Kernel Based Mechanisms for High Performance I/O
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Storage Administration Guide Storage Administration Guide SUSE Linux Enterprise Server 12 SP4
SUSE Linux Enterprise Server 12 SP4 Storage Administration Guide Storage Administration Guide SUSE Linux Enterprise Server 12 SP4 Provides information about how to manage storage devices on a SUSE Linux Enterprise Server. Publication Date: September 24, 2021 SUSE LLC 1800 South Novell Place Provo, UT 84606 USA https://documentation.suse.com Copyright © 2006– 2021 SUSE LLC and contributors. All rights reserved. Permission is granted to copy, distribute and/or modify this document under the terms of the GNU Free Documentation License, Version 1.2 or (at your option) version 1.3; with the Invariant Section being this copyright notice and license. A copy of the license version 1.2 is included in the section entitled “GNU Free Documentation License”. For SUSE trademarks, see https://www.suse.com/company/legal/ . All other third-party trademarks are the property of their respective owners. Trademark symbols (®, ™ etc.) denote trademarks of SUSE and its aliates. Asterisks (*) denote third-party trademarks. All information found in this book has been compiled with utmost attention to detail. However, this does not guarantee complete accuracy. Neither SUSE LLC, its aliates, the authors nor the translators shall be held liable for possible errors or the consequences thereof. Contents About This Guide xii 1 Available Documentation xii 2 Giving Feedback xiv 3 Documentation Conventions xiv 4 Product Life Cycle and Support xvi Support Statement for SUSE Linux Enterprise Server xvii • Technology Previews xviii I FILE SYSTEMS AND MOUNTING 1 1 Overview -

SAS Storage Architecture: Serial Attached SCSI, 2005, Mike Jackson, 0977087808, 9780977087808, Mindshare Press, 2005
SAS Storage Architecture: Serial Attached SCSI, 2005, Mike Jackson, 0977087808, 9780977087808, MindShare Press, 2005 DOWNLOAD http://bit.ly/1zNQCoA http://www.barnesandnoble.com/s/?store=book&keyword=SAS+Storage+Architecture%3A+Serial+Attached+SCSI SAS (Serial Attached SCSI) is the serial storage interface that has been designed to replace and upgrade SCSI, by far the most popular storage interface for high-performance systems for many years. Retaining backward compatibility with the millions of lines of code written to support SCSI devices, SAS incorporates recent advances in high-speed serial design to provide better performance, better reliability and enhanced capabilities, all at a lower cost. SAS will be a significant part of many future high-performance storage systems, and hardware designers, system validation engineers, device driver developers and others working in this area will need a working knowledge of it.SAS Storage Architecture provides a comprehensive guide to the SAS standard. The book contains descriptions and numerous examples of the concepts presented, using the same building block approach as other MindShare offerings. This book details important concepts relating to the design and implementation of storage networks.Specific topics of interest include:SATA Compatibility Expander devices Discovery Process Connection protocols Arbitration of competing connection requests Flow Control protocols ACK/NAK protocol Primitives ? construction and uses Frames ? format, definition, used of each field Error checking mechanisms -

