C1q a Fresh Look Upon an Old Molecule
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Human and Mouse CD Marker Handbook Human and Mouse CD Marker Key Markers - Human Key Markers - Mouse
Welcome to More Choice CD Marker Handbook For more information, please visit: Human bdbiosciences.com/eu/go/humancdmarkers Mouse bdbiosciences.com/eu/go/mousecdmarkers Human and Mouse CD Marker Handbook Human and Mouse CD Marker Key Markers - Human Key Markers - Mouse CD3 CD3 CD (cluster of differentiation) molecules are cell surface markers T Cell CD4 CD4 useful for the identification and characterization of leukocytes. The CD CD8 CD8 nomenclature was developed and is maintained through the HLDA (Human Leukocyte Differentiation Antigens) workshop started in 1982. CD45R/B220 CD19 CD19 The goal is to provide standardization of monoclonal antibodies to B Cell CD20 CD22 (B cell activation marker) human antigens across laboratories. To characterize or “workshop” the antibodies, multiple laboratories carry out blind analyses of antibodies. These results independently validate antibody specificity. CD11c CD11c Dendritic Cell CD123 CD123 While the CD nomenclature has been developed for use with human antigens, it is applied to corresponding mouse antigens as well as antigens from other species. However, the mouse and other species NK Cell CD56 CD335 (NKp46) antibodies are not tested by HLDA. Human CD markers were reviewed by the HLDA. New CD markers Stem Cell/ CD34 CD34 were established at the HLDA9 meeting held in Barcelona in 2010. For Precursor hematopoetic stem cell only hematopoetic stem cell only additional information and CD markers please visit www.hcdm.org. Macrophage/ CD14 CD11b/ Mac-1 Monocyte CD33 Ly-71 (F4/80) CD66b Granulocyte CD66b Gr-1/Ly6G Ly6C CD41 CD41 CD61 (Integrin b3) CD61 Platelet CD9 CD62 CD62P (activated platelets) CD235a CD235a Erythrocyte Ter-119 CD146 MECA-32 CD106 CD146 Endothelial Cell CD31 CD62E (activated endothelial cells) Epithelial Cell CD236 CD326 (EPCAM1) For Research Use Only. -

NKG2D Promotes B1a Cell Development and Protection
NKG2D Promotes B1a Cell Development and Protection against Bacterial Infection Maja Lenartic, Vedrana Jelencic, Biljana Zafirova, Mateja Ozanic, Valentina Marecic, Slaven Jurkovic, Veronika Sexl, This information is current as Marina Santic, Felix M. Wensveen and Bojan Polic of September 25, 2021. J Immunol 2017; 198:1531-1542; Prepublished online 13 January 2017; doi: 10.4049/jimmunol.1600461 http://www.jimmunol.org/content/198/4/1531 Downloaded from Supplementary http://www.jimmunol.org/content/suppl/2017/01/12/jimmunol.160046 Material 1.DCSupplemental http://www.jimmunol.org/ References This article cites 45 articles, 18 of which you can access for free at: http://www.jimmunol.org/content/198/4/1531.full#ref-list-1 Why The JI? Submit online. • Rapid Reviews! 30 days* from submission to initial decision by guest on September 25, 2021 • No Triage! Every submission reviewed by practicing scientists • Fast Publication! 4 weeks from acceptance to publication *average Subscription Information about subscribing to The Journal of Immunology is online at: http://jimmunol.org/subscription Permissions Submit copyright permission requests at: http://www.aai.org/About/Publications/JI/copyright.html Email Alerts Receive free email-alerts when new articles cite this article. Sign up at: http://jimmunol.org/alerts The Journal of Immunology is published twice each month by The American Association of Immunologists, Inc., 1451 Rockville Pike, Suite 650, Rockville, MD 20852 Copyright © 2017 by The American Association of Immunologists, Inc. All rights reserved. Print ISSN: 0022-1767 Online ISSN: 1550-6606. The Journal of Immunology NKG2D Promotes B1a Cell Development and Protection against Bacterial Infection Maja Lenartic´,* Vedrana Jelencic´,* Biljana Zafirova,*,† Mateja Ozanic,‡ Valentina Marecic´,‡ Slaven Jurkovic´,x Veronika Sexl,{ Marina Santic ´,‡ Felix M. -

