A Quantitative Neural Coding Model of Sensory Memory Authors: Peilei Liu1*, Ting Wang1
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Neural Coding and the Statistical Modeling of Neuronal Responses By
Neural coding and the statistical modeling of neuronal responses by Jonathan Pillow A dissertation submitted in partial fulfillment of the requirements for the degree of Doctor of Philosophy Center for Neural Science New York University Jan 2005 Eero P. Simoncelli TABLE OF CONTENTS LIST OF FIGURES v INTRODUCTION 1 1 Characterization of macaque retinal ganglion cell responses using spike-triggered covariance 5 1.1NeuralCharacterization.................... 9 1.2One-DimensionalModelsandtheSTA............ 12 1.3Multi-DimensionalModelsandSTCAnalysis........ 16 1.4 Separability and Subspace STC ................ 21 1.5 Subunit model . ....................... 23 1.6ModelValidation........................ 25 1.7Methods............................. 28 2 Estimation of a Deterministic IF model 37 2.1Leakyintegrate-and-firemodel................. 40 2.2Simulationresultsandcomparison............... 41 ii 2.3Recoveringthelinearkernel.................. 42 2.4Recoveringakernelfromneuraldata............. 44 2.5Discussion............................ 46 3 Estimation of a Stochastic, Recurrent IF model 48 3.1TheModel............................ 52 3.2TheEstimationProblem.................... 54 3.3ComputationalMethodsandNumericalResults....... 57 3.4TimeRescaling......................... 60 3.5Extensions............................ 61 3.5.1 Interneuronalinteractions............... 62 3.5.2 Nonlinear input ..................... 63 3.6Discussion............................ 64 AppendixA:ProofofLog-ConcavityofModelLikelihood..... 65 AppendixB:ComputingtheLikelihoodGradient........ -

Neural Oscillations As a Signature of Efficient Coding in the Presence of Synaptic Delays Matthew Chalk1*, Boris Gutkin2,3, Sophie Dene` Ve2
RESEARCH ARTICLE Neural oscillations as a signature of efficient coding in the presence of synaptic delays Matthew Chalk1*, Boris Gutkin2,3, Sophie Dene` ve2 1Institute of Science and Technology Austria, Klosterneuburg, Austria; 2E´ cole Normale Supe´rieure, Paris, France; 3Center for Cognition and Decision Making, National Research University Higher School of Economics, Moscow, Russia Abstract Cortical networks exhibit ’global oscillations’, in which neural spike times are entrained to an underlying oscillatory rhythm, but where individual neurons fire irregularly, on only a fraction of cycles. While the network dynamics underlying global oscillations have been well characterised, their function is debated. Here, we show that such global oscillations are a direct consequence of optimal efficient coding in spiking networks with synaptic delays and noise. To avoid firing unnecessary spikes, neurons need to share information about the network state. Ideally, membrane potentials should be strongly correlated and reflect a ’prediction error’ while the spikes themselves are uncorrelated and occur rarely. We show that the most efficient representation is when: (i) spike times are entrained to a global Gamma rhythm (implying a consistent representation of the error); but (ii) few neurons fire on each cycle (implying high efficiency), while (iii) excitation and inhibition are tightly balanced. This suggests that cortical networks exhibiting such dynamics are tuned to achieve a maximally efficient population code. DOI: 10.7554/eLife.13824.001 *For correspondence: Introduction [email protected] Oscillations are a prominent feature of cortical activity. In sensory areas, one typically observes Competing interests: The ’global oscillations’ in the gamma-band range (30–80 Hz), alongside single neuron responses that authors declare that no are irregular and sparse (Buzsa´ki and Wang, 2012; Yu and Ferster, 2010). -

