A Phylogenetic Approach to Inferring the Order in Which Mutations Arise During Cancer Progression
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Deutsche Gesellschaft Für Experimentelle Und Klinische Pharmakologie Und Toxikologie E.V
Naunyn-Schmiedeberg´s Arch Pharmacol (2013 ) 386 (Suppl 1):S1–S104 D OI 10.1007/s00210-013-0832-9 Deutsche Gesellschaft für Experimentelle und Klinische Pharmakologie und Toxikologie e.V. Abstracts of the 79 th Annual Meeting March 5 – 7, 2013 Halle/Saale, Germany This supplement was not sponsored by outside commercial interests. It was funded entirely by the publisher. 123 S2 S3 001 003 Multitarget approach in the treatment of gastroesophagel reflux disease – Nucleoside Diphosphate Kinase B is a Novel Receptor-independent Activator of comparison of a proton-pump inhibitor with STW 5 G-protein Signaling in Clinical and Experimental Atrial Fibrillation Abdel-Aziz H.1,2, Khayyal M. T.3, Kelber O.2, Weiser D.2, Ulrich-Merzenich G.4 Abu-Taha I.1, Voigt N.1, Nattel S.2, Wieland T.3, Dobrev D.1 1Inst. of Pharmaceutical & Medicinal Chemistry, University of Münster Pharmacology, 1Universität Duisburg-Essen Institut für Pharmakologie, Hufelandstr. 55, 45122 Essen, Hittorfstr 58-62, 48149 Münster, Germany Germany 2Steigerwald Arzneimittelwerk Wissenschaft, Havelstr 5, 64295 Darmstadt, Germany 2McGill University Montreal Heart Institute, 3655 Promenade Sir-William-Osler, Montréal 3Faculty of Pharmacy, Cairo University Pharmacology, Cairo Egypt Québec H3G 1Y6, Canada 4Medizinische Poliklinik, University of Bonn, Wilhelmstr. 35-37, 53111 Bonn, Germany 3Medizinische Fakultät Mannheim der Universität Heidelberg Institutes für Experimentelle und Klinische Pharmakologie und Toxikologie, Maybachstr. 14, 68169 Gastroesophageal reflux disease (GERD) was the most common GI-diagnosis (8.9 Mannheim, Germany million visits) in the US in 2012 (1). Proton pump inhibitors (PPI) are presently the mainstay of therapy, but in up to 40% of the patients complete symptom control fails. -

140503 IPF Signatures Supplement Withfigs Thorax
Supplementary material for Heterogeneous gene expression signatures correspond to distinct lung pathologies and biomarkers of disease severity in idiopathic pulmonary fibrosis Daryle J. DePianto1*, Sanjay Chandriani1⌘*, Alexander R. Abbas1, Guiquan Jia1, Elsa N. N’Diaye1, Patrick Caplazi1, Steven E. Kauder1, Sabyasachi Biswas1, Satyajit K. Karnik1#, Connie Ha1, Zora Modrusan1, Michael A. Matthay2, Jasleen Kukreja3, Harold R. Collard2, Jackson G. Egen1, Paul J. Wolters2§, and Joseph R. Arron1§ 1Genentech Research and Early Development, South San Francisco, CA 2Department of Medicine, University of California, San Francisco, CA 3Department of Surgery, University of California, San Francisco, CA ⌘Current address: Novartis Institutes for Biomedical Research, Emeryville, CA. #Current address: Gilead Sciences, Foster City, CA. *DJD and SC contributed equally to this manuscript §PJW and JRA co-directed this project Address correspondence to Paul J. Wolters, MD University of California, San Francisco Department of Medicine Box 0111 San Francisco, CA 94143-0111 [email protected] or Joseph R. Arron, MD, PhD Genentech, Inc. MS 231C 1 DNA Way South San Francisco, CA 94080 [email protected] 1 METHODS Human lung tissue samples Tissues were obtained