Deploying Prometheus at Wikimedia Foundation
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Josh Malone Systems Administrator National Radio Astronomy Observatory Charlottesville, VA
heck What the #%!@ is wrong ^ with my server?!? Josh Malone Systems Administrator National Radio Astronomy Observatory Charlottesville, VA 1 Agenda • Intro to Monitoring • Internet protocols 101 • • Nagios SMTP • IMAP • Install/Config • HTTP • Usage • Custom plugins • Packet sniffing for dummies • Intro to Troubleshooting • Tools • telnet, openssl • grep, sed • ps, lsof, netstat 2 MONITORING 3 Automated Monitoring Workflow 4 Monitoring Packages: Open Source • • Pandora FMS • Opsview Core • Naemon • • • • • • Captialware ServerStatus • Core • Sensu All Trademarks and Logos are property of their respective trademark or copyright holders and are used by permission or fair use for education. Neither the presenter nor the conference organizers are affiliated in any way with any companies mentioned here. 5 Monitoring Packages: Commercial • Nagios XI • Groundwork • PRTG network monitor • CopperEgg • WhatsUp Gold • PRTG network monitor • op5 (Naemon) All Trademarks and Logos are property of their respective trademark or copyright holders and are used by permission or fair use for education. Neither the presenter nor the conference organizers are affiliated in any way with any companies mentioned here. 6 Why Automatic Service Monitoring? • Spot small problems before they become big ones • Learn about outages before your users do • Checklist when restoring from a power outage • Gives you better problem reports than users • Problems you might never spot otherwise • Failed HDDs in RAIDs • Full /var partitions • Logs not rotating • System temperature rising 7 Why Automatic Service Monitoring? • Capacity planning • Performance data can generate graphs of utilization • RAM, Disk, etc. • Availability reports - CAUTION • Easy to generate -- even easier to generate wrong • Make sure your configurations actually catch problems • Will also include problems with Nagios itself :( • If you’re going to quote your availability numbers (SLAs, etc.) make sure you understand what you’re actually monitoring. -

Monitoring Bareos with Icinga 2 Version: 1.0
Monitoring Bareos with Icinga 2 Version: 1.0 We love Open Source 1 © NETWAYS Table of Contents 1 Environment 2 Introduction 3 Host 4 Active Checks 5 Passive Events 6 Graphite 2 © NETWAYS 1 Environment 3 © NETWAYS Pre-installed Software Bareos Bareos Database (PostgreSQL) Bareos WebUI Icinga 2 IDO (MariaDB) Icinga Web 2 Graphite 4 © NETWAYS 2 Introduction 5 © NETWAYS 2.1 Bareos 6 © NETWAYS What is Bareos? Backup Archiving Recovery Open Sourced Backup, archiving and recovery of current operating systems Open Source Fork of Bacula (http://bacula.org) Forked 2010 (http://bareos.org) AGPL v3 License (https://github.com/bareos/bareos) A lot of new features: LTO Hardware encryption Bandwidth limitation Cloud storage connection New console commands Many more 7 © NETWAYS Bareos Structure 8 © NETWAYS 2.2 Icinga 2 9 © NETWAYS Icinga - Open Source Enterprise Monitoring Icinga is a scalable and extensible monitoring system which checks the availability of your resources, notifies users of outages and provides extensive BI data. International community project Everything developed by the Icinga Project is Open Source Originally forked from Nagios in 2009 Independent version Icinga 2 since 2014 10 © NETWAYS Icinga - Availability Monitoring Monitors everything Gathering status Collect performance data Notifies using any channel Considers dependencies Handles events Checks and forwards logs Deals with performance data Provides SLA data 11 © NETWAYS What is Icinga 2? Core based on C++ and Boost Supports all major *NIX and Windows platforms Powerful configuration -

