1 a Model of Heuristic Judgment1 Daniel Kahneman1 and Shane Frederick2 1Princeton University & 2Massachusetts Institute of T
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

A Task-Based Taxonomy of Cognitive Biases for Information Visualization
A Task-based Taxonomy of Cognitive Biases for Information Visualization Evanthia Dimara, Steven Franconeri, Catherine Plaisant, Anastasia Bezerianos, and Pierre Dragicevic Three kinds of limitations The Computer The Display 2 Three kinds of limitations The Computer The Display The Human 3 Three kinds of limitations: humans • Human vision ️ has limitations • Human reasoning 易 has limitations The Human 4 ️Perceptual bias Magnitude estimation 5 ️Perceptual bias Magnitude estimation Color perception 6 易 Cognitive bias Behaviors when humans consistently behave irrationally Pohl’s criteria distilled: • Are predictable and consistent • People are unaware they’re doing them • Are not misunderstandings 7 Ambiguity effect, Anchoring or focalism, Anthropocentric thinking, Anthropomorphism or personification, Attentional bias, Attribute substitution, Automation bias, Availability heuristic, Availability cascade, Backfire effect, Bandwagon effect, Base rate fallacy or Base rate neglect, Belief bias, Ben Franklin effect, Berkson's paradox, Bias blind spot, Choice-supportive bias, Clustering illusion, Compassion fade, Confirmation bias, Congruence bias, Conjunction fallacy, Conservatism (belief revision), Continued influence effect, Contrast effect, Courtesy bias, Curse of knowledge, Declinism, Decoy effect, Default effect, Denomination effect, Disposition effect, Distinction bias, Dread aversion, Dunning–Kruger effect, Duration neglect, Empathy gap, End-of-history illusion, Endowment effect, Exaggerated expectation, Experimenter's or expectation bias, -

Heuristics and Biases the Psychology of Intuitive Judgment. In
P1: FYX/FYX P2: FYX/UKS QC: FCH/UKS T1: FCH CB419-Gilovich CB419-Gilovich-FM May 30, 2002 12:3 HEURISTICS AND BIASES The Psychology of Intuitive Judgment Edited by THOMAS GILOVICH Cornell University DALE GRIFFIN Stanford University DANIEL KAHNEMAN Princeton University iii P1: FYX/FYX P2: FYX/UKS QC: FCH/UKS T1: FCH CB419-Gilovich CB419-Gilovich-FM May 30, 2002 12:3 published by the press syndicate of the university of cambridge The Pitt Building, Trumpington Street, Cambridge, United Kingdom cambridge university press The Edinburgh Building, Cambridge CB2 2RU, UK 40 West 20th Street, New York, NY 10011-4211, USA 477 Williamstown, Port Melbourne, VIC 3207, Australia Ruiz de Alarcon´ 13, 28014, Madrid, Spain Dock House, The Waterfront, Cape Town 8001, South Africa http://www.cambridge.org C Cambridge University Press 2002 This book is in copyright. Subject to statutory exception and to the provisions of relevant collective licensing agreements, no reproduction of any part may take place without the written permission of Cambridge University Press. First published 2002 Printed in the United States of America Typeface Palatino 9.75/12.5 pt. System LATEX2ε [TB] A catalog record for this book is available from the British Library. Library of Congress Cataloging in Publication data Heuristics and biases : the psychology of intuitive judgment / edited by Thomas Gilovich, Dale Griffin, Daniel Kahneman. p. cm. Includes bibliographical references and index. ISBN 0-521-79260-6 – ISBN 0-521-79679-2 (pbk.) 1. Judgment. 2. Reasoning (Psychology) 3. Critical thinking. I. Gilovich, Thomas. II. Griffin, Dale III. Kahneman, Daniel, 1934– BF447 .H48 2002 153.4 – dc21 2001037860 ISBN 0 521 79260 6 hardback ISBN 0 521 79679 2 paperback iv P1: FYX/FYX P2: FYX/UKS QC: FCH/UKS T1: FCH CB419-Gilovich CB419-Gilovich-FM May 30, 2002 12:3 Contents List of Contributors page xi Preface xv Introduction – Heuristics and Biases: Then and Now 1 Thomas Gilovich and Dale Griffin PART ONE. -

