The Apache Platform and Architecture
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Licensing Information User Manual Mysql Enterprise Monitor 3.4
Licensing Information User Manual MySQL Enterprise Monitor 3.4 Table of Contents Licensing Information .......................................................................................................................... 4 Licenses for Third-Party Components .................................................................................................. 5 Ant-Contrib ............................................................................................................................... 10 ANTLR 2 .................................................................................................................................. 11 ANTLR 3 .................................................................................................................................. 11 Apache Commons BeanUtils v1.6 ............................................................................................. 12 Apache Commons BeanUtils v1.7.0 and Later ........................................................................... 13 Apache Commons Chain .......................................................................................................... 13 Apache Commons Codec ......................................................................................................... 13 Apache Commons Collections .................................................................................................. 14 Apache Commons Daemon ...................................................................................................... 14 Apache -

(DIS) Installation Guide
Delegation Issuing Service (DIS) Installation Guide © University of Kent 2005-2010 Document History Version Date Comments 0.1 9 September 2005 First draft by Wensheng 0.2 12 September 2005 Updated by Tuan Anh 0.3 14 September 2005 Reviewed by David 1.0 15 September 2005 First public release 1.1 1 July 2006 Updated with Acceptance Tests for issuing attributes 1.2 24 July 2006 Update the installation instructions 1.3 26 July 2006 Updated with Acceptance Tests for revocation attributes 1.4 14 August 2006 Fix some inconsistencies after validating by Romain 1.5 3 October 2006 Add the SearchRequestor parameter, change the parameters in the configuration file using Permis standard parameters. 1.6 24 October 2006 Add instruction for using policy stored in a file 1.7 24 October 2006 Add support for java 1.5 1.8 22 February 2007 Add support for Tomat 5.5 1.9 23 April 2007 Add support for Apache 2.2 2.0 12 August 2008 Using PERMIS v5 policies and Apache http server on Windows (by Linying) 2.1 25 March 2009 Updated the authentication of tomcat, DIS installation instruction, instruction for apache2.2 (by Kaniz) 2.2 17 February 2010 Revised and updated by Kaniz 2.3 16 April 2010 Updated by Mark 2.5 26 October 2010 Install guide rewritten and separated into its own document 2.5.2 2 November 2010 Java installation explained more fully. Tomcat native library installation corrected. Default DIS configuration file inserted. 2.5.4 5 November 2010 Addressed feedback from Kaniz System Requirements For the DIS Web Service A recent Java Runtime Environment (JRE). -

Apachecon 2004 November 13-17, 2004 Las Vegas Nevada
ApacheCon 2004 November 13-17, 2004 Las Vegas Nevada CLICK SESSION TITLE FOR PRESENTATION TUTORIALS MONDAY TUESDAY WEDNESDAY T01 Introduction to the Apache Web Server T02 mod_perl 2.0 by Example T03 Apache Portable Runtime 1.0 Tutorial T06 Mangling data with XSLT T07 Test-Driven Apache Module Development T08 Tapestry In Action T09 SpamAssassin Tutorial T10 Everything You Always Wanted to Know About XML Parsing T11 Scalable Internet Architectures T12 Apache Derby/Cloudscape: Embed This! T13 Struts: the good, the bad, and the ugly T14 Subversion Tutorial T15 Digging deep into XML Schema with Apache XMLBeans T16 PHP Security T17 Taming Apache Cocoon T18 Lucene in Action Search Next Help ApacheCon 2004 November 13-17, 2004 Las Vegas Nevada CLICK SESSION TITLE FOR PRESENTATION TUTORIALS MONDAY TUESDAY WEDNESDAY MO01 Behind the Scenes of the Apache Software Foundation MO02 Apache 2.0 on Windows MO03 The State of Apache Geronimo MO04 Advanced Topics in Module Design: Threadsafety and Portability MO05 The Incubator: Starting a Successful Apache Open Source Project MO06 Apache authentication MO07 Comparing Web Frameworks: Struts, Spring MVC, WebWork, Tapestry & JSF MO08 WebDAV and Apache MO09 New and upcoming features in SpamAssassin v3 MO10 What's so great about Apache 2.0? MO11 Embedding Tomcat 5 into Applications Servers MO12 Logging and Configuration - Demystifying the banes of App development MO13 Storing SpamAssassin User Data in SQL Databases MO14 Shoehorning Apache Onto Your Box: System Sizing Tips MO15 Highly available web sites with Tomcat -

