Interactive Light Field Tilt-Shift Refocus with Generalized Shift-And-Sum
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Completing a Photography Exhibit Data Tag
Completing a Photography Exhibit Data Tag Current Data Tags are available at: https://unl.box.com/s/1ttnemphrd4szykl5t9xm1ofiezi86js Camera Make & Model: Indicate the brand and model of the camera, such as Google Pixel 2, Nikon Coolpix B500, or Canon EOS Rebel T7. Focus Type: • Fixed Focus means the photographer is not able to adjust the focal point. These cameras tend to have a large depth of field. This might include basic disposable cameras. • Auto Focus means the camera automatically adjusts the optics in the lens to bring the subject into focus. The camera typically selects what to focus on. However, the photographer may also be able to select the focal point using a touch screen for example, but the camera will automatically adjust the lens. This might include digital cameras and mobile device cameras, such as phones and tablets. • Manual Focus allows the photographer to manually adjust and control the lens’ focus by hand, usually by turning the focus ring. Camera Type: Indicate whether the camera is digital or film. (The following Questions are for Unit 2 and 3 exhibitors only.) Did you manually adjust the aperture, shutter speed, or ISO? Indicate whether you adjusted these settings to capture the photo. Note: Regardless of whether or not you adjusted these settings manually, you must still identify the images specific F Stop, Shutter Sped, ISO, and Focal Length settings. “Auto” is not an acceptable answer. Digital cameras automatically record this information for each photo captured. This information, referred to as Metadata, is attached to the image file and goes with it when the image is downloaded to a computer for example. -

Depth-Aware Blending of Smoothed Images for Bokeh Effect Generation
1 Depth-aware Blending of Smoothed Images for Bokeh Effect Generation Saikat Duttaa,∗∗ aIndian Institute of Technology Madras, Chennai, PIN-600036, India ABSTRACT Bokeh effect is used in photography to capture images where the closer objects look sharp and every- thing else stays out-of-focus. Bokeh photos are generally captured using Single Lens Reflex cameras using shallow depth-of-field. Most of the modern smartphones can take bokeh images by leveraging dual rear cameras or a good auto-focus hardware. However, for smartphones with single-rear camera without a good auto-focus hardware, we have to rely on software to generate bokeh images. This kind of system is also useful to generate bokeh effect in already captured images. In this paper, an end-to-end deep learning framework is proposed to generate high-quality bokeh effect from images. The original image and different versions of smoothed images are blended to generate Bokeh effect with the help of a monocular depth estimation network. The proposed approach is compared against a saliency detection based baseline and a number of approaches proposed in AIM 2019 Challenge on Bokeh Effect Synthesis. Extensive experiments are shown in order to understand different parts of the proposed algorithm. The network is lightweight and can process an HD image in 0.03 seconds. This approach ranked second in AIM 2019 Bokeh effect challenge-Perceptual Track. 1. Introduction tant problem in Computer Vision and has gained attention re- cently. Most of the existing approaches(Shen et al., 2016; Wad- Depth-of-field effect or Bokeh effect is often used in photog- hwa et al., 2018; Xu et al., 2018) work on human portraits by raphy to generate aesthetic pictures. -

DEPTH of FIELD CHEAT SHEET What Is Depth of Field? the Depth of Field (DOF) Is the Area of a Scene That Appears Sharp in the Image
Ms. Brown Photography One DEPTH OF FIELD CHEAT SHEET What is Depth of Field? The depth of field (DOF) is the area of a scene that appears sharp in the image. DOF refers to the zone of focus in a photograph or the distance between the closest and furthest parts of the picture that are reasonably sharp. Depth of field is determined by three main attributes: 1) The APERTURE (size of the opening) 2) The SHUTTER SPEED (time of the exposure) 3) DISTANCE from the subject being photographed 4) SHALLOW and GREAT Depth of Field Explained Shallow Depth of Field: In shallow depth of field, the main subject is emphasized by making all other elements out of focus. (Foreground or background is purposely blurry) Aperture: The larger the aperture, the shallower the depth of field. Distance: The closer you are to the subject matter, the shallower the depth of field. ***You cannot achieve shallow depth of field with excessive bright light. This means no bright sunlight pictures for shallow depth of field because you can’t open the aperture wide enough in bright light.*** SHALLOW DOF STEPS: 1. Set your camera to a small f/stop number such as f/2-f/5.6. 2. GET CLOSE to your subject (between 2-5 feet away). 3. Don’t put the subject too close to its background; the farther away the subject is from its background the better. 4. Set your camera for the correct exposure by adjusting only the shutter speed (aperture is already set). 5. Find the best composition, focus the lens of your camera and take your picture. -

