15 Processing Flows of Information: from Data Stream to Complex Event Processing
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Eakta Jain A. Professional Preparation: B. Appointments: C. Publications
Eakta Jain Department of Computer and Information Science and Engineering University of Florida Phone: (352) 562-3979 E-mail: [email protected] Webpage: jainlab.cise.ufl.edu A. Professional Preparation: Indian Institute of Technology Kanpur, India B.Tech. (Electrical Engineering) 2006 Carnegie Mellon University M.S. (Robotics) 2010 Carnegie Mellon University Ph.D. (Robotics) 2012 B. Appointments: 02/14 – present Assistant Professor, Department of Computer and Information Science and Engi- neering, University of Florida, Gainesville, FL 12/12-02/14 Member of Technical Staff, Texas Instruments Embedded Signal Processing Lab, Computer Vision Branch, Dallas, TX 07/12-12/12 Systems Software Engineer, Natural User Interfaces Team, Texas Instruments, Dallas, TX 09/11-01/12 Lab Associate, Disney Research Pittsburgh, PA 06/10-08/10 Lab Associate, Disney Research Pittsburgh, PA 06/08-08/08 Lab Associate, Disney Research Pittsburgh, PA 06/07-08/07 Walt Disney Animation Studios, Burbank, CA C. Publications: Is the Motion of a Child Perceivably Different from the Motion of an Adult? Jain, E., Anthony, L., Aloba, A., Castonguay, A., Cuba, I., Shaw, A. and Woodward, J. (2016). ACM Transactions on Applied Percep- tion (TAP), 13(4), Article 22. DOI: 10.1145/2947616 Decoupling Light Reflex from Pupillary Dilation to Measure Emotional Arousal in Videos, Rai- turkar, P., Kleinsmith, A., Keil, A., Banerjee, A., and Jain, E. (2016), ACM Symposium on Ap- plied Perception (SAP), 89-96. Gaze-driven Video Re-editing, Jain, E., Sheikh, Y., Shamir, A. and Hodgins, J., (2015), ACM Transac- tions on Graphics (TOG) (34, p21:1-p21:12). DOI: 10.1145/2699644 3D Saliency from Eye Tracking with Tomography, Ma, B., Jain, E., and Entezari, A. -

Progress Software Introduces a New Generation of the Apama Capital Markets Foundation
June 22, 2010 Progress Software Introduces a New Generation of the Apama Capital Markets Foundation Apama Capital Markets Foundation Enhances CEP Platform With Reusable Services That Enable Developers to Help Quant Traders Become More Successful NEW YORK, NY and BEDFORD, MA, Jun 22, 2010 (MARKETWIRE via COMTEX News Network) -- SIFMA - Progress Software Corporation (NASDAQ: PRGS), a leading software provider that enables enterprises to be operationally responsive, today announced the launch and immediate availability of a new generation of its Progress(R) Apama(R) Capital Markets Foundation. The Apama Capital Markets Foundation builds on the award-winning Apama Complex Event Processing platform by providing a powerful set of pre-built capabilities for developers creating a broad range of capital markets trading applications. The new version includes new functionality and across-the-board feature enhancements that deliver significant improvements in performance and productivity. As a result, developers can enable quantitative and systematic traders to more rapidly create trading strategies and platforms that are highly competitive and differentiated, as well as create highly flexible market surveillance and risk management applications. Most importantly, these enhancements help developers significantly improve the way traders can research, design and implement their own strategies. The new Apama Capital Markets Foundation is built in the form of easily configurable building blocks and includes the following capabilities: 1. A new market data architecture, which provides an increase in performance and flexibility in the processing of cross-asset market data. The architecture makes optimal use of the patented Apama parallel event processing engine that can scale to hundreds of thousands of market data updates per second. -

