Efficient Machine Learning for Attack Detection
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Security Now! #664 - 05-22-18 Spectreng Revealed
Security Now! #664 - 05-22-18 SpectreNG Revealed This week on Security Now! This week we examine the recent flaws discovered in the secure Signal messaging app for desktops, the rise in DNS router hijacking, another seriously flawed consumer router family, Microsoft Spectre patches for Win10's April 2018 feature update, the threat of voice assistant spoofing attacks, the evolving security of HTTP, still more new trouble with GPON routers, Facebook's Android app mistake, BMW's 14 security flaws and some fun miscellany. Then we examine the news of the next-generation of Spectre processor speculation flaws and what they mean for us. Our Picture of the Week Security News Update your Signal Desktop Apps for Windows & Linux A few weeks ago, Argentinian security researchers discovered a severe vulnerability in the Signal messaging app for Windows and Linux desktops that allows remote attackers to execute malicious code on recipient systems simply by sending a message—without requiring any user interaction. The vulnerability was accidentally discovered while researchers–amond them Juliano Rizzo–were chatting on Signal messenger and one of them shared a link of a vulnerable site with an XSS payload in its URL. However, the XSS payload unexpectedly got executed on the Signal desktop app!! (Juliano Rizzo was on the beach when the BEAST and CRIME attacks occurred to him.) After analyzing the scope of this issue by testing multiple XSS payloads, they found that the vulnerability resides in the function responsible for handling shared links, allowing attackers to inject user-defined HTML/JavaScript code via iFrame, image, video and audio tags. -

Internet of Things Botnet Detection Approaches: Analysis and Recommendations for Future Research
applied sciences Systematic Review Internet of Things Botnet Detection Approaches: Analysis and Recommendations for Future Research Majda Wazzan 1,*, Daniyal Algazzawi 2 , Omaima Bamasaq 1, Aiiad Albeshri 1 and Li Cheng 3 1 Computer Science Department, Faculty of Computing and Information Technology, King Abdulaziz University, Jeddah 21589, Saudi Arabia; [email protected] (O.B.); [email protected] (A.A.) 2 Information Systems Department, Faculty of Computing and Information Technology, King Abdulaziz University, Jeddah 21589, Saudi Arabia; [email protected] 3 Xinjiang Technical Institute of Physics & Chemistry Chinese Academy of Sciences, Urumqi 830011, China; [email protected] * Correspondence: [email protected] Abstract: Internet of Things (IoT) is promising technology that brings tremendous benefits if used optimally. At the same time, it has resulted in an increase in cybersecurity risks due to the lack of security for IoT devices. IoT botnets, for instance, have become a critical threat; however, systematic and comprehensive studies analyzing the importance of botnet detection methods are limited in the IoT environment. Thus, this study aimed to identify, assess and provide a thoroughly review of experimental works on the research relevant to the detection of IoT botnets. To accomplish this goal, a systematic literature review (SLR), an effective method, was applied for gathering and critically reviewing research papers. This work employed three research questions on the detection methods used to detect IoT botnets, the botnet phases and the different malicious activity scenarios. The authors analyzed the nominated research and the key methods related to them. The detection Citation: Wazzan, M.; Algazzawi, D.; methods have been classified based on the techniques used, and the authors investigated the botnet Bamasaq, O.; Albeshri, A.; Cheng, L. -

Technical Brief P2P Iot Botnets Clean AC Font
Uncleanable and Unkillable: The Evolution of IoT Botnets Through P2P Networking Technical Brief By Stephen Hilt, Robert McArdle, Fernando Merces, Mayra Rosario, and David Sancho Introduction Peer-to-peer (P2P) networking is a way for computers to connect to one another without the need for a central server. It was originally invented for file sharing, with BitTorrent being the most famous P2P implementation. Decentralized file-sharing systems built on P2P networking have stood the test of time. Even though they have been used to share illegal pirated content for over 20 years, authorities have not been able to put a stop to these systems. Of course, malicious actors have used it for malware for quite a long time as well. Being able to create and manage botnets without the need for a central server is a powerful capability, mostly because law enforcement and security companies typically take down criminal servers. And since a P2P botnet does not need a central command-and-control (C&C) server, it is much more difficult to take down. From the point of view of defenders, this is the scariest problem presented by P2P botnets: If they cannot be taken down centrally, the only option available would be to disinfect each of the bot clients separately. Since computers communicate only with their own peers, the good guys would need to clean all the members one by one for a botnet to disappear. Originally, P2P botnets were implemented in Windows, but developers of internet-of-things (IoT) botnets do have a tendency to start incorporating this feature into their creations. -