Pynag Documentation Release 0.9.0
pynag Documentation Release 0.9.0 Pall Sigurdsson and Tomas Edwardsson July 23, 2014 Contents 1 Introduction 3 1.1 About pynag...............................................3 2 The pynag module 5 2.1 pynag Package.............................................5 2.2 Subpackages...............................................5 3 The pynag command line 85 3.1 NAME.................................................. 85 Python Module Index 89 i ii pynag Documentation, Release 0.9.0 Release 0.9.0 Date July 23, 2014 This document is under a Creative Commons Attribution - Non-Commercial - Share Alike 2.5 license. Contents 1 pynag Documentation, Release 0.9.0 2 Contents CHAPTER 1 Introduction 1.1 About pynag Pynag is a all around python interface to Nagios and bretheren (Icinga, Naemon and Shinken) as well as providing a command line interface to them for managing them. 3 pynag Documentation, Release 0.9.0 4 Chapter 1. Introduction CHAPTER 2 The pynag module 2.1 pynag Package 2.2 Subpackages 2.2.1 Control Package Control Package The Control module includes classes to control the Nagios service and the Command submodule wraps Nagios com- mands. class pynag.Control.daemon(nagios_bin=’/usr/bin/nagios’, nagios_cfg=’/etc/nagios/nagios.cfg’, na- gios_init=None, sudo=True, shell=None, service_name=’nagios’, na- gios_config=None) Bases: object Control the nagios daemon through python >>> from pynag.Control import daemon >>> >>> d= daemon() >>> d.restart() SYSTEMD = 3 SYSV_INIT_SCRIPT = 1 SYSV_INIT_SERVICE = 2 reload() Reloads Nagios. Returns Return code of the reload command ran by pynag.Utils.runCommand() Return type int restart() Restarts Nagios via it’s init script. Returns Return code of the restart command ran by pynag.Utils.runCommand() Return type int 5 pynag Documentation, Release 0.9.0 running() Checks if the daemon is running Returns Whether or not the daemon is running Return type bool start() Start the Nagios service. -

Azure Icinga 2.5 - Client Connection Guide Scope
Azure Icinga 2.5 - Client Connection Guide Scope The purpose of this document is to provide the steps necessary for connecting a client instance of Icinga 2, version 2.5 or later, to a master node. The steps contained within are sourced from the official Icinga 2 documentation in Section 6, "Distributed Monitoring with Master, Satellites, and Clients" This version of the documentation has been adapted to match the necessary upgrade steps for an instance of the Shadow-Soft Marketplace VHD image. Distributed Monitoring Your Shadow-Soft Marketplace VHD image for Icinga 2 is already configured with a "Master" node. If you have a second Icinga 2 node that you would like to have as a part of your monitoring environment, you can connect the two Icinga 2 daemons together securely using the included icinga2 node wizard commands. This creates an SSL-authenticated tunnel between the daemons over port 5665. This connection will allow configuration to be distributed outward to the satellite, and allow local checks on the satellite node to be executed, then communicated upstream to the master. A master node has no parent node A master node is where you usually install Icinga Web 2. A master node can combine executed checks from child nodes into backends and notifications. A satellite node has a parent node, and may have a child node. A satellite node may execute checks on its own or delegate check execution to child nodes. A satellite node can receive configuration for hosts/services, etc. from the parent node. A satellite node continues to run even if the master node is temporarily unavailable. -

Best Practices in Monitoring
Best Practices in Monitoring Lars Vogdt Team Lead SUSE DevOPS <[email protected]> About Lars Vogdt ● Co-developer of the SUSE School Server (2003) ● Team lead openSUSE Education since 2006 ● Team lead internal IT Services Team 2009 – 2016 ● Team lead DevOPS Team since Sep. 2016 (Main Target: Build Service) • Responsible for Product Generation, Build Service and Package Hub inside and outside SUSE ● Responsible for “monitoring packages” at SUSE 2 Control your infrastructure Optimize your IT resources ? How can you do that without knowing your requirements and your current resources ? Conclusion: Monitoring is a basic requirement before thinking about anything else... Agenda SUSE monitoring packages Tips and Tricks • Generic Tips • Examples High available and/or load balanced monitoring: one possible way to go Demos: • Icinga, PNP4Nagios, NagVis • automatic inventory via check_mk • Pacemaker / Corosync (SUSE Linux Enterprise High Availability) • (mod_)Gearman • Salt • … The future of monitoring @SUSE SUSE monitoring packages SUSE monitoring packages Official vs. unsupported Official supported server:monitoring SUSE Package Hub SUSE official repos https://download.opensuse.org/ https://packagehub.suse.com/ Nagios for <= SLES 11 Base repository for ALL New repository with checked monitoring packages packages, provided via SCC (special channel) nagios-plugins <= > 650 packages Contains packages from SLES 11 server:monitoring which saw additional reviews & testing Icinga 1 for >= SLES Newer packages, Stable, but without support. 12 via SUSE Manager including Add-Ons Rollback possible. - no support monitoring-plugins for Used heavily inside >= SLES 12 SUSE, but with no official support Tips and Tricks Monitoring? 1. Monitoring starts before a machine/service goes into production 2. Monitoring without history will not help to think about the future 3. -