Cognitive Biases in Software Engineering: a Systematic Mapping Study
Cognitive Biases in Software Engineering: A Systematic Mapping Study Rahul Mohanani, Iflaah Salman, Burak Turhan, Member, IEEE, Pilar Rodriguez and Paul Ralph Abstract—One source of software project challenges and failures is the systematic errors introduced by human cognitive biases. Although extensively explored in cognitive psychology, investigations concerning cognitive biases have only recently gained popularity in software engineering research. This paper therefore systematically maps, aggregates and synthesizes the literature on cognitive biases in software engineering to generate a comprehensive body of knowledge, understand state of the art research and provide guidelines for future research and practise. Focusing on bias antecedents, effects and mitigation techniques, we identified 65 articles (published between 1990 and 2016), which investigate 37 cognitive biases. Despite strong and increasing interest, the results reveal a scarcity of research on mitigation techniques and poor theoretical foundations in understanding and interpreting cognitive biases. Although bias-related research has generated many new insights in the software engineering community, specific bias mitigation techniques are still needed for software professionals to overcome the deleterious effects of cognitive biases on their work. Index Terms—Antecedents of cognitive bias. cognitive bias. debiasing, effects of cognitive bias. software engineering, systematic mapping. 1 INTRODUCTION OGNITIVE biases are systematic deviations from op- knowledge. No analogous review of SE research exists. The timal reasoning [1], [2]. In other words, they are re- purpose of this study is therefore as follows: curring errors in thinking, or patterns of bad judgment Purpose: to review, summarize and synthesize the current observable in different people and contexts. A well-known state of software engineering research involving cognitive example is confirmation bias—the tendency to pay more at- biases. -

Mitigating Cognitive Bias and Design Distortion
RSD2 Relating Systems Thinking and Design 2013 Working Paper. www.systemic-design.net Interliminal Design: Mitigating Cognitive Bias and Design Distortion 1 2 3 Andrew McCollough, PhD , DeAunne Denmark, MD, PhD , and Don Harker, MS “Design is an inquiry for action” - Harold Nelson, PhD Liminal: from the Latin word līmen, a threshold “Our values and biases are expressions of who we are. It isn’t so much that our prior commitments disable our ability to reason; it is that we need to appreciate that reasoning takes place, for the most part, in settings in which we are not neutral bystanders.” - Alva Noe In this globally interconnected and information-rich society, complexity and uncertainty are escalating at an unprecedented pace. Our most pressing problems are now considered wicked, or even super wicked, in that they commonly have incomplete, continuously changing, intricately interdependent yet contradictory requirements, urgent or emergency status, no central authority, and are often caused by the same entities charged with solving them (Rittel & Webber, 1973). Perhaps similar to philosopher Karl Jaspers’ Axial Age where ‘man asked radical questions’ and the ‘unquestioned grasp on life was loosened,’ communities of all kinds now face crises of “in-between”; necessary and large-scale dismantling of previous structures, institutions, and world-views has begun, but has yet to be replaced. Such intense periods of destruction and reconstruction, or liminality, eliminate boundary lines, reverse or dissolve social hierarchies, disrupt cultural continuity, and cast penetrating onto future outcomes. Originating in human ritual, liminal stages occur mid-transition, where initiates literally "stand at the threshold" between outmoded constructs of identity or community, and entirely new ways of being. -

Heuristics & Biases Simplified
University of Pennsylvania ScholarlyCommons Master of Behavioral and Decision Sciences Capstones Behavioral and Decision Sciences Program 8-9-2019 Heuristics & Biases Simplified: Easy ot Understand One-Pagers that Use Plain Language & Examples to Simplify Human Judgement and Decision-Making Concepts Brittany Gullone University of Pennsylvania Follow this and additional works at: https://repository.upenn.edu/mbds Part of the Social and Behavioral Sciences Commons Gullone, Brittany, "Heuristics & Biases Simplified: Easy to Understand One-Pagers that Use Plain Language & Examples to Simplify Human Judgement and Decision-Making Concepts" (2019). Master of Behavioral and Decision Sciences Capstones. 7. https://repository.upenn.edu/mbds/7 The final capstone research project for the Master of Behavioral and Decision Sciences is an independent study experience. The paper is expected to: • Present a position that is unique, original and directly applies to the student's experience; • Use primary sources or apply to a primary organization/agency; • Conform to the style and format of excellent academic writing; • Analyze empirical research data that is collected by the student or that has already been collected; and • Allow the student to demonstrate the competencies gained in the master’s program. This paper is posted at ScholarlyCommons. https://repository.upenn.edu/mbds/7 For more information, please contact [email protected]. Heuristics & Biases Simplified: Easy ot Understand One-Pagers that Use Plain Language & Examples to Simplify Human Judgement and Decision-Making Concepts Abstract Behavioral Science is a new and quickly growing field of study that has found ways of capturing readers’ attention across a variety of industries. The popularity of this field has led to a wealth of terms, concepts, and materials that describe human behavior and decision making. -