at UCSF from clinical samples from IPF patients at the time of biopsy or lung transplantation. All patients were seen at UCSF and the diagnosis of IPF was established through multidisciplinary review of clinical, radiological, and pathological data according to criteria established by the consensus classification of the American Thoracic Society (ATS) and European Respiratory Society (ERS), Japanese Respiratory Society (JRS), and the Latin American Thoracic Association (ALAT) (ref. 5 in main text). Non-diseased normal lung tissues were procured from lungs not used by the Northern California Transplant Donor Network. -

ZNF263 Is a Transcriptional Regulator of Heparin and Heparan Sulfate Biosynthesis
ZNF263 is a transcriptional regulator of heparin and heparan sulfate biosynthesis Ryan J. Weissa,1, Philipp N. Spahnb,1, Alejandro Gómez Toledoa, Austin W. T. Chiangb, Benjamin P. Kellmanb,JingLia, Christopher Bennerc, Christopher K. Glassa,c,PhilipL.S.M.Gordtsc,d,NathanE.Lewisb,d,e,2, and Jeffrey D. Eskoa,d,2,3 aDepartment of Cellular and Molecular Medicine, University of California San Diego, La Jolla, CA 92093-0687; bDepartment of Pediatrics, University of California San Diego, La Jolla, CA 92093-0760; cDepartment of Medicine, University of California San Diego, La Jolla, CA 92093-0687; dGlycobiology Research and Training Center, University of California San Diego, La Jolla, CA 92093-0687; and eDepartment of Bioengineering, University of California San Diego, La Jolla, CA 92093-0687 Edited by Tadatsugu Taniguchi, University of Tokyo, Meguro-ku, Japan, and approved March 9, 2020 (received for review December 2, 2019) Heparin is the most widely prescribed biopharmaceutical in pro- inactivate thrombin and Factor Xa, which accounts for its potent duction globally. Its potent anticoagulant activity and safety makes anticoagulant activity (4). it the drug of choice for preventing deep vein thrombosis and In 2008, the US Food and Drug Administration issued a major pulmonary embolism. In 2008, adulterated material was intro- recall of pharmaceutical heparin due to contamination of the duced into the heparin supply chain, resulting in several hundred raw heparin stock imported from China. This crisis prompted deaths and demonstrating the need for alternate sources of heparin. new guidelines for monitoring the purity of heparin, but the Heparin is a fractionated form of heparan sulfate derived from feedstock remains vulnerable to natural variation, susceptibility animal sources, predominantly from connective tissue mast cells in of the pig population to infectious agents, and potential con- pig mucosa. -

Newly Identified Gon4l/Udu-Interacting Proteins
www.nature.com/scientificreports OPEN Newly identifed Gon4l/ Udu‑interacting proteins implicate novel functions Su‑Mei Tsai1, Kuo‑Chang Chu1 & Yun‑Jin Jiang1,2,3,4,5* Mutations of the Gon4l/udu gene in diferent organisms give rise to diverse phenotypes. Although the efects of Gon4l/Udu in transcriptional regulation have been demonstrated, they cannot solely explain the observed characteristics among species. To further understand the function of Gon4l/Udu, we used yeast two‑hybrid (Y2H) screening to identify interacting proteins in zebrafsh and mouse systems, confrmed the interactions by co‑immunoprecipitation assay, and found