Blob Detection Achieving Scale Covariance
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Scale Invariant Interest Points with Shearlets
Scale Invariant Interest Points with Shearlets Miguel A. Duval-Poo1, Nicoletta Noceti1, Francesca Odone1, and Ernesto De Vito2 1Dipartimento di Informatica Bioingegneria Robotica e Ingegneria dei Sistemi (DIBRIS), Universit`adegli Studi di Genova, Italy 2Dipartimento di Matematica (DIMA), Universit`adegli Studi di Genova, Italy Abstract Shearlets are a relatively new directional multi-scale framework for signal analysis, which have been shown effective to enhance signal discon- tinuities such as edges and corners at multiple scales. In this work we address the problem of detecting and describing blob-like features in the shearlets framework. We derive a measure which is very effective for blob detection and closely related to the Laplacian of Gaussian. We demon- strate the measure satisfies the perfect scale invariance property in the continuous case. In the discrete setting, we derive algorithms for blob detection and keypoint description. Finally, we provide qualitative justifi- cations of our findings as well as a quantitative evaluation on benchmark data. We also report an experimental evidence that our method is very suitable to deal with compressed and noisy images, thanks to the sparsity property of shearlets. 1 Introduction Feature detection consists in the extraction of perceptually interesting low-level features over an image, in preparation of higher level processing tasks. In the last decade a considerable amount of work has been devoted to the design of effective and efficient local feature detectors able to associate with a given interesting point also scale and orientation information. Scale-space theory has been one of the main sources of inspiration for this line of research, providing an effective framework for detecting features at multiple scales and, to some extent, to devise scale invariant image descriptors. -

Scale Space Multiresolution Analysis of Random Signals
Scale Space Multiresolution Analysis of Random Signals Lasse Holmstr¨om∗, Leena Pasanen Department of Mathematical Sciences, University of Oulu, Finland Reinhard Furrer Institute of Mathematics, University of Zurich,¨ Switzerland Stephan R. Sain National Center for Atmospheric Research, Boulder, Colorado, USA Abstract A method to capture the scale-dependent features in a random signal is pro- posed with the main focus on images and spatial fields defined on a regular grid. A technique based on scale space smoothing is used. However, where the usual scale space analysis approach is to suppress detail by increasing smoothing progressively, the proposed method instead considers differences of smooths at neighboring scales. A random signal can then be represented as a sum of such differences, a kind of a multiresolution analysis, each difference representing de- tails relevant at a particular scale or resolution. Bayesian analysis is used to infer which details are credible and which are just artifacts of random variation. The applicability of the method is demonstrated using noisy digital images as well as global temperature change fields produced by numerical climate prediction models. Keywords: Scale space smoothing, Bayesian methods, Image analysis, Climate research 1. Introduction In signal processing, smoothing is often used to suppress noise. An optimal level of smoothing is then of interest. In scale space analysis of noisy curves and images, instead of a single, in some sense “optimal” level of smoothing, a whole family of smooths is considered and each smooth is thought to provide information about the underlying object at a particular scale or resolution. The ∗Corresponding author ∗∗P.O.Box 3000, 90014 University of Oulu, Finland Tel. -

Image Denoising Using Non Linear Diffusion Tensors
2011 8th International Multi-Conference on Systems, Signals & Devices IMAGE DENOISING USING NON LINEAR DIFFUSION TENSORS Benzarti Faouzi, Hamid Amiri Signal, Image Processing and Pattern Recognition: TSIRF (ENIT) Email: [email protected] , [email protected] ABSTRACT linear models. Many approaches have been proposed to remove the noise effectively while preserving the original Image denoising is an important pre-processing step for image details and features as much as possible. In the past many image analysis and computer vision system. It few years, the use of non linear PDEs methods involving refers to the task of recovering a good estimate of the true anisotropic diffusion has significantly grown and image from a degraded observation without altering and becomes an important tool in contemporary image changing useful structure in the image such as processing. The key idea behind the anisotropic diffusion discontinuities and edges. In this paper, we propose a new is to incorporate an adaptative smoothness constraint in approach for image denoising based on the combination the denoising process. That is, the smooth is encouraged of two non linear diffusion tensors. One allows diffusion in a homogeneous region and discourage across along the orientation of greatest coherences, while the boundaries, in order to preserve the natural edge of the other allows diffusion along orthogonal directions. The image. One of the most successful tools for image idea is to track perfectly the local geometry of the denoising is the Total Variation (TV) model [9] [8][10] degraded image and applying anisotropic diffusion and the anisotropic smoothing model [1] which has since mainly along the preferred structure direction. -