Dof 4.0 – a Depth of Field Calculator
DoF 4.0 – A Depth of Field Calculator Last updated: 8-Mar-2021 Introduction When you focus a camera lens at some distance and take a photograph, the further subjects are from the focus point, the blurrier they look. Depth of field is the range of subject distances that are acceptably sharp. It varies with aperture and focal length, distance at which the lens is focused, and the circle of confusion – a measure of how much blurring is acceptable in a sharp image. The tricky part is defining what acceptable means. Sharpness is not an inherent quality as it depends heavily on the magnification at which an image is viewed. When viewed from the same distance, a smaller version of the same image will look sharper than a larger one. Similarly, an image that looks sharp as a 4x6" print may look decidedly less so at 16x20". All other things being equal, the range of in-focus distances increases with shorter lens focal lengths, smaller apertures, the farther away you focus, and the larger the circle of confusion. Conversely, longer lenses, wider apertures, closer focus, and a smaller circle of confusion make for a narrower depth of field. Sometimes focus blur is undesirable, and sometimes it’s an intentional creative choice. Either way, you need to understand depth of field to achieve predictable results. What is DoF? DoF is an advanced depth of field calculator available for both Windows and Android. What DoF Does Even if your camera has a depth of field preview button, the viewfinder image is just too small to judge critical sharpness. -

Depth of Focus (DOF)
Erect Image Depth of Focus (DOF) unit: mm Also known as ‘depth of field’, this is the distance (measured in the An image in which the orientations of left, right, top, bottom and direction of the optical axis) between the two planes which define the moving directions are the same as those of a workpiece on the limits of acceptable image sharpness when the microscope is focused workstage. PG on an object. As the numerical aperture (NA) increases, the depth of 46 focus becomes shallower, as shown by the expression below: λ DOF = λ = 0.55µm is often used as the reference wavelength 2·(NA)2 Field number (FN), real field of view, and monitor display magnification unit: mm Example: For an M Plan Apo 100X lens (NA = 0.7) The depth of focus of this objective is The observation range of the sample surface is determined by the diameter of the eyepiece’s field stop. The value of this diameter in 0.55µm = 0.6µm 2 x 0.72 millimeters is called the field number (FN). In contrast, the real field of view is the range on the workpiece surface when actually magnified and observed with the objective lens. Bright-field Illumination and Dark-field Illumination The real field of view can be calculated with the following formula: In brightfield illumination a full cone of light is focused by the objective on the specimen surface. This is the normal mode of viewing with an (1) The range of the workpiece that can be observed with the optical microscope. With darkfield illumination, the inner area of the microscope (diameter) light cone is blocked so that the surface is only illuminated by light FN of eyepiece Real field of view = from an oblique angle. -

Depth of Field in Photography
Instructor: N. David King Page 1 DEPTH OF FIELD IN PHOTOGRAPHY Handout for Photography Students N. David King, Instructor WWWHAT IS DDDEPTH OF FFFIELD ??? Photographers generally have to deal with one of two main optical issues for any given photograph: Motion (relative to the film plane) and Depth of Field. This handout is about Depth of Field. But what is it? Depth of Field is a major compositional tool used by photographers to direct attention to specific areas of a print or, at the other extreme, to allow the viewer’s eye to travel in focus over the entire print’s surface, as it appears to do in reality. Here are two example images. Depth of Field Examples Shallow Depth of Field Deep Depth of Field using wide aperture using small aperture and close focal distance and greater focal distance Depth of Field in PhotogPhotography:raphy: Student Handout © N. DavDavidid King 2004, Rev 2010 Instructor: N. David King Page 2 SSSURPRISE !!! The first image (the garden flowers on the left) was shot IIITTT’’’S AAALL AN ILLUSION with a wide aperture and is focused on the flower closest to the viewer. The second image (on the right) was shot with a smaller aperture and is focused on a yellow flower near the rear of that group of flowers. Though it looks as if we are really increasing the area that is in focus from the first image to the second, that apparent increase is actually an optical illusion. In the second image there is still only one plane where the lens is critically focused. -