CD93 and Dystroglycan Cooperation in Human Endothelial Cell Adhesion and Migration
www.impactjournals.com/oncotarget/ Oncotarget, Vol. 7, No. 9 CD93 and dystroglycan cooperation in human endothelial cell adhesion and migration Federico Galvagni1,*, Federica Nardi1,*, Marco Maida1, Giulia Bernardini1, Silvia Vannuccini2, Felice Petraglia2, Annalisa Santucci1, Maurizio Orlandini1 1 Department of Biotechnology, Chemistry and Pharmacy, University of Siena, 2-53100 Siena, Italy 2 Department of Molecular and Developmental Medicine, Obstetrics and Gynecology, University of Siena, 53100 Siena, Italy *These authors contributed equally to this work Correspondence to: Maurizio Orlandini, e-mail: [email protected] Keywords: angiogenesis, signal transduction, C1qRp, Src, Cbl Received: June 29, 2015 Accepted: January 22, 2016 Published: February 02, 2016 ABSTRACT CD93 is a transmembrane glycoprotein predominantly expressed in endothelial cells. Although CD93 displays proangiogenic activity, its molecular function in angiogenesis still needs to be clarified. To get molecular insight into the biological role of CD93 in the endothelium, we performed proteomic analyses to examine changes in the protein profile of endothelial cells after CD93 silencing. Among differentially expressed proteins, we identified dystroglycan, a laminin-binding protein involved in angiogenesis, whose expression is increased in vascular endothelial cells within malignant tumors. Using immunofluorescence, FRET, and proximity ligation analyses, we observed a close interaction between CD93 and β-dystroglycan. Moreover, silencing experiments showed that CD93 and dystroglycan promoted endothelial cell migration and organization into capillary-like structures. CD93 proved to be phosphorylated on tyrosine 628 and 644 following cell adhesion on laminin through dystroglycan. This phosphorylation was shown to be necessary for a proper endothelial migratory phenotype. Moreover, we showed that during cell spreading phosphorylated CD93 recruited the signaling protein Cbl, which in turn was phosphorylated on tyrosine 774. -

Global H3k4me3 Genome Mapping Reveals Alterations of Innate Immunity Signaling and Overexpression of JMJD3 in Human Myelodysplastic Syndrome CD34 Þ Cells
Leukemia (2013) 27, 2177–2186 & 2013 Macmillan Publishers Limited All rights reserved 0887-6924/13 www.nature.com/leu ORIGINAL ARTICLE Global H3K4me3 genome mapping reveals alterations of innate immunity signaling and overexpression of JMJD3 in human myelodysplastic syndrome CD34 þ cells YWei1, R Chen2, S Dimicoli1, C Bueso-Ramos3, D Neuberg4, S Pierce1, H Wang2, H Yang1, Y Jia1, H Zheng1, Z Fang1, M Nguyen3, I Ganan-Gomez1,5, B Ebert6, R Levine7, H Kantarjian1 and G Garcia-Manero1 The molecular bases of myelodysplastic syndromes (MDS) are not fully understood. Trimethylated histone 3 lysine 4 (H3K4me3) is present in promoters of actively transcribed genes and has been shown to be involved in hematopoietic differentiation. We performed a genome-wide H3K4me3 CHIP-Seq (chromatin immunoprecipitation coupled with whole genome sequencing) analysis of primary MDS bone marrow (BM) CD34 þ cells. This resulted in the identification of 36 genes marked by distinct higher levels of promoter H3K4me3 in MDS. A majority of these genes are involved in nuclear factor (NF)-kB activation and innate immunity signaling. We then analyzed expression of histone demethylases and observed significant overexpression of the JmjC-domain histone demethylase JMJD3 (KDM6b) in MDS CD34 þ cells. Furthermore, we demonstrate that JMJD3 has a positive effect on transcription of multiple CHIP-Seq identified genes involved in NF-kB activation. Inhibition of JMJD3 using shRNA in primary BM MDS CD34 þ cells resulted in an increased number of erythroid colonies in samples isolated from patients with lower-risk MDS. Taken together, these data indicate the deregulation of H3K4me3 and associated abnormal activation of innate immunity signals have a role in the pathogenesis of MDS and that targeting these signals may have potential therapeutic value in MDS. -