Scibian 9 HPC Installation Guide
Scibian 9 HPC Installation guide CCN-HPC Version 1.9, 2018-08-20 Table of Contents About this document . 1 Purpose . 2 Structure . 3 Typographic conventions . 4 Build dependencies . 5 License . 6 Authors . 7 Reference architecture. 8 1. Hardware architecture . 9 1.1. Networks . 9 1.2. Infrastructure cluster. 10 1.3. User-space cluster . 12 1.4. Storage system . 12 2. External services . 13 2.1. Base services. 13 2.2. Optional services . 14 3. Software architecture . 15 3.1. Overview . 15 3.2. Base Services . 16 3.3. Additional Services. 19 3.4. High-Availability . 20 4. Conventions . 23 5. Advanced Topics . 24 5.1. Boot sequence . 24 5.2. iPXE Bootmenu Generator. 28 5.3. Debian Installer Preseed Generator. 30 5.4. Frontend nodes: SSH load-balancing and high-availability . 31 5.5. Service nodes: DNS load-balancing and high-availability . 34 5.6. Consul and DNS integration. 35 5.7. Scibian diskless initrd . 37 Installation procedure. 39 6. Overview. 40 7. Requirements . 41 8. Temporary installation node . 44 8.1. Base installation . 44 8.2. Administration environment . 44 9. Internal configuration repository . 46 9.1. Base directories . 46 9.2. Organization settings . 46 9.3. Cluster directories . 48 9.4. Puppet configuration . 48 9.5. Cluster definition. 49 9.6. Service role . 55 9.7. Authentication and encryption keys . 56 10. Generic service nodes . 62 10.1. Temporary installation services . 62 10.2. First Run. 62 10.3. Second Run . 64 10.4. Base system installation. 64 10.5. Ceph deployment . 66 10.6. Consul deployment. -
Nagios & Icinga Network Monitoring
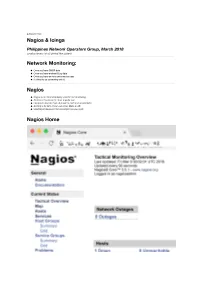
autoscale: true Nagios & Icinga Philippines Network Operators Group, March 2018 Jonathan Brewer Telco2 Limited New Zealand Network Monitoring: Once you have SNMP data Once you have analysed Log data Once you have service performance data It's time to do something with it! Nagios Nagios is an Internet industry standard for monitoring At times it has been the most popular tool Its job is to monitor hosts & services, and alert on problems Alerting is its forte, it can use email, SMS, or API Handling of issues can be as complex as you need Nagios Home Nagios Hosts Hosts are containers for services If a host is unreachable, so are its services If a host is down, so are its services Nagios treats hosts differently from services! Nagios Hosts Nagios Host Groups Many hosts in a network are identical They can be added to a common group Nagios will behave the same way towards all hosts in a group This saves time & effort in adding hosts to Nagios Nagios Host Groups Nagios Services Nagios pre-defines service templates for many common things DNS, FTP, HTTP, HTTPS, SSH Users can define their own services for special cases For example calling a remote application via SSH Nagios Services Nagios Custom Service Nagios Heirarchy All services in Nagios are children of a host All hosts in Nagios are considered in a heirarchy If a host's parent is unavailable, its children are unreachable This prevents Nagios from alerting on unreachable hosts & services Nagios Heirarchy Nagios Contacts Alerting is what Nagios does best! Contacts the basis of alerting How a contact -

