Entropy Encoding Based Memory Compression for Gpus
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-

Arithmetic Coding
Arithmetic Coding Arithmetic coding is the most efficient method to code symbols according to the probability of their occurrence. The average code length corresponds exactly to the possible minimum given by information theory. Deviations which are caused by the bit-resolution of binary code trees do not exist. In contrast to a binary Huffman code tree the arithmetic coding offers a clearly better compression rate. Its implementation is more complex on the other hand. In arithmetic coding, a message is encoded as a real number in an interval from one to zero. Arithmetic coding typically has a better compression ratio than Huffman coding, as it produces a single symbol rather than several separate codewords. Arithmetic coding differs from other forms of entropy encoding such as Huffman coding in that rather than separating the input into component symbols and replacing each with a code, arithmetic coding encodes the entire message into a single number, a fraction n where (0.0 ≤ n < 1.0) Arithmetic coding is a lossless coding technique. There are a few disadvantages of arithmetic coding. One is that the whole codeword must be received to start decoding the symbols, and if there is a corrupt bit in the codeword, the entire message could become corrupt. Another is that there is a limit to the precision of the number which can be encoded, thus limiting the number of symbols to encode within a codeword. There also exist many patents upon arithmetic coding, so the use of some of the algorithms also call upon royalty fees. Arithmetic coding is part of the JPEG data format. -

Information Theory Revision (Source)
ELEC3203 Digital Coding and Transmission – Overview & Information Theory S Chen Information Theory Revision (Source) {S(k)} {b i } • Digital source is defined by digital source source coding 1. Symbol set: S = {mi, 1 ≤ i ≤ q} symbols/s bits/s 2. Probability of occurring of mi: pi, 1 ≤ i ≤ q 3. Symbol rate: Rs [symbols/s] 4. Interdependency of {S(k)} • Information content of alphabet mi: I(mi) = − log2(pi) [bits] • Entropy: quantifies average information conveyed per symbol q – Memoryless sources: H = − pi · log2(pi) [bits/symbol] i=1 – 1st-order memory (1st-order Markov)P sources with transition probabilities pij q q q H = piHi = − pi pij · log2(pij) [bits/symbol] Xi=1 Xi=1 Xj=1 • Information rate: tells you how many bits/s information the source really needs to send out – Information rate R = Rs · H [bits/s] • Efficient source coding: get rate Rb as close as possible to information rate R – Memoryless source: apply entropy coding, such as Shannon-Fano and Huffman, and RLC if source is binary with most zeros – Generic sources with memory: remove redundancy first, then apply entropy coding to “residauls” 86 ELEC3203 Digital Coding and Transmission – Overview & Information Theory S Chen Practical Source Coding • Practical source coding is guided by information theory, with practical constraints, such as performance and processing complexity/delay trade off • When you come to practical source coding part, you can smile – as you should know everything • As we will learn, data rate is directly linked to required bandwidth, source coding is to encode source with a data rate as small as possible, i.e. -

Probability Interval Partitioning Entropy Codes Detlev Marpe, Senior Member, IEEE, Heiko Schwarz, and Thomas Wiegand, Senior Member, IEEE
SUBMITTED TO IEEE TRANSACTIONS ON INFORMATION THEORY 1 Probability Interval Partitioning Entropy Codes Detlev Marpe, Senior Member, IEEE, Heiko Schwarz, and Thomas Wiegand, Senior Member, IEEE Abstract—A novel approach to entropy coding is described that entropy coding while the assignment of codewords to symbols provides the coding efficiency and simple probability modeling is the actual entropy coding. For decades, two methods have capability of arithmetic coding at the complexity level of Huffman dominated practical entropy coding: Huffman coding that has coding. The key element of the proposed approach is given by a partitioning of the unit interval into a small set of been invented in 1952 [8] and arithmetic coding that goes back disjoint probability intervals for pipelining the coding process to initial ideas attributed to Shannon [7] and Elias [9] and along the probability estimates of binary random variables. for which first practical schemes have been published around According to this partitioning, an input sequence of discrete 1976 [10][11]. Both entropy coding methods are capable of source symbols with arbitrary alphabet sizes is mapped to a approximating the entropy limit (in a certain sense) [12]. sequence of binary symbols and each of the binary symbols is assigned to one particular probability interval. With each of the For a fixed probability mass function, Huffman codes are intervals being represented by a fixed probability, the probability relatively easy to construct. The most attractive property of interval partitioning entropy (PIPE) coding process is based on Huffman codes is that their implementation can be efficiently the design and application of simple variable-to-variable length realized by the use of variable-length code (VLC) tables. -