four novel Gon4l‑interacting proteins: BRCA1 associated protein‑1 (Bap1), DNA methyltransferase 1 (Dnmt1), Tho complex 1 (Thoc1, also known as Tho1 or HPR1), and Cryptochrome circadian regulator 3a (Cry3a). Furthermore, all known Gon4l/Udu‑interacting proteins—as found in this study, in previous reports, and in online resources—were investigated by Phenotype Enrichment Analysis. The most enriched phenotypes identifed include increased embryonic tissue cell apoptosis, embryonic lethality, increased T cell derived lymphoma incidence, decreased cell proliferation, chromosome instability, and abnormal dopamine level, characteristics that largely resemble those observed in reported Gon4l/udu mutant animals. Similar to the expression pattern of udu, those of bap1, dnmt1, thoc1, and cry3a are also found in the brain region and other tissues. Thus, these fndings indicate novel mechanisms of Gon4l/ Udu in regulating CpG methylation, histone expression/modifcation, DNA repair/genomic stability, and RNA binding/processing/export. Gon4l is a nuclear protein conserved among species. Animal models from invertebrates to vertebrates have shown that the protein Gon4-like (Gon4l) is essential for regulating cell proliferation and diferentiation. -

Supplementary Material Computational Prediction of SARS
Supplementary_Material Computational prediction of SARS-CoV-2 encoded miRNAs and their putative host targets Sheet_1 List of potential stem-loop structures in SARS-CoV-2 genome as predicted by VMir. Rank Name Start Apex Size Score Window Count (Absolute) Direct Orientation 1 MD13 2801 2864 125 243.8 61 2 MD62 11234 11286 101 211.4 49 4 MD136 27666 27721 104 205.6 119 5 MD108 21131 21184 110 204.7 210 9 MD132 26743 26801 119 188.9 252 19 MD56 9797 9858 128 179.1 59 26 MD139 28196 28233 72 170.4 133 28 MD16 2934 2974 76 169.9 71 43 MD103 20002 20042 80 159.3 403 46 MD6 1489 1531 86 156.7 171 51 MD17 2981 3047 131 152.8 38 87 MD4 651 692 75 140.3 46 95 MD7 1810 1872 121 137.4 58 116 MD140 28217 28252 72 133.8 62 122 MD55 9712 9758 96 132.5 49 135 MD70 13171 13219 93 130.2 131 164 MD95 18782 18820 79 124.7 184 173 MD121 24086 24135 99 123.1 45 176 MD96 19046 19086 75 123.1 179 196 MD19 3197 3236 76 120.4 49 200 MD86 17048 17083 73 119.8 428 223 MD75 14534 14600 137 117 51 228 MD50 8824 8870 94 115.8 79 234 MD129 25598 25642 89 115.6 354 Reverse Orientation 6 MR61 19088 19132 88 197.8 271 10 MR72 23563 23636 148 188.8 286 11 MR11 3775 3844 136 185.1 116 12 MR94 29532 29582 94 184.6 271 15 MR43 14973 15028 109 183.9 226 27 MR14 4160 4206 89 170 241 34 MR35 11734 11792 111 164.2 37 52 MR5 1603 1652 89 152.7 118 53 MR57 18089 18132 101 152.7 139 94 MR8 2804 2864 122 137.4 38 107 MR58 18474 18508 72 134.9 237 117 MR16 4506 4540 72 133.8 311 120 MR34 10010 10048 82 132.7 245 133 MR7 2534 2578 90 130.4 75 146 MR79 24766 24808 75 127.9 59 150 MR65 21528 21576 99 127.4 83 180 MR60 19016 19049 70 122.5 72 187 MR51 16450 16482 75 121 363 190 MR80 25687 25734 96 120.6 75 198 MR64 21507 21544 70 120.3 35 206 MR41 14500 14542 84 119.2 94 218 MR84 26840 26894 108 117.6 94 Sheet_2 List of stable stem-loop structures based on MFE. -

2013: DGPT-Programm, Halle / Saale
