Virtex Ultrascale+ HBM FPGA: a Revolutionary Increase in Memory Performance
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

MEGHARAJ-THESIS-2017.Pdf (1.176Mb)
INTGRATING PROCESSING IN-MEMORY (PIM) TECHNOLOGY INTO GENERAL PURPOSE GRAPHICS PROCESSING UNITS (GPGPU) FOR ENERGY EFFICIENT COMPUTING A Thesis Presented to the Faculty of the Department of Electrical Engineering University of Houston In Partial Fulfillment of the Requirements for the Degree Master of Science in Electrical Engineering by Paraag Ashok Kumar Megharaj August 2017 INTGRATING PROCESSING IN-MEMORY (PIM) TECHNOLOGY INTO GENERAL PURPOSE GRAPHICS PROCESSING UNITS (GPGPU) FOR ENERGY EFFICIENT COMPUTING ________________________________________________ Paraag Ashok Kumar Megharaj Approved: ______________________________ Chair of the Committee Dr. Xin Fu, Assistant Professor, Electrical and Computer Engineering Committee Members: ____________________________ Dr. Jinghong Chen, Associate Professor, Electrical and Computer Engineering _____________________________ Dr. Xuqing Wu, Assistant Professor, Information and Logistics Technology ____________________________ ______________________________ Dr. Suresh K. Khator, Associate Dean, Dr. Badri Roysam, Professor and Cullen College of Engineering Chair of Dept. in Electrical and Computer Engineering Acknowledgements I would like to thank my advisor, Dr. Xin Fu, for providing me an opportunity to study under her guidance and encouragement through my graduate study at University of Houston. I would like to thank Dr. Jinghong Chen and Dr. Xuqing Wu for serving on my thesis committee. Besides, I want to thank my friend, Chenhao Xie, for helping me out and discussing in detail all the problems -
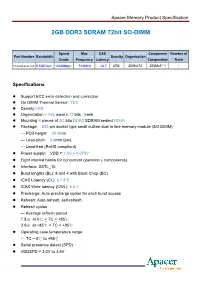
2GB DDR3 SDRAM 72Bit SO-DIMM
Apacer Memory Product Specification 2GB DDR3 SDRAM 72bit SO-DIMM Speed Max CAS Component Number of Part Number Bandwidth Density Organization Grade Frequency Latency Composition Rank 0C 78.A2GCB.AF10C 8.5GB/sec 1066Mbps 533MHz CL7 2GB 256Mx72 256Mx8 * 9 1 Specifications z Support ECC error detection and correction z On DIMM Thermal Sensor: YES z Density:2GB z Organization – 256 word x 72 bits, 1rank z Mounting 9 pieces of 2G bits DDR3 SDRAM sealed FBGA z Package: 204-pin socket type small outline dual in line memory module (SO-DIMM) --- PCB height: 30.0mm --- Lead pitch: 0.6mm (pin) --- Lead-free (RoHS compliant) z Power supply: VDD = 1.5V + 0.075V z Eight internal banks for concurrent operation ( components) z Interface: SSTL_15 z Burst lengths (BL): 8 and 4 with Burst Chop (BC) z /CAS Latency (CL): 6,7,8,9 z /CAS Write latency (CWL): 5,6,7 z Precharge: Auto precharge option for each burst access z Refresh: Auto-refresh, self-refresh z Refresh cycles --- Average refresh period 7.8㎲ at 0℃ < TC < +85℃ 3.9㎲ at +85℃ < TC < +95℃ z Operating case temperature range --- TC = 0℃ to +95℃ z Serial presence detect (SPD) z VDDSPD = 3.0V to 3.6V Apacer Memory Product Specification Features z Double-data-rate architecture; two data transfers per clock cycle. z The high-speed data transfer is realized by the 8 bits prefetch pipelined architecture. z Bi-directional differential data strobe (DQS and /DQS) is transmitted/received with data for capturing data at the receiver. z DQS is edge-aligned with data for READs; center aligned with data for WRITEs. -