Capacity of Human Dendritic Cells Uptake Receptor Expression And
The Novel Cyclophilin-Binding Drug Sanglifehrin A Specifically Affects Antigen Uptake Receptor Expression and Endocytic Capacity of Human Dendritic Cells This information is current as of September 25, 2021. Andrea M. Woltman, Nicole Schlagwein, Sandra W. van der Kooij and Cees van Kooten J Immunol 2004; 172:6482-6489; ; doi: 10.4049/jimmunol.172.10.6482 http://www.jimmunol.org/content/172/10/6482 Downloaded from References This article cites 44 articles, 20 of which you can access for free at: http://www.jimmunol.org/content/172/10/6482.full#ref-list-1 http://www.jimmunol.org/ Why The JI? Submit online. • Rapid Reviews! 30 days* from submission to initial decision • No Triage! Every submission reviewed by practicing scientists • Fast Publication! 4 weeks from acceptance to publication by guest on September 25, 2021 *average Subscription Information about subscribing to The Journal of Immunology is online at: http://jimmunol.org/subscription Permissions Submit copyright permission requests at: http://www.aai.org/About/Publications/JI/copyright.html Email Alerts Receive free email-alerts when new articles cite this article. Sign up at: http://jimmunol.org/alerts The Journal of Immunology is published twice each month by The American Association of Immunologists, Inc., 1451 Rockville Pike, Suite 650, Rockville, MD 20852 Copyright © 2004 by The American Association of Immunologists All rights reserved. Print ISSN: 0022-1767 Online ISSN: 1550-6606. The Journal of Immunology The Novel Cyclophilin-Binding Drug Sanglifehrin A Specifically Affects Antigen Uptake Receptor Expression and Endocytic Capacity of Human Dendritic Cells1 Andrea M. Woltman,2 Nicole Schlagwein, Sandra W. van der Kooij, and Cees van Kooten Sanglifehrin A (SFA) is a recently developed immunosuppressant that belongs to the family of immunophilin-binding ligands. -

S41467-020-18249-3.Pdf
ARTICLE https://doi.org/10.1038/s41467-020-18249-3 OPEN Pharmacologically reversible zonation-dependent endothelial cell transcriptomic changes with neurodegenerative disease associations in the aged brain Lei Zhao1,2,17, Zhongqi Li 1,2,17, Joaquim S. L. Vong2,3,17, Xinyi Chen1,2, Hei-Ming Lai1,2,4,5,6, Leo Y. C. Yan1,2, Junzhe Huang1,2, Samuel K. H. Sy1,2,7, Xiaoyu Tian 8, Yu Huang 8, Ho Yin Edwin Chan5,9, Hon-Cheong So6,8, ✉ ✉ Wai-Lung Ng 10, Yamei Tang11, Wei-Jye Lin12,13, Vincent C. T. Mok1,5,6,14,15 &HoKo 1,2,4,5,6,8,14,16 1234567890():,; The molecular signatures of cells in the brain have been revealed in unprecedented detail, yet the ageing-associated genome-wide expression changes that may contribute to neurovas- cular dysfunction in neurodegenerative diseases remain elusive. Here, we report zonation- dependent transcriptomic changes in aged mouse brain endothelial cells (ECs), which pro- minently implicate altered immune/cytokine signaling in ECs of all vascular segments, and functional changes impacting the blood–brain barrier (BBB) and glucose/energy metabolism especially in capillary ECs (capECs). An overrepresentation of Alzheimer disease (AD) GWAS genes is evident among the human orthologs of the differentially expressed genes of aged capECs, while comparative analysis revealed a subset of concordantly downregulated, functionally important genes in human AD brains. Treatment with exenatide, a glucagon-like peptide-1 receptor agonist, strongly reverses aged mouse brain EC transcriptomic changes and BBB leakage, with associated attenuation of microglial priming. We thus revealed tran- scriptomic alterations underlying brain EC ageing that are complex yet pharmacologically reversible. -