79. Jahrestagung der Deutschen Gesellschaft für Experimentelle und Klinische Pharmakologie und Toxikologie e. V. (DGPT) 5. – 7. März 2013 Martin-Luther-Universität Halle-Wittenberg www.dgpt-2013.de Anzeige METRIS 79. Jahrestagung der Deutschen Gesellschaft für Experimentelle und Klinische Pharmakologie und Toxikologie e. V. (DGPT) 5. – 7. März 2013 Martin-Luther-Universität Halle-Wittenberg Inhaltsverzeichnis Willkommensgruß der Tagungspräsidentin . 3 Willkommensgruß des Präsidenten der DGPT e. V. 4 Veranstalter und Organisation . 5 Allgemeine Informationen . 6 Lageplan Hörsaalzentrum . 7 Sponsoren und Aussteller . 8-9 Ausstellungsplan . 10 Programmübersicht . 11-13 Parallele Sitzungen und AK-Treffen . 14 Posterinformation . 15 Preisverleihung und Gesellschaftsabend . 16 MONTAG, 04.03.2013 . 17-18 Advanced Courses . 17-18 DIENSTAG, 05.03.2013 . 19 Kongresseröffnung – Grußworte . 19 Plenarvortrag Klinische Pharmakologie . 19 Kurzvorträge der Gesellschaften . 19-27 Forum Junge Wissenschaft in der DGPT . 27 Postersitzung I . 28-54 Symposien der Gesellschaften . 54-55 Mitgliederversammlungen . 55 MITTWOCH, 06.03.2013 . 56 Kurzvorträge der Gesellschaften . 56-60 Plenarvortrag – Toxikologie . 61 Symposien der Gesellschaften . 61-62 Satellitensymposium der Roche Pharma AG . 63 Kurzvorträge der Gesellschaften . 63-64 Symposium und Pressekonferenz . 64 Forum Junge Wissenschaft in der DGPT . 64 Postersitzung II . 65-88 Gesellschaftsabend . 88 DONNERSTAG, 07.03.2013 . 89 Symposien der Gesellschaften . 89 Kurzvorträge der Gesellschaften . 89-90 Plenarvortrag Pharmakologie . 90 Symposien der Gesellschaften . 91 Arbeitskreis für Neuropharmakologie/Neurotoxikologie . 92 Verleihung der Poster- und Vortragspreise . 92 Verzeichnis der Hauptautoren, Referenten und Vorsitzenden . 93-99 Liniennetzplan der HAVAG . 100 Anfahrt und Anreise . 101 Willkommensgruß der Tagungspräsidentin Liebe Kolleginnen, liebe Kollegen, ich begrüße Sie sehr herzlich zur 79. Jahrestagung der Deutschen Gesellschaft für Experimentelle und Klinische Pharmakologie und Toxikologie. -

Epigenetic Mechanisms Are Involved in the Oncogenic Properties of ZNF518B in Colorectal Cancer
Epigenetic mechanisms are involved in the oncogenic properties of ZNF518B in colorectal cancer Francisco Gimeno-Valiente, Ángela L. Riffo-Campos, Luis Torres, Noelia Tarazona, Valentina Gambardella, Andrés Cervantes, Gerardo López-Rodas, Luis Franco and Josefa Castillo SUPPLEMENTARY METHODS 1. Selection of genomic sequences for ChIP analysis To select the sequences for ChIP analysis in the five putative target genes, namely, PADI3, ZDHHC2, RGS4, EFNA5 and KAT2B, the genomic region corresponding to the gene was downloaded from Ensembl. Then, zoom was applied to see in detail the promoter, enhancers and regulatory sequences. The details for HCT116 cells were then recovered and the target sequences for factor binding examined. Obviously, there are not data for ZNF518B, but special attention was paid to the target sequences of other zinc-finger containing factors. Finally, the regions that may putatively bind ZNF518B were selected and primers defining amplicons spanning such sequences were searched out. Supplementary Figure S3 gives the location of the amplicons used in each gene. 2. Obtaining the raw data and generating the BAM files for in silico analysis of the effects of EHMT2 and EZH2 silencing The data of siEZH2 (SRR6384524), siG9a (SRR6384526) and siNon-target (SRR6384521) in