Scholarly Program Notes for the Graduate Voice Recital of Laura Neal Laura Neal [email protected]
Southern Illinois University Carbondale OpenSIUC Research Papers Graduate School 2012 Scholarly Program Notes for the Graduate Voice Recital of Laura Neal Laura Neal [email protected] Follow this and additional works at: http://opensiuc.lib.siu.edu/gs_rp I am not submitting this version as a PDF. Please let me know if there are any problems in the automatic conversion. Thank you! Recommended Citation Neal, Laura, "Scholarly Program Notes for the Graduate Voice Recital of Laura Neal" (2012). Research Papers. Paper 280. http://opensiuc.lib.siu.edu/gs_rp/280 This Article is brought to you for free and open access by the Graduate School at OpenSIUC. It has been accepted for inclusion in Research Papers by an authorized administrator of OpenSIUC. For more information, please contact [email protected]. SCHOLARLY PROGRAM NOTES FOR MY GRADUATE VOCAL RECITAL by Laura S. Neal B.S., Murray State University, 2010 B.A., Murray State University, 2010 A Research Paper Submitted in Partial Fulfillment of the Requirements for the Masters in Music Department of Music in the Graduate School Southern Illinois University Carbondale May 2012 RESEARCH PAPER APPROVAL SCHOLARLY PROGRAM NOTES ON MY GRADUATE VOCAL RECITAL By Laura Stone Neal A Research Paper Submitted in Partial Fulfillment of the Requirements for the Degree of Masters in the field of Music Approved by: Dr. Jeanine Wagner, Chair Dr. Diane Coloton Dr. Paul Transue Graduate School Southern Illinois University Carbondale May 4, 2012 ACKNOWLEDGMENTS I wish to thank first and foremost my voice teacher and mentor, Dr. Jeanine Wagner for her constant support during my academic studies at Southern Illinois University Carbondale. -
LRVNA Hospice Board of Directors' Adopted Resolutions, December 9, 2020 APPENDIX U Statements of Support from Community Members Appendix A
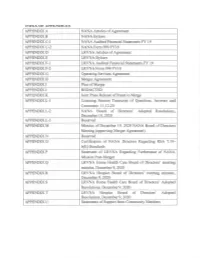
INDEX OF APPENDICES APPENDIX A NANA Articles of Agreement APPENDIX B NANA Bylaws APPENDIX C.l NANA Audited Financial Statements FY 19 APPENDIX C-2 NANA Form 990 FY18 APPENDIX D LRVNA Articles of Agreement APPENDIX E LRVNA Bylaws APPENDIX F-l LRVNA Audited Financial Statements FY 19 APPENDIXF-2 LR\rNA Form 990 FY18 APPENDIX G Operating Services Agreement APPENDIX H Merger Agreement APPENDIX I Plan of Merger APPENDIX J REDACTED APPENDIX K Joint Press Release of Intent to Merge APPENDIX L-l Listening Session Transcript of Questions, Answers and Comments 11.12.20 APPENDIXL-2 NANA Board of Directors' Adopted Resolutions, December I0,2020 APPENDIX L-3 Reserved APPENDIX M Minutes of December 10. 2020 NANA Board of Directors Meeting (approving Merger Agreement) APPENDIX N Reserved APPENDIX O Certification of NANA Directors Regarding RSA 7:19- b(II) Standards APPENDIX P Statement of LRVNA Regarding Furtherance of NANA Mission Post-Merger APPENDIX Q LR'\/NA Home Health Care Board of Directors' meeting minutes, December 9, 2020 APPENDIX R LRVNA Hospice Board of Directors' meeting minutes, December 9,2020 APPENDIX S LRVNA Home Health Care Board of Directors' Adopted Resolutions, December 9, 2020 APPENDIX T LRVNA Hospice Board of Directors' Adopted Resolutions, December 9, 2020 APPENDIX U Statements of Support from Community Members Appendix A Newfound Area Nursing Association Articles of Agreement Stutr uf $(rur ffiurnpxgiru OFtrICE OF SECRETARY OF STATE .l. R{}IiIll'f y. .J,iJ/Jl?{")S/:, Dt'l;tti^rt .i{:,(.}(.,//zi i] t.l: .\!utt' c1i ,llri" ilrrlr:' r.,.f .\i1";1, lltt:t:S:.tit!rt', it.t ltr:t'r'it,t t'trli!t' llirLt t tr: ft,ill,r'1r,f- . -

