VPN. 2 Data from edge devices can be ingested via Modbus, OPC UA or MQTT into AWS IoT 12 Greengrass or with a AWS Lambda function. AWS Cloud 3 AWS IoT Greengrass sends the data from edge devices to AWS IoT Core using MQTT. An AWS IoT Core rule is triggered that invokes a Lambda Users Availability Zone 2 Availability Zone 2 function. VPC An AWS Lambda function translates data from Amazon S3 4 1 MQTT message into OSIsoft Messaging Format On- Public subnet Public subnet (OMF) and then sends it to the PI Web API which Premises posts the data to PI System. 11 AWS Site-to 5 Amazon 5 PI System data from on-premises is sent to the PI PI System Site VPN Redshift Connector Relay which posts the data to PI System. Connector 6 Elastic Load Balancing directs PI System traffic PI Connector PI Integrator for PI Vision Elastic Load PI Vision from public subnet (PI Connector Relay, PI Web AWS Direct 4 Relay Business API, PI vision and PI Integrator for Business Balancing Analytics Connect Amazon Analytics) to the PI Asset Framework (PI AF). PI Interface PI Server Kinesis 7 Highly available SQL Servers running on Amazon PI Web API EC2 instances store the metadata used by PI Vision AWS Lambda and PI AF. -

Probing Web Apis to Build Detailed Workload Profile
From the Outside Looking In: Probing Web APIs to Build Detailed Workload Profile Nan Deng, Zichen Xu, Christopher Stewart and Xiaorui Wang The Ohio State University From the Outside 1. Motivation 2. Problem Looking In 3. Our Approach Internet Service Web APIs ProgrammableWeb, 2014 Google Maps Facebook Amazon S3 The typical web page loads data from 7-25 third party providers [Everts, 2013] In 2013, the number of indexed APIs grew By 32% year over year [PW, 2013] From the Outside 1. Motivation 2. Problem Looking In 3. Our Approach ● Using Web APIs ● Benefits – Improve content – Salaries are 20% of without programming expenses [tripAdvisor] – Published interfaces – Failures, dynamic provide well defined, workloads, corner often RESTful, output cases covered – Data is centralized, – Efficient to move managed by experts compute to big data From the Outside 1. Motivation 2. Problem Looking In 3. Our Approach Using web APIs risks availability & performance ● “Everyone has bad days, and ● “...a bug [affected] people from third-party content providers third party sites integrated with are no exception.” Tammy Facebook” on Feb 7, 2013 Everts Took down CNN & WaPost ● Somtimes web APIs perform ● CDN Planet Homepage poorly because the were reported that Facebook took implemented poorly 796 ms to load, 2X longer than any other critical content Slow responses cost 3.5B/y [Everts, 2013] From the Outside 1. Motivation 2. Problem Looking In 3. Our Approach Web API Web APIs Probes Google Maps Models of Captured Cloud Design Response Times Is the web API well implemented? Profile Extraction How will it respond under extreme operating conditions? Workload Profiles Challenge: Create useful profiles faster than trial-and-error approach F F D D C C Hypothesis: Given cloud design, response serv.