Apama 5.3 Readme
Apama 5.3.0.0 Readme Version 5.3.0.0 Ports: All Date: April 2015 -------------------------------------------------------------------------------- CONTENTS ======== 1. Release Notes for 5.3.0.0 2. Customer Reported Defects Fixed in 5.3.0.0 and previous releases 3. Other Defects Fixed in 5.3.0.0 4. Copyright Notices 5. Support For installation information, see "Installing Apama" (installing_apama.pdf in the downloaded package). Adobe Acrobat Reader version 8.0 or greater is required to view the included PDF documentation. ------------------------------ 1. Release Notes for 5.3.0.0 ------------------------------ a. ADBC PAM-10573 : Some supported databases store empty strings as NULL (since 5.3.0.0) ================================================================================ Some databases such as Oracle are known to store empty strings as NULL values, which can lead to confusion when executing queries where a field is compared to the empty string. For example: select * from table where field = "" Would not match rows where the field was null for such databases. To ensure the desired results are returned when running queries against databases that store empty strings as null, we recommend queries to be written to check for NULL instead of empty string literals. However, despite this limitation in the underlying database, the supplied ODBC driver for Oracle includes special logic to allow queries to use empty strings (though this does not apply to the supplied JDBC driver, or to most other 3rd party Oracle drivers). PAM-21466 : Bundled Oracle JDBC driver can incorrectly report Oracle Advanced Security errors (since 5.2.0.0) ================================================================================ Even when Oracle Advanced Security is not turned on for the server, the following error can occur during connect: [Oracle JDBC Driver]The connect attempt failed because the server requires Oracle Advanced Security. -

Apama 10.7 Supported Platforms.Xlsx
Apama 10.7 Platform Matrix - Operating Systems Apama with Apama Capital Apama Capital Predictive Platform Software AG Apama Server Markets Markets Analytics Plug- Designer Foundation Adapters in for Apama CentOS Linux 8 (and higher) (x86) 64-bit x x x x 7 (Update 2 and higher) (x86) 64-bit x x x x Microsoft Windows 10 64-bit x x x x x 8.1 64-bit x x x x x Microsoft Windows Server 2019 64-bit x x x x x 2016 64-bit x x x x x 2012 R2 64-bit x x x x x Red Hat Enterprise Linux 8 (and higher) (x86) 64-bit x x x x 7 (Update 2 and higher) (x86) 64-bit x x x x SUSE Linux Enterprise Server 12 (x86) 64-bit x x x x Apama does not support Security Enhanced Linux (SELinux). This option should be turned off on Linux for Apama to run. For Oracle Linux, Apama is only supported with the Red Hat Compatible Kernel. For Apama server, the compiled runtime feature is only available on the Linux platforms. Apama 10.7 Platform Matrix - Compilers Microsoft Visual Studio GCC GCC Platform 2015 Update 3 4.8 8.2 (C++) CentOS Linux 8 (and higher) (x86) 64-bit x 7 (Update 2 and higher) (x86) 64-bit x Microsoft Windows 10 64-bit x 8.1 64-bit x Microsoft Windows Server 2019 64-bit x 2016 64-bit x 2012 R2 64-bit x Red Hat Enterprise Linux 8 (and higher) (x86) 64-bit x 7 (Update 2 and higher) (x86) 64-bit x SUSE Linux Enterprise Server 12 (x86) 64-bit x Compilers are relevant for Apama when creating C++ plug-ins and applications using the C++ client API. -

Progress Software Introduces Apama 4.3 for Faster Deployment and Massive Scalability for Event Processing Applications
November 17, 2010 Progress Software Introduces Apama 4.3 for Faster Deployment and Massive Scalability for Event Processing Applications New and Unique Functionality Includes Combination of Discrete and Streaming Events BEDFORD, MA -- (MARKET WIRE) -- 11/17/10 -- Progress Software Corporation (NASDAQ: PRGS), a leading independent enterprise software provider that enables companies to be operationally responsive, today announced the availability of Progress® Apama® 4.3, a major new release of the market leading Progress Apama Event Processing platform. This new version includes a next-generation Event Processing Language (EPL) optimized for the concise expression of business and temporal logic. Moreover, events can be captured as a stream with common attributes, giving developers and business users greater scalability and more control over how they can sense and respond to events. This is the third major product release of the Apama Event Processing platform in two years from Progress Software, demonstrating the company's commitment to leading research, innovation and development in this important area. The Apama development team remains steadfast in its focus on enhancing productivity, improving performance and increasing integration with innovative language features, new dashboard functionality and massive scalability. Enhancements in the Apama 4.3 platform's Event Processing Language (EPL), formerly known as MonitorScript, support sophisticated event stream management, and are the result of more than 10 person years of R&D effort. The new capabilities provide developers and business users with a simplified but extremely powerful syntax that allows "event stream networks" to be defined with common attributes, giving them more direct control over their critical business events. -

