Alan Turing Institute Symposium on Reproducibility for Data-Intensive Research – FINAL REPORT Page | 1 Lucie C
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Annual Report 2018–19
Annual report 2018–19 2018 –19 Annual Report 2018–19 Part 1 Our year 3 Part 2 Trustees’ and strategic report 74 Part 3 Financial statements 84 Our year 1.1 Chair’s foreword 1.2 Institute Director and Chief Executive’s foreword 1 1.3 Outputs, impact and equalities 1.4 Turing trends and statistics 1.5 Research mapping: Linking research, people and activities 3 Creating real world impact We have had yet another year of rapid growth Since 2016, researchers at the Institute have produced and remarkable progress. over 200 publications in leading journals and demonstrated early impacts with great potential. Some of the impacts The Alan Turing Institute is a multidisciplinary institute are captured in this annual report and we are excited to formed through partnerships with some of the UK’s see the translation of our data science and AI research leading universities. This innovative approach gives us into a real-world context. access to expertise and skills in data science and AI that is unparalleled outside of a handful of large tech platforms. We are witnessing a massive growth of data science Our substantial convening power enables us to work and AI. We are also seeing important challenges and across the economy: with large corporations, the public breakthroughs in many areas including safe and ethical sector including government departments, charitable AI, quantum computing, urban transport, defence, foundations and small businesses. These collaborations manufacturing, health and financial services. Across cut across disciplines and break through institutional the Institute we are leading the public conversation in boundaries. -

STEM Education Centre E-Bulletin: March 2014
STEM Education Centre E-bulletin: March 2014 Welcome to the March e-bulletin from the University of Birmingham’s STEM Education Centre. It is designed to provide you with information about STEM-related events, resources, news and updates that may be of interest to you and your colleagues. STEM Policy and Practice News Budget 2014: Alan Turing Institute to lead big data research A £42m Alan Turing Institute is to be founded to ensure that Britain leads the way in big data and algorithm research, George Osborne has announced. Drawing on the name of the British mathematician who led code-breaking work at Bletchley Park during the World War II, the institute is intended to help British companies by bringing together expertise and experience in tackling problems requiring huge computational power. Turing’s work led to the cracking of the German "Enigma" codes, which used highly compl ex encryption, is believed to have saved hundreds or even thousands of lives. He later formed a number of theories that underpin modern computing, and formalised the idea of algorithms – sequences of instructions – for a computer. This announcement marks further official rehabilitation of a scientist who many see as having been treated badly by the British government after his work during the war. Turing, who was gay, was convicted of indecency in March 1952, and lost his security clearance with GCHQ, the successor to Bletchley Park. He killed himself in June 1954. Only after a series of public campaigns was he given an official pardon by the UK government in December 2013. Public Attitudes to Science (PAS) 2014 Public Attitudes to Science (PAS) 2014 is the fifth in a series of studies looking at attitudes to science, scientists and science policy among the UK public. -

CV Adilet Otemissov
CV Adilet Otemissov RESEARCH INTERESTS Global Optimization; Stochastic Methods for Optimisation; Random Matrices EDUCATION DPhil (PhD) in Mathematics 2016{2021 University of Oxford The Alan Turing Institute, the UK's national institute for data science and AI - Thesis title: Dimensionality reduction techniques for global optimization (supervised by Dr Coralia Cartis) MSc in Applied Mathematics with Industrial Modelling 2015{2016 University of Manchester - Thesis title: Matrix Completion and Euclidean Distance Matrices (supervised by Dr Martin Lotz) BSc in Mathematics 2011{2015 Nazarbayev University AWARDS & ACHIEVEMENTS - SEDA Professional Development Framework Supporting Learning award for successfully completing Developing Learning and Teaching course; more details can be found on https://www.seda.ac.uk/supporting-learning, 2020 - The Alan Turing Doctoral Studentship: highly competitive full PhD funding, providing also a vibrant interdisciplinary research environment at the Institute in London, as well as extensive training in the state-of-the-art data science subjects from world's leading researchers, 2016{2020 - NAG MSc student prize in Applied Mathematics with Industrial Modelling for achieving the highest overall mark in the numerical analysis course units in my cohort at the University of Manchester, 2016 PUBLICATIONS - C. Cartis, E. Massart, and A. Otemissov. Applications of conic integral geometry in global optimization. 2021. Research completed, in preparation - C. Cartis, E. Massart, and A. Otemissov. Constrained global optimization of functions with low effective dimensionality using multiple random embeddings. ArXiv e-prints, page arXiv:2009.10446, 2020. Manuscript (41 pages) submitted for publication in Mathematical Programming. Got back from the first round of reviewing - C. Cartis and A. Otemissov. A dimensionality reduction technique for unconstrained global optimization of functions with low effective dimensionality. -