Auditory Experience Controls the Maturation of Song Discrimination and Sexual Response in Drosophila Xiaodong Li, Hiroshi Ishimoto, Azusa Kamikouchi*
RESEARCH ARTICLE Auditory experience controls the maturation of song discrimination and sexual response in Drosophila Xiaodong Li, Hiroshi Ishimoto, Azusa Kamikouchi* Graduate School of Science, Nagoya University, Nagoya, Japan Abstract In birds and higher mammals, auditory experience during development is critical to discriminate sound patterns in adulthood. However, the neural and molecular nature of this acquired ability remains elusive. In fruit flies, acoustic perception has been thought to be innate. Here we report, surprisingly, that auditory experience of a species-specific courtship song in developing Drosophila shapes adult song perception and resultant sexual behavior. Preferences in the song-response behaviors of both males and females were tuned by social acoustic exposure during development. We examined the molecular and cellular determinants of this social acoustic learning and found that GABA signaling acting on the GABAA receptor Rdl in the pC1 neurons, the integration node for courtship stimuli, regulated auditory tuning and sexual behavior. These findings demonstrate that maturation of auditory perception in flies is unexpectedly plastic and is acquired socially, providing a model to investigate how song learning regulates mating preference in insects. DOI: https://doi.org/10.7554/eLife.34348.001 Introduction Vocal learning in infants or juvenile birds relies heavily on the early experience of the adult conspe- cific sounds. In humans, early language input is necessary to form the ability of phonetic distinction *For correspondence: and pattern detection in the phase of auditory learning (Doupe and Kuhl, 1999; Kuhl, 2004). [email protected] Because of the strong parallels between speech acquisition of humans and song learning of song- Competing interests: The birds, and the difficulties to investigate the neural mechanisms of human early auditory memory at authors declare that no cellular resolution, songbirds have been used as a predominant model in studying memory formation competing interests exist. -
A Spiking Neuron Classifier Network with a Deep Architecture Inspired By
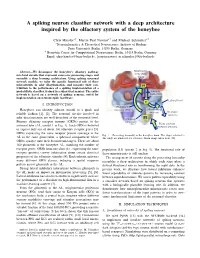
A spiking neuron classifier network with a deep architecture inspired by the olfactory system of the honeybee Chris Hausler¨ ∗†, Martin Paul Nawrot∗† and Michael Schmuker∗† ∗Neuroinformatics & Theoretical Neuroscience, Institute of Biology Freie Universitat¨ Berlin, 14195 Berlin, Germany † Bernstein Center for Computational Neuroscience Berlin, 10115 Berlin, Germany Email: [email protected], fmartin.nawrot, [email protected] Abstract—We decompose the honeybee’s olfactory pathway Mushroom into local circuits that represent successive processing stages and body (MB) calyx resemble a deep learning architecture. Using spiking neuronal network models, we infer the specific functional role of these microcircuits in odor discrimination, and measure their con- 2 tribution to the performance of a spiking implementation of a probabilistic classifier, trained in a supervised manner. The entire Kenyon network is based on a network of spiking neurons, suited for Cells (KC) implementation on neuromorphic hardware. Lateral horn 3 I. INTRODUCTION Projection Honeybees can identify odorant stimuli in a quick and neurons (PN) MB-extrinsic neurons To motor reliable fashion [1], [2]. The neuronal circuits involved in neurons odor discrimination are well described at the structural level. 1 Antennal Primary olfactory receptor neurons (ORNs) project to the lobe (AL) From odorant antennal lobe (AL, circuit 1 in Fig. 1). Each ORN is believed receptor neurons to express only one of about 160 olfactory receptor genes [3]. ORNs expressing the same receptor protein converge in the Fig. 1. Processing hierarchy in the honeybee brain. The stages relevant to AL in the same glomerulus, a spherical compartment where this study are numbered for reference. -

1P MON. PM Cortex and Subcortical Auditory Nuclei
dynamic role for the vestibular system in orientation and flight control. Laboratory studies of flight behavior under illuminated and dark conditions in both static and rotating obstacle tests were carried out while administering heavy water ͑D2O͒ to bats to impair their vestibular inputs. Eptesicus carried out complex maneuvers through both fixed arrays of wires and a rotating obstacle array using both vision and echolocation, or when guided by echolocation alone. When treated with D2O in combination with lack of visual cues, bats showed considerable decrements in performance. These data indicate that big brown bats use both vision and echolocation to provide spatial registration for head position information generated by the vestibular system. 2:55 1pAB3. Bat’s auditory system: Corticofugal feedback and plasticity. Nobuo Suga ͑Dept. of Biol., Washington Univ., One Brookings Dr., St. Louis, MO 63130͒ The auditory system of the mustached bat consists of physiologically distinct subdivisions for processing different types of biosonar information. It was found that the corticofugal ͑descending͒ auditory system plays an important role in improving and adjusting auditory signal processing. Repetitive acoustic stimulation, cortical electrical stimulation or auditory fear conditioning evokes plastic changes of the central auditory system. The changes are based upon egocentric selection evoked by focused positive feedback associated with lateral inhibition. Focal electric stimulation of the auditory cortex evokes short-term changes in the auditory 1p MON. PM cortex and subcortical auditory nuclei. An increase in a cortical acetylcholine level during the electric stimulation changes the cortical changes from short-term to long-term. There are two types of plastic changes ͑reorganizations͒: centripetal best frequency shifts for expanded reorganization of a neural frequency map and centrifugal best frequency shifts for compressed reorganization of the map. -

An Optogenetic Approach to Understanding the Neural Circuits of Fear Joshua P
Controlling the Elements: An Optogenetic Approach to Understanding the Neural Circuits of Fear Joshua P. Johansen, Steffen B.E. Wolff, Andreas Lüthi, and Joseph E. LeDoux Neural circuits underlie our ability to interact in the world and to learn adaptively from experience. Understanding neural circuits and how circuit structure gives rise to neural firing patterns or computations is fundamental to our understanding of human experience and behavior. Fear conditioning is a powerful model system in which to study neural circuits and information processing and relate them to learning and behavior. Until recently, technological limitations have made it difficult to study the causal role of specific circuit elements during fear conditioning. However, newly developed optogenetic tools allow researchers to manipulate individual circuit components such as anatom- ically or molecularly defined cell populations, with high temporal precision. Applying these tools to the study of fear conditioning to control specific neural subpopulations in the fear circuit will facilitate a causal analysis of the role of these circuit elements in fear learning and memory. By combining this approach with in vivo electrophysiological recordings in awake, behaving animals, it will also be possible to determine the functional contribution of specific cell populations to neural processing in the fear circuit. As a result, the application of optogenetics to fear conditioning could shed light on how specific circuit elements contribute to neural coding and to fear learning and memory. Furthermore, this approach may reveal general rules for how circuit structure and neural coding within circuits gives rise to sensory experience and behavior. Key Words: Electrophysiology, fear conditioning, learning and circuits and the identification of sites of neural plasticity in these memory, neural circuits, neural plasticity, optogenetics circuits. -

Krogh's Principle
Introduction to Neuroscience: Behavioral Neuroscience Neuroethology, Comparative Neuroscience, Natural Neuroscience Nachum Ulanovsky Department of Neurobiology, Weizmann Institute of Science 2017-2018, 2nd semester Principles of Neuroethology Neuroethology seeks to understand the mechanisms by which the Neurobiology central nervous system controls the Neuroethology Ethology natural behavior of animals. • Focus on Natural behaviors: Choosing to study a well-defined and reproducible yet natural behavior (either Innate or Learned behavior) • Need to study thoroughly the animal’s behavior, including in the field: Neuroethology starts with a good understanding of Ethology. • If you study the animals in the lab, you need to keep them in conditions as natural as possible, to avoid the occurrence of unnatural behaviors. • Krogh’s principle 1 Krogh’s principle August Krogh Nobel prize 1920 “For such a large number of problems there will be some animal of choice or a few such animals on which it can be most conveniently studied. Many years ago when my teacher, Christian Bohr, was interested in the respiratory mechanism of the lung and devised the method of studying the exchange through each lung separately, he found that a certain kind of tortoise possessed a trachea dividing into the main bronchi high up in the neck, and we used to say as a laboratory joke that this animal had been created expressly for the purposes of respiration physiology. I have no doubt that there is quite a number of animals which are similarly "created" for special physiological -

Lateral Inhibition Effects Demonstrate That the Maturational State of Neurons That Then Inhibit Their Neighbors
522 Lateral Inhibition effects demonstrate that the maturational state of neurons that then inhibit their neighbors. When a the learner’s brain is crucial for the attainment of stimulus (such as a bar of light or any other stim- a language system. ulus) excites a number of neurons in the network Several questions remain open about the mecha- (in this case neurons 4e, 5e, 6e, and 7e), the effect nisms underlying language learning. One issue is of inhibition is to suppress the neurons just out- whether specific aspects of language acquisition side the edge of the bar (3e and 8e) because those should be attributed to language-specific versus neurons are inhibited but not excited. Further, general-purpose learning mechanisms. Another issue because the neurons just inside the edges of the is whether children’s native language can affect the bar (4e and 7e) are excited by light and only inhib- way they think, and whether language is necessary ited by one neighbor, they are especially active. or helpful for the development of human concepts. This leads to perceptual contrast enhancement at borders. Further research showed that lateral inhi- Anna Papafragou bition also applied to overlapping stimuli, and that its strength fell off with distance between the See also Aphasias; Audition: Cognitive Influences; Context Effects in Perception; Speech Perception; Top- interacting stimuli. Down and Bottom-Up Processing; Word Recognition Haldan Keffer Hartline won the Nobel Prize in 1967 for discovering lateral inhibition and its neu- ral correlates. The first inhibitory circuit in the Further Readings nervous system was found in the horseshoe crab (Limulus polyphemus). -

6 Optogenetic Actuation, Inhibition, Modulation and Readout for Neuronal Networks Generating Behavior in the Nematode Caenorhabditis Elegans
Mario de Bono, William R. Schafer, Alexander Gottschalk 6 Optogenetic actuation, inhibition, modulation and readout for neuronal networks generating behavior in the nematode Caenorhabditis elegans 6.1 Introduction – the nematode as a genetic model in systems neurosciencesystems neuroscience Elucidating the mechanisms by which nervous systems process information and gen- erate behavior is among the fundamental problems of biology. The complexity of our brain and plasticity of our behaviors make it challenging to understand even simple human actions in terms of molecular mechanisms and neural activity. However the molecular machines and operational features of our neural circuits are often found in invertebrates, so that studying flies and worms provides an effective way to gain insights into our nervous system. Caenorhabditis elegans offers special opportunities to study behavior. Each of the 302 neurons in its nervous system can be identified and imaged in live animals [1, 2], and manipulated transgenically using specific promoters or promoter combinations [3, 4, 5, 6]. The chemical synapses and gap junctions made by every neuron are known from electron micrograph reconstruction [1]. Importantly, forward genetics can be used to identify molecules that modulate C. elegans’ behavior. Forward genetic dis- section of behavior is powerful because it requires no prior knowledge. It allows mol- ecules to be identified regardless of in vivo concentration, and focuses attention on genes that are functionally important. The identity and expression patterns of these molecules then provide entry points to study the molecular mechanisms and neural circuits controlling the behavior. Genetics does not provide the temporal resolution required to study neural circuit function directly. -

Exploring the Function of Neural Oscillations in Early Sensory Systems
FOCUSED REVIEW published: 15 May 2010 doi: 10.3389/neuro.01.010.2010 Exploring the function of neural oscillations in early sensory systems Kilian Koepsell1*, Xin Wang 2, Judith A. Hirsch 2 and Friedrich T. Sommer1* 1 Redwood Center for Theoretical Neuroscience, University of California, Berkeley, CA, USA 2 Neuroscience Graduate Program, University of Southern California, Los Angeles, CA, USA Neuronal oscillations appear throughout the nervous system, in structures as diverse as the cerebral cortex, hippocampus, subcortical nuclei and sense organs. Whether neural rhythms contribute to normal function, are merely epiphenomena, or even interfere with physiological processing are topics of vigorous debate. Sensory pathways are ideal for investigation of oscillatory activity because their inputs can be defined. Thus, we will focus on sensory systems Edited by: S. Murray Sherman, as we ask how neural oscillations arise and how they might encode information about the University of Chicago, USA stimulus. We will highlight recent work in the early visual pathway that shows how oscillations Reviewed by: can multiplex different types of signals to increase the amount of information that spike trains Michael J. Friedlander, Baylor College of Medicine, USA encode and transmit. Last, we will describe oscillation-based models of visual processing and Jose-Manuel Alonso, Sociedad Espanola explore how they might guide further research. de Neurociencia, Spain; University of Connecticut, USA; State University Keywords: LGN, retina, visual coding, oscillations, multiplexing of New York, USA Naoum P. Issa, University of Chicago, USA NEURAL OSCILLATIONS IN EARLY However, the autocorrelograms are subject to *Correspondence: SENSORY SYSTEMS confounds caused by the refractory period and Oscillatory neural activity has been observed spectral peaks often fail to reveal weak rhythms. -

A Barrel of Spikes Reach out and Touch
HIGHLIGHTS NEUROANATOMY Reach out and touch Dendritic spines are a popular sub- boutons (where synapses are formed ject these days. One theory is that on the shaft of the axon) would occur they exist, at least in part, to allow when dendritic spines were able to axons to synapse with dendrites bridge the gap between dendrite and without deviating from a nice axon. They carried out a detailed straight path through the brain. But, morphological study of spiny neuron as Anderson and Martin point out in axons in cat cortex to test this Nature Neuroscience, axons can also hypothesis. form spine-like structures, known as Perhaps surprisingly, they found terminaux boutons. Might these also that the two types of synaptic bouton be used to maintain economic, did not differentiate between den- straight axonal trajectories? dritic spines and shafts. Axons were Anderson and Martin proposed just as likely to use terminaux boutons that, if this were the case, the two to contact dendritic spines as they types of axonal connection — were to use en passant boutons, even terminaux boutons and en passant in cases where it would seem that the boutons — would each make path of the axon would allow it to use synapses preferentially with different an en passant bouton. So, why do types of dendritic site. Terminaux axons bother to construct these deli- boutons would be used to ‘reach out’ cate structures, if not simply to con- to dendritic shafts, whereas en passant nect to out-of-the-way dendrites? NEURAL CODING exploring an environment, a rat will use its whiskers to collect information by sweeping them backwards and forwards, and it could use a copy of the motor command to predict A barrel of spikes when the stimulus was likely to have occurred. -

Sensory Receptors A17 (1)
SENSORY RECEPTORS A17 (1) Sensory Receptors Last updated: April 20, 2019 Sensory receptors - transducers that convert various forms of energy in environment into action potentials in neurons. sensory receptors may be: a) neurons (distal tip of peripheral axon of sensory neuron) – e.g. in skin receptors. b) specialized cells (that release neurotransmitter and generate action potentials in neurons) – e.g. in complex sense organs (vision, hearing, equilibrium, taste). sensory receptor is often associated with nonneural cells that surround it, forming SENSE ORGAN. to stimulate receptor, stimulus must first pass through intervening tissues (stimulus accession). each receptor is adapted to respond to one particular form of energy at much lower threshold than other receptors respond to this form of energy. adequate (s. appropriate) stimulus - form of energy to which receptor is most sensitive; receptors also can respond to other energy forms, but at much higher thresholds (e.g. adequate stimulus for eye is light; eyeball rubbing will stimulate rods and cones to produce light sensation, but threshold is much higher than in skin pressure receptors). when information about stimulus reaches CNS, it produces: a) reflex response b) conscious sensation c) behavior alteration SENSORY MODALITIES Sensory Modality Receptor Sense Organ CONSCIOUS SENSATIONS Vision Rods & cones Eye Hearing Hair cells Ear (organ of Corti) Smell Olfactory neurons Olfactory mucous membrane Taste Taste receptor cells Taste bud Rotational acceleration Hair cells Ear (semicircular