Optimizing Paas Provider Profit Under Service Level Agreement Constraints Djawida Dib
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

WEIYANG (STEPHEN) YUAN [email protected] | Chicago | 608-504-0649 | Stephenyuan.Urspace.Io Education University of Wisconsin-Madison B.S
WEIYANG (STEPHEN) YUAN [email protected] | Chicago | 608-504-0649 | stephenyuan.urspace.io Education University of Wisconsin-Madison B.S. in Computer Engineering May 2020 ● GPA: 3.83/4.0 ● Related Coursework: Operating Systems • A rtificial Intelligence • Computer Networks and Communication • Databases • Information Security • Big Data Systems • Android Mobile Development Skills ● Programming Languages: Java • Golang • C++ • Scala • MATLAB • SQL • Julia • C • Python ● Technologies: Git, Linux, Java Spring, Amazon Web Services (AWS), MongoDB, Postgres, React, Node.js, Docker, Jenkins, Play Framework, Hadoop, Spark, Wireshark, Visual Studio Experience Enfusion, Chicago Java Software Developer July 2020 - Current ● Develop the portfolio management software system used by over 500 clients that supports a variety of financial calculation and valuation over 20 financial derivatives as well as back office general ledger and cash flow with more than 10,000 daily positions on average ● Take responsibility in the whole development lifecycle from designing (10%), implementing (40%), running regression & unit testing (40%) to supporting internal and production issues (10%) ● Apply experience of Object-Oriented design patterns and best practices to creating a robust and reliable infrastructure for the system with knowledge of Java SE, Hibernate, JMS, JVM and MySQL and deliver constant results in weekly production release ● Automate development and testing frameworks by writing python and shell scripts to improve overall -

HP Datacenter Care - Datacenter Care for Cloud Datasheet Addendum HP Technology Services - Contractual Services
Technical data HP Datacenter Care - Datacenter Care for Cloud datasheet addendum HP Technology Services - Contractual Services HP Datacenter Care for Cloud (DC4C) is a version of HP Datacenter Care developed to address the needs of complex private cloud and hybrid cloud environments built on the HP CloudSystem infrastructure and HP cloud management software. A primary feature of DC4C is its linkage to, and collaboration with, your HP Software Premier Support. Optional features and services can be added to DC4C to accommodate public cloud service providers, pay-per-use pricing, multivendor management, and more. Core features and options include the following: – Coordinates the sale, invoicing, and delivery of HP Datacenter Care and HP Software Premier Support for a simplified and unified experience across cloud infrastructure and cloud management software when purchased at the same time and under the same support coverage period – Joins together the Datacenter Care and Premier Support account teams and augments the deliverables they provide – Coordinates activities provided by Matrix Master technical experts when included in your DC4C Statement of Work – Can combine with Datacenter Care Flexible Capacity and Primary Service Provider capabilities – Offers a Hybrid Cloud Support (HCS) option to accommodate cloud service providers The features of HP Datacenter Care and Premier Support are fully described in their respective data sheets. This Datacenter Care for Cloud data sheet addendum highlights features or requirements that are different when the customer purchases these two services as a Datacenter Care for Cloud configuration, and highlights additional features or options that are of special interest in cloud environments. A mutually agreed-upon and executed Statement of Work will detail these additional features based upon your needs when you purchase Datacenter Care for Cloud along with your purchase of HP Software Premier Support. -
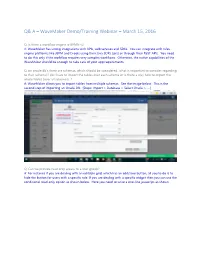
Q& a – Wavemaker Demo/Training Webinar – March 15, 2016
Q& A – WaveMaker Demo/Training Webinar – March 15, 2016 Q: Is there a workflow engine ie BPMN v2 A: WaveMaker has strong integrations with APIs, web services and SDKs. You can integrate with rules engine platforms like JBPM and Drools using their Java SDKs (jars) or through their ReST APIs. You need to do this only if the workflow requires very complex workflows. Otherwise, the native capabilities of the WaveMaker should be enough to take care of your app requirements. Q: on oracle db's there are schemas, which should be considered...what is important to consider regarding to that (schema)? do I have to import the tables over each schema or is there a way how to import the whole tables (over all schemas)...? A: WaveMaker allows you to import tables from multiple schemas. See the image below. This is the second step of importing an Oracle DB. [Steps: Import > Database > Select Oracle > ….] Q: Can we provide read only access to a user group? A: For instance if you are dealing with an editable grid, which has an add/save button, all you to do is to hide the button for users with a specific role. If you are dealing with a specific widget then you can use the conditional read-only option as shown below. Here you need to write a one-line javascript as shown below, where the users with the role “rolename” will be presented a read-only birthdate. Q: Can we integrate the application for SSO ? A: You can configure SSO easily through the following approach. -