Fast Algorithm for PQ Data Compression Using Integer DTCWT and Entropy Encoding
International Journal of Applied Engineering Research ISSN 0973-4562 Volume 12, Number 22 (2017) pp. 12219-12227 © Research India Publications. http://www.ripublication.com Fast Algorithm for PQ Data Compression using Integer DTCWT and Entropy Encoding Prathibha Ekanthaiah 1 Associate Professor, Department of Electrical and Electronics Engineering, Sri Krishna Institute of Technology, No 29, Chimney hills Chikkabanavara post, Bangalore-560090, Karnataka, India. Orcid Id: 0000-0003-3031-7263 Dr.A.Manjunath 2 Principal, Sri Krishna Institute of Technology, No 29, Chimney hills Chikkabanavara post, Bangalore-560090, Karnataka, India. Orcid Id: 0000-0003-0794-8542 Dr. Cyril Prasanna Raj 3 Dean & Research Head, Department of Electronics and communication Engineering, MS Engineering college , Navarathna Agrahara, Sadahalli P.O., Off Bengaluru International Airport,Bengaluru - 562 110, Karnataka, India. Orcid Id: 0000-0002-9143-7755 Abstract metering infrastructures (smart metering), integration of distributed power generation, renewable energy resources and Smart meters are an integral part of smart grid which in storage units as well as high power quality and reliability [1]. addition to energy management also performs data By using smart metering Infrastructure sustains the management. Power Quality (PQ) data from smart meters bidirectional data transfer and also decrease in the need to be compressed for both storage and transmission environmental effects. With this resilience and reliability of process either through wired or wireless medium. In this power utility network can be improved effectively. Work paper, PQ data compression is carried out by encoding highlights the need of development and technology significant features captured from Dual Tree Complex encroachment in smart grid communications [2]. -

Entropy Encoding in Wavelet Image Compression
Entropy Encoding in Wavelet Image Compression Myung-Sin Song1 Department of Mathematics and Statistics, Southern Illinois University Edwardsville [email protected] Summary. Entropy encoding which is a way of lossless compression that is done on an image after the quantization stage. It enables to represent an image in a more efficient way with smallest memory for storage or transmission. In this paper we will explore various schemes of entropy encoding and how they work mathematically where it applies. 1 Introduction In the process of wavelet image compression, there are three major steps that makes the compression possible, namely, decomposition, quanti- zation and entropy encoding steps. While quantization may be a lossy step where some quantity of data may be lost and may not be re- covered, entropy encoding enables a lossless compression that further compresses the data. [13], [18], [5] In this paper we discuss various entropy encoding schemes that are used by engineers (in various applications). 1.1 Wavelet Image Compression In wavelet image compression, after the quantization step (see Figure 1) entropy encoding, which is a lossless form of compression is performed on a particular image for more efficient storage. Either 8 bits or 16 bits are required to store a pixel on a digital image. With efficient entropy encoding, we can use a smaller number of bits to represent a pixel in an image; this results in less memory usage to store or even transmit an image. Karhunen-Lo`eve theorem enables us to pick the best basis thus to minimize the entropy and error, to better represent an image for optimal storage or transmission. -

The Pillars of Lossless Compression Algorithms a Road Map and Genealogy Tree
International Journal of Applied Engineering Research ISSN 0973-4562 Volume 13, Number 6 (2018) pp. 3296-3414 © Research India Publications. http://www.ripublication.com The Pillars of Lossless Compression Algorithms a Road Map and Genealogy Tree Evon Abu-Taieh, PhD Information System Technology Faculty, The University of Jordan, Aqaba, Jordan. Abstract tree is presented in the last section of the paper after presenting the 12 main compression algorithms each with a practical This paper presents the pillars of lossless compression example. algorithms, methods and techniques. The paper counted more than 40 compression algorithms. Although each algorithm is The paper first introduces Shannon–Fano code showing its an independent in its own right, still; these algorithms relation to Shannon (1948), Huffman coding (1952), FANO interrelate genealogically and chronologically. The paper then (1949), Run Length Encoding (1967), Peter's Version (1963), presents the genealogy tree suggested by researcher. The tree Enumerative Coding (1973), LIFO (1976), FiFO Pasco (1976), shows the interrelationships between the 40 algorithms. Also, Stream (1979), P-Based FIFO (1981). Two examples are to be the tree showed the chronological order the algorithms came to presented one for Shannon-Fano Code and the other is for life. The time relation shows the cooperation among the Arithmetic Coding. Next, Huffman code is to be presented scientific society and how the amended each other's work. The with simulation example and algorithm. The third is Lempel- paper presents the 12 pillars researched in this paper, and a Ziv-Welch (LZW) Algorithm which hatched more than 24 comparison table is to be developed. -