Scale-Space Theory for Multiscale Geometric Image Analysis
Tutorial Scale-Space Theory for Multiscale Geometric Image Analysis Bart M. ter Haar Romeny, PhD Utrecht University, the Netherlands [email protected] Introduction Multiscale image analysis has gained firm ground in computer vision, image processing and models of biological vision. The approaches however have been characterised by a wide variety of techniques, many of them chosen ad hoc. Scale-space theory, as a relatively new field, has been established as a well founded, general and promising multiresolution technique for image structure analysis, both for 2D, 3D and time series. The rather mathematical nature of many of the classical papers in this field has prevented wide acceptance so far. This tutorial will try to bridge that gap by giving a comprehensible and intuitive introduction to this field. We also try, as a mutual inspiration, to relate the computer vision modeling to biological vision modeling. The mathematical rigor is much relaxed for the purpose of giving the broad picture. In appendix A a number of references are given as a good starting point for further reading. The multiscale nature of things In mathematics objects have no scale. We are familiar with the notion of points, that really shrink to zero, lines with zero width. In mathematics are no metrical units involved, as in physics. Neighborhoods, like necessary in the definition of differential operators, are defined as taken into the limit to zero, so we can really speak of local operators. In physics objects live on a range of scales. We need an instrument to do an observation (our eye, a camera) and it is the range that this instrument can see that we call the scale range. -

An Overview of Wavelet Transform Concepts and Applications
An overview of wavelet transform concepts and applications Christopher Liner, University of Houston February 26, 2010 Abstract The continuous wavelet transform utilizing a complex Morlet analyzing wavelet has a close connection to the Fourier transform and is a powerful analysis tool for decomposing broadband wavefield data. A wide range of seismic wavelet applications have been reported over the last three decades, and the free Seismic Unix processing system now contains a code (succwt) based on the work reported here. Introduction The continuous wavelet transform (CWT) is one method of investigating the time-frequency details of data whose spectral content varies with time (non-stationary time series). Moti- vation for the CWT can be found in Goupillaud et al. [12], along with a discussion of its relationship to the Fourier and Gabor transforms. As a brief overview, we note that French geophysicist J. Morlet worked with non- stationary time series in the late 1970's to find an alternative to the short-time Fourier transform (STFT). The STFT was known to have poor localization in both time and fre- quency, although it was a first step beyond the standard Fourier transform in the analysis of such data. Morlet's original wavelet transform idea was developed in collaboration with the- oretical physicist A. Grossmann, whose contributions included an exact inversion formula. A series of fundamental papers flowed from this collaboration [16, 12, 13], and connections were soon recognized between Morlet's wavelet transform and earlier methods, including harmonic analysis, scale-space representations, and conjugated quadrature filters. For fur- ther details, the interested reader is referred to Daubechies' [7] account of the early history of the wavelet transform. -
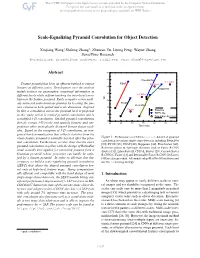
Scale-Equalizing Pyramid Convolution for Object Detection
Scale-Equalizing Pyramid Convolution for Object Detection Xinjiang Wang,* Shilong Zhang∗, Zhuoran Yu, Litong Feng, Wayne Zhang SenseTime Research {wangxinjiang, zhangshilong, yuzhuoran, fenglitong, wayne.zhang}@sensetime.com Abstract 42 41 FreeAnchor C-Faster Feature pyramid has been an efficient method to extract FSAF D-Faster 40 features at different scales. Development over this method Reppoints mainly focuses on aggregating contextual information at 39 different levels while seldom touching the inter-level corre- L-Faster AP lation in the feature pyramid. Early computer vision meth- 38 ods extracted scale-invariant features by locating the fea- FCOS RetinaNet ture extrema in both spatial and scale dimension. Inspired 37 by this, a convolution across the pyramid level is proposed Faster Baseline 36 SEPC-lite in this study, which is termed pyramid convolution and is Two-stage detectors a modified 3-D convolution. Stacked pyramid convolutions 35 directly extract 3-D (scale and spatial) features and out- 60 65 70 75 80 85 90 performs other meticulously designed feature fusion mod- Time (ms) ules. Based on the viewpoint of 3-D convolution, an inte- grated batch normalization that collects statistics from the whole feature pyramid is naturally inserted after the pyra- Figure 1: Performance on COCO-minival dataset of pyramid mid convolution. Furthermore, we also show that the naive convolution in various single-stage detectors including RetinaNet [20], FCOS [38], FSAF [48], Reppoints [44], FreeAnchor [46]. pyramid convolution, together with the design of RetinaNet Reference points of two-stage detectors such as Faster R-CNN head, actually best applies for extracting features from a (Faster) [31], Libra Faster R-CNN (L-Faster) [29], Cascade Faster Gaussian pyramid, whose properties can hardly be satis- R-CNN (C-Faster) [1] and Deformable Faster R-CNN (D-Faster) fied by a feature pyramid. -

