Bit-Coded Regular Expression Parsing
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Use Perl Regular Expressions in SAS® Shuguang Zhang, WRDS, Philadelphia, PA
NESUG 2007 Programming Beyond the Basics Use Perl Regular Expressions in SAS® Shuguang Zhang, WRDS, Philadelphia, PA ABSTRACT Regular Expression (Regexp) enhance search and replace operations on text. In SAS®, the INDEX, SCAN and SUBSTR functions along with concatenation (||) can be used for simple search and replace operations on static text. These functions lack flexibility and make searching dynamic text difficult, and involve more function calls. Regexp combines most, if not all, of these steps into one expression. This makes code less error prone, easier to maintain, clearer, and can improve performance. This paper will discuss three ways to use Perl Regular Expression in SAS: 1. Use SAS PRX functions; 2. Use Perl Regular Expression with filename statement through a PIPE such as ‘Filename fileref PIPE 'Perl programm'; 3. Use an X command such as ‘X Perl_program’; Three typical uses of regular expressions will also be discussed and example(s) will be presented for each: 1. Test for a pattern of characters within a string; 2. Replace text; 3. Extract a substring. INTRODUCTION Perl is short for “Practical Extraction and Report Language". Larry Wall Created Perl in mid-1980s when he was trying to produce some reports from a Usenet-Nes-like hierarchy of files. Perl tries to fill the gap between low-level programming and high-level programming and it is easy, nearly unlimited, and fast. A regular expression, often called a pattern in Perl, is a template that either matches or does not match a given string. That is, there are an infinite number of possible text strings. -

Lecture 18: Theory of Computation Regular Expressions and Dfas
Introduction to Theoretical CS Lecture 18: Theory of Computation Two fundamental questions. ! What can a computer do? ! What can a computer do with limited resources? General approach. Pentium IV running Linux kernel 2.4.22 ! Don't talk about specific machines or problems. ! Consider minimal abstract machines. ! Consider general classes of problems. COS126: General Computer Science • http://www.cs.Princeton.EDU/~cos126 2 Why Learn Theory In theory . Regular Expressions and DFAs ! Deeper understanding of what is a computer and computing. ! Foundation of all modern computers. ! Pure science. ! Philosophical implications. a* | (a*ba*ba*ba*)* In practice . ! Web search: theory of pattern matching. ! Sequential circuits: theory of finite state automata. a a a ! Compilers: theory of context free grammars. b b ! Cryptography: theory of computational complexity. 0 1 2 ! Data compression: theory of information. b "In theory there is no difference between theory and practice. In practice there is." -Yogi Berra 3 4 Pattern Matching Applications Regular Expressions: Basic Operations Test if a string matches some pattern. Regular expression. Notation to specify a set of strings. ! Process natural language. ! Scan for virus signatures. ! Search for information using Google. Operation Regular Expression Yes No ! Access information in digital libraries. ! Retrieve information from Lexis/Nexis. Concatenation aabaab aabaab every other string ! Search-and-replace in a word processors. cumulus succubus Wildcard .u.u.u. ! Filter text (spam, NetNanny, Carnivore, malware). jugulum tumultuous ! Validate data-entry fields (dates, email, URL, credit card). aa Union aa | baab baab every other string ! Search for markers in human genome using PROSITE patterns. aa ab Closure ab*a abbba ababa Parse text files. -