Enabling a World-Leading Regional Digital Economy Through Data Driven Innovation
©Jonathan Clark Fine Art, Representatives of the Artist's Estate Enabling a World-Leading Regional Digital Economy through Data Driven Innovation Edinburgh & South East Scotland City Region A Science and Innovation Audit Report sponsored by the Department for Business, Energy & Industrial Strategy MAIN REPORT Edinburgh and South East Scotland City Region Consortium Foreword In Autumn 2015 the UK Government announced regional Science and Innovation Audits (SIAs) to catalyse a new approach to regional economic development. SIAs enable local Consortia to focus on analysing regional strengths and identify mechanisms to realise their potential. In the Edinburgh and South East Scotland City Region, a Consortium was formed to focus on our rapidly growing strength in Data-Driven Innovation (DDI). This report presents the results which includes broad-ranging analysis of the City Region’s DDI capabilities, the challenges and the substantial opportunities for future economic growth. Data-led disruption will be at the heart of future growth in the Digital Economy, and will enable transformational change across the broader economy. However, the exact scope, scale and timing of these impacts remains unclear1. The questions we face are simple yet far-reaching – given this uncertainty, is now the right time to commit fully to the DDI opportunity? If so, what are the investments we should make to optimise regional economic growth? This SIA provides evidence that we must take concerted action now to best position the City Region to benefit from the disruptive effects of DDI. If investment is deferred, we run the risk of losing both competitiveness and output to other leading digital clusters that have the confidence to invest. -

Annual Report 2015/16
THE ALAN TURING INSTITUTE ANNUAL REPORT AND ACCOUNTS FOR THE PERIOD TO 31 March 2016 Tel: +44 (0) 300 770 1912 British Library Company number: 96 Euston Road 09512457 NW1 2DB Charity Number 1162533 [email protected] turing.ac.uk CONTENTS 04 Chair’s Foreword 05 Director’s Foreword 06 – 09 Trustees’ Report 10 – 22 Independent Auditors Report and Accounts Annual Report and Accounts 03 CHAIR’S FOREWORD formed a trading subsidiary and also Europe. This is a new source of risk for held interviews for our first cohort of all and has introduced an unexpected Turing research fellows. As I write this note of caution into our longer-term we are joined by thirty researchers plans. Like all organisations we for a summer programme and are will do our best to deal with the busily refurbishing space for the 120 consequences of this new uncertainty. or so researchers who will join us in the autumn at the start of our first full Starting the Institute has been academic year. enormously exciting and we are highly optimistic about what the This breathless pace could not Institute will achieve. We will work to have been sustained without achieve our vision to become a world enormous support from all concerned leader in data science research and throughout the UK data science innovation, and to be a great resource community. I would like to thank all for the UK’s data science community, of the colleagues who joined us on for its businesses and for its society secondment in the early months of more generally. -

Multilayer Modeling of Adoption Dynamics in Energy Demand Management
Multilayer modeling of adoption dynamics in energy demand management Cite as: Chaos 30, 013153 (2020); https://doi.org/10.1063/1.5122313 Submitted: 30 July 2019 . Accepted: 14 January 2020 . Published Online: 31 January 2020 Iacopo Iacopini , Benjamin Schäfer , Elsa Arcaute , Christian Beck , and Vito Latora COLLECTIONS Paper published as part of the special topic on Dynamics of Modern Power Grids Note: This paper is part of the Focus Issue on the Dynamics of Modern Power Grids. ARTICLES YOU MAY BE INTERESTED IN Functionability in complex networks: Leading nodes for the transition from structural to functional networks through remote asynchronization Chaos: An Interdisciplinary Journal of Nonlinear Science 30, 013105 (2020); https:// doi.org/10.1063/1.5099621 Merger of a Hénon-like attractor with a Hénon-like repeller in a model of vortex dynamics Chaos: An Interdisciplinary Journal of Nonlinear Science 30, 011105 (2020); https:// doi.org/10.1063/1.5144144 Uncertainty propagation in complex networks: From noisy links to critical properties Chaos: An Interdisciplinary Journal of Nonlinear Science 30, 023129 (2020); https:// doi.org/10.1063/1.5129630 Chaos 30, 013153 (2020); https://doi.org/10.1063/1.5122313 30, 013153 © 2020 Author(s). Chaos ARTICLE scitation.org/journal/cha Multilayer modeling of adoption dynamics in energy demand management Cite as: Chaos 30, 013153 (2020); doi: 10.1063/1.5122313 Submitted: 30 July 2019 · Accepted: 14 January 2020 · Published Online: 31 January 2020 View Online Export Citation CrossMark Iacopo Iacopini,1,2,3,a) -