Depth of Field and Depth of Focus Explained
1 Reference: Queries. Vol. 31 /1 Proceedings RMS March 1996 pp64-66 Depth of Field and depth of Focus Explained What is the difference between 'depth of field' and 'depth of focus'? - I have seen both terms used in textbooks This is a good question, which prompts an answer that encompasses more than simply terminology. In the past there has been some confusion about these terms, and they have been used rather indiscriminately. Recently, usage has become more consistent, and when we published the RMS Dictionary of light Microscopy in 1989, we felt able to make an unambiguous distinction in our somewhat ponderous definitions: • Depth of field is the axial depth of the space on both sides of the object plane within which the object can be moved without detectable loss of sharpness in the image, and within which features of the object appear acceptably sharp in the image while the position of the image plane is maintained. • Depth of focus is the axial depth of the space on both sides of the image plane within which the image appears acceptably sharp while the positions of the object plane and of the objective are maintained. The essential distinction between the terms is clear: depth of field refers to object space and depth of focus to image space. A possibly useful mnemonic is that the field of view is that part of the object that is being examined, and the focus is the point at which parallel rays converge after passing through a lens. These definitions contain two rather imprecise terms: detectable loss of sharpness, and acceptably sharp; clearly it all depends on what can be detected and what is considered acceptable. -

Three Techniques for Rendering Generalized Depth of Field Effects
Three Techniques for Rendering Generalized Depth of Field Effects Todd J. Kosloff∗ Computer Science Division, University of California, Berkeley, CA 94720 Brian A. Barskyy Computer Science Division and School of Optometry, University of California, Berkeley, CA 94720 Abstract Post-process methods are fast, sometimes to the point Depth of field refers to the swath that is imaged in sufficient of real-time [13, 17, 9], but generally do not share the focus through an optics system, such as a camera lens. same image quality as distributed ray tracing. Control over depth of field is an important artistic tool that can be used to emphasize the subject of a photograph. In a A full literature review of depth of field methods real camera, the control over depth of field is limited by the is beyond the scope of this paper, but the interested laws of physics and by physical constraints. Depth of field reader should consult the following surveys: [1, 2, 5]. has been rendered in computer graphics, but usually with the same limited control as found in real camera lenses. In Kosara [8] introduced the notion of semantic depth this paper, we generalize depth of field in computer graphics of field, a somewhat similar notion to generalized depth by allowing the user to specify the distribution of blur of field. Semantic depth of field is non-photorealistic throughout a scene in a more flexible manner. Generalized depth of field provides a novel tool to emphasize an area of depth of field used for visualization purposes. Semantic interest within a 3D scene, to select objects from a crowd, depth of field operates at a per-object granularity, and to render a busy, complex picture more understandable allowing each object to have a different amount of blur. -

Lenses and Depth of Field
Lenses and Depth of Field Prepared by Behzad Sajadi Borrowed from Frédo Durand’s Lectures at MIT 3 major type of issues • Diffraction – ripples when aperture is small • Third-order/spherical aberrations – Rays don’t focus – Also coma, astigmatism, field curvature • Chromatic aberration – Focus depends on wavelength References Links • http://en.wikipedia.org/wiki/Chromatic_aberration • http://www.dpreview.com/learn/?/key=chromatic+aberration • http://hyperphysics.phy- astr.gsu.edu/hbase/geoopt/aberrcon.html#c1 • http://en.wikipedia.org/wiki/Spherical_aberration • http://en.wikipedia.org/wiki/Lens_(optics) • http://en.wikipedia.org/wiki/Optical_coating • http://www.vanwalree.com/optics.html • http://en.wikipedia.org/wiki/Aberration_in_optical_systems • http://www.imatest.com/docs/iqf.html • http://www.luminous-landscape.com/tutorials/understanding- series/understanding-mtf.shtml Other quality issues Flare From "The Manual of Photography" Jacobson et al Example of flare "bug" • Some of the first copies of the Canon 24-105 L had big flare problems • http://www.the-digital-picture.com/Reviews/Canon- EF-24-105mm-f-4-L-IS-USM-Lens-Review.aspx • Flare and Ghosting source: canon red book Flare/ghosting special to digital source: canon red book Use a hood! (and a good one) Flare ray Hood is to short Flare Good hood Adapted from Ray's Applied Photographic Optics Lens hood From Ray's Applied Photographic Optics Coating • Use destructive interferences • Optimized for one wavelength From "The Manual of Photography" Jacobson et al Coating for digital source: canon red book Vignetting • The periphery does not get as much light source: canon red book Vignetting • http://www.photozone.de/3Technology/lenstec3.htm Lens design Optimization software • Has revolutionized lens design • E.g. -