Crack Iscsi Cake 197
1 / 2 Crack Iscsi Cake 197 Open-E DSS V7 increases iSCSI target efficiency by supporting ... drive serial number and the drive serial number information from the robotic library), ... Open-E DSS V7 MANUAL www.open-e.com. 197 work in that User .... nuance pdf converter professional 8 crack keygen · avunu telugu movie english subtitles download torrent · Veerappan ... Crack Iscsi Cake 197.. Crack Iscsi Cake 1.97. Download. Crack Iscsi Cake 1.97. ISCSI...CAKE...1.8.0418...CRACK.. Merci..de..tlcharger..iSCSI.. Contribute to Niarfe/hack-recommender development by creating an account on GitHub. ... 197, ETAP. 198, EtQ. 199, Cincom Eloquence ... 1022, Adobe Target. 1023, Adobe ... 3485, Dell EqualLogic PS6500E iSCSI SAN Storage. 3486, Dell .... iscsi cake, iscsi cake crack, iscsi cake 1.8 crack full, iscsi cake 1.97 full, iscsi cake tutorial, iscsi cake 1.9 crack, iscsi cake 1.9 full, iscsi cake .... Crack Iscsi Cake 197 iscsi cake, iscsi cake 1.8 crack full, iscsi cake 1.9, iscsi cake full, iscsi cake 1.9 expired, iscsi cake crack, iscsi cake 1.9 full, .... Crack Iscsi Cake 197. June 16 2020 0. iscsi cake, iscsi cake 1.8 crack full, iscsi cake full, iscsi cake 1.8 serial number, iscsi cake 1.9, iscsi cake crack, iscsi cake ... Serial interface and protocol. Standard PC mice once used the RS-232C serial port via a D-subminiature connector, which provided power to run the mouse's .... Avira Phantom VPN Pro v3.7.1.26756 Final Crack (2018) .rar · fb limiter pro cracked full version ... Crack Iscsi Cake 197 · Hoshi Wo Katta Hi ... -

SAS Enters the Mainstream Although Adoption of Serial Attached SCSI
SAS enters the mainstream By the InfoStor staff http://www.infostor.com/articles/article_display.cfm?Section=ARTCL&C=Newst&ARTICLE_ID=295373&KEYWORDS=Adaptec&p=23 Although adoption of Serial Attached SCSI (SAS) is still in the infancy stages, the next 12 months bode well for proponents of the relatively new disk drive/array interface. For example, in a recent InfoStor QuickVote reader poll, 27% of the respondents said SAS will account for the majority of their disk drive purchases over the next year, although Serial ATA (SATA) topped the list with 37% of the respondents, followed by Fibre Channel with 32%. Only 4% of the poll respondents cited the aging parallel SCSI interface (see figure). However, surveys of InfoStor’s readers are skewed by the fact that almost half of our readers are in the channel (primarily VARs and systems/storage integrators), and the channel moves faster than end users in terms of adopting (or at least kicking the tires on) new technologies such as serial interfaces. Click here to enlarge image To get a more accurate view of the pace of adoption of serial interfaces such as SAS, consider market research predictions from firms such as Gartner and International Data Corp. (IDC). Yet even in those firms’ predictions, SAS is coming on surprisingly strong, mostly at the expense of its parallel SCSI predecessor. For example, Gartner predicts SAS disk drives will account for 16.4% of all multi-user drive shipments this year and will garner almost 45% of the overall market in 2009 (see figure on p. 18). -

Gen 6 Fibre Channel Technology
WHITE PAPER Better Performance, Better Insight for Your Mainframe Storage Network with Brocade Gen 6 TABLE OF CONTENTS Brocade and the IBM z Systems IO product team share a unique Overview .............................................................. 1 history of technical development, which has produced the world’s most Technology Highlights .................................. 2 advanced mainframe computing and storage systems. Brocade’s Gen 6 Fibre Channel Technology technical heritage can be traced to the late 1980s, with the creation of Benefits for z Systems and Flash channel extension technologies to extend data centers beyond the “glass- Storage ................................................................ 7 house.” IBM revolutionized the classic “computer room” with the invention Summary ............................................................. 9 of the original ESCON Storage Area Network (SAN) of the 1990s, and, in the 2000s, it facilitated geographically dispersed FICON® storage systems. Today, the most compelling innovations in mainframe storage networking technology are the product of this nearly 30-year partnership between Brocade and IBM z Systems. As the flash era of the 2010s disrupts between the business teams allows both the traditional mainframe storage organizations to guide the introduction networking mindset, Brocade and of key technologies to the market place, IBM have released a series of features while the integration between the system that address the demands of the data test and qualification teams ensures the center. These technologies leverage the integrity of those products. Driving these fundamental capabilities of Gen 5 and efforts are the deep technical relationships Gen 6 Fibre Channel, and extend them to between the Brocade and IBM z Systems the applications driving the world’s most IO architecture and development teams, critical systems. -