Anchoring Bias in Eliciting Attribute Weights and Values in Multi-Attribute Decision-Making
Delft University of Technology Anchoring bias in eliciting attribute weights and values in multi-attribute decision-making Rezaei, Jafar DOI 10.1080/12460125.2020.1840705 Publication date 2020 Document Version Final published version Published in Journal of Decision Systems Citation (APA) Rezaei, J. (2020). Anchoring bias in eliciting attribute weights and values in multi-attribute decision-making. Journal of Decision Systems, 30(1), 72-96. https://doi.org/10.1080/12460125.2020.1840705 Important note To cite this publication, please use the final published version (if applicable). Please check the document version above. Copyright Other than for strictly personal use, it is not permitted to download, forward or distribute the text or part of it, without the consent of the author(s) and/or copyright holder(s), unless the work is under an open content license such as Creative Commons. Takedown policy Please contact us and provide details if you believe this document breaches copyrights. We will remove access to the work immediately and investigate your claim. This work is downloaded from Delft University of Technology. For technical reasons the number of authors shown on this cover page is limited to a maximum of 10. Journal of Decision Systems ISSN: (Print) (Online) Journal homepage: https://www.tandfonline.com/loi/tjds20 Anchoring bias in eliciting attribute weights and values in multi-attribute decision-making Jafar Rezaei To cite this article: Jafar Rezaei (2020): Anchoring bias in eliciting attribute weights and values in multi-attribute decision-making, Journal of Decision Systems, DOI: 10.1080/12460125.2020.1840705 To link to this article: https://doi.org/10.1080/12460125.2020.1840705 © 2020 The Author(s). -

The Flushtration Count Illusion: Attribute Substitution Tricks Our Interpretation of a Simple Visual Event Sequence Cyril Thomas
The Flushtration Count Illusion: Attribute substitution tricks our interpretation of a simple visual event sequence Cyril Thomas1, André Didierjean2 and Gustav Kuhn1 1 Department of Psychology 2 Laboratoire de Psychologie & MSHE Goldsmiths University of London Université de Bourgogne-Franche-Comté, New Cross, London SE14 6NW 30 rue Mégevand, 25030 Besançon United Kingdom France Address for correspondence: Cyril Thomas, Department of Psychology, Goldsmiths University of London, New Cross, London SE14 6NW, United Kingdom E-mail: [email protected] Telephone number: +33 (0)3 81 66 51 92 Fax number: +33 (0)3 81 66 54 40 Abstract: When faced with a difficult question, people sometimes work out an answer to a related, easier question without realizing that a substitution has taken place (e.g., Kahneman; 2011). In two experiments, we investigated whether this attribute substitution effect can also affect the interpretation of a simple visual event sequence. We used a magic trick called the “Flushtration Count Illusion,” which involves a technique used by magicians to give the 1 illusion of having seen multiple cards with identical backs, when in fact only the back of one card (the bottom card) is repeatedly shown. In Experiment 1, we demonstrated that most participants are susceptible to the illusion, even if they have the visual and analytical reasoning capacity to correctly process the sequence. In Experiment 2, we demonstrated that participants construct a biased and simplified representation of the Flushtration Count by substituting some attributes of the event sequence. We discussed of the psychological processes underlying this attribute substitution effect. Keywords: Magic, Attribute Substitution Effect, Misdirection, Flushtration Count Illusion, Perception, reasoning, Dual process theory Word Count: 4992. -
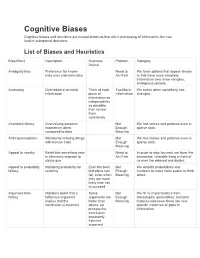
Cognitive Biases Cognitive Biases and Heuristics Are Mental Shortcuts That Aid in Processing of Information, but Can Lead to Suboptimal Decisions
Cognitive Biases Cognitive biases and heuristics are mental shortcuts that aid in processing of information, but can lead to suboptimal decisions. List of Biases and Heuristics Bias/Effect Description Business Problem Category Advice Ambiguity bias Preference for known Need to We favor options that appear simple risks over unknown risks Act Fast or that have more complete information over more complex, ambiguous options. Anchoring Overreliance on initial Think of each Too Much We notice when something has information piece of Information changed. information as independently as possible, then review them collectively Anecdotal fallacy Overvaluing personal Not We find stories and patterns even in experience when Enough sparse data. compared to data Meaning Anthropomorphism Mistakenly imbuing things Not We find stories and patterns even in with human traits Enough sparse data. Meaning Appeal to novelty Belief that something new Need to In order to stay focused, we favor the is inherently superior to Act Fast immediate, relatable thing in front of status quo us over the delayed and distant. Appeal to probability Mistaking probability for Even the best Not We simplify probabilities and fallacy certainty laid plans can Enough numbers to make them easier to think fail, even when Meaning about. they are more likely than not to succeed Argument from Mistaken belief that a Some Not We fill in characteristics from fallacy fallacious argument arguments are Enough stereotypes, generalities, and prior implies that the better than Meaning histories -