Different Types of RAM RAM RAM Stands for Random Access Memory. It Is Place Where Computer Stores Its Operating System. Applicat
Different types of RAM RAM RAM stands for Random Access Memory. It is place where computer stores its Operating System. Application Program and current data. when you refer to computer memory they mostly it mean RAM. The two main forms of modern RAM are Static RAM (SRAM) and Dynamic RAM (DRAM). DRAM memories (Dynamic Random Access Module), which are inexpensive . They are used essentially for the computer's main memory SRAM memories(Static Random Access Module), which are fast and costly. SRAM memories are used in particular for the processer's cache memory. Early memories existed in the form of chips called DIP (Dual Inline Package). Nowaday's memories generally exist in the form of modules, which are cards that can be plugged into connectors for this purpose. They are generally three types of RAM module they are 1. DIP 2. SIMM 3. DIMM 4. SDRAM 1. DIP(Dual In Line Package) Older computer systems used DIP memory directely, either soldering it to the motherboard or placing it in sockets that had been soldered to the motherboard. Most memory chips are packaged into small plastic or ceramic packages called dual inline packages or DIPs . A DIP is a rectangular package with rows of pins running along its two longer edges. These are the small black boxes you see on SIMMs, DIMMs or other larger packaging styles. However , this arrangment caused many problems. Chips inserted into sockets suffered reliability problems as the chips would (over time) tend to work their way out of the sockets. 2. SIMM A SIMM, or single in-line memory module, is a type of memory module containing random access memory used in computers from the early 1980s to the late 1990s . -

Product Guide SAMSUNG ELECTRONICS RESERVES the RIGHT to CHANGE PRODUCTS, INFORMATION and SPECIFICATIONS WITHOUT NOTICE
May. 2018 DDR4 SDRAM Memory Product Guide SAMSUNG ELECTRONICS RESERVES THE RIGHT TO CHANGE PRODUCTS, INFORMATION AND SPECIFICATIONS WITHOUT NOTICE. Products and specifications discussed herein are for reference purposes only. All information discussed herein is provided on an "AS IS" basis, without warranties of any kind. This document and all information discussed herein remain the sole and exclusive property of Samsung Electronics. No license of any patent, copyright, mask work, trademark or any other intellectual property right is granted by one party to the other party under this document, by implication, estoppel or other- wise. Samsung products are not intended for use in life support, critical care, medical, safety equipment, or similar applications where product failure could result in loss of life or personal or physical harm, or any military or defense application, or any governmental procurement to which special terms or provisions may apply. For updates or additional information about Samsung products, contact your nearest Samsung office. All brand names, trademarks and registered trademarks belong to their respective owners. © 2018 Samsung Electronics Co., Ltd. All rights reserved. - 1 - May. 2018 Product Guide DDR4 SDRAM Memory 1. DDR4 SDRAM MEMORY ORDERING INFORMATION 1 2 3 4 5 6 7 8 9 10 11 K 4 A X X X X X X X - X X X X SAMSUNG Memory Speed DRAM Temp & Power DRAM Type Package Type Density Revision Bit Organization Interface (VDD, VDDQ) # of Internal Banks 1. SAMSUNG Memory : K 8. Revision M: 1st Gen. A: 2nd Gen. 2. DRAM : 4 B: 3rd Gen. C: 4th Gen. D: 5th Gen. -

Peering Over the Memory Wall: Design Space and Performance
Peering Over the Memory Wall: Design Space and Performance Analysis of the Hybrid Memory Cube UniversityDesign of Maryland Space andSystems Performance & Computer Architecture Analysis Group of Technical the Hybrid Report UMD-SCA-2012-10-01 Memory Cube Paul Rosenfeld*, Elliott Cooper-Balis*, Todd Farrell*, Dave Resnick°, and Bruce Jacob† *Micron, Inc. °Sandia National Labs †University of Maryland Abstract the hybrid memory cube which has the potential to address The Hybrid Memory Cube is an emerging main memory all three of these problems at the same time. The HMC tech- technology that leverages advances in 3D fabrication tech- nology leverages advances in fabrication technology to create niques to create a CMOS logic layer with DRAM dies stacked a 3D stack that contains a CMOS logic layer with several on top. The logic layer contains several DRAM memory con- DRAM dies stacked on top. The logic layer contains several trollers that receive requests from high speed serial links from memory controllers, a high speed serial link interface, and an the host processor. Each memory controller is connected to interconnect switch that connects the high speed links to the several memory banks in several DRAM dies with a vertical memory controllers. By stacking memory elements on top of through-silicon via (TSV). Since the TSVs form a dense in- controllers, the HMC can deliver data from memory banks to terconnect with short path lengths, the data bus between the controllers with much higher bandwidth and lower energy per controller and banks can be operated at higher throughput and bit than a traditional memory system. -