HCT116 cell line, were downloaded from SRA (Bioproject PRJNA422822, https://www.ncbi. nlm.nih.gov/bioproject/), using SRA-tolkit (https://ncbi.github.io/sra-tools/). All data correspond to RNAseq single end. doBasics = TRUE doAll = FALSE $ fastq-dump -I --split-files SRR6384524 Data quality was checked using the software fastqc (https://www.bioinformatics.babraham. ac.uk /projects/fastqc/). The first low quality removing nucleotides were removed using FASTX- Toolkit (http://hannonlab.cshl.edu/fastxtoolkit/). -

Transcriptional Regulation of the Human Immunodeficiency Virus Type 1 Enhancer Binding Protein 1 (HIVEP1)
Transcriptional regulation of the human immunodeficiency virus type 1 enhancer binding protein 1 (HIVEP1) Regulation der Transkription des human immunodeficiency virus type 1 enhancer binding protein 1 (HIVEP1 ) A. Salomon 1,2 , B. Schmitz 2, M. Herrmann 3, A. Rötrige 1, E. Brand 3, P.E. Morange 4, F. Cambien 5, L. Tiret 5, D. Trègouët 5, S.-M. Brand 1,2 1Leibniz-Institute for Arteriosclerosis Research, Münster; 2Medical Faculty of the Westfalian Wilhelms-University of Münster, Department of Molecular Genetics of Cardiovascular Disease, University of Muenster, Münster; 3University Hospital Münster, Internal Medicine D, Münster; 4INSERM, UMR_S 626, Marseille; 5INSERM, UMR_S 525, Paris Objective: As a ZAS-family member, HIVEP1 binds specific DNA sequences, including NF-ĸB and other proinflammatory consensus sequences. We recently identified rs169713, positioned 90 kb upstream of the HIVEP1 gene, to be replicatively associated with venous thrombosis (AJHG 2010) in a multistage study following GWAs. Methods: Serial HIVEP1 promoter deletion constructs were cloned into a pGL3- Basic vector, and a 332 bp potential enhancer fragment, harbouring rs169713C/T, into the pGL3-Promoter vector. Reporter gene assays were performed by transient transfection and overexpression of transcription factors was executed by cotransfection assays in vascular endothelial cells EA.hy926 and THP1 monocytes. Bandshift assays were performed with EA.hy926 and THP1 nuclear extracts. Results: In EA.hy926 cells, endogenous HIVEP1 expression was increased by proinflammatory cytokines TNF α, IL1 β and IL4. The construct harbouring rs169713T showed significantly higher transcriptional activity over the empty pGL3-Promoter vector and the one including rs169713C (both P<0.001); similar results were revealed in THP1 cells. -

1 Type I Interferon Transcriptional Network Regulates Expression Of
bioRxiv preprint doi: https://doi.org/10.1101/2020.10.30.362947; this version posted October 31, 2020. The copyright holder for this preprint (which was not certified by peer review) is the author/funder, who has granted bioRxiv a license to display the preprint in perpetuity. It is made available under aCC-BY-NC-ND 4.0 International license. Type I Interferon Transcriptional Network Regulates Expression of Coinhibitory Receptors in Human T cells Tomokazu S. Sumida*1, Shai Dulberg2*, Jonas Schupp3*, Helen A. Stillwell1, Pierre-Paul Axisa1, Michela Comi1, Matthew Lincoln1, Avraham Unterman3, Naftali Kaminski3, Asaf Madi2,4, Vijay K. Kuchroo4,5,†, David A. Hafler1,5,† 1Departments of Neurology and Immunobiology, Yale School of Medicine, New Haven, CT, USA. 2 Department of Pathology, Sackler School of Medicine, Tel Aviv University, Tel Aviv, Israel. 