Abkürzungs-Liste ABKLEX
Abkürzungs-Liste ABKLEX (Informatik, Telekommunikation) W. Alex 1. Juli 2021 Karlsruhe Copyright W. Alex, Karlsruhe, 1994 – 2018. Die Liste darf unentgeltlich benutzt und weitergegeben werden. The list may be used or copied free of any charge. Original Point of Distribution: http://www.abklex.de/abklex/ An authorized Czechian version is published on: http://www.sochorek.cz/archiv/slovniky/abklex.htm Author’s Email address: [email protected] 2 Kapitel 1 Abkürzungen Gehen wir von 30 Zeichen aus, aus denen Abkürzungen gebildet werden, und nehmen wir eine größte Länge von 5 Zeichen an, so lassen sich 25.137.930 verschiedene Abkür- zungen bilden (Kombinationen mit Wiederholung und Berücksichtigung der Reihenfol- ge). Es folgt eine Auswahl von rund 16000 Abkürzungen aus den Bereichen Informatik und Telekommunikation. Die Abkürzungen werden hier durchgehend groß geschrieben, Akzente, Bindestriche und dergleichen wurden weggelassen. Einige Abkürzungen sind geschützte Namen; diese sind nicht gekennzeichnet. Die Liste beschreibt nur den Ge- brauch, sie legt nicht eine Definition fest. 100GE 100 GBit/s Ethernet 16CIF 16 times Common Intermediate Format (Picture Format) 16QAM 16-state Quadrature Amplitude Modulation 1GFC 1 Gigabaud Fiber Channel (2, 4, 8, 10, 20GFC) 1GL 1st Generation Language (Maschinencode) 1TBS One True Brace Style (C) 1TR6 (ISDN-Protokoll D-Kanal, national) 247 24/7: 24 hours per day, 7 days per week 2D 2-dimensional 2FA Zwei-Faktor-Authentifizierung 2GL 2nd Generation Language (Assembler) 2L8 Too Late (Slang) 2MS Strukturierte -

Protection of System Layer Affordances
Master Thesis in Software Engineering Thesis no: MSE-2002:14 June 2002 Protection of System Layer Affordances Per Mellstrand Department of Software Engineering and Computer Science Blekinge Institute of Technology Box 520 SE - 372 25 Ronneby Sweden This thesis is submitted to the Department of Software Engineering and Computer Science at Blekinge Institute of Technology in partial fulfilment of the requirements for the degree of Master of Science in Software Engineering. The thesis is equivalent to 20 weeks of full time studies. Contact Information: Author: Per Mellstrand E-mail: [email protected] University advisor: Rune Gustavsson Department of Software Engineering and Computer Science Department of Internet : www.ipd.bth.se Software Engineering and Computer Science Phone : +46 457 38 50 00 Blekinge Institute of Technology Fax : + 46 457 271 25 SE - 372 25 Ronneby Sweden Abstract With more and more open systems connected to the Internet security is perhaps the most important attribute of modern software systems. A large problem when creating secure systems is developers misunderstanding or incorrectly assuming how objects behave. In this paper I describe how such incorrect assumption can result in large problems in software systems, under which conditions these problems typically appear and a method that can be used to reduce the number of software defects caused by incorrect assumption. Keywords: Secure Systems, Assumption of Properties, Security Engineering Protection of System Layer Affordances 4 Table of Contents Introduction .......................................................................... -
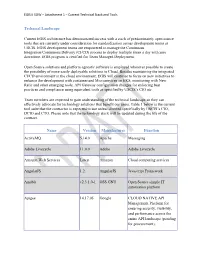
Technical Landscape Current EGIS Architecture Has Demonstrated
EGIS II SOW – Attachment 1 – Current Technical Stack and Tools Technical Landscape Current EGIS architecture has demonstrated success with a stack of predominately open source tools that are currently under consideration for standardization across development teams at USCIS. EGIS development teams are empowered to manage the Continuous Integration/Continuous Delivery (CI/CD) process to deploy multiple times a day with zero downtime. EGIS program is certified for Team Managed Deployment. Open Source solutions and platform agnostic software is employed wherever possible to create the possibility of more easily deployable solutions in Cloud. Besides maintaining the integrated CI/CD environment in the cloud environment, EGIS will continue to focus on new initiatives to enhance the development with containerized Microservices on EKS, monitoring with New Relic and other emerging tools, API Gateway configuration changes for enforcing best practices and compliance using equivalent tools as specified by USCIS’s CIO etc. Team members are expected to gain understanding of the technical landscape so they can effectively advocate for technology solutions that benefit our users. Table 1 below is the current tool suite that the contractor is expected to use unless directed specifically by USCIS’s CIO, DCIO and CTO. Please note that the technology stack will be updated during the life of the contract. Name Version Manufacturer Function ActiveMQ 5.14.0 Apache Messaging Adobe Livecycle 11.0.0 Adobe Adobe Livecycle Amazon Web Services Latest Amazon Cloud computing services AngularJS 1.2. AngularJS Javascript Framework Ansible v2.3.1.0-1 OSS GNU Open Source simple IT automation platform Apigee 14.17.05 Google CLOUD NATIVE API Management Platform for ensuring security, visibility, and performance across the entire API landscape (pending for procurement). -