3-0 Lrnaaina Past &Besent
sAma3-0lrnaaina Past &besent;3 A 'cAFdklumd National A WOO' A tad8 of the lato *asthrough the early found in amateur stereo slid~s bgm~illlre I This slide is labeled. "Car and Ifail- of the sign says), but it may have Vacationing in Canada er at Eisenhower kct ti on, Canada, consisted of only the small gas sta- ur first view this time was Wednesday, August 15,1956." tion visible in the background! The taken by a Portland, Oregon- Since this same wonderful trailer film chips of this image were area stereographer who appar- and car appear in several of his attached to one of the early Realist 0 shots, I beliwe are what he using ently made numerous road trips, they paper masks the Realist heat- which he documented in stereo. was traveling in at the time. seal mounting kit, and then sand- (My collection of slides by this My atlas does not show an wiched and taped in glass. man includes some wonderful Eisenhower Junction in this area, The second view was made by a stereo views made with a pair of so it may not wen exist any more. different (and unknown) photogra- standard 35mm cameras and It is clear from the sign that it was pher, and is unfortunately unla- Kodachrome film in the late 1930s, on Highway 1, and it was in or beled. However, I think I recognize but he later adopted the Realist near Banff National Park (that's these falls as Athabasca Falls from format once it was introduced.) what the beprint at the bottom my own journey to Canada years ago. -
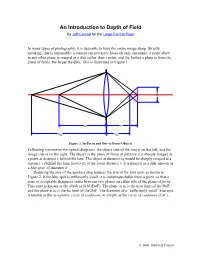
An Introduction to Depth of Field by Jeff Conrad for the Large Format Page
An Introduction to Depth of Field By Jeff Conrad for the Large Format Page In many types of photography, it is desirable to have the entire image sharp. Strictly speaking, this is impossible: a camera can precisely focus on only one plane; a point object in any other plane is imaged as a disk rather than a point, and the farther a plane is from the plane of focus, the larger the disk. This is illustrated in Figure 1. k u v ud vd Figure 1. In-Focus and Out-of-Focus Objects Following convention for optical diagrams, the object side of the lens is on the left, and the image side is on the right. The object in the plane of focus at distance u is sharply imaged as a point at distance v behind the lens. The object at distance ud would be sharply imaged at a distance vd behind the lens; however, at the focus distance v, it is imaged as a disk, known as a blur spot, of diameter k. Reducing the size of the aperture stop reduces the size of the blur spot, as shown in Figure 2. If the blur spot is sufficiently small, it is indistinguishable from a point, so that a zone of acceptable sharpness exists between two planes on either side of the plane of focus. This zone is known as the depth of field (DoF). The plane at un is the near limit of the DoF, and the plane at uf is the far limit of the DoF. The diameter of a “sufficiently small” blur spot is known as the acceptable circle of confusion, or simply as the circle of confusion (CoC). -

Depth of Field & Circle of Confusion
Advanced Photography Topic 6 - Optics – Depth of Field and Circle Of Confusion Learning Outcomes In this lesson, we will learn all about depth of field and a concept known as the Circle of Confusion. By the end of this lesson, you will have a much better understanding of what each of these terms mean and how they impact your photography. Page | 1 Advanced Photography Depth of Field Depth of field refers to the range of distance that appears acceptably sharp. It varies depending on camera type, aperture and focusing distance. The depth of field isn’t something that abruptly changes from sharp to unsharp/soft. It happens as a gradual transition. Everything immediately in front of or behind the focusing distance begins to lose sharpness, even if this is not perceived by our eyes or by the resolution of the camera. Circle of Confusion (CoF) The term called the "circle of confusion" is used to define how much a point needs to be blurred in order to be perceived as unsharp, due to the fact that there is no obvious sharp point in transition. When the circle of confusion becomes perceptible to our eyes, this region is said to be outside the depth of field and thus no longer "acceptably sharp." The circle of confusion in this example has been exaggerated for clarity; in reality this would only be a tiny portion of the camera sensor's area. When does this circle of confusion become perceptible to our eyes? Well, an acceptably sharp circle of confusion is loosely defined as one which would go unnoticed when enlarged to a standard 8x10 inch print, and observed from a standard viewing distance of about 1 foot.