Network Monitoring Solutions
NETWORK MONITORING SOLUTIONS Steven Borik Corey Muniz Brandon Irizarry 7/14/2015 PRE-PROJECT PREPARATION - Monitoring PAW - Learning PK - Troubleshooting problems PROJECT INTRODUCTION ResearchResearch MeetingsMeetings withwith StakeholdersStakeholders Implementing/TestingImplementing/Testing TopTop SoftwareSoftware PHASE 1 - RESEARCH Paid Solution Open Source Zenoss Monit Splunk Icinga OpManager Nagios Verax Zenoss Core Sensu Zabbix Munin Server Density Shinken Arturis Monitorix CopperEgg Opsview MindArray openNMS SolarWinds Observium Datadog LibreNMS Pandora FMS Argus-the all-seeing IBM Tivoli Kaseya Traverse PHASE 2 - MEETINGS •• PhilPhil MolterMolter •• MarkMark LaForestLaForest •• GiganewsGiganews RonaldRonald KauffmanKauffman •• LSAsLSAs (Steven(Steven Klestinect,Klestinect, ChuChu Song,Song, ThomasThomas Elrod,Elrod, MattMatt Wash)Wash) •• ClayClay BishopBishop •• BrianCohenBrianCohen DataFoundryDataFoundry •• WilliamWilliam McCormickMcCormick •• ChrisChris MarshMarsh •• ThomasThomas AdamsAdams ITIT PHASE 3 - IMPLEMENTATION ZabbixZabbix IcingaIcinga ArgusArgus ZenossZenoss PandoraFMSPandoraFMS CopperCopper EggEgg ObserviumObservium LibreNMSLibreNMS MindMind ArrayArray NagiosNagios Zabbix, LibreNMS, Zenoss, Nagios SOFTWARE 1: LIBRENMS PROS CONS hensive Compre raphing G ket Comprehensive No Tic tion Graphing Integra riendly Plugin F lity ckNso Q Tuicaket Plugin Friendly La SInutepgproartion c Aestheti Lacks Quality Aesthetic Support SOFTWARE 2: ZABBIX s o r P Highly Minor MiB Customizable Support In-Depth Very Resource Graphing Dependent -

FUJITSU Server Plug-Ins for Nagios Core FUJITSU Server Plug-Ins V3.50 for Nagios Core
FUJITSU Server Plug-ins for Nagios Core FUJITSU Server Plug-ins V3.50 for Nagios Core Interface Documentation March 2018 Edition Copyright 2018 FUJITSU LIMITED All hardware and software names used are trademarks of their respective manufacturers. All rights, including rights of translation, reproduction by printing, copying or similar methods, in part or in whole, are reserved. Offenders will be liable for damages. All rights, including rights created by patent grant or registration of a utility model or design, are reserved. Delivery subject to availability. Right of technical modification reserved. FUJITSU Server Plug-ins for Nagios Core Page: 3 / 86 Keywords ServerView, Nagios, Icinga, PRIMERGY, Blade, PRIMEQUEST, RAID, CIM, iRMC, RackCDU Copyright 2012-2018 FUJITSU LIMITED All rights reserved. FUJITSU Server Plug-ins for Nagios Core Page: 4 / 86 CONTENTS 1 Introduction ..............................................................................................................................................7 1.1 Change History ..................................................................................................................................8 1.2 Documentation ..................................................................................................................................8 1.3 How to Start .......................................................................................................................................9 1.4 Protocol Overview (SNMP, CIM, REST) ....................................................................................... -

For Control Systems at Cern
Evaluation of standard monitoring tools(including log analysis) for control systems at Cern August 2013 Author: Vlad Vintila Supervisor(s): Fernando Varela Rodriguez CERN openlab Summer Student Report 2013 CERN openlab Summer Student Report 2013 Project Specification The goal of this Openlab Summer Student project was to assess the implications and the benefits of integrating two standard IT tools, namely Icinga and Splunkstorm with the existing production setup for monitoring and management of control systems at CERN. Icinga – an open source monitoring software based on Nagios would need to be integrated with an in-house developed WinCC OA application called MOON, that is currently used for monitoring and managing all the components that make up the control systems. Splunkstorm – a data analysis and log management online application would be used stand alone, so it didn’t need integration with other software, only understanding of features and installation procedure. Abstract The aim of this document is to provide insights into installation procedures, key features and functionality and projected implementation effort of Icinga and Splunkstorm IT tools. Focus will be on presenting the most feasible implementation paths that surfaced once both software were well understood. CERN openlab Summer Student Report 2013 Table of Contents Project specification ........................................................................................................ 2 Abstract ........................................................................................................................... -