Apache Internals and Debugging Ryan Matteson [email protected] Presentation Overview
Apache internals and debugging Ryan Matteson [email protected] http://prefetch.net Presentation overview • An introduction to the Apache source code layout • An introduction to key concepts such as modules, buckets, brigades, hooks, filters, and MPMs • An introduction to several tools that can be used to perform post-mortem analysis • An introduction to several tools that can be used to debug transient server problems Apache layout What is Apache? • Flexible and extensible opensource web server • Supports HTTP versions 0.9, 1.0 and 1.1 • Ships with a variety of modules that can be used to secure communications and transform content • Supports virtual hosting • Supports static and dynamic content delivery • The list goes on and on … How big is Apache? • 150k+ lines of C code*: $ find . -name \*.c -exec egrep -v '(^[ ]+\*|^$|\/\*|\*\/) {} \; | wc -l 155884 • 480+ source code files: $ find . -name \*.c -ls | wc -l 488 • 240+ header files: $ find . -name \*.h -ls | wc -l 247 * Several source code files are used for experimentation, testing, and debugging purposes How is Apache organized? • Apache is broken up into several pieces – The server core – The Apache portable runtime – The Apache portable runtime utilities – Support infrastructure – Numerous modules How is the Apache source code organized? • The server core source code resides in $SRCROOT/server • The server core header files reside in $SRCROOT/include • The portable runtime resides in $SRCROOT/srclib/apr • The portable runtime utilities reside in $SRCROOT/srclib/apr-util • Support -
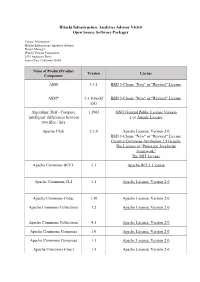
Hitachi Infrastructure Analytics Advisor V4.0.0 Open Source Software Packages
Hitachi Infrastructure Analytics Advisor V4.0.0 Open Source Software Packages Contact Information: Hitachi Infrastructure Analytics Advisor Project Manager Hitachi Vantara Corporation 2535 Augustine Drive Santa Clara, California 95054 Name of Product/Product Version License Component ASM 3.3.1 BSD 3-Clause "New" or "Revised" License ASM* 3.3.1(modif BSD 3-Clause "New" or "Revised" License ied) Algorithm::Diff - Compute 1.1903 GNU General Public License Version `intelligent' differences between 1 or Artistic License two files / lists Apache Click 2.3.0 Apache License, Version 2.0 BSD 3-Clause "New" or "Revised" License Creative Commons Attribution 2.5 Generic The License of "Prototype JavaScript framework" The MIT License Apache Commons BCEL 5.1 Apache BCEL License Apache Commons CLI 1.1 Apache License, Version 2.0 Apache Commons Codec 1.10 Apache License, Version 2.0 Apache Commons Collections 3.2 Apache License, Version 2.0 Apache Commons Collections 4.1 Apache License, Version 2.0 Apache Commons Compress 1.0 Apache License, Version 2.0 Apache Commons Compress 1.1 Apache License, Version 2.0 Apache Commons Email 1.4 Apache License, Version 2.0 Name of Product/Product Version License Component Apache HTTP Server 2.4.28 Apache License, Version 2.0 GNU General Public License, Version 3 with Autoconf exception The License by "Bell Communications Research, Inc. (Bellcore)" The License by "Carnegie Mellon University" The License by "Ian F. Darwin" The License by "Massachusetts Institute of Technology" The License by "RSA Data Security, Inc." The License of "RSA Data Security, Inc. MD4 Message-Digest Algorithm" The License of "RSA Data Security, Inc. -