Dual-DIMM DDR2 and DDR3 SDRAM Board Design Guidelines, External
5. Dual-DIMM DDR2 and DDR3 SDRAM Board Design Guidelines June 2012 EMI_DG_005-4.1 EMI_DG_005-4.1 This chapter describes guidelines for implementing dual unbuffered DIMM (UDIMM) DDR2 and DDR3 SDRAM interfaces. This chapter discusses the impact on signal integrity of the data signal with the following conditions in a dual-DIMM configuration: ■ Populating just one slot versus populating both slots ■ Populating slot 1 versus slot 2 when only one DIMM is used ■ On-die termination (ODT) setting of 75 Ω versus an ODT setting of 150 Ω f For detailed information about a single-DIMM DDR2 SDRAM interface, refer to the DDR2 and DDR3 SDRAM Board Design Guidelines chapter. DDR2 SDRAM This section describes guidelines for implementing a dual slot unbuffered DDR2 SDRAM interface, operating at up to 400-MHz and 800-Mbps data rates. Figure 5–1 shows a typical DQS, DQ, and DM signal topology for a dual-DIMM interface configuration using the ODT feature of the DDR2 SDRAM components. Figure 5–1. Dual-DIMM DDR2 SDRAM Interface Configuration (1) VTT Ω RT = 54 DDR2 SDRAM DIMMs (Receiver) Board Trace FPGA Slot 1 Slot 2 (Driver) Board Trace Board Trace Note to Figure 5–1: (1) The parallel termination resistor RT = 54 Ω to VTT at the FPGA end of the line is optional for devices that support dynamic on-chip termination (OCT). © 2012 Altera Corporation. All rights reserved. ALTERA, ARRIA, CYCLONE, HARDCOPY, MAX, MEGACORE, NIOS, QUARTUS and STRATIX words and logos are trademarks of Altera Corporation and registered in the U.S. Patent and Trademark Office and in other countries. -

First Draft of Hybrid Memory Cube Interface Specification Released
First Draft of Hybrid Memory Cube Interface Specification Released August 14, 2012 BOISE, Idaho and SAN JOSE, Calif., Aug. 14, 2012 (GLOBE NEWSWIRE) -- The Hybrid Memory Cube Consortium (HMCC), led by Micron Technology, Inc. (Nasdaq:MU), and Samsung Electronics Co., Ltd., today announced that its developer members have released the initial draft of the Hybrid Memory Cube (HMC) interface specification to a rapidly growing number of industry adopters. Issuance of the draft puts the consortium on schedule to release the final version by the end of this year. The industry specification will enable adopters to fully develop designs that leverage HMC's innovative technology, which has the potential to boost performance in a wide range of applications. The initial specification draft consists of an interface protocol and short-reach interconnection across physical layers (PHYs) targeted for high-performance networking, industrial, and test and measurement applications. The next step in development of the specification calls for the consortium's adopters and developers to refine the specification and define an ultra short-reach PHY for applications requiring tightly coupled or close proximity memory support for FPGAs, ASICs and ASSPs. "With the draft standard now available for final input and modification by adopter members, we're excited to move one step closer to enabling the Hybrid Memory Cube and the latest generation of 28-nanometer (nm) FPGAs to be easily integrated into high-performance systems," said Rob Sturgill, architect, at Altera. "The steady progress among the consortium's member companies for defining a new standard bodes well for businesses who would like to achieve unprecedented system performance and bandwidth by incorporating the Hybrid Memory Cube into their product strategies." The interface specification reflects a focused collaboration among several of the world's leading technology providers. -