Midterm Study Sheet for CS3719 Regular Languages and Finite
Midterm study sheet for CS3719 Regular languages and finite automata: • An alphabet is a finite set of symbols. Set of all finite strings over an alphabet Σ is denoted Σ∗.A language is a subset of Σ∗. Empty string is called (epsilon). • Regular expressions are built recursively starting from ∅, and symbols from Σ and closing under ∗ Union (R1 ∪ R2), Concatenation (R1 ◦ R2) and Kleene Star (R denoting 0 or more repetitions of R) operations. These three operations are called regular operations. • A Deterministic Finite Automaton (DFA) D is a 5-tuple (Q, Σ, δ, q0,F ), where Q is a finite set of states, Σ is the alphabet, δ : Q × Σ → Q is the transition function, q0 is the start state, and F is the set of accept states. A DFA accepts a string if there exists a sequence of states starting with r0 = q0 and ending with rn ∈ F such that ∀i, 0 ≤ i < n, δ(ri, wi) = ri+1. The language of a DFA, denoted L(D) is the set of all and only strings that D accepts. • Deterministic finite automata are used in string matching algorithms such as Knuth-Morris-Pratt algorithm. • A language is called regular if it is recognized by some DFA. • ‘Theorem: The class of regular languages is closed under union, concatenation and Kleene star operations. • A non-deterministic finite automaton (NFA) is a 5-tuple (Q, Σ, δ, q0,F ), where Q, Σ, q0 and F are as in the case of DFA, but the transition function δ is δ : Q × (Σ ∪ {}) → P(Q). -

Backtrack Parsing Context-Free Grammar Context-Free Grammar
Context-free Grammar Problems with Regular Context-free Grammar Language and Is English a regular language? Bad question! We do not even know what English is! Two eggs and bacon make(s) a big breakfast Backtrack Parsing Can you slide me the salt? He didn't ought to do that But—No! Martin Kay I put the wine you brought in the fridge I put the wine you brought for Sandy in the fridge Should we bring the wine you put in the fridge out Stanford University now? and University of the Saarland You said you thought nobody had the right to claim that they were above the law Martin Kay Context-free Grammar 1 Martin Kay Context-free Grammar 2 Problems with Regular Problems with Regular Language Language You said you thought nobody had the right to claim [You said you thought [nobody had the right [to claim that they were above the law that [they were above the law]]]] Martin Kay Context-free Grammar 3 Martin Kay Context-free Grammar 4 Problems with Regular Context-free Grammar Language Nonterminal symbols ~ grammatical categories Is English mophology a regular language? Bad question! We do not even know what English Terminal Symbols ~ words morphology is! They sell collectables of all sorts Productions ~ (unordered) (rewriting) rules This concerns unredecontaminatability Distinguished Symbol This really is an untiable knot. But—Probably! (Not sure about Swahili, though) Not all that important • Terminals and nonterminals are disjoint • Distinguished symbol Martin Kay Context-free Grammar 5 Martin Kay Context-free Grammar 6 Context-free Grammar Context-free -

Chapter 6 Formal Language Theory
Chapter 6 Formal Language Theory In this chapter, we introduce formal language theory, the computational theories of languages and grammars. The models are actually inspired by formal logic, enriched with insights from the theory of computation. We begin with the definition of a language and then proceed to a rough characterization of the basic Chomsky hierarchy. We then turn to a more de- tailed consideration of the types of languages in the hierarchy and automata theory. 6.1 Languages What is a language? Formally, a language L is defined as as set (possibly infinite) of strings over some finite alphabet. Definition 7 (Language) A language L is a possibly infinite set of strings over a finite alphabet Σ. We define Σ∗ as the set of all possible strings over some alphabet Σ. Thus L ⊆ Σ∗. The set of all possible languages over some alphabet Σ is the set of ∗ all possible subsets of Σ∗, i.e. 2Σ or ℘(Σ∗). This may seem rather simple, but is actually perfectly adequate for our purposes. 6.2 Grammars A grammar is a way to characterize a language L, a way to list out which strings of Σ∗ are in L and which are not. If L is finite, we could simply list 94 CHAPTER 6. FORMAL LANGUAGE THEORY 95 the strings, but languages by definition need not be finite. In fact, all of the languages we are interested in are infinite. This is, as we showed in chapter 2, also true of human language. Relating the material of this chapter to that of the preceding two, we can view a grammar as a logical system by which we can prove things. -