Evaluating the Impact of Court Reform in England and Wales on Access to Justice
Developing the Detail: Evaluating the Impact of Court Reform in England and Wales on Access to Justice Report and recommendations arising from two expert workshops 1 Acknowledgments The author would like to thank Professor Dame Hazel Genn and Professor Abigail Adams for their helpful comments on an earlier draft. Suggested citation: Byrom, N (2019) “Developing the detail: Evaluating the Impact of Court Reform in England and Wales on Access to Justice” 2 Contents 1 Executive Summary ............................................................................................................................... 4 2 Background ............................................................................................................................................. 6 3 About the workshops ........................................................................................................................... 7 4 Scope of the recommendations ........................................................................................................... 8 5 Defining vulnerability ........................................................................................................................... 9 6 Monitoring fairness ............................................................................................................................. 12 7 Defining “Access to Justice”- An irreducible minimum standard ............................................... 14 8 Component 1: Access to the formal legal system .......................................................................... -

Data Science and AI in the Age of COVID-19
Data science and AI in the age of COVID-19 Reflections on the response of the UK’s data science and AI community to the COVID-19 pandemic Executive summary Contents This report summarises the findings of a science activity during the pandemic. The Foreword 4 series of workshops carried out by The Alan message was clear: better data would Turing Institute, the UK’s national institute enable a better response. Preface 5 for data science and artificial intelligence (AI), in late 2020 following the 'AI and data Third, issues of inequality and exclusion related to data science and AI arose during 1. Spotlighting contributions from the data science 7 science in the age of COVID-19' conference. and AI community The aim of the workshops was to capture the pandemic. These included concerns about inadequate representation of minority the successes and challenges experienced + The Turing's response to COVID-19 10 by the UK’s data science and AI community groups in data, and low engagement with during the COVID-19 pandemic, and the these groups, which could bias research 2. Data access and standardisation 12 community’s suggestions for how these and policy decisions. Workshop participants challenges might be tackled. also raised concerns about inequalities 3. Inequality and exclusion 14 in the ease with which researchers could Four key themes emerged from the access data, and about a lack of diversity 4. Communication 17 workshops. within the research community (and the potential impacts of this). 5. Conclusions 20 First, the community made many contributions to the UK’s response to Fourth, communication difficulties Appendix A. -

International Symposium on Directors' Liability for Climate Change Damages
International Symposium on Directors’ Liability for Climate Change Damages Lady Margaret Hall, University of Oxford 8th June 2016 In Partnership with: International Symposium on Directors’ Liability for Climate Change Damages The Commonwealth Climate and Law Initiative (CCLI) is organising a series of high-level international symposia on the legal exposures of company directors for climate change damages. The first symposium will be held at Lady Margaret Hall, a college within the University of Oxford, on the 8th June 2016. Each symposium will facilitate a cross-institutional and cross-jurisdictional exchange of legal thought leadership on director liability risks relevant to plaintiff and defence lawyers, regulators, investors, accountants, and insurers. It is now clear that climate change presents material – if not unparalleled – economic risks and opportunities. The Bank of England’s Prudential Regulation Authority and others have recently warned of the potential liability exposure of company directors for i) their company's contribution to anthropogenic climate change, ii) a failure to adequately manage the risks associated with climate change, and iii) inaccurate disclosure or reporting of these factors. These emerging exposures have implications for corporate governance in climate- risk exposed industries (from financial services to mining, infrastructure, agriculture, and beyond), and for the insurance sector (in terms of professional indemnity and directors' and officers’ insurance). Despite these risks, there remains little in-depth analysis of how prevailing corporate governance laws and fiduciary duties facilitate – or constrain – the actions of company directors confronted with complex climate change challenges. In light of this and related developments, CCLI has been established as a research, education, and outreach project by the University of Oxford's Smith School of Enterprise and the Environment, HRH The Prince of Wales's Accounting for Sustainability Project, and ClientEarth. -
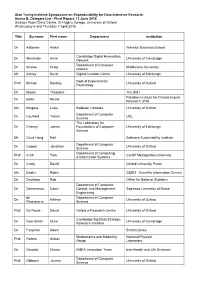
Alan Turing Institute Symposium on Reproducibility for Data-Intensive
Alan Turing Institute Symposium on Reproducibility for Data-Intensive Research Annex B, Delegate List - Final Report, 13 June 2016 Dickson Poon China Centre, St Hugh’s College, University of Oxford Wednesday 6 and Thursday 7 April 2016 Title Surname First name Department Institution Dr Aaltonen Aleksi Warwick Business School Cambridge Digital Humanities Dr Alexander Anne University of Cambridge Network Department of Computer Dr Anslow Craig Middlessex University science Mr Ashley Kevin Digital Curation Centre University of Edinburgh Dept of Experimental Prof Bishop Dorothy University of Oxford Psychology Dr Bloom Theodora The BMJ Potsdam Institute for Climate Impact Dr Botta Nicola Research (PIK) Ms Burgess Lucie Bodleian Libraries University of Oxford Department of Computer Dr Caulfield Tristan UCL Science The Laboratory for Dr Cheney James Foundations of Computer University of Edinburgh Science Mr Chue Hong Neil Software Sustainability Institute Department of Computer Dr Cooper Jonathan University of Oxford Science Department of Computing Prof Crick Tom Cardiff Metropolitan University & Information Systems Dr Crotty David Oxford University Press Ms Dasler Robin CERN - Scientific Information Service Dr Davidson Rob Office for National Statistics Department of Computer, Dr Demetrescu Camil Control, and Management Sapienza University of Rome Engineering de Department of Computer Dr Hélène University of Oxford Ribaupierre Science Prof De Roure David Oxford e-Research Centre University of Oxford Cambridge Big Data Strategic Dr Dyer-Smith -