HAAG$) for High Performance 3D DRAM Architectures
History-Assisted Adaptive-Granularity Caches (HAAG$) for High Performance 3D DRAM Architectures Ke Chen† Sheng Li‡ Jung Ho Ahn§ Naveen Muralimanohar¶ Jishen Zhao# Cong Xu[ Seongil O§ Yuan Xie\ Jay B. Brockman> Norman P. Jouppi? †Oracle Corporation∗ ‡Intel Labs∗ §Seoul National University #University of California at Santa Cruz∗ ¶Hewlett-Packard Labs [Pennsylvania State University \University of California at Santa Barbara >University of Notre Dame ?Google∗ †[email protected] ‡[email protected] §{gajh, swdfish}@snu.ac.kr ¶[email protected] #[email protected] [[email protected] \[email protected] >[email protected] [email protected] TSVs (Wide Data Path) ABSTRACT Silicon Interposer 3D-stacked DRAM has the potential to provide high performance DRAM and large capacity memory for future high performance comput- Logic & CMP ing systems and datacenters, and the integration of a dedicated HAAG$ logic die opens up opportunities for architectural enhancements such as DRAM row-buffer caches. However, high performance Figure 1: The target system design for integrating the HAAG$: a hyb- and cost-effective row-buffer cache designs remain challenging for rid 3D DRAM stack and a chip multiprocessor are co-located on a silicon 3D memory systems. In this paper, we propose History-Assisted interposer. Adaptive-Granularity Cache (HAAG$) that employs an adaptive caching scheme to support full associativity at various granularities, and an intelligent history-assisted predictor to support a large num- 1. INTRODUCTION ber of banks in 3D memory systems. By increasing the row-buffer Future high performance computing demands high performance cache hit rate and avoiding unnecessary data caching, HAAG$ sig- and large capacity memory subsystems with low cost. -

Intel PSG (Altera) Commitment to SKA Community
Intel PSG (Altera) Enabling the SKA Community Lance Brown Sr. Strategic & Technical Marketing Mgr. [email protected], 719-291-7280 Agenda Intel Programmable Solutions Group (Altera) PSG’s COTS Strategy for PowerMX High Bandwidth Memory (HBM2), Lower Power Case Study – CNN – FPGA vs GPU – Power Density Stratix 10 – Current Status, HLS, OpenCL NRAO Efforts 2 Altera == Intel Programmable Solutions Group 3 Intel Completes Altera Acquisition December 28, 2015 STRATEGIC RATIONALE POST-MERGER STRUCTURE • Accelerated FPGA innovation • Altera operates as a new Intel from combined R&D scale business unit called Programmable • Improved FPGA power and Solutions Group (PSG) with intact performance via early access and and dedicated sales and support greater optimization of process • Dan McNamara appointed node advancements Corporate VP and General Manager • New, breakthrough Data Center leading PSG, reports directly to Intel and IoT products harnessing CEO combined FPGA + CPU expertise 4 Intel Programmable Solutions Group (PSG) (Altera) Altera GM Promoted to Intel VP to run PSG Intel is adding resources to PSG On 14nm, 10nm & 7nm roadmap with larger Intel Enhancing High Performance Computing teams for OpenCL, OpenMP and Virtualization Access to Intel Labs Research Projects – Huge Will Continue ARM based System-on-Chip Arria and Stratix Product Lines 5 Proposed PowerMX COTS Model NRC + CEI + Intel PSG (Altera) Moving PowerMX to Broader Industries Proposed PowerMX COTS Business Model Approaching Top COTS Providers PowerMX CEI COTS Products A10 PowerMX -