The Deep Learning Solutions on Lossless Compression Methods for Alleviating Data Load on Iot Nodes in Smart Cities
sensors Article The Deep Learning Solutions on Lossless Compression Methods for Alleviating Data Load on IoT Nodes in Smart Cities Ammar Nasif *, Zulaiha Ali Othman and Nor Samsiah Sani Center for Artificial Intelligence Technology (CAIT), Faculty of Information Science & Technology, University Kebangsaan Malaysia, Bangi 43600, Malaysia; [email protected] (Z.A.O.); [email protected] (N.S.S.) * Correspondence: [email protected] Abstract: Networking is crucial for smart city projects nowadays, as it offers an environment where people and things are connected. This paper presents a chronology of factors on the development of smart cities, including IoT technologies as network infrastructure. Increasing IoT nodes leads to increasing data flow, which is a potential source of failure for IoT networks. The biggest challenge of IoT networks is that the IoT may have insufficient memory to handle all transaction data within the IoT network. We aim in this paper to propose a potential compression method for reducing IoT network data traffic. Therefore, we investigate various lossless compression algorithms, such as entropy or dictionary-based algorithms, and general compression methods to determine which algorithm or method adheres to the IoT specifications. Furthermore, this study conducts compression experiments using entropy (Huffman, Adaptive Huffman) and Dictionary (LZ77, LZ78) as well as five different types of datasets of the IoT data traffic. Though the above algorithms can alleviate the IoT data traffic, adaptive Huffman gave the best compression algorithm. Therefore, in this paper, Citation: Nasif, A.; Othman, Z.A.; we aim to propose a conceptual compression method for IoT data traffic by improving an adaptive Sani, N.S. -

Coding and Compression
Chapter 3 Multimedia Systems Technology: Co ding and Compression 3.1 Intro duction In multimedia system design, storage and transport of information play a sig- ni cant role. Multimedia information is inherently voluminous and therefore requires very high storage capacity and very high bandwidth transmission capacity.For instance, the storage for a video frame with 640 480 pixel resolution is 7.3728 million bits, if we assume that 24 bits are used to en- co de the luminance and chrominance comp onents of each pixel. Assuming a frame rate of 30 frames p er second, the entire 7.3728 million bits should b e transferred in 33.3 milliseconds, which is equivalent to a bandwidth of 221.184 million bits p er second. That is, the transp ort of such large number of bits of information and in such a short time requires high bandwidth. Thereare two approaches that arepossible - one to develop technologies to provide higher bandwidth of the order of Gigabits per second or more and the other to nd ways and means by which the number of bits to betransferred can be reduced, without compromising the information content. It amounts to saying that we need a transformation of a string of characters in some representation such as ASCI I into a new string e.g., of bits that contains the same information but whose length must b e as small as p ossible; i.e., data compression. Data compression is often referred to as co ding, whereas co ding is a general term encompassing any sp ecial representation of data that achieves a given goal. -

Answers to Exercises
Answers to Exercises A bird does not sing because he has an answer, he sings because he has a song. —Chinese Proverb Intro.1: abstemious, abstentious, adventitious, annelidous, arsenious, arterious, face- tious, sacrilegious. Intro.2: When a software house has a popular product they tend to come up with new versions. A user can update an old version to a new one, and the update usually comes as a compressed file on a floppy disk. Over time the updates get bigger and, at a certain point, an update may not fit on a single floppy. This is why good compression is important in the case of software updates. The time it takes to compress and decompress the update is unimportant since these operations are typically done just once. Recently, software makers have taken to providing updates over the Internet, but even in such cases it is important to have small files because of the download times involved. 1.1: (1) ask a question, (2) absolutely necessary, (3) advance warning, (4) boiling hot, (5) climb up, (6) close scrutiny, (7) exactly the same, (8) free gift, (9) hot water heater, (10) my personal opinion, (11) newborn baby, (12) postponed until later, (13) unexpected surprise, (14) unsolved mysteries. 1.2: A reasonable way to use them is to code the five most-common strings in the text. Because irreversible text compression is a special-purpose method, the user may know what strings are common in any particular text to be compressed. The user may specify five such strings to the encoder, and they should also be written at the start of the output stream, for the decoder’s use. -

Digital Video Source Encoding Entropy Encoding
CSE 126 Multimedia Systems P. Venkat Rangan Spring 2003 Lecture Note 4 (April 10) Digital Video The bandwidth required for digital video is staggering. Uncompressed NTSC video requires a bandwidth of 20MByte/sec, HDTV requires 200MByte/sec! Various encoding techniques have been developed in order to make digital video feasible. Two classes of encoding techniques are Source Encoding and Entropy Encoding. Source Encoding Source encoding is lossy and applies techniques based upon properties of the media. There are four types of source encoding: • Sub-band coding gives different resolutions to different bands. E.g. since the human eye is more sensitive to intensity changes than color changes, give the Y component of YUV video more resolution than the U and V components. • Subsampling groups pixels together into a meta-region and encodes a single value for