A Complex Event Processing Engine Based on Data Stream
ReCEPtor: Sensing Complex Events in Data Streams for Service-Oriented Architectures Mingzhu Wei, Ismail Ari, Jun Li, Mohamed Dekhil Digital Printing and Imaging Laboratory HP Laboratories Palo Alto HPL-2007-176 November 2, 2007* data stream, complex All mission-critical applications read or generate raw data streams and require event processing, real-time processing of these streams to collect statistics, control flow and detect SOA, query plan, abnormal patterns. A trend which has gained strong momentum in different EPL industry sectors is the use of Complex Event Processing (CEP) over streams for all critical business processes, thus pushing its span beyond military and financial applications. A parallel trend has been the re-architecting of existing business processes with Service Oriented Architecture (SOA) principals to provide integration and interoperability. This requires use of middleware that incorporates web services, Business Process Management (BPM) systems or an Enterprise Service Bus (ESB), and in some cases Business Rule Engines (BRE). There is a gap between the new generation of business processes which desperately need CEP and the proposed CEP engines that were not built with SOA in mind. These engines either don’t support the flexible, dynamic and distributed business applications deployed in SOA or they try to merge the middleware with the CEP engine as one big proprietary package. This paper describes the design and implementation of our CEP engine called ReCEPtor, which can sense complex events in data streams in real-time. Our modular architecture describes how to integrate ReCEPtor with different business applications in different platforms either directly or by using an off-the-shelf BPM system and a platform adapter. -

Department of Computer Science and Engineering
Department of Computer Science and Engineering Journals SJR Title ISSN SJR Quartile Country Molecular Systems Biology ISSN 17444292 8.87 Q1 United Kingdom IEEE Transactions on Pattern Analysis and Machine Intelligence ISSN 01628828 7.653 Q1 United States MIS Quarterly: Management Information Systems ISSN 02767783 6.984 Q1 United States Wiley Interdisciplinary Reviews: Computational Molecular Science ISSN 17590884, 17590876 6.715 Q1 United States Foundations and Trends in Machine Learning ISSN 19358237 6.194 Q1 United States IEEE Transactions on Fuzzy Systems ISSN 10636706 5.8 Q1 United States International Journal of Computer Vision ISSN 09205691 5.633 Q1 Netherlands Journal of Supply Chain Management ISSN 15232409 5.343 Q1 United Kingdom Journal of Operations Management ISSN 02726963 5.052 Q1 Netherlands IEEE Transactions on Smart Grid ISSN 19493053 4.784 Q1 United States Bioinformatics ISSN 13674811, 13674803 4.643 Q1 United Kingdom Information Systems Research ISSN 15265536, 10477047 4.397 Q1 United States IEEE Transactions on Evolutionary Computation ISSN 1089778X 4.308 Q1 United States IEEE Transactions on Automatic Control ISSN 00189286 4.238 Q1 United States International Journal of Robotics Research ISSN 02783649 4.184 Q1 United States Briefings in Bioinformatics ISSN 14774054, 14675463 4.086 Q1 United Kingdom SIAM Journal on Optimization ISSN 10526234, 10957189 3.943 Q1 United States IEEE Transactions on Systems, Man and Cybernetics Part B: Cybernetics ISSN 10834419 3.921 Q1 United States Internet and Higher Education ISSN 10967516 -

Introduction to Apama
Introduction to Apama 9.9.0 October 2015 This document applies to Apama 9.9.0 and to all subsequent releases. Specifications contained herein are subject to change and these changes will be reported in subsequent release notes or new editions. Copyright © 2013-2015 Software AG, Darmstadt, Germany and/or Software AG USA Inc., Reston, VA, USA, and/or its subsidiaries and/or its affiliates and/or their licensors. The name Software AG and all Software AG product names are either trademarks or registered trademarks of Software AG and/or Software AG USA Inc. and/or its subsidiaries and/or its affiliates and/or their licensors. Other company and product names mentioned herein may be trademarks of their respective owners. Detailed information on trademarks and patents owned by Software AG and/or its subsidiaries is located at http://softwareag.com/licenses. Use of this software is subject to adherence to Software AG's licensing conditions and terms. These terms are part of the product documentation, located at http://softwareag.com/licenses/ and/or in the root installation directory of the licensed product(s). This software may include portions of third-party products. For third-party copyright notices, license terms, additional rights or restrictions, please refer to "License Texts, Copyright Notices and Disclaimers of Third Party Products". For certain specific third-party license restrictions, please refer to section E of the Legal Notices available under "License Terms and Conditions for Use of Software AG Products / Copyright and Trademark Notices of Software AG Products". These documents are part of the product documentation, located at http://softwareag.com/licenses and/or in the root installation directory of the licensed product(s). -