Evaluating Cloud Service Vendors with Comparison J.Jagadeesh Babu1 Mr.P.Saikiran 2 M.Tech Information Technology Dept of IT/LBRCE College India
Volume 3, Issue 5, May 2013 ISSN: 2277 128X International Journal of Advanced Research in Computer Science and Software Engineering Research Paper Available online at: www.ijarcsse.com Evaluating Cloud Service Vendors with Comparison J.Jagadeesh Babu1 Mr.P.Saikiran 2 M.Tech Information Technology Dept of IT/LBRCE college India. India. Abstract: In this paper we reviewed the technical and service aspects of different Cloud providers and presents the comparisons of these selected service offerings in cloud computing. By this User can have good understanding regarding services provided to avoid bottlenecks are also obstacles that could limit the growth. This comparison of cloud service providers, to serve as a starting point for user looking to take throw service and for Selecting the better one for there need into cloud environment . Keywords: Cloud Computing, Service Vendors, Cloud Services. I. Introduction As the use of computers in our day-to-day life has increased, the computing resources that we need also grown up. It was costly to buy a mainframe and computer‘s, it became important to find the alternative ways to get the greatest return on the investment, allowing multiple users to share among both the physical access to the computer from multiple terminals and to share the CPU time, eliminating periods of inactivity, which became known in the industry as time- sharing[1]. The origin of the term cloud computing is vague, but it appears to derive from the way of drawings of stylized clouds to denote networks in diagrams of computing and communications systems.Cloud computing is a paradigm shift in which computing is moved away from personal computers and even the individual enterprise application‘s to a ‗cloud‘ of computers. -

Deliverable No. 5.3 Techniques to Build the Cloud Infrastructure Available to the Community
Deliverable No. 5.3 Techniques to build the cloud infrastructure available to the community Grant Agreement No.: 600841 Deliverable No.: D5.3 Deliverable Name: Techniques to build the cloud infrastructure available to the community Contractual Submission Date: 31/03/2015 Actual Submission Date: 31/03/2015 Dissemination Level PU Public X PP Restricted to other programme participants (including the Commission Services) RE Restricted to a group specified by the consortium (including the Commission Services) CO Confidential, only for members of the consortium (including the Commission Services) Grant Agreement no. 600841 D5.3 – Techniques to build the cloud infrastructure available to the community COVER AND CONTROL PAGE OF DOCUMENT Project Acronym: CHIC Project Full Name: Computational Horizons In Cancer (CHIC): Developing Meta- and Hyper-Multiscale Models and Repositories for In Silico Oncology Deliverable No.: D5.3 Document name: Techniques to build the cloud infrastructure available to the community Nature (R, P, D, O)1 R Dissemination Level (PU, PP, PU RE, CO)2 Version: 1.0 Actual Submission Date: 31/03/2015 Editor: Manolis Tsiknakis Institution: FORTH E-Mail: [email protected] ABSTRACT: This deliverable reports on the technologies, techniques and configuration needed to install, configure, maintain and run a private cloud infrastructure for productive usage. KEYWORD LIST: Cloud infrastructure, OpenStack, Eucalyptus, CloudStack, VMware vSphere, virtualization, computation, storage, security, architecture. The research leading to these results has received funding from the European Community's Seventh Framework Programme (FP7/2007-2013) under grant agreement no 600841. The author is solely responsible for its content, it does not represent the opinion of the European Community and the Community is not responsible for any use that might be made of data appearing therein. -