Adaptive LL(*) Parsing: the Power of Dynamic Analysis
Adaptive LL(*) Parsing: The Power of Dynamic Analysis Terence Parr Sam Harwell Kathleen Fisher University of San Francisco University of Texas at Austin Tufts University [email protected] [email protected] kfi[email protected] Abstract PEGs are unambiguous by definition but have a quirk where Despite the advances made by modern parsing strategies such rule A ! a j ab (meaning “A matches either a or ab”) can never as PEG, LL(*), GLR, and GLL, parsing is not a solved prob- match ab since PEGs choose the first alternative that matches lem. Existing approaches suffer from a number of weaknesses, a prefix of the remaining input. Nested backtracking makes de- including difficulties supporting side-effecting embedded ac- bugging PEGs difficult. tions, slow and/or unpredictable performance, and counter- Second, side-effecting programmer-supplied actions (muta- intuitive matching strategies. This paper introduces the ALL(*) tors) like print statements should be avoided in any strategy that parsing strategy that combines the simplicity, efficiency, and continuously speculates (PEG) or supports multiple interpreta- predictability of conventional top-down LL(k) parsers with the tions of the input (GLL and GLR) because such actions may power of a GLR-like mechanism to make parsing decisions. never really take place [17]. (Though DParser [24] supports The critical innovation is to move grammar analysis to parse- “final” actions when the programmer is certain a reduction is time, which lets ALL(*) handle any non-left-recursive context- part of an unambiguous final parse.) Without side effects, ac- free grammar. ALL(*) is O(n4) in theory but consistently per- tions must buffer data for all interpretations in immutable data forms linearly on grammars used in practice, outperforming structures or provide undo actions. -
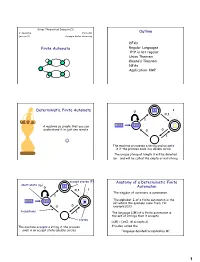
Deterministic Finite Automata 0 0,1 1
Great Theoretical Ideas in CS V. Adamchik CS 15-251 Outline Lecture 21 Carnegie Mellon University DFAs Finite Automata Regular Languages 0n1n is not regular Union Theorem Kleene’s Theorem NFAs Application: KMP 11 1 Deterministic Finite Automata 0 0,1 1 A machine so simple that you can 0111 111 1 ϵ understand it in just one minute 0 0 1 The machine processes a string and accepts it if the process ends in a double circle The unique string of length 0 will be denoted by ε and will be called the empty or null string accept states (F) Anatomy of a Deterministic Finite start state (q0) 11 0 Automaton 0,1 1 The singular of automata is automaton. 1 The alphabet Σ of a finite automaton is the 0111 111 1 ϵ set where the symbols come from, for 0 0 example {0,1} transitions 1 The language L(M) of a finite automaton is the set of strings that it accepts states L(M) = {x∈Σ: M accepts x} The machine accepts a string if the process It’s also called the ends in an accept state (double circle) “language decided/accepted by M”. 1 The Language L(M) of Machine M The Language L(M) of Machine M 0 0 0 0,1 1 q 0 q1 q0 1 1 What language does this DFA decide/accept? L(M) = All strings of 0s and 1s The language of a finite automaton is the set of strings that it accepts L(M) = { w | w has an even number of 1s} M = (Q, Σ, , q0, F) Q = {q0, q1, q2, q3} Formal definition of DFAs where Σ = {0,1} A finite automaton is a 5-tuple M = (Q, Σ, , q0, F) q0 Q is start state Q is the finite set of states F = {q1, q2} Q accept states : Q Σ → Q transition function Σ is the alphabet : Q Σ → Q is the transition function q 1 0 1 0 1 0,1 q0 Q is the start state q0 q0 q1 1 q q1 q2 q2 F Q is the set of accept states 0 M q2 0 0 q2 q3 q2 q q q 1 3 0 2 L(M) = the language of machine M q3 = set of all strings machine M accepts EXAMPLE Determine the language An automaton that accepts all recognized by and only those strings that contain 001 1 0,1 0,1 0 1 0 0 0 1 {0} {00} {001} 1 L(M)={1,11,111, …} 2 Membership problem Determine the language decided by Determine whether some word belongs to the language. -