Three Plead Guilty in US to Developing Mirai Botnet
Source: https://internetofbusiness.com/three-plead-guilty-developing-mirai-botnet/ Three plead guilty in US to developing Mirai botnet By Rene Millman - December 18, 2017 Hackers go up before US federal court charged with creating Mirai botnet used in massive DDoS attacks. Three men have pleaded guilty to creating the Mirai IoT botnet, used in distributed denial of service (DDoS) attacks since 2016. A statement released last week by the US Department of Justice, it outlines plea deals and details of the three defendants: Paras Jha, 21, of Fanwood, New Jersey; Josiah White, 20, of Washington, Pennsylvania; and Dalton Norman, 21, of Metairie, Louisiana. The three admitted conspiracy to violate the Computer Fraud & Abuse Act. Jha and Norman also pleaded guilty to building an IoT botnet of 100,000 devices to carry out ‘clickfraud’, an Internet-based scheme that makes it appear that a real user has clicked’ on an advertisement for the purpose of articially generating revenue. In addition, Jha pleaded guilty to a third charge, related to a series of DDoS attacks on the networks of Rutgers University in New Jersey. Read more: Malwar! Hajime IoT botnet ghts back against Mirai Adopted by others The DoJ said the Mirai botnet was created during the summer and autumn of 2016, and went on to compromise 300,000 IoT devices, such as wireless cameras, routers, and digital video recorders. It added that the defendants’ involvement with the original Mirai variant ended in the fall of 2016, when Jha posted its source code on a criminal forum. Since then, other criminal actors have adopted Mirai and used variants in other attacks. -

Visualization of Prague Castle
Master’s Thesis Czech Technical University in Prague Faculty of Electrical Engineering F3 Department of Computer Graphics and Interaction Visualization of Prague Castle Bc. Antonín Smrček Study Programme: Open Informatics Field of Study: Computer Graphics and Interaction January 2016 Supervisor: prof. Ing. Jiří Žára, CSc. Acknowledgement / Declaration I would like to thank prof. Ing. Jiří I hereby declare that I have completed Žára, CSc., for supervision of my the- this thesis independently and that I have sis. He provided me with invaluable in- listed all the literature and publications sights, feedback on work in progress and used. his guidance was especially important I have no objection to usage of this in finishing stages of the project. My work in compliance with the act §60 thanks are also due to all friends who Zákon č. 121/2000Sb. (copyright law), helped me with the user testing. Finally, and with the rights connected with the I want to particularly thank my mother copyright act including the changes in for her support throughout my studies. the act. In Prague on January 11, 2016 ........................................ v Abstrakt / Abstract Tato diplomová práce se zabývá vý- This thesis describes a development vojem webové aplikace která vizualizuje of the web-based 3D virtual walk ap- prostředí Pražského hradu a umožňuje plication which visualizes the Prague 3D virtuální procházku v rámci jeho Castle and provides the users with an prostor. Důraz je kladen na grafic- information about interesting objects kou kvalitu a výkon aplikace. Obdobné in the area, with focus on graphical systémy pro vizualizaci měst jsou podro- quality and performance of the ap- beny analýze a jsou diskutovány možné plication. -