Salesforce Heroku Enterprise: a Cloud Security Overview June 2016
Salesforce Heroku Enterprise: A Cloud Security Overview June 2016 1 Contents INTRODUCTION 3 CASESTUDY:GLIBC 19 Heroku behind the Curtain: Patching SALESFORCETRUSTMODEL 4 the glibc Security Hole What Do We Do When a Security CLOUD COMPUTING AND Vulnerability Lands? THESHAREDSECURITYMODEL 5 Provider Responsibilities How Do We Do This with Minimum Downtime? Tenant Responsibilities What about Data? INFRASTRUCTURE AND What about Heroku Itself? APPLICATIONSECURITY 8 Keep Calm, Carry On Server Hardening Customer Applications BUSINESSCONTINUITY 23 Heroku Platform: High Availability Container Hardening and Disaster Recovery Application Security Customer Applications Heroku Flow Postgres Databases Identity and Access Management Customer Configuration and Identity Federation via Single Sign-On Meta-Information Organizations, Roles, and Permissions Service Resiliency and Availability Business Continuity and Emergency NETWORKSECURITY 14 Preparedness Secure Network Architecture Secure Access Points INCIDENTRESPONSE 27 Data in Motion ELEMENTSMARKETPLACE 28 Private Spaces App Permissions Building Secure Applications with Add-Ons DATASECURITY 16 Heroku Postgres PHYSICALSECURITY 29 Encryption Data Center Access Customer Data Retention and Destruction Environmental Controls Management SECURITYMONITORING 17 Storage Device Decommissioning Logging and Network Monitoring DDoS COMPLIANCEANDAUDIT 31 Man in the Middle and IP Spoofing SUMMARY 33 Patch Management HEROKU ENTERPRISE SECURITY WHITE PAPER 2 Introduction eroku Enterprise, a key component of the Salesforce Platform, is a cloud application platform used by organizations of all sizes to deploy and operate applications throughout Hthe world. The Heroku platform is one of the first cloud application platforms delivered entirely as a service, allowing organizations to focus on application development and business strategy while Salesforce and the Heroku division of Salesforce focus on infrastructure management, scaling, and security. -

Dell Openstack Cloud Solution
Dell OpenStack Cloud Solution Peter Jung Senior Solutions Architect & Business Developer Fast. Easy. Now. Dell.com/OpenStack Dell.com/Crowbar Cloud expectations and promises Support the mobile & social marketplace Innovate and grow and workforce Anytime, anywhere, on any device access and Speed time to market when introducing new engagement. (BYOD) increases productivity and goods and services job satisfaction Apps Revenue Data “The Business” BI Cost Speed Efficiency Attract & retain new customers Reduce IT cost, deliver operational results On-demand, self-service and automated access Connect customer data, gain intelligence on lowers costs and decreases demands on IT customers to better target, nurture and solidify leads Cloud - Challenges for SP and Enterprise Service provider challenges Enterprise challenges • Cost-effectively scaling, and competing in the • Lack of infrastructure standardization and emerging public cloud ecosystem automation leading to poor resource utilization, cost escalation, slow application delivery • Ability to quickly launch new cloud services • Locked-in to proprietary vendors and • Keeping license costs down on traditional technologies – increasing license costs with virtualization solutions – costs increase linearly growth and scale with scale (often per node) • Poor understanding of cost allocations • Keeping maintenance costs down on home- grown components that have been built • Long resource provisioning cycle times haphazardly over time • Inflexible and non-adaptive infrastructure • Flexibility to rapidly add/change features in response to customer needs –commercial • Building a cloud is too complex and takes too solutions lack features they need long • Lack of availability and support of the entire end-to-end solution Cloud Taxonomy – Complex? Cloud service PaaS/SaaS management PaaS/SaaS services sit on top of this stack along with other any specific vertical solutions such as VDI, HPC, CDN etc. -