For Immediate Release
an ellisys company FOR IMMEDIATE RELEASE SerialTek Contact: Simon Thomas, Director, Sales and Marketing Phone: +1-720-204-2140 Email: [email protected] SerialTek Debuts PCIe x16 Gen5 Protocol Analysis System and Web Application New Kodiak™ Platform Brings SerialTek Advantages to More Computing and Data Storage Markets Longmont, CO, USA — February 24, 2021 — SerialTek, a leading provider of protocol test solutions for PCI Express®, NVM Express®, Serial Attached SCSI, and Serial ATA, today introduced an advancement in the PCIe® test and analysis market with the release of the Kodiak PCIe x16 Gen5 Analysis System, as well as the industry’s first calibration-free PCIe x16 add-in-card (AIC) interposer and a new web-based BusXpert™ user interface to manage and analyze traces more efficiently than ever. The addition of PCIe x16 Gen5 to the Kodiak analyzer and SI-Fi™ interposer family brings previously unavailable analysis capabilities and efficiencies to computing, datacenter, networking, storage, AI, and other PCIe x16 Gen5 applications. With SerialTek’s proven calibration-free SI-Fi interposer technology, the Kodiak’s innovative state-of-the-art design, and the new BusXpert analyzer software, users can more easily set up the analyzer hardware, more accurately probe PCIe signals, and more efficiently analyze traces. Kodiak PCIe x16 Gen5 Analysis System At the core of the Kodiak PCIe x16 analyzer is an embedded hardware architecture that delivers substantial and unparalleled advancements in capture, search, and processing acceleration. Interface responsiveness is markedly advanced, searches involving massive amounts of data are fast, and hardware filtering is flexible and powerful. “Once installed in a customer test environment the Kodiak’s features and benefits are immediately obvious,” said Paul Mutschler, CEO of SerialTek. -

Serial Attached SCSI (SAS)
Storage A New Technology Hits the Enterprise Market: Serial Attached SCSI (SAS) A New Interface Technology Addresses New Requirements Enterprise data access and transfer demands are no longer driven by advances in CPU processing power alone. Beyond the sheer volume of data, information routinely consists of rich content that increases the need for capacity. High-speed networks have increased the velocity of data center activity. Networked applications have increased the rate of transactions. Serial Attached SCSI (SAS) addresses the technical requirements for performance and availability in these more I/O-intensive, mission-critical environments. Still, IT managers are pressed on the other side by cost constraints and the need White paper for flexibility and scalability in their systems. While application requirements are the first measure of a storage technology, systems based on SAS deliver on this second front as well. Because SAS is software compatible with Parallel SCSI and is interoperable with Serial ATA (SATA), SAS technology offers the ability to manage costs by staging deployment and fine-tuning a data center’s storage configuration on an ongoing basis. When presented in a small form factor (SFF) 2.5” hard disk drive, SAS even addresses the increasingly important facility considerations of space, heat, and power consumption in the data center. The backplanes, enclosures and cabling are less cumbersome than before. Connectors are smaller, cables are thinner and easier to route impeding less airflow, and both SAS and SATA HDDs can share a common backplane. White paper Getting this new technology to the market in a workable, compatible fashion takes various companies coming together. -