Tessj R Ii 3 Tr
DM ht Tfct Evening World DaMy M t fill n c , TP r tft y , jTuy , ffrrB MMfM U "S'Matter, Pop?" it nw HOT fat 55 M 13 By C. M. Payne I - " Irrt" k,.d., el. 1 I ! , II iT". Tl I I 111, I - i i i lj r I ii m .cn . i i i r x i ' i J m r i Kfi k . m mm tessj r ii 3 Tr . "fe """'! s?f j fc r S O-u-- n- - - J K KB -- - S3fS- a "- S?TZ T30rO 1 eg " tS". - - i i V ' ' N 7" ; ; - spas - r - - - mmmtmrntmaXj I nr rinnnr. i. j r.- j .nr j nr irft i alaawwswssewwessasssswsa mmmmmmmmmmmmmmmm0mmmmmmmmmmmmmm0mmmmmmmaimmtmmimmmmi0mm0m0tm Mmmtmttttttiititmfimtmitmmtmmi nwi'wwww"! I 1 Nation-Famo- us tTmjuuuifJfaB Ten - No Wonder! UaSS&l B - My Hunt for Husband L rf- a LL 0 wmmmmm Ahem Ytk $ Bmttffl? Qmatfmr "W Ibf 4 New 7mSSH out tSwi I f KE md York Murders Wipe UMLel BE ovDWN,riaTj) By W. V. Pollock. By Alfred Henry Lewis See. this oeNCM STMt 6eNCH OMJ VV OtBtTlskt, Mil, g Ths Press r - bUak -g Ot. (Tee New Tent to VIII. THE LOVB- AT-FIRST -SlGHr' MAS. and mamma Instated that tha only Why to -- How Stoke$ Killed Fink and Why. Y9 JSOlursg of our I broke ray engagement ta Ogag. was to run away from town. M or PhBCtDIMO IWALMKNTK blue cigar lord Y smoke over all. fresh achemes Mamma and visited da O tn aw ManU Orna, fish, a Varmoater, after Ttriooe prnrlarUI or piracy In atocka and politics were al- I the 'e If OrtHii far furs-- aa then wast the Grand Canyon Aitsuna, where wa warn to use to New Tork. -

Comparing the Utility of User-Level and Kernel-Level Data for Dynamic Malware Analysis
Comparing the utility of User-level and Kernel-level data for Dynamic Malware Analysis A thesis submitted in partial fulfilment of the requirement for the degree of Doctor of Philosophy Matthew Nunes October 2019 Cardiff University School of Computer Science & Informatics i Copyright c 2019 Nunes, Matthew. Permission is granted to copy, distribute and/or modify this document under the terms of the GNU Free Documentation License, Version 1.2 or any later version published by the Free Software Foundation; with no Invariant Sections, no Front-Cover Texts, and no Back-Cover Texts. A copy of the license is included in the section entitled “GNU Free Documentation License”. A copy of this document in various transparent and opaque machine-readable formats and related software is available at http://orca.cf.ac.uk. Dedication ii To my family (blood or otherwise) for their love and support. iii Abstract Dynamic malware analysis is fast gaining popularity over static analysis since it is not easily defeated by evasion tactics such as obfuscation and polymorphism. During dynamic analysis, it is common practice to capture the system calls that are made to better understand the behaviour of malware. System calls are captured by hooking certain structures in the Operating System. There are several hooking techniques that broadly fall into two categories, those that run at user-level and those that run at kernel- level. User-level hooks are currently more popular despite there being no evidence that they are better suited to detecting malware. The focus in much of the literature surrounding dynamic malware analysis is on the data analysis method over the data capturing method. -

Flashdetect: Actionscript 3 Malware Detection
FlashDetect: ActionScript 3 malware detection Timon Van Overveldt1, Christopher Kruegel23, and Giovanni Vigna23 1 Katholieke Universiteit Leuven, Belgium, [email protected] 2 University of California, Santa Barbara, USA, {chris,vigna}@cs.ucsb.edu 3 Lastline, Inc. Abstract. Adobe Flash is present on nearly every PC, and it is in- creasingly being targeted by malware authors. Despite this, research into methods for detecting malicious Flash files has been limited. Similarly, there is very little documentation available about the techniques com- monly used by Flash malware. Instead, most research has focused on JavaScript malware. This paper discusses common techniques such as heap spraying, JIT spraying, and type confusion exploitation in the context of Flash mal- ware. Where applicable, these techniques are compared to those used in malicious JavaScript. Subsequently, FlashDetect is presented, an off- line Flash file analyzer that uses both dynamic and static analysis, and that can detect malicious Flash files using ActionScript 3. FlashDetect classifies submitted files using a naive Bayesian classifier based on a set of predefined features. Our experiments show that FlashDetect has high classification accuracy, and that its efficacy is comparable with that of commercial anti-virus products. Keywords: Flash exploit analysis, malicious ActionScript 3 detection, Flash type confusion 1 Introduction Adobe Flash is a technology that provides advanced video playback and anima- tion capabilities to developers through an advanced scripting language. The files played by Flash, called SWFs, are often embedded into webpages to be played by a browser plugin, or are embedded into a PDF file to be played by a copy of the Flash Player included in Adobe’s Acrobat Reader. -