Attribute Substitution in Systems Engineering
Regular Paper Attribute Substitution in Systems Engineering Eric D. Smith1, * and A. Terry Bahill2 1Systems Engineering Program, Industrial Engineering Department, University of Texas at El Paso, El Paso, TX 79968 2Systems & Industrial Engineering Department, University of Arizona, Tucson, AZ ATTRIBUTE SUBSTITUTION IN SYSTEMS ENGINEERING Received 3 December 2008; Accepted 19 February 2009, after one or more revisions Published online in Wiley InterScience (www.interscience.wiley.com) DOI 10.1002/sys.20138 ABSTRACT Cognitive biases affect decision making in systems engineering (SE). Daniel Kahneman, 2002 Nobel laureate for his pioneering studies of cognitive biases in economic decision making, describes many disparate cognitive biases as abstractly belonging to one higher-level bias, that of attribute substitution. Attribute substitution occurs when an answer about a target attribute is unconscientiously provided by referring to a sublevel heuristic attribute that is simpler or more easily accessible, while other subattrib- utes are ignored. The essence of this biasing process is generalized with real examples at all phases of the systems engineering process. Willful awareness of attribute substitution, however, can help prevent erroneous reduction in focus, and ensure that valid systems are being built to satisfy customer needs. © 2009 Wiley Periodcals, Inc. Syst Eng Key words: attribute substitution; systems engineering; cognitive biases; abstraction; generalization; tradeoff studies; mental mistakes 1. INTRODUCTION tailored to specific situations, so Generic Attributes (GA) have gained acceptance for general process performance appraisal Everyone uses attribute substitution. For example, if you own [EIA/IS-731, 2002]. (The present paper does not follow the an old car and you want to know the amount of wear on the software engineering definition of “attributes” as variables engine, then you could measure the thickness of the piston within classes.) Historically, attributes were discussed by rings. -