International Symposium on Directors' Liability for Climate Change Damages
International Symposium on Directors’ Liability for Climate Change Damages Lady Margaret Hall, University of Oxford 8th June 2016 In Partnership with: International Symposium on Directors’ Liability for Climate Change Damages The Commonwealth Climate and Law Initiative (CCLI) is organising a series of high-level international symposia on the legal exposures of company directors for climate change damages. The first symposium will be held at Lady Margaret Hall, a college within the University of Oxford, on the 8th June 2016. Each symposium will facilitate a cross-institutional and cross-jurisdictional exchange of legal thought leadership on director liability risks relevant to plaintiff and defence lawyers, regulators, investors, accountants, and insurers. It is now clear that climate change presents material – if not unparalleled – economic risks and opportunities. The Bank of England’s Prudential Regulation Authority and others have recently warned of the potential liability exposure of company directors for i) their company's contribution to anthropogenic climate change, ii) a failure to adequately manage the risks associated with climate change, and iii) inaccurate disclosure or reporting of these factors. These emerging exposures have implications for corporate governance in climate- risk exposed industries (from financial services to mining, infrastructure, agriculture, and beyond), and for the insurance sector (in terms of professional indemnity and directors' and officers’ insurance). Despite these risks, there remains little in-depth analysis of how prevailing corporate governance laws and fiduciary duties facilitate – or constrain – the actions of company directors confronted with complex climate change challenges. In light of this and related developments, CCLI has been established as a research, education, and outreach project by the University of Oxford's Smith School of Enterprise and the Environment, HRH The Prince of Wales's Accounting for Sustainability Project, and ClientEarth. -

UK Universities & Research Labs Related to Longevity and Geroscience
UK Universities & Research Labs related to Longevity and GeroScience 25 Universities & Research Labs 997 1. Ageing Research at King’s 11. Clinical Ageing Research Unit (CARU) 2. Aston University Aston Research Centre for Healthy 12. Glasgow Ageing Research Network Ageing (ARCHA) 13. Institute of Ageing and Chronic Disease Research 3. Brunei University London Brunei Institute for Ageing 14. Institute of Healthy Ageing (IHA) Studies (BIAS) 15. Manchester Institute for Collaborative Research on 4. Positive Ageing Research Institute Ageing (MICRA) 5. Lancaster University. Faculty of Health & Medicine 16. Medawar Centre for Healthy Ageing Research Centre for Ageing Research (C4AR) 17. Oxford Institute of Population Ageing 6. University of Edinburgh Centre for Cognitive Ageing 18. Salford Institute for Dementia and Cognitive Epidemiology (CCACE) 19. UK Longevity Explorer (UbbLE) 7. University of Liverpool Centre for Integrated Research 20. International Longevity Centre – UK (ILC - UK) into Musculoskeletal Ageing (CIMA) 21. NDORMS (Nuffield Department of Orthopaedics, 8. Newcastle University Centre for Integrated Systems Rheumatology and Musculoskeletal Sciences) Biology of Ageing and Nutrition (CISBAN) 22. The Alan Turing Institute 9. Centre for Research on Ageing (CRA) 23. Francis Crick Institute 10. University Surrey Centre for Research on Ageing and 24. Integrative Genomics of Ageing Group Gender (CRAG) 25. Centre for Social Gerontology - Keele University Ageing Research at 998 King’s Ageing Research at King's (ARK) is a cross-faculty multidisciplinary consortium of investigators which brings together scholarship and research in ageing in several complementary areas. ARK represents King’s world class excellence for research on the biology of ageing, from the basic mechanisms in biogerontology to clinical translation and the social impact of ageing.