Perl Regular Expressions Tip Sheet Functions and Call Routines
– Perl Regular Expressions Tip Sheet Functions and Call Routines Basic Syntax Advanced Syntax regex-id = prxparse(perl-regex) Character Behavior Character Behavior Compile Perl regular expression perl-regex and /…/ Starting and ending regex delimiters non-meta Match character return regex-id to be used by other PRX functions. | Alternation character () Grouping {}[]()^ Metacharacters, to match these pos = prxmatch(regex-id | perl-regex, source) $.|*+?\ characters, override (escape) with \ Search in source and return position of match or zero Wildcards/Character Class Shorthands \ Override (escape) next metacharacter if no match is found. Character Behavior \n Match capture buffer n Match any one character . (?:…) Non-capturing group new-string = prxchange(regex-id | perl-regex, times, \w Match a word character (alphanumeric old-string) plus "_") Lazy Repetition Factors Search and replace times number of times in old- \W Match a non-word character (match minimum number of times possible) string and return modified string in new-string. \s Match a whitespace character Character Behavior \S Match a non-whitespace character *? Match 0 or more times call prxchange(regex-id, times, old-string, new- \d Match a digit character +? Match 1 or more times string, res-length, trunc-value, num-of-changes) Match a non-digit character ?? Match 0 or 1 time Same as prior example and place length of result in \D {n}? Match exactly n times res-length, if result is too long to fit into new-string, Character Classes Match at least n times trunc-value is set to 1, and the number of changes is {n,}? Character Behavior Match at least n but not more than m placed in num-of-changes. -
6.045 Final Exam Name
6.045J/18.400J: Automata, Computability and Complexity Prof. Nancy Lynch 6.045 Final Exam May 20, 2005 Name: • Please write your name on each page. • This exam is open book, open notes. • There are two sheets of scratch paper at the end of this exam. • Questions vary substantially in difficulty. Use your time accordingly. • If you cannot produce a full proof, clearly state partial results for partial credit. • Good luck! Part Problem Points Grade Part I 1–10 50 1 20 2 15 3 25 Part II 4 15 5 15 6 10 Total 150 final-1 Name: Part I Multiple Choice Questions. (50 points, 5 points for each question) For each question, any number of the listed answersClearly may place be correct. an “X” in the box next to each of the answers that you are selecting. Problem 1: Which of the following are true statements about regular and nonregular languages? (All lan guages are over the alphabet{0, 1}) IfL1 ⊆ L2 andL2 is regular, thenL1 must be regular. IfL1 andL2 are nonregular, thenL1 ∪ L2 must be nonregular. IfL1 is nonregular, then the complementL 1 must of also be nonregular. IfL1 is regular,L2 is nonregular, andL1 ∩ L2 is nonregular, thenL1 ∪ L2 must be nonregular. IfL1 is regular,L2 is nonregular, andL1 ∩ L2 is regular, thenL1 ∪ L2 must be nonregular. Problem 2: Which of the following are guaranteed to be regular languages ? ∗ L2 = {ww : w ∈{0, 1}}. L2 = {ww : w ∈ L1}, whereL1 is a regular language. L2 = {w : ww ∈ L1}, whereL1 is a regular language. L2 = {w : for somex,| w| = |x| andwx ∈ L1}, whereL1 is a regular language. -

Sequence Alignment/Map Format Specification
Sequence Alignment/Map Format Specification The SAM/BAM Format Specification Working Group 3 Jun 2021 The master version of this document can be found at https://github.com/samtools/hts-specs. This printing is version 53752fa from that repository, last modified on the date shown above. 1 The SAM Format Specification SAM stands for Sequence Alignment/Map format. It is a TAB-delimited text format consisting of a header section, which is optional, and an alignment section. If present, the header must be prior to the alignments. Header lines start with `@', while alignment lines do not. Each alignment line has 11 mandatory fields for essential alignment information such as mapping position, and variable number of optional fields for flexible or aligner specific information. This specification is for version 1.6 of the SAM and BAM formats. Each SAM and BAMfilemay optionally specify the version being used via the @HD VN tag. For full version history see Appendix B. Unless explicitly specified elsewhere, all fields are encoded using 7-bit US-ASCII 1 in using the POSIX / C locale. Regular expressions listed use the POSIX / IEEE Std 1003.1 extended syntax. 1.1 An example Suppose we have the following alignment with bases in lowercase clipped from the alignment. Read r001/1 and r001/2 constitute a read pair; r003 is a chimeric read; r004 represents a split alignment. Coor 12345678901234 5678901234567890123456789012345 ref AGCATGTTAGATAA**GATAGCTGTGCTAGTAGGCAGTCAGCGCCAT +r001/1 TTAGATAAAGGATA*CTG +r002 aaaAGATAA*GGATA +r003 gcctaAGCTAA +r004 ATAGCT..............TCAGC -r003 ttagctTAGGC -r001/2 CAGCGGCAT The corresponding SAM format is:2 1Charset ANSI X3.4-1968 as defined in RFC1345. -