D1.5 Final Business Models
ITEA 2 Project 10014 EASI-CLOUDS - Extended Architecture and Service Infrastructure for Cloud-Aware Software Deliverable D1.5 – Final Business Models for EASI-CLOUDS Task 1.3: Business model(s) for the EASI-CLOUDS eco-system Editor: Atos, Gearshift Security public Version 1.0 Melanie Jekal, Alexander Krebs, Markku Authors Nurmela, Juhana Peltonen, Florian Röhr, Jan-Frédéric Plogmeier, Jörn Altmann, (alphabetically) Maurice Gagnaire, Mario Lopez-Ramos Pages 95 Deliverable 1.5 – Final Business Models for EASI-CLOUDS v1.0 Abstract The purpose of the business working group within the EASI-CLOUDS project is to investigate the commercial potential of the EASI-CLOUDS platform, and the brokerage and federation- based business models that it would help to enable. Our described approach is both ‘top down’ and ‘bottom up’; we begin by summarizing existing studies on the cloud market, and review how the EASI-CLOUDS project partners are positioned on the cloud value chain. We review emerging trends, concepts, business models and value drivers in the cloud market, and present results from a survey targeted at top cloud bloggers and cloud professionals. We then review how the EASI-CLOUDS infrastructure components create value both directly and by facilitating brokerage and federation. We then examine how cloud market opportunities can be grasped through different business models. Specifically, we examine value creation and value capture in different generic business models that may benefit from the EASI-CLOUDS infrastructure. We conclude by providing recommendations on how the different EASI-CLOUDS demonstrators may be commercialized through different business models. © EASI-CLOUDS Consortium. 2 Deliverable 1.5 – Final Business Models for EASI-CLOUDS v1.0 Table of contents Table of contents ........................................................................................................................... -

Cloud Computing: a Taxonomy of Platform and Infrastructure-Level Offerings David Hilley College of Computing Georgia Institute of Technology
Cloud Computing: A Taxonomy of Platform and Infrastructure-level Offerings David Hilley College of Computing Georgia Institute of Technology April 2009 Cloud Computing: A Taxonomy of Platform and Infrastructure-level Offerings David Hilley 1 Introduction Cloud computing is a buzzword and umbrella term applied to several nascent trends in the turbulent landscape of information technology. Computing in the “cloud” alludes to ubiquitous and inexhaustible on-demand IT resources accessible through the Internet. Practically every new Internet-based service from Gmail [1] to Amazon Web Services [2] to Microsoft Online Services [3] to even Facebook [4] have been labeled “cloud” offerings, either officially or externally. Although cloud computing has garnered significant interest, factors such as unclear terminology, non-existent product “paper launches”, and opportunistic marketing have led to a significant lack of clarity surrounding discussions of cloud computing technology and products. The need for clarity is well-recognized within the industry [5] and by industry observers [6]. Perhaps more importantly, due to the relative infancy of the industry, currently-available product offerings are not standardized. Neither providers nor potential consumers really know what a “good” cloud computing product offering should look like and what classes of products are appropriate. Consequently, products are not easily comparable. The scope of various product offerings differ and overlap in complicated ways – for example, Ama- zon’s EC2 service [7] and Google’s App Engine [8] partially overlap in scope and applicability. EC2 is more flexible but also lower-level, while App Engine subsumes some functionality in Amazon Web Services suite of offerings [2] external to EC2. -

KLIKON Solutions Adds High Quality Cloud Computing to Its IT Services Client Offering
KLIKON Solutions adds high quality cloud computing to its IT services client offering “We were determined to build our own cloud computing infrastructure. Our engineers thoroughly analysed the market offerings and many failed to impress. The quality and cost effectiveness of the HP storage solution was a stand out. Our confident message now to clients is simple: Jump On Board.” —David Abouhaidar, director, KLIKON Solutions HP customer Objective case study HP server To offer cloud computing as part of its managed and storage business services portfolio to clients solution delivers KLIKON’s cloud Approach computing vision Determined to offer a first class cloud computing Industry infrastructure capability to its client base, KLIKON IT services conducted a rigorous research and analysis of the market for more than 18 months IT improvements • Established secondary data centre • Achieved business continuity with 100 per cent redundancy • Assured of HP support across the end to end solution Business benefits KLIKON Solutions is an Australia-wide organisation • Achieved goal of adding cloud computing to its specialising in the design, implementation and services portfolio management of IT systems. The company goes • Met its cost targets in achieving a robust cloud beyond the traditional managed service provider computing platform format in delivering remote management of mission-critical services, managing infrastructure, • Well positioned to meet growing client appetite networking and security. It caters for the business for cloud computing needs of a client base that crosses industry sectors as • Removed the IT cost ownership burden diverse as aerospace, financial services, health care, from clients manufacturing and retail. KLIKON follows through on a thorough review of a client’s business and technical needs with a well established partner model that implements infrastructure services, network and security solutions. -