View Matching with Blob Features
View Matching with Blob Features Per-Erik Forssen´ and Anders Moe Computer Vision Laboratory Department of Electrical Engineering Linkoping¨ University, Sweden Abstract mographic transformation that is not part of the affine trans- formation. This means that our results are relevant for both This paper introduces a new region based feature for ob- wide baseline matching and 3D object recognition. ject recognition and image matching. In contrast to many A somewhat related approach to region based matching other region based features, this one makes use of colour is presented in [1], where tangents to regions are used to de- in the feature extraction stage. We perform experiments on fine linear constraints on the homography transformation, the repeatability rate of the features across scale and incli- which can then be found through linear programming. The nation angle changes, and show that avoiding to merge re- connection is that a line conic describes the set of all tan- gions connected by only a few pixels improves the repeata- gents to a region. By matching conics, we thus implicitly bility. Finally we introduce two voting schemes that allow us match the tangents of the ellipse-approximated regions. to find correspondences automatically, and compare them with respect to the number of valid correspondences they 2. Blob features give, and their inlier ratios. We will make use of blob features extracted using a clus- tering pyramid built using robust estimation in local image regions [2]. Each extracted blob is represented by its aver- 1. Introduction age colour pk,areaak, centroid mk, and inertia matrix Ik. I.e. -

Scale Normalized Image Pyramids with Autofocus for Object Detection
1 Scale Normalized Image Pyramids with AutoFocus for Object Detection Bharat Singh, Mahyar Najibi, Abhishek Sharma and Larry S. Davis Abstract—We present an efficient foveal framework to perform object detection. A scale normalized image pyramid (SNIP) is generated that, like human vision, only attends to objects within a fixed size range at different scales. Such a restriction of objects’ size during training affords better learning of object-sensitive filters, and therefore, results in better accuracy. However, the use of an image pyramid increases the computational cost. Hence, we propose an efficient spatial sub-sampling scheme which only operates on fixed-size sub-regions likely to contain objects (as object locations are known during training). The resulting approach, referred to as Scale Normalized Image Pyramid with Efficient Resampling or SNIPER, yields up to 3× speed-up during training. Unfortunately, as object locations are unknown during inference, the entire image pyramid still needs processing. To this end, we adopt a coarse-to-fine approach, and predict the locations and extent of object-like regions which will be processed in successive scales of the image pyramid. Intuitively, it’s akin to our active human-vision that first skims over the field-of-view to spot interesting regions for further processing and only recognizes objects at the right resolution. The resulting algorithm is referred to as AutoFocus and results in a 2.5-5× speed-up during inference when used with SNIP. Code: https://github.com/mahyarnajibi/SNIPER Index Terms—Object Detection, Image Pyramids , Foveal vision, Scale-Space Theory, Deep-Learning. F 1 INTRODUCTION BJECT-detection is one of the most popular and widely O researched problems in the computer vision community, owing to its application to a myriad of industrial systems, such as autonomous driving, robotics, surveillance, activity-detection, scene-understanding and/or large-scale multimedia analysis. -

Multi-Scale Edge Detection and Image Segmentation
MULTI-SCALE EDGE DETECTION AND IMAGE SEGMENTATION Baris Sumengen, B. S. Manjunath ECE Department, UC, Santa Barbara 93106, Santa Barbara, CA, USA email: {sumengen,manj}@ece.ucsb.edu web: vision.ece.ucsb.edu ABSTRACT In this paper, we propose a novel multi-scale edge detection and vector field design scheme. We show that using multi- scale techniques edge detection and segmentation quality on natural images can be improved significantly. Our ap- proach eliminates the need for explicit scale selection and edge tracking. Our method favors edges that exist at a wide range of scales and localize these edges at finer scales. This work is then extended to multi-scale image segmentation us- (a) (b) (c) (d) ing our anisotropic diffusion scheme. Figure 1: Localized and clean edges using multiple scales. a) 1. INTRODUCTION Original image. b) Edge strengths at spatial scale σ = 1, c) Most edge detection algorithms specify a spatial scale at using scales from σ = 1 to σ = 4. d) at σ = 4. Edges are not which the edges are detected. Typically, edge detectors uti- well localized at σ = 4. lize local operators and the effective area of these local oper- ators define this spatial scale. The spatial scale usually corre- sponds to the level of smoothing of the image, for example, scales and generating a synthesis of these edges. On the the variance of the Gaussian smoothing. At small scales cor- other hand, it is desirable that the multi-scale information responding to finer image details, edge detectors find inten- is integrated to the edge detection at an earlier stage and the sity jumps in small neighborhoods. -