Apache Portable Runtime Apache License, Version 2.0 (January 2004)
NETBRAIN TECHNOLOGIES, INC. OPEN SOURCE SOFTWARE LICENSES (NETBRAIN SOFTWARE VERSION 6.1) Apache Portable Runtime Apache License, Version 2.0 (January 2004) [License, Start] TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION 1. Definitions. "License" shall mean the terms and conditions for use, reproduction, and distribution as defined by Sections 1 through 9 of this document. "Licensor" shall mean the copyright owner or entity authorized by the copyright owner that is granting the License. "Legal Entity" shall mean the union of the acting entity and all other entities that control, are controlled by, or are under common control with that entity. For the purposes of this definition, "control" means (i) the power, direct or indirect, to cause the direction or management of such entity, whether by contract or otherwise, or (ii) ownership of fifty percent (50%) or more of the outstanding shares, or (iii) beneficial ownership of such entity. "You" (or "Your") shall mean an individual or Legal Entity exercising permissions granted by this License. "Source" form shall mean the preferred form for making modifications, including but not limited to software source code, documentation source, and configuration files. "Object" form shall mean any form resulting from mechanical transformation or translation of a Source form, including but not limited to compiled object code, generated documentation, and conversions to other media types. "Work" shall mean the work of authorship, whether in Source or Object form, made available under the License, as indicated by a copyright notice that is included in or attached to the work (an example is provided in the Appendix below). -
The Glassfish Community Delivering a Java EE Application Server
The GlassFish Community: An Overview The GlassFish Community Delivering a Java EE Application Server Eduardo Pelegri-Llopart Yutaka Yoshida Alexis Moussine-Pouchkine Sun Microsystems, Inc. http://blogs.sun.com/theaquarium Last Updated September 2007 The GlassFish Community 1 At JavaOne 2005, Sun announced Project GlassFish, an initiative to open source its Application Server and the Java EE Reference Implementation (see inset: Project GlassFish). This was the first step of open sourcing all the Java platform, but it also had other effects. Project GlassFish Project GlassFish accelerated the adoption of Java EE 5, added a new enterprise-quality App Server Sun launched Project GlassFish to the options available to the Open Source in June 2005, during JavaOne, to community, and has lead to a Open Source the Reference transformation of how Sun's AppServer is Implementation for Java EE 5 and developed, tested, made available, and Sun's Application Server. evolved, in the process creating a much The first release followed less better product. than a year after, at JavaOne 2006 A year and a half after the initial launch, the (May 2006). GlassFish community has already delivered The second release was released its first final release and is on its way to its in September 2007. second. In this article we will provide an overview of all the aspects of the GlassFish The focus is now on GlassFish v3, Community and the GlassFish AppServer. the modular and lightweight application server (see HK2). What is GlassFish GlassFish is a Community and an Application Server. The community's main deliverables are a Java EE 5 compatible Application Server, the GlassFish AppServer, and the Reference Implementation for the Java Persistence API, TopLink Essentials. -

Apache Configuration Due Date: Nov 8 Points: 25 Points
Apache Configuration Due Date: Nov 8 Points: 25 Points Objective: To gain experience with configuring the Apache web server Equipment Needed The Ubuntu system that you have already downloaded has the apache daemon along with html files that are needed in this experience. You will also need an Ethernet connection, i.e. a cat 5 cable. Background The Apache HTTP Server, commonly referred to as Apache is a web server notable for playing a key role in the initial growth of the World Wide Web. In 2009 it became the first web server to surpass the 100 million web site milestone. The majority of web servers using Apache run the Linux operating system. Apache is developed and maintained by an open community of developers under the auspices of the Apache Software Foundation. The application is available for a wide variety of operating systems, including Unix, GNU, FreeBSD, Linux, Solaris, Novell NetWare, Mac OS X, Microsoft Windows, OS/2, TPF, and eComStation. Released under the Apache License, Apache is characterized as open source software. Since April 1996 Apache has been the most popular HTTP server on the World Wide Web. As of September 2009, Apache served over 54.48% of all websites and over 66% of the million busiest. The first version of the Apache web server was created by Robert McCool, who was heavily involved with the National Center for Supercomputing Applications web server, known simply as NCSA HTTPd. When McCool left NCSA in mid-1994, the development of httpd stalled, leaving a variety of patches for improvements circulating through e-mails. -

Apache Web Server: Applying Lessons from Physical Architecture to Enable Systems to Thrive
Apache Web Server: Applying Lessons from Physical Architecture to Enable Systems to Thrive William T. Schiano, Bentley University, USA David J. Yates, Bentley University, USA Leslie J. Waguespack, Bentley University, USA Abstract: The Apache web server is one of the most successful software products in history. The architecture of Apache has been a primary driver of this success. To understand what has made Apache thrive, and to learn from its success, we turn to lessons gleaned from physical architecture. Christopher Alexander distilled architectural quality into fifteen properties, the combination of which determines whether the architecture will exhibit wholeness, or life. Waguespack has applied Alexander’s theory to articulate fifteen corresponding properties of modeling and information systems that determine whether an information system will have sufficient functionality and strength to thrive. We first explain Apache’s success over time through the application of these properties. We then explore how organizations can emulate this success in their own information systems by managing the portfolio of properties. Linking information systems properties to desirable business outcomes to create a synergy between design goals and business requirements is critical to success. For a system to serve the needs of a business, its design and implementation should not only accommodate, but facilitate change. We argue that facilitating change amplifies, not obviates, the need for great architecture. Applying the lessons from physical architecture to enable systems to thrive thus improves both system agility and business agility. Keywords: Alignment, Architecture, Design, Functionality, Strength, Business Outcomes, Information Systems, Software Engineering, Thriving Systems Introduction he Apache web server is one of the most successful software products in history.