Vice Throughout My Masters Program
Western Kentucky University TopSCHOLAR® Masters Theses & Specialist Projects Graduate School Summer 2016 Vertical Implementation of Cloud for Education (V.I.C.E.) Travis S. Brummett Western Kentucky University, [email protected] Follow this and additional works at: http://digitalcommons.wku.edu/theses Part of the Computer Engineering Commons, and the Computer Sciences Commons Recommended Citation Brummett, Travis S., "Vertical Implementation of Cloud for Education (V.I.C.E.)" (2016). Masters Theses & Specialist Projects. Paper 1643. http://digitalcommons.wku.edu/theses/1643 This Thesis is brought to you for free and open access by TopSCHOLAR®. It has been accepted for inclusion in Masters Theses & Specialist Projects by an authorized administrator of TopSCHOLAR®. For more information, please contact [email protected]. VERTICAL IMPLEMENTATION OF CLOUD FOR EDUCATION (V.I.C.E.) A Thesis Presented to The Faculty of the Department of Computer Science Western Kentucky University Bowling Green, Kentucky In Partial Fulfillment Of the Requirements for the Degree Master of Science By Travis Brummett August 2016 DEDICATION To my mother, father, sister, and friends. & To the faculty of the Computer Science Department at Western Kentucky University. ACKNOWLEDGMENTS My appreciation goes to my professor and adviser, Dr. Michael Galloway. I am grateful for his support and advice throughout my Masters program. I truly appreciate the sacrifices he has made to meet with me,to help me attend conferences, and to provide his students with a place and supplies to do research. I have never seen someone so invested in his students as Dr. Galloway. He strives to find his students funding and built a lab for them to work. -

Cloud Computing Parallel Session Cloud Computing
Cloud Computing Parallel Session Jean-Pierre Laisné Open Source Strategy Bull OW2 Open Source Cloudware Initiative Cloud computing -Which context? -Which road map? -Is it so cloudy? -Openness vs. freedom? -Opportunity for Europe? Cloud in formation Source: http://fr.wikipedia.org/wiki/Fichier:Clouds_edited.jpg ©Bull, 2 ITEA2 - Artemis: Cloud Computing 2010 1 Context 1: Software commoditization Common Specifications Not process specific •Marginal product •Economies of scope differentiation Offshore •Input in many different •Recognized quality end-products or usage standards •Added value is created •Substituable goods downstream Open source •Minimize addition to end-user cost Mature products Volume trading •Marginal innovation Cloud •Economies of scale •Well known production computing •Industry-wide price process levelling •Multiple alternative •Additional margins providers through additional volume Commoditized IT & Internet-based IT usage ©Bull, 3 ITEA2 - Artemis: Cloud Computing 2010 Context 2: The Internet is evolving ©Bull, 4 ITEA2 - Artemis: Cloud Computing 2010 2 New trends, new usages, new business -Apps vs. web pages - Specialized apps vs. HTML5 - Segmentation vs. Uniformity -User “friendly” - Pay for convenience -New devices - Phones, TV, appliances, etc. - Global economic benefits of the Internet - 2010: $1.5 Trillion - 2020: $3.8 Trillion Information Technology and Innovation Foundation (ITIF) Long live the Internet ©Bull, 5 ITEA2 - Artemis: Cloud Computing 2010 Context 3: Cloud on peak of inflated expectations According to