Serial Attached SCSI (SAS) Interface Manual
Users Guide Serial Attached SCSI (SAS) Interface Manual Users Guide Serial Attached SCSI (SAS) Interface Manual ©2003, 2004, 2005, 2006 Seagate Technology LLC All rights reserved Publication number: 100293071, Rev. B May 2006 Seagate, Seagate Technology, and the Seagate logo are registered trademarks of Seagate Technology LLC. SeaTools, SeaFAX, SeaFONE, SeaBOARD, and SeaTDD are either registered trademarks or trade- marks of Seagate Technology LLC. Other product names are registered trademarks or trademarks of their owners. Seagate reserves the right to change, without notice, product offerings or specifications. No part of this publication may be reproduced in any form without written permission of Seagate Technology LLC. Revision status summary sheet Revision Date Writers/Engineers Notes Rev. A 11/11/04 J. Coomes Initial release. Rev. B 05/07/06 C. Chalupa, J. Coomes, G. Houlder All. Contents 1.0 Interface requirements. 1 1.1 Acknowledgements . 1 1.2 How to use this interface manual . 1 1.2.1 Scope . 2 1.2.2 Applicable specifications . 2 1.2.3 Other references . 3 1.3 General interface description. 3 1.3.1 Introduction to Serial Attached SCSI Interface (SAS) . 3 1.3.2 The SAS interface . 3 1.3.3 Glossary . 5 1.3.4 Keywords . 16 1.4 Physical interface characteristics. 17 1.5 Bit and byte ordering . 17 2.0 General . 19 2.1 Architecture . 19 2.1.1 Architecture overview . 19 2.1.2 Physical links and phys . 19 2.1.3 Ports (narrow ports and wide ports) . 20 2.1.4 SAS devices . 21 2.1.5 Expander devices (edge expander devices and fanout expander devices) . -

EMC’S Perspective: a Look Forward
The Performance Impact of NVM Express and NVM Express over Fabrics PRESENTATION TITLE GOES HERE Live: November 13, 2014 Presented by experts from Cisco, EMC and Intel Webcast Presenters J Metz, R&D Engineer for the Office of the CTO, Cisco Amber Huffman, Senior Principal Engineer, Intel Steve Sardella , Distinguished Engineer, EMC Dave Minturn, Storage Architect, Intel SNIA Legal Notice The material contained in this tutorial is copyrighted by the SNIA unless otherwise noted. Member companies and individual members may use this material in presentations and literature under the following conditions: Any slide or slides used must be reproduced in their entirety without modification The SNIA must be acknowledged as the source of any material used in the body of any document containing material from these presentations. This presentation is a project of the SNIA Education Committee. Neither the author nor the presenter is an attorney and nothing in this presentation is intended to be, or should be construed as legal advice or an opinion of counsel. If you need legal advice or a legal opinion please contact your attorney. The information presented herein represents the author's personal opinion and current understanding of the relevant issues involved. The author, the presenter, and the SNIA do not assume any responsibility or liability for damages arising out of any reliance on or use of this information. NO WARRANTIES, EXPRESS OR IMPLIED. USE AT YOUR OWN RISK. 3 What This Presentation Is A discussion of a new way of talking to Non-Volatile -