Lista Ofrecida Por Mashe De Forobeta. Visita Mi Blog Como Agradecimiento :P Y Pon E Me Gusta En Forobeta!
Lista ofrecida por mashe de forobeta. Visita mi blog como agradecimiento :P Y pon e Me Gusta en Forobeta! http://mashet.com/ Seguime en Twitter si queres tambien y avisame que sos de Forobeta y voy a evalu ar si te sigo o no.. >>@mashet NO ABUSEN Y SIGAN LOS CONSEJOS DEL THREAD! http://blog.newsarama.com/2009/04/09/supernaturalcrimefightinghasanewname anditssolomonstone/ http://htmlgiant.com/?p=7408 http://mootools.net/blog/2009/04/01/anewnameformootools/ http://freemovement.wordpress.com/2009/02/11/rlctochangename/ http://www.mattheaton.com/?p=14 http://www.webhostingsearch.com/blog/noavailabledomainnames068 http://findportablesolarpower.com/updatesandnews/worldresponsesearthhour2009 / http://www.neuescurriculum.org/nc/?p=12 http://www.ybointeractive.com/blog/2008/09/18/thewrongwaytochooseadomain name/ http://www.marcozehe.de/2008/02/29/easyariatip1usingariarequired/ http://www.universetoday.com/2009/03/16/europesclimatesatellitefailstoleave pad/ http://blogs.sjr.com/editor/index.php/2009/03/27/touchinganerveresponsesto acolumn/ http://blog.privcom.gc.ca/index.php/2008/03/18/yourcreativejuicesrequired/ http://www.taiaiake.com/27 http://www.deadmilkmen.com/2007/08/24/leaveusaloan/ http://www.techgadgets.in/household/2007/06/roboamassagingchairresponsesto yourvoice/ http://blog.swishzone.com/?p=1095 http://www.lorenzogil.com/blog/2009/01/18/mappinginheritancetoardbmswithst ormandlazrdelegates/ http://www.venganza.org/about/openletter/responses/ http://www.middleclassforum.org/?p=405 http://flavio.castelli.name/qjson_qt_json_library http://www.razorit.com/designers_central/howtochooseadomainnameforapree -

Brutalny Napad Brutalny Napad
18 grudnia 2000 r, Nr 245 (15 387) Plebiscyty Wydanie O NAKŁAD : 44 125 z nagrodami Cena 80 gr • Dł a kogo Laur •• No.';n"~ ;+-'-~ Ukazuje się w Polsce - str. 22. południowo-wschodniej • Jutro lista kandydatów e-mail [email protected] do tytufu" Czlowiek TysIą cl ec ia " • Kto n aj ł e pszym sportowcem? www . nowi ny _ med ia. pł - str. 13. Redaktor prowadzący Finat plebiscy1lów Elżbieta Kolano GAZETA CODZIENNA I PONIEDZIAŁEK - coraz Milczenie kryje Co naprawdę Katarzyna Wójcicka maltretowanie stało się i Paweł Zygmunt , kobiet w grudniu mistrzami w rodzinach. 1970 r. wieloboju. na Wybrzeżu str. 21 str. 6 str. 14 Spotkali się internowani, więźniowie , politycy Nasza chata J u ż jutro wraz z ~ Nowinam iH IJdod~:;~r~~f. bezpłatny Więzienne I ~ N asza Chata", a w nim wiele praktycznych porad • nI.: klejenia tapet i samodzielnego uk ładania paneli rocznice podłogowych , Ponadto dowiesz się o zaletach BARTOSZ B ĄCA l dar n ośc i" za zryw narodowo marmuru i granitu ś ciowy . za umożliwieni e wp ro naturalnego oraz ZAŁIi:ł:E K . RZESZOWA. wadzeniu kapelanów do w i ę z i eń Sltucznego. L Wczoraj w Zakładzie Karnym - powiedzial ks . bp Edward spotkali się członkowie NSZZ B i a ł ogłow s ki . "Solidarność ". którzy trafili Podczas koncelebrowanej tam po ogłoszeniu stanu wo przez niego mszy św , przed jennego. Tego samego dnia stawiciele "S" z l ożyli w darze Wyrok na pijanych zakład obchodził 20-lecle ornat do po s ł ugi li turgicznej, funkcjonowania. Potem dzielono s ię opłatk i em , Karanie za j azdę po pijanemu spowoduje tłok w więz i e nia c h .