Wild-Type Bone Marrow Cells ) Mice with −/− in C1q-Deficient (C1qa
Reconstitution of the Complement Function in C1q-Deficient C1qa؊/؊) Mice with Wild-Type Bone Marrow Cells1) Franz Petry,2* Marina Botto,† Rafaela Holtappels,‡ Mark J. Walport,† and Michael Loos* Besides Ab-independent and Ab-dependent activation of the complement classical pathway in host defense, C1q plays a key role in the processing of immune complexes and in the clearance of apoptotic cells. In humans, C1q deficiency leads to systemic lupus erythematosus-like symptoms in over 90% of the cases, thus making this defect a strong disease susceptibility factor. Similarly, -C1q-deficient mice (C1qa؊/؊) develop systemic lupus erythematosus-like symptoms, such as autoantibodies and glomerulone phritis. We have previously provided evidence that C1q is produced by cells of the monocyte-macrophage lineage. In this study, .we have tested whether transplantation of bone marrow cells would be sufficient to reconstitute C1q levels in C1qa؊/؊ mice C1qa؊/؊ mice received a single graft of 107 bone marrow cells from wild-type (wt) donors after irradiation doses of 6, 7, 8, or 9 .Gy. Engraftment was monitored by a Y chromosome-specific PCR and a PCR that differentiated wt from C1qa؊/؊ genotype Serum levels of C1q Ag and C1 function increased rapidly in the recipient mice, and titers reached normal levels within 6 wk after bone marrow transplantation. In wt mice that received C1qa؊/؊ bone marrow, serum levels of C1q decreased constantly over time and became C1q deficient within 55 wk. These data clearly demonstrate that bone marrow-derived cells are the source of serum C1q and are competent to reconstitute normal C1q serum levels in C1q-deficient mice. -

By Map44 Pathway Activation in a Manner Inhibitable Pattern
Co-Complexes of MASP-1 and MASP-2 Associated with the Soluble Pattern-Recognition Molecules Drive Lectin Pathway Activation in a Manner Inhibitable This information is current as by MAp44 of September 28, 2021. Søren E. Degn, Lisbeth Jensen, Tomasz Olszowski, Jens C. Jensenius and Steffen Thiel J Immunol 2013; 191:1334-1345; Prepublished online 19 June 2013; Downloaded from doi: 10.4049/jimmunol.1300780 http://www.jimmunol.org/content/191/3/1334 http://www.jimmunol.org/ Supplementary http://www.jimmunol.org/content/suppl/2013/06/19/jimmunol.130078 Material 0.DC1 References This article cites 43 articles, 23 of which you can access for free at: http://www.jimmunol.org/content/191/3/1334.full#ref-list-1 Why The JI? Submit online. by guest on September 28, 2021 • Rapid Reviews! 30 days* from submission to initial decision • No Triage! Every submission reviewed by practicing scientists • Fast Publication! 4 weeks from acceptance to publication *average Subscription Information about subscribing to The Journal of Immunology is online at: http://jimmunol.org/subscription Permissions Submit copyright permission requests at: http://www.aai.org/About/Publications/JI/copyright.html Email Alerts Receive free email-alerts when new articles cite this article. Sign up at: http://jimmunol.org/alerts The Journal of Immunology is published twice each month by The American Association of Immunologists, Inc., 1451 Rockville Pike, Suite 650, Rockville, MD 20852 Copyright © 2013 by The American Association of Immunologists, Inc. All rights reserved. Print ISSN: 0022-1767 Online ISSN: 1550-6606. The Journal of Immunology Co-Complexes of MASP-1 and MASP-2 Associated with the Soluble Pattern-Recognition Molecules Drive Lectin Pathway Activation in a Manner Inhibitable by MAp44 Søren E. -