Lexing and Parsing with ANTLR4
Lab 2 Lexing and Parsing with ANTLR4 Objective • Understand the software architecture of ANTLR4. • Be able to write simple grammars and correct grammar issues in ANTLR4. EXERCISE #1 Lab preparation Ï In the cap-labs directory: git pull will provide you all the necessary files for this lab in TP02. You also have to install ANTLR4. 2.1 User install for ANTLR4 and ANTLR4 Python runtime User installation steps: mkdir ~/lib cd ~/lib wget http://www.antlr.org/download/antlr-4.7-complete.jar pip3 install antlr4-python3-runtime --user Then in your .bashrc: export CLASSPATH=".:$HOME/lib/antlr-4.7-complete.jar:$CLASSPATH" export ANTLR4="java -jar $HOME/lib/antlr-4.7-complete.jar" alias antlr4="java -jar $HOME/lib/antlr-4.7-complete.jar" alias grun='java org.antlr.v4.gui.TestRig' Then source your .bashrc: source ~/.bashrc 2.2 Structure of a .g4 file and compilation Links to a bit of ANTLR4 syntax : • Lexical rules (extended regular expressions): https://github.com/antlr/antlr4/blob/4.7/doc/ lexer-rules.md • Parser rules (grammars) https://github.com/antlr/antlr4/blob/4.7/doc/parser-rules.md The compilation of a given .g4 (for the PYTHON back-end) is done by the following command line: java -jar ~/lib/antlr-4.7-complete.jar -Dlanguage=Python3 filename.g4 or if you modified your .bashrc properly: antlr4 -Dlanguage=Python3 filename.g4 2.3 Simple examples with ANTLR4 EXERCISE #2 Demo files Ï Work your way through the five examples in the directory demo_files: Aurore Alcolei, Laure Gonnord, Valentin Lorentz. 1/4 ENS de Lyon, Département Informatique, M1 CAP Lab #2 – Automne 2017 ex1 with ANTLR4 + Java : A very simple lexical analysis1 for simple arithmetic expressions of the form x+3. -

Unicode Regular Expressions Technical Reports
7/1/2019 UTS #18: Unicode Regular Expressions Technical Reports Working Draft for Proposed Update Unicode® Technical Standard #18 UNICODE REGULAR EXPRESSIONS Version 20 Editors Mark Davis, Andy Heninger Date 2019-07-01 This Version http://www.unicode.org/reports/tr18/tr18-20.html Previous Version http://www.unicode.org/reports/tr18/tr18-19.html Latest Version http://www.unicode.org/reports/tr18/ Latest Proposed http://www.unicode.org/reports/tr18/proposed.html Update Revision 20 Summary This document describes guidelines for how to adapt regular expression engines to use Unicode. Status This is a draft document which may be updated, replaced, or superseded by other documents at any time. Publication does not imply endorsement by the Unicode Consortium. This is not a stable document; it is inappropriate to cite this document as other than a work in progress. A Unicode Technical Standard (UTS) is an independent specification. Conformance to the Unicode Standard does not imply conformance to any UTS. Please submit corrigenda and other comments with the online reporting form [Feedback]. Related information that is useful in understanding this document is found in the References. For the latest version of the Unicode Standard, see [Unicode]. For a list of current Unicode Technical Reports, see [Reports]. For more information about versions of the Unicode Standard, see [Versions]. Contents 0 Introduction 0.1 Notation 0.2 Conformance 1 Basic Unicode Support: Level 1 1.1 Hex Notation 1.1.1 Hex Notation and Normalization 1.2 Properties 1.2.1 General