Feature Detection Florian Stimberg
Feature Detection Florian Stimberg Outline ● Introduction ● Types of Image Features ● Edges ● Corners ● Ridges ● Blobs ● SIFT ● Scale-space extrema detection ● keypoint localization ● orientation assignment ● keypoint descriptor ● Resources Introduction ● image features are distinct image parts ● feature detection often is first operation to define image parts to process later ● finding corresponding features in pictures necessary for object recognition ● Multi-Image-Panoramas need to be “stitched” together at according image features ● the description of a feature is as important as the extraction Types of image features Edges ● sharp changes in brightness ● most algorithms use the first derivative of the intensity ● different methods: (one or two thresholds etc.) Types of image features Corners ● point with two dominant and different edge directions in its neighbourhood ● Moravec Detector: similarity between patch around pixel and overlapping patches in the neighbourhood is measured ● low similarity in all directions indicates corner Types of image features Ridges ● curves which points are local maxima or minima in at least one dimension ● quality depends highly on the scale ● used to detect roads in aerial images or veins in 3D magnetic resonance images Types of image features Blobs ● points or regions brighter or darker than the surrounding ● SIFT uses a method for blob detection SIFT ● SIFT = Scale-invariant feature transform ● first published in 1999 by David Lowe ● Method to extract and describe distinctive image features ● feature -

EECS 442 Computer Vision: Homework 2
EECS 442 Computer Vision: Homework 2 Instructions • This homework is due at 11:59:59 p.m. on Friday October 18th, 2019. • The submission includes two parts: 1. To Gradescope: a pdf file as your write-up, including your answers to all the questions and key choices you made. You might like to combine several files to make a submission. Here is an example online link for combining multiple PDF files: https://combinepdf.com/. 2. To Canvas: a zip file including all your code. The zip file should follow the HW formatting instructions on the class website. • The write-up must be an electronic version. No handwriting, including plotting questions. LATEX is recommended but not mandatory. Python Environment We are using Python 3.7 for this course. You can find references for the Python stan- dard library here: https://docs.python.org/3.7/library/index.html. To make your life easier, we recommend you to install Anaconda 5.2 for Python 3.7.x (https://www.anaconda.com/download/). This is a Python package manager that includes most of the modules you need for this course. We will make use of the following packages extensively in this course: • Numpy (https://docs.scipy.org/doc/numpy-dev/user/quickstart.html) • OpenCV (https://opencv.org/) • SciPy (https://scipy.org/) • Matplotlib (http://matplotlib.org/users/pyplot tutorial.html) 1 1 Image Filtering [50 pts] In this first section, you will explore different ways to filter images. Through these tasks you will build up a toolkit of image filtering techniques. By the end of this problem, you should understand how the development of image filtering techniques has led to convolution. -

Computer Vision: Edge Detection
Edge Detection Edge detection Convert a 2D image into a set of curves • Extracts salient features of the scene • More compact than pixels Origin of Edges surface normal discontinuity depth discontinuity surface color discontinuity illumination discontinuity Edges are caused by a variety of factors Edge detection How can you tell that a pixel is on an edge? Profiles of image intensity edges Edge detection 1. Detection of short linear edge segments (edgels) 2. Aggregation of edgels into extended edges (maybe parametric description) Edgel detection • Difference operators • Parametric-model matchers Edge is Where Change Occurs Change is measured by derivative in 1D Biggest change, derivative has maximum magnitude Or 2nd derivative is zero. Image gradient The gradient of an image: The gradient points in the direction of most rapid change in intensity The gradient direction is given by: • how does this relate to the direction of the edge? The edge strength is given by the gradient magnitude The discrete gradient How can we differentiate a digital image f[x,y]? • Option 1: reconstruct a continuous image, then take gradient • Option 2: take discrete derivative (finite difference) How would you implement this as a cross-correlation? The Sobel operator Better approximations of the derivatives exist • The Sobel operators below are very commonly used -1 0 1 1 2 1 -2 0 2 0 0 0 -1 0 1 -1 -2 -1 • The standard defn. of the Sobel operator omits the 1/8 term – doesn’t make a difference for edge detection – the 1/8 term is needed to get the right gradient