Hazardous Heuristics Cass R
University of Chicago Law School Chicago Unbound Public Law and Legal Theory Working Papers Working Papers 2002 Hazardous Heuristics Cass R. Sunstein Follow this and additional works at: https://chicagounbound.uchicago.edu/ public_law_and_legal_theory Part of the Law Commons Chicago Unbound includes both works in progress and final versions of articles. Please be aware that a more recent version of this article may be available on Chicago Unbound, SSRN or elsewhere. Recommended Citation Cass R. Sunstein, "Hazardous Heuristics" (University of Chicago Public Law & Legal Theory Working Paper No. 33, 2002). This Working Paper is brought to you for free and open access by the Working Papers at Chicago Unbound. It has been accepted for inclusion in Public Law and Legal Theory Working Papers by an authorized administrator of Chicago Unbound. For more information, please contact [email protected]. CHICAGO PUBLIC LAW AND LEGAL THEORY WORKING PAPER NO. 33 HAZARDOUS HEURISTICS Cass R. Sunstein THE LAW SCHOOL THE UNIVERSITY OF CHICAGO This paper can be downloaded without charge at: The Social Science Research Network Electronic Paper Collection: http://ssrn.com/abstract_id= 1 Hazardous Heuristics Cass R. Sunstein* Abstract New work on heuristics and biases has explored the role of emotions and affect; the idea of “dual processing”; the place of heuristics and biases outside of the laboratory; and the implications of heuristics and biases for policy and law. This review- essay focuses on certain aspects of Heuristics and Biases: The Psychology of Intuitive Judgment, edited by Thomas Gilovich, Dale Griffin, and Daniel Kahneman. An understanding of heuristics and biases casts light on many issues in law, involving jury awards, risk regulation, and political economy in general. -

An Inclusive Taxonomy of Behavioral Biases
View metadata, citation and similar papers at core.ac.uk brought to you by CORE provided by European Journal of Government and Economics European Journal of Government and Economics 6(1), June 2017, 24-58. European Journal of Government and Economics journal homepage: www.ejge.org ISSN: 2254-7088 An inclusive taxonomy of behavioral biases David Peóna, *, Manel Antelob, Anxo Calvo-Silvosaa a Department of Business Studies, Universidade da Coruña, Spain. b Department of Economics, University of Santiago de Compostela, Spain. * Corresponding author at: Departamento de Empresa. Universidade da Coruña, Campus de Elviña s/n, 15071 A Coruña, Spain. email: [email protected] Article history. Received 25 May 2016; first revision required 9 December 2016; accepted 27 February 2017. Abstract. This paper overviews the theoretical and empirical research on behavioral biases and their influence in the literature. To provide a systematic exposition, we present a unified framework that takes the reader through an original taxonomy, based on the reviews of relevant authors in the field. In particular, we establish three broad categories that may be distinguished: heuristics and biases; choices, values and frames; and social factors. We then describe the main biases within each category, and revise the main theoretical and empirical developments, linking each bias with other biases and anomalies that are related to them, according to the literature. Keywords. Behavioral biases; decision-making; heuristics; framing; prospect theory; social contagion. JEL classification. D03; G02; G11; G14; G30 1. Introduction The standard model of rational choice argues that people choose to follow the option that maximizes expected utility. However, this ignores the presence of behavioral biases, i.e. -
A Perspective on Judgment and Choice Mapping Bounded Rationality
A Perspective on Judgment and Choice Mapping Bounded Rationality Daniel Kahneman Princeton University Early studies of intuitive judgment and decision making sents an attribute substitution model of heuristic judg- conducted with the late Amos Tversky are reviewed in the ment. The fifth section, Prototype Heuristics, describes context of two related concepts: an analysis of accessibil- that particular family of heuristics. A concluding section ity, the ease with which thoughts come to mind; a distinc- follows. tion between effortless intuition and deliberate reasoning. Intuitive thoughts, like percepts, are highly accessible. De- Intuition and Accessibility terminants and consequences of accessibility help explain From its earliest days, the research that Tversky and I the central results of prospect theory, framing effects, the conducted was guided by the idea that intuitive judgments heuristic process of attribute substitution, and the charac- occupy a position—perhaps corresponding to evolutionary teristic biases that result from the substitution of nonexten- history—between the automatic operations of perception sional for extensional attributes. Variations in the accessi- and the deliberate operations of reasoning. Our first joint bility of rules explain the occasional corrections of intuitive article examined systematic errors in the casual statistical judgments. The study of biases is compatible with a view of judgments of statistically sophisticated researchers (Tver- intuitive thinking and decision making as generally skilled sky & Kahneman, 1971). Remarkably, the intuitive judg- and successful. ments of these experts did not conform to statistical prin- ciples with which they were thoroughly familiar. In particular, their intuitive statistical inferences and their he work cited by the Nobel committee was done estimates of statistical power showed a striking lack of jointly with the late Amos Tversky (1937–1996) sensitivity to the effects of sample size.