3Section of Pulmonary, Critical Care and Sleep Medicine Section, Department of Internal Medicine, Yale School of Medicine, New Haven, CT, USA. 4 Evergrande Center for Immunologic Diseases and Ann Romney Center for Neurologic Diseases, Harvard Medical School and Brigham and Women's Hospital, Boston, MA, USA. 5Broad Institute of MIT and Harvard, Cambridge, MA, USA. *Equal Contributions † Correspondence to Drs. Vijay Kuchroo ([email protected]) or David Hafler ([email protected]) 1 bioRxiv preprint doi: https://doi.org/10.1101/2020.10.30.362947; this version posted October 31, 2020. The copyright holder for this preprint (which was not certified by peer review) is the author/funder, who has granted bioRxiv a license to display the preprint in perpetuity. It is made available under aCC-BY-NC-ND 4.0 International license. -

Genomic Insights Into the Pathogenesis of Epstein–Barr Virus
Gebauer et al. Blood Cancer Journal (2021) 11:102 https://doi.org/10.1038/s41408-021-00493-5 Blood Cancer Journal ARTICLE Open Access Genomic insights into the pathogenesis of Epstein–Barr virus-associated diffuse large B-cell lymphoma by whole-genome and targeted amplicon sequencing Niklas Gebauer 1,2,AxelKünstner 2,3,4, Julius Ketzer1,2,5,HannoM.Witte 1,2,6,TobiasRausch 7, Vladimir Benes 7, Jürgen Zimmermann7,JudithGebauer2,8,HartmutMerz9,VeronicaBernard9, Lana Harder10,KatharinaRatjen10, Stefan Gesk10,WolfgangPeter11,12, Yannik Busch11, Peter Trojok11, Nikolas von Bubnoff 1,2, Harald Biersack1,2, Hauke Busch2,3,4 and Alfred C. Feller9 Abstract Epstein–Barr virus (EBV)-associated diffuse large B-cell lymphoma not otherwise specified (DLBCL NOS) constitute a distinct clinicopathological entity in the current World Health Organization (WHO) classification. However, its genomic features remain sparsely characterized. Here, we combine whole-genome sequencing (WGS), targeted amplicon sequencing (tNGS), and fluorescence in situ hybridization (FISH) from 47 EBV + DLBCL (NOS) cases to delineate the genomic landscape of this rare disease. Integrated WGS and tNGS analysis clearly distinguished this tumor type from EBV-negative DLBCL due to frequent mutations in ARID1A (45%), KMT2A/KMT2D (32/30%), ANKRD11 (32%), or NOTCH2 (32%). WGS uncovered structural aberrations including 6q deletions (5/8 patients), which were subsequently validated 1234567890():,; 1234567890():,; 1234567890():,; 1234567890():,; by FISH (14/32 cases). Expanding on previous reports, we identified recurrent alterations in CCR6 (15%), DAPK1 (15%), TNFRSF21 (13%), CCR7 (11%), and YY1 (6%). Lastly, functional annotation of the mutational landscape by sequential gene set enrichment and network propagation predicted an effect on the nuclear factor κB (NFκB) pathway (CSNK2A2, CARD10), IL6/JAK/STAT (SOCS1/3, STAT3), and WNT signaling (FRAT1, SFRP5) alongside aberrations in immunological processes, such as interferon response. -

Autocrine IFN Signaling Inducing Profibrotic Fibroblast Responses By