Comparing Fibre Channel, Serial Attached SCSI (SAS) and Serial ATA (SATA)
Comparing Fibre Channel, Serial Attached SCSI (SAS) and Serial ATA (SATA) by Allen Hin Wing Lam Bachelor ofElectrical Engineering Carleton University 1996 PROJECT SUBMITTED IN PARTIAL FULFILLMENT OF THE REQUIREMENTS FOR THE DEGREE OF MASTER OF ENGINEERING In the School ofEngineering Science © Allen Hin Wing Lam 2009 SIMON FRASER UNIVERSITY Fall 2009 All rights reserved. However, in accordance with the Copyright Act ofCanada, this work may be reproduced, without authorization, under the conditions for Fair Dealing. Therefore, limited reproduction ofthis work for the purposes ofprivate study, research, criticism, review and news reporting is likely to be in accordance with the law, particularly ifcited appropriately. Approval Name: Allen Hin Wing Lam Degree: Master ofEngineering Title ofProject: Comparing Fibre Channel, Serial Attached SCSI (SAS) and Serial ATA (SATA) Examining Committee: Chair: Dr. Daniel Lee Chair ofCommittee Associate Professor, School ofEngineering Science Simon Fraser University Dr. Stephen Hardy Senior Supervisor Professor, School ofEngineering Science Simon Fraser University Jim Younger Manager, Product Engineering PMC- Sierra, Inc. Date ofDefence/Approval r 11 SIMON FRASER UNIVERSITY LIBRARY Declaration of Partial Copyright Licence The author, whose copyright is declared on the title page of this work, has granted to Simon Fraser University the right to lend this thesis, project or extended essay to users of the Simon Fraser University Library, and to make partial or single copies only for such users or in response -
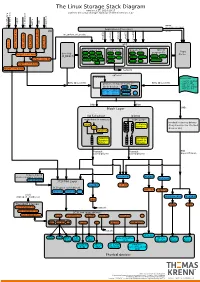
The Linux Storage Stack Diagram
The Linux Storage Stack Diagram version 3.17, 2014-10-17 outlines the Linux storage stack as of Kernel version 3.17 ISCSI USB mmap Fibre Channel Fibre over Ethernet Fibre Channel Fibre Virtual Host Virtual FireWire (anonymous pages) Applications (Processes) LIO malloc vfs_writev, vfs_readv, ... ... stat(2) read(2) open(2) write(2) chmod(2) VFS tcm_fc sbp_target tcm_usb_gadget tcm_vhost tcm_qla2xxx iscsi_target_mod block based FS Network FS pseudo FS special Page ext2 ext3 ext4 proc purpose FS target_core_mod direct I/O NFS coda sysfs Cache (O_DIRECT) xfs btrfs tmpfs ifs smbfs ... pipefs futexfs ramfs target_core_file iso9660 gfs ocfs ... devtmpfs ... ceph usbfs target_core_iblock target_core_pscsi network optional stackable struct bio - sector on disk BIOs (Block I/O) BIOs (Block I/O) - sector cnt devices on top of “normal” - bio_vec cnt block devices drbd LVM - bio_vec index - bio_vec list device mapper mdraid dm-crypt dm-mirror ... dm-cache dm-thin bcache BIOs BIOs Block Layer BIOs I/O Scheduler blkmq maps bios to requests multi queue hooked in device drivers noop Software (they hook in like stacked ... Queues cfq devices do) deadline Hardware Hardware Dispatch ... Dispatch Queue Queues Request Request BIO based Drivers based Drivers based Drivers request-based device mapper targets /dev/nullb* /dev/vd* /dev/rssd* dm-multipath SCSI Mid Layer /dev/rbd* null_blk SCSI upper level drivers virtio_blk mtip32xx /dev/sda /dev/sdb ... sysfs (transport attributes) /dev/nvme#n# /dev/skd* rbd Transport Classes nvme skd scsi_transport_fc network -

Unbreakable Enterprise Kernel Release Notes for Unbreakable Enterprise Kernel Release 3
Unbreakable Enterprise Kernel Release Notes for Unbreakable Enterprise Kernel Release 3 E48380-10 June 2020 Oracle Legal Notices Copyright © 2013, 2020, Oracle and/or its affiliates. This software and related documentation are provided under a license agreement containing restrictions on use and disclosure and are protected by intellectual property laws. Except as expressly permitted in your license agreement or allowed by law, you may not use, copy, reproduce, translate, broadcast, modify, license, transmit, distribute, exhibit, perform, publish, or display any part, in any form, or by any means. Reverse engineering, disassembly, or decompilation of this software, unless required by law for interoperability, is prohibited. The information contained herein is subject to change without notice and is not warranted to be error-free. If you find any errors, please report them to us in writing. If this is software or related documentation that is delivered to the U.S. Government or anyone licensing it on behalf of the U.S. Government, then the following notice is applicable: U.S. GOVERNMENT END USERS: Oracle programs (including any operating system, integrated software, any programs embedded, installed or activated on delivered hardware, and modifications of such programs) and Oracle computer documentation or other Oracle data delivered to or accessed by U.S. Government end users are "commercial computer software" or "commercial computer software documentation" pursuant to the applicable Federal Acquisition Regulation and agency-specific supplemental regulations. As such, the use, reproduction, duplication, release, display, disclosure, modification, preparation of derivative works, and/or adaptation of i) Oracle programs (including any operating system, integrated software, any programs embedded, installed or activated on delivered hardware, and modifications of such programs), ii) Oracle computer documentation and/or iii) other Oracle data, is subject to the rights and limitations specified in the license contained in the applicable contract.