The Forrester Wave™: Streaming Analytics, Q3 2019 the 11 Providers That Matter Most and How They Stack up by Mike Gualtieri September 23, 2019
LICENSED FOR INDIVIDUAL USE ONLY The Forrester Wave™: Streaming Analytics, Q3 2019 The 11 Providers That Matter Most And How They Stack Up by Mike Gualtieri September 23, 2019 Why Read This Report Key Takeaways In our 26-criterion evaluation of streaming Software AG, IBM, Microsoft, Google, And analytics providers, we identified the 11 most TIBCO Software Lead The Pack significant ones — Alibaba, Amazon Web Forrester’s research uncovered a market in which Services, Cloudera, EsperTech, Google, IBM, Software AG, IBM, Microsoft, Google, and TIBCO Impetus, Microsoft, SAS, Software AG, and Software are Leaders; Cloudera, SAS, Amazon TIBCO Software — and researched, analyzed, Web Services, and Impetus are Strong Performers; and scored them. This report shows how each and EsperTech and Alibaba are Contenders. provider measures up and helps application Analytics Prowess, Scalability, And development and delivery (AD&D) professionals Deployment Freedom Are Key Differentiators select the right one for their needs. Depth and breadth of analytics types on streaming data are critical. But that is all for naught if streaming analytics vendors cannot also scale to handle potentially huge volumes of streaming data. Also, it’s critical that streaming analytics can be deployed where it is most needed, such as on-premises, in the cloud, and/ or at the edge. This PDF is only licensed for individual use when downloaded from forrester.com or reprints.forrester.com. All other distribution prohibited. FORRESTER.COM FOR APPLICATION DEVELOPMENT & DELIVERY PROFESSIONALS The Forrester Wave™: Streaming Analytics, Q3 2019 The 11 Providers That Matter Most And How They Stack Up by Mike Gualtieri with Srividya Sridharan and Robert Perdoni September 23, 2019 Table Of Contents Related Research Documents 2 Enterprises Must Take A Streaming-First The Future Of Machine Learning Is Unstoppable Approach To Analytics Predictions 2019: Artificial Intelligence 3 Evaluation Summary Predictions 2019: Business Insights 6 Vendor Offerings 6 Vendor Profiles Leaders Share reports with colleagues. -
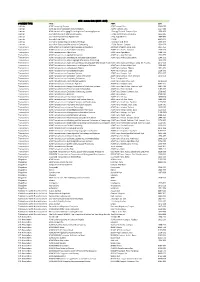
A ACM Transactions on Trans. 1553 TITLE ABBR ISSN ACM Computing Surveys ACM Comput. Surv. 0360‐0300 ACM Journal
ACM - zoznam titulov (2016 - 2019) CONTENT TYPE TITLE ABBR ISSN Journals ACM Computing Surveys ACM Comput. Surv. 0360‐0300 Journals ACM Journal of Computer Documentation ACM J. Comput. Doc. 1527‐6805 Journals ACM Journal on Emerging Technologies in Computing Systems J. Emerg. Technol. Comput. Syst. 1550‐4832 Journals Journal of Data and Information Quality J. Data and Information Quality 1936‐1955 Journals Journal of Experimental Algorithmics J. Exp. Algorithmics 1084‐6654 Journals Journal of the ACM J. ACM 0004‐5411 Journals Journal on Computing and Cultural Heritage J. Comput. Cult. Herit. 1556‐4673 Journals Journal on Educational Resources in Computing J. Educ. Resour. Comput. 1531‐4278 Transactions ACM Letters on Programming Languages and Systems ACM Lett. Program. Lang. Syst. 1057‐4514 Transactions ACM Transactions on Accessible Computing ACM Trans. Access. Comput. 1936‐7228 Transactions ACM Transactions on Algorithms ACM Trans. Algorithms 1549‐6325 Transactions ACM Transactions on Applied Perception ACM Trans. Appl. Percept. 1544‐3558 Transactions ACM Transactions on Architecture and Code Optimization ACM Trans. Archit. Code Optim. 1544‐3566 Transactions ACM Transactions on Asian Language Information Processing 1530‐0226 Transactions ACM Transactions on Asian and Low‐Resource Language Information Proce ACM Trans. Asian Low‐Resour. Lang. Inf. Process. 2375‐4699 Transactions ACM Transactions on Autonomous and Adaptive Systems ACM Trans. Auton. Adapt. Syst. 1556‐4665 Transactions ACM Transactions on Computation Theory ACM Trans. Comput. Theory 1942‐3454 Transactions ACM Transactions on Computational Logic ACM Trans. Comput. Logic 1529‐3785 Transactions ACM Transactions on Computer Systems ACM Trans. Comput. Syst. 0734‐2071 Transactions ACM Transactions on Computer‐Human Interaction ACM Trans. -
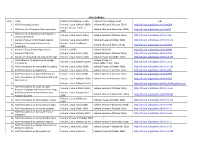
ACM JOURNALS S.No. TITLE PUBLICATION RANGE :STARTS PUBLICATION RANGE: LATEST URL 1. ACM Computing Surveys Volume 1 Issue 1
ACM JOURNALS S.No. TITLE PUBLICATION RANGE :STARTS PUBLICATION RANGE: LATEST URL 1. ACM Computing Surveys Volume 1 Issue 1 (March 1969) Volume 49 Issue 3 (October 2016) http://dl.acm.org/citation.cfm?id=J204 Volume 24 Issue 1 (Feb. 1, 2. ACM Journal of Computer Documentation Volume 26 Issue 4 (November 2002) http://dl.acm.org/citation.cfm?id=J24 2000) ACM Journal on Emerging Technologies in 3. Volume 1 Issue 1 (April 2005) Volume 13 Issue 2 (October 2016) http://dl.acm.org/citation.cfm?id=J967 Computing Systems 4. Journal of Data and Information Quality Volume 1 Issue 1 (June 2009) Volume 8 Issue 1 (October 2016) http://dl.acm.org/citation.cfm?id=J1191 Journal on Educational Resources in Volume 1 Issue 1es (March 5. Volume 16 Issue 2 (March 2016) http://dl.acm.org/citation.cfm?id=J814 Computing 2001) 6. Journal of Experimental Algorithmics Volume 1 (1996) Volume 21 (2016) http://dl.acm.org/citation.cfm?id=J430 7. Journal of the ACM Volume 1 Issue 1 (Jan. 1954) Volume 63 Issue 4 (October 2016) http://dl.acm.org/citation.cfm?id=J401 8. Journal on Computing and Cultural Heritage Volume 1 Issue 1 (June 2008) Volume 9 Issue 3 (October 2016) http://dl.acm.org/citation.cfm?id=J1157 ACM Letters on Programming Languages Volume 2 Issue 1-4 9. Volume 1 Issue 1 (March 1992) http://dl.acm.org/citation.cfm?id=J513 and Systems (March–Dec. 1993) 10. ACM Transactions on Accessible Computing Volume 1 Issue 1 (May 2008) Volume 9 Issue 1 (October 2016) http://dl.acm.org/citation.cfm?id=J1156 11. -