Downloaded from http://www.jimmunol.org/ by guest on September 23, 2021 Inducing is online at: average * The Journal of Immunology , 11 of which you can access for free at: 2013; 191:2956-2966; Prepublished online 16 from submission to initial decision 4 weeks from acceptance to publication August 2013; doi: 10.4049/jimmunol.1300376 http://www.jimmunol.org/content/191/6/2956 A Synthetic TLR3 Ligand Mitigates Profibrotic Fibroblast Responses by Autocrine IFN Signaling Feng Fang, Kohtaro Ooka, Xiaoyong Sun, Ruchi Shah, Swati Bhattacharyya, Jun Wei and John Varga J Immunol cites 49 articles Submit online. Every submission reviewed by practicing scientists ? is published twice each month by Receive free email-alerts when new articles cite this article. Sign up at: http://jimmunol.org/alerts http://jimmunol.org/subscription Submit copyright permission requests at: http://www.aai.org/About/Publications/JI/copyright.html http://www.jimmunol.org/content/suppl/2013/08/20/jimmunol.130037 6.DC1 This article http://www.jimmunol.org/content/191/6/2956.full#ref-list-1 Information about subscribing to The JI No Triage! Fast Publication! Rapid Reviews! 30 days* Why • • • Material References Permissions Email Alerts Subscription Supplementary The Journal of Immunology The American Association of Immunologists, Inc., 1451 Rockville Pike, Suite 650, Rockville, MD 20852 Copyright © 2013 by The American Association of Immunologists, Inc. All rights reserved. Print ISSN: 0022-1767 Online ISSN: 1550-6606. This information is current as of September 23, 2021. The Journal of Immunology A Synthetic TLR3 Ligand Mitigates Profibrotic Fibroblast Responses by Inducing Autocrine IFN Signaling Feng Fang,* Kohtaro Ooka,* Xiaoyong Sun,† Ruchi Shah,* Swati Bhattacharyya,* Jun Wei,* and John Varga* Activation of TLR3 by exogenous microbial ligands or endogenous injury-associated ligands leads to production of type I IFN. -
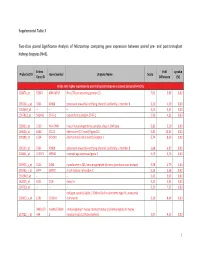
Supplemental Table 3 Two-Class Paired Significance Analysis of Microarrays Comparing Gene Expression Between Paired
Supplemental Table 3 Two‐class paired Significance Analysis of Microarrays comparing gene expression between paired pre‐ and post‐transplant kidneys biopsies (N=8). Entrez Fold q‐value Probe Set ID Gene Symbol Unigene Name Score Gene ID Difference (%) Probe sets higher expressed in post‐transplant biopsies in paired analysis (N=1871) 218870_at 55843 ARHGAP15 Rho GTPase activating protein 15 7,01 3,99 0,00 205304_s_at 3764 KCNJ8 potassium inwardly‐rectifying channel, subfamily J, member 8 6,30 4,50 0,00 1563649_at ‐‐ ‐‐ ‐‐ 6,24 3,51 0,00 1567913_at 541466 CT45‐1 cancer/testis antigen CT45‐1 5,90 4,21 0,00 203932_at 3109 HLA‐DMB major histocompatibility complex, class II, DM beta 5,83 3,20 0,00 204606_at 6366 CCL21 chemokine (C‐C motif) ligand 21 5,82 10,42 0,00 205898_at 1524 CX3CR1 chemokine (C‐X3‐C motif) receptor 1 5,74 8,50 0,00 205303_at 3764 KCNJ8 potassium inwardly‐rectifying channel, subfamily J, member 8 5,68 6,87 0,00 226841_at 219972 MPEG1 macrophage expressed gene 1 5,59 3,76 0,00 203923_s_at 1536 CYBB cytochrome b‐245, beta polypeptide (chronic granulomatous disease) 5,58 4,70 0,00 210135_s_at 6474 SHOX2 short stature homeobox 2 5,53 5,58 0,00 1562642_at ‐‐ ‐‐ ‐‐ 5,42 5,03 0,00 242605_at 1634 DCN decorin 5,23 3,92 0,00 228750_at ‐‐ ‐‐ ‐‐ 5,21 7,22 0,00 collagen, type III, alpha 1 (Ehlers‐Danlos syndrome type IV, autosomal 201852_x_at 1281 COL3A1 dominant) 5,10 8,46 0,00 3493///3 IGHA1///IGHA immunoglobulin heavy constant alpha 1///immunoglobulin heavy 217022_s_at 494 2 constant alpha 2 (A2m marker) 5,07 9,53 0,00 1 202311_s_at