Adiponectin and Related C1q/TNF-Related Proteins Bind Selectively to Anionic Phospholipids and Sphingolipids
Adiponectin and related C1q/TNF-related proteins bind selectively to anionic phospholipids and sphingolipids Jessica J. Yea,b, Xin Bianc,d, Jaechul Lima,b, and Ruslan Medzhitova,b,1 aHHMI, Yale University, New Haven, CT 06520; bDepartment of Immunobiology, Yale University School of Medicine, New Haven, CT 06520; cDepartment of Cell Biology, Yale University School of Medicine, New Haven, CT 06520; and dDepartment of Neuroscience, Yale University School of Medicine, New Haven, CT 06520 Contributed by Ruslan Medzhitov, April 14, 2020 (sent for review December 20, 2019; reviewed by Ido Amit and G. William Wong) Adiponectin (Acrp30) is an adipokine associated with protection 5-mers of trimers, respectively referred to as low molecular weight from cardiovascular disease, insulin resistance, and inflammation. (LMW), medium molecular weight (MMW), and high molecular Although its effects are conventionally attributed to binding weight (HMW) complexes. Adiponectin can also be cleaved by Adipor1/2 and T-cadherin, its abundance in circulation, role in serum elastases and thrombin between the globular C1q-like head ceramide metabolism, and homology to C1q suggest an overlooked domain and the collagenous tail domain, forming globular adi- role as a lipid-binding protein, possibly generalizable to other C1q/ ponectin (gAd). While gAd appears to bind AdipoR1/2 and ac- TNF-related proteins (CTRPs) and C1q family members. To investi- tivate AMPK more strongly than full-length protein (19, 20), levels gate this, adiponectin, representative family members, and variants of HMW multimers are more strongly associated with insulin were expressed in Expi293 cells and tested for binding to lipids in sensitivity (21, 22), have a longer half-life in circulation (18), and liposomes using density centrifugation. -
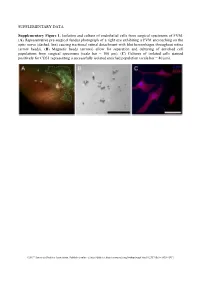
Supplementary Figures and Tables
SUPPLEMENTARY DATA Supplementary Figure 1. Isolation and culture of endothelial cells from surgical specimens of FVM. (A) Representative pre-surgical fundus photograph of a right eye exhibiting a FVM encroaching on the optic nerve (dashed line) causing tractional retinal detachment with blot hemorrhages throughout retina (arrow heads). (B) Magnetic beads (arrows) allow for separation and culturing of enriched cell populations from surgical specimens (scale bar = 100 μm). (C) Cultures of isolated cells stained positively for CD31 representing a successfully isolated enriched population (scale bar = 40 μm). ©2017 American Diabetes Association. Published online at http://diabetes.diabetesjournals.org/lookup/suppl/doi:10.2337/db16-1035/-/DC1 SUPPLEMENTARY DATA Supplementary Figure 2. Efficient siRNA knockdown of RUNX1 expression and function demonstrated by qRT-PCR, Western Blot, and scratch assay. (A) RUNX1 siRNA induced a 60% reduction of RUNX1 expression measured by qRT-PCR 48 hrs post-transfection whereas expression of RUNX2 and RUNX3, the two other mammalian RUNX orthologues, showed no significant changes, indicating specificity of our siRNA. Functional inhibition of Runx1 signaling was demonstrated by a 330% increase in insulin-like growth factor binding protein-3 (IGFBP3) RNA expression level, a known target of RUNX1 inhibition. Western blot demonstrated similar reduction in protein levels. (B) siRNA- 2’s effect on RUNX1 was validated by qRT-PCR and western blot, demonstrating a similar reduction in both RNA and protein. Scratch assay demonstrates functional inhibition of RUNX1 by siRNA-2. ns: not significant, * p < 0.05, *** p < 0.001 ©2017 American Diabetes Association. Published online at http://diabetes.diabetesjournals.org/lookup/suppl/doi:10.2337/db16-1035/-/DC1 SUPPLEMENTARY DATA Supplementary Table 1. -