DDR3 SODIMM Product Datasheet
DDR3 SODIMM Product Datasheet 廣 穎 電 通 股 份 有 限 公 司 Silicon Power Computer & Communications Inc. TEL: 886-2 8797-8833 FAX: 886-2 8751-6595 台北市114內湖區洲子街106號7樓 7F, No.106, ZHO-Z ST. NEIHU DIST, 114, TAIPEI, TAIWAN, R.O.C This document is a general product description and is subject to change without notice DDR3 SODIMM Product Datasheet Index Index...................................................................................................................................................................... 2 Revision History ................................................................................................................................................ 3 Description .......................................................................................................................................................... 4 Features ............................................................................................................................................................... 5 Pin Assignments................................................................................................................................................ 7 Pin Description................................................................................................................................................... 8 Environmental Requirements......................................................................................................................... 9 Absolute Maximum DC Ratings.................................................................................................................... -

An Energy-Efficient Technique to Reduce Refresh Overhead in Hybrid Memory Cube Architectures
2016 29th International Conference on VLSI Design and 2016 15th International Conference on Embedded Systems Massed Refresh: An Energy-Efficient Technique to Reduce Refresh Overhead in Hybrid Memory Cube Architectures Ishan G Thakkar, Sudeep Pasricha Department of Electrical and Computer Engineering Colorado State University, Fort Collins, CO, U.S.A. {ishan.thakkar, sudeep}@colostate.edu Abstract— This paper presents a novel, energy-efficient In this paper, we propose massed refresh, a novel energy-ef- DRAM refresh technique called massed refresh that simul- ficient DRAM refresh technique that intelligently leverages taneously leverages bank-level and subarray-level concur- bank-level as well as subarray-level parallelism to reduce re- rency to reduce the overhead of distributed refresh opera- fresh cycle time overhead in the 3D-stacked Hybrid Memory tions in the Hybrid Memory Cube (HMC). In massed re- Cube (HMC) DRAM architecture. We have observed that due fresh, a bundle of DRAM rows in a refresh operation is com- to the increased power density and resulting high operating tem- posed of two subgroups mapped to two different banks, with peratures, the effects of periodic refresh commands on refresh the rows of each subgroup mapped to different subarrays cycle time and energy-efficiency of 3D-stacked DRAMs, such within the corresponding bank. Both subgroups of DRAM as the emerging HMC [1], are significantly exacerbated. There- rows are refreshed concurrently during a refresh command, fore, we select the HMC for our study, even though the concept which greatly reduces the refresh cycle time and improves of massed refresh can be applied to any other 2D or 3D-stacked bandwidth and energy efficiency of the HMC. -

DDR4 2400 R-DIMM / VLP R-DIMM / ECC U-DIMM / ECC SO-DIMM Features
DDR4 2400 R-DIMM / VLP R-DIMM / ECC U-DIMM / ECC SO-DIMM Available in densities ranging from 4GB to 16GB per module and clocked up to 2400MHz for a maximum 17GB/s bandwidth, ADATA DDR4 server memory modules are all certified Intel® Haswell-EP compatible to ensure superior performance. Products ship in four convenient form factors to accommodate diverse needs and applications: R-DIMM and ECC U-DIMM for servers and enterprises, VLP R-DIMM for high-end blade servers, and ECC SO-SIMM for micro servers. Running at a mere 1.2V, ADATA DDR4 memory modules use 20% less energy than conventional lower-performance DDR3 modules, in effect delivering more computational power for less energy draw. ADATA DDR4 server memory modules are an excellent choice for users looking to balance performance, environmental responsibility, and cost effectiveness. Features ECC U-DIMM High speed up to 2400MHz Transfer bandwidths up to 17GB/s Energy efficient: save up to 20% compared to DDR3 8-layer PCB provides improved signal transfer R-DIMM and system stability PCB gold plating: 30u and up Intel Haswell-EP compatible for extreme performance VLP R-DIMM ECC SO-DIMM Specifications Type ECC-DIMM R-DIMM VLP R-DIMM ECC SO-DIMM Standard Standard Very low profile Standard Form factor (1.18" height) (1.18" height) (0.7" height) (1.18" height) Enterprise servers / Enterprise servers / Suitable for Blade servers Micro servers data centers data centers Interface 288-pin 288-pin 288-pin 260-pin Capacity 4GB / 8GB / 16GB 4GB / 8GB / 16GB 4GB / 8GB /16GB 4GB / 8GB / 16GB Rank