Lucas Nussbaum [email protected]
Supervision - Monitoring Lucas Nussbaum [email protected] Licence professionnelle ASRALL Administration de systèmes, réseaux et applications à base de logiciels libres Lucas Nussbaum Supervision - Monitoring 1 / 51 Administrative stuff I Yes, this course is in English I will speak in French though Goal: get you used to reading technical documentation in English I This module: 6 slots of 3 hours Evaluation: practical work (TPs) + possibly exam Goals: F General knowledge of infrastructure monitoring F Master standard tools of the field F Know about the current trends in this field (e.g. impact of cloud and elasticity) I The other part of this module (Supervision - Annuaire) is totally independent (and with a different tutor: Fabien Pascale) Lucas Nussbaum Supervision - Monitoring 2 / 51 Introduction I Success criteria for sysadmins: infrastructure that just works Avoid incidents if possible If not possible, minimize downtime I How? Well-designed infrastructure Choose reliable technologies and software Add HA (high-availability), failover, redundancy, etc. I Not enough: Murphy’s law (Anything that can go wrong will go wrong) I Monitoring: Collect information about the state of the infrastructure Detect problems (before users have to report them) Predict problems Usual components: ; Probes to acquire data Database to store all measurements Dashboard to show results Notification system (email, SMS, etc.) Lucas Nussbaum Supervision - Monitoring 3 / 51 Example: Icinga https://nagios.debian.org/icinga/ – login: dsa-guest / password: dsa-guest Lucas Nussbaum Supervision - Monitoring 4 / 51 Example: graph from Munin I Disk usage on a server Lucas Nussbaum Supervision - Monitoring 5 / 51 Two sides of the same coin: Metrology Goal: collect lots of metrics about how the system behaves to track performance of the system over time telemetry I Example: collect statistics about; network traffic, HTTP req/s, disk I/Os, .. -

27Th Large Installation System Administration Conference (LISA '13)
conference proceedings Proceedings of the 27th Large Installation System Administration Conference 27th Large Installation System Administration Conference (LISA ’13) Washington, D.C., USA November 3–8, 2013 Washington, D.C., USA November 3–8, 2013 Sponsored by In cooperation with LOPSA Thanks to Our LISA ’13 Sponsors Thanks to Our USENIX and LISA SIG Supporters Gold Sponsors USENIX Patrons Google InfoSys Microsoft Research NetApp VMware USENIX Benefactors Akamai EMC Hewlett-Packard Linux Journal Linux Pro Magazine Puppet Labs Silver Sponsors USENIX and LISA SIG Partners Cambridge Computer Google USENIX Partners Bronze Sponsors Meraki Nutanix Media Sponsors and Industry Partners ACM Queue IEEE Security & Privacy LXer ADMIN IEEE Software No Starch Press CiSE InfoSec News O’Reilly Media Computer IT/Dev Connections Open Source Data Center Conference Distributed Management Task Force IT Professional (OSDC) (DMTF) Linux Foundation Server Fault Free Software Magazine Linux Journal The Data Center Journal HPCwire Linux Pro Magazine Userfriendly.org IEEE Pervasive © 2013 by The USENIX Association All Rights Reserved This volume is published as a collective work. Rights to individual papers remain with the author or the author’s employer. Permission is granted for the noncommercial reproduction of the complete work for educational or research purposes. Permission is granted to print, primarily for one person’s exclusive use, a single copy of these Proceedings. USENIX acknowledges all trademarks herein. ISBN 978-1-931971-05-8 USENIX Association Proceedings of the 27th Large Installation System Administration Conference November 3–8, 2013 Washington, D.C. Conference Organizers Program Co-Chairs David Nalley, Apache Cloudstack Narayan Desai, Argonne National Laboratory Adele Shakal, Metacloud, Inc.