Differential and Altered Spatial Distribution of Complement Expression in Age-Related Macular Degeneration
Physiology and Pharmacology Differential and Altered Spatial Distribution of Complement Expression in Age-Related Macular Degeneration John T. Demirs, Junzheng Yang, Maura A. Crowley, Michael Twarog, Omar Delgado, Yubin Qiu, Stephen Poor, Dennis S. Rice, Thaddeus P. Dryja,* Karen Anderson,** and Sha-Mei Liao Department of Ophthalmology, Novartis Institutes for Biomedical Research, Cambridge, Massachusetts, United States Correspondence: Sha-Mei Liao, 22 PURPOSE. Dysregulation of the alternative complement pathway is a major pathogenic Windsor Street, Cambridge, MA mechanism in age-related macular degeneration. We investigated whether locally synthe- 02139, USA; sized complement components contribute to AMD by profiling complement expression [email protected]. in postmortem eyes with and without AMD. Current affiliation: *Cogan Eye METHODS. AMD severity grade 1 to 4 was determined by analysis of postmortem acquired Pathology Laboratory, Massachusetts fundus images and hematoxylin and eosin stained histological sections. TaqMan (donor Eye and Ear, Boston, Massachusetts, eyes n = 39) and RNAscope/in situ hybridization (n = 10) were performed to detect United States. = ** Biogen, Cambridge, complement mRNA. Meso scale discovery assay and Western blot (n 31) were used to Massachusetts, United States. measure complement protein levels. Received: September 2, 2020 RESULTS. The levels of complement mRNA and protein expression were approximately Accepted: May 19, 2021 15- to 100-fold (P < 0.0001–0.001) higher in macular retinal pigment epithelium Published: June 23, 2021 (RPE)/choroid tissue than in neural retina, regardless of AMD grade status. Complement Citation: Demirs JT, Yang J, Crowley mRNA and protein levels were modestly elevated in vitreous and the macular neural MA, et al. -

C1q Binding to Surface-Bound Igg Is Stabilized by C1r2s2 Proteases
bioRxiv preprint doi: https://doi.org/10.1101/2021.02.08.430229; this version posted February 10, 2021. The copyright holder for this preprint (which was not certified by peer review) is the author/funder. All rights reserved. No reuse allowed without permission. C1q binding to surface-bound IgG is stabilized by C1r2s2 proteases Seline A. Zwarthoff1, Kevin Widmer2, Annemarie Kuipers1, Jürgen Strasser3, Maartje Ruyken1, Piet C. Aerts1, Carla J.C. de Haas1, Deniz Ugurlar4, Gestur Vidarsson5, Jos A. G. Van Strijp1, Piet Gros4, Paul W.H.I. Parren6,7, Kok P.M. van Kessel1, Johannes Preiner3, Frank J. Beurskens8, Janine Schuurman8, Daniel Ricklin2, Suzan H.M. Rooijakkers1 1Medical Microbiology, University Medical Center Utrecht, Utrecht University, Utrecht, The Netherlands; 2Pharmaceutical Sciences, University of Basel, Basel, Switzerland; 3University of Applied Sciences Upper Austria, 4020 Linz, Austria; 4Crystal and Structural Chemistry, Utrecht University, Utrecht, The Netherlands; 5Experimental Immunohematology, Sanquin Research, Amsterdam, The Netherlands 6Immunohematology and Blood Transfusion, Leiden University Medical Center, Leiden, The Netherlands. 7Lava Therapeutics, Utrecht, The Netherlands 8Genmab, Utrecht, The Netherlands; Running title: C1r2s2 enhance stability of C1q-IgG bioRxiv preprint doi: https://doi.org/10.1101/2021.02.08.430229; this version posted February 10, 2021. The copyright holder for this preprint (which was not certified by peer review) is the author/funder. All rights reserved. No reuse allowed without permission. Abstract Complement is an important effector mechanism for antibody-mediated clearance of infections and tumor cells. Upon binding to target cells, the antibody's constant (Fc) domain recruits complement component C1 to initiate a proteolytic cascade that generates lytic pores and stimulates phagocytosis.