1 Acmsmall Author Submission Guide: Setting up Your Latex2ε Files
1 acmsmall Author Submission Guide: Setting Up Your LATEX2ε Files DONALD E. KNUTH, Stanford University LESLIE LAMPORT, Microsoft Corporation A The LTEX 2ε acmsmall document class formats articles in the style of the ACM small size journals and A transactions. Users who have prepared their document with LTEX 2ε can, with very little effort, produce camera-ready copy for these journals. Categories and Subject Descriptors: D.2.7 [Software Engineering]: Distribution and Maintenance—doc- umentation; H.4.0 [Information Systems Applications]: General; I.7.2 [Text Processing]: Document Preparation—languages; photocomposition General Terms: Documentation, Languages Additional Key Words and Phrases: Document preparation, publications, typesetting ACM Reference Format: Donald E. Knuth and Leslie Lamport. 2010. acmsmall Author submission guide: setting up your LATEX 2ε files. ACM Comput. Surv. 2, 3, Article 1 (July 2010), 14 pages. DOI:http://dx.doi.org/10.1145/0000000.0000000 1. INTRODUCTION This article is a description of the LATEX 2ε acmsmall document class for typesetting articles in the format of the ACM small size transactions and journals—Transactions on Programming Languages and Systems, Journal of the ACM, etc. It has, of course, been typeset using this document class, so it is a self-illustrating article. The reader is assumed to be familiar with LATEX, as described by Lamport [1986]. This document also describes the acmsmall bibliography style. LATEX 2ε is a document preparation system implemented as a macro package in Don- ald Knuth’s TEX typesetting system [Knuth 1984]. It is based upon the premise that the user should describe the logical structure of his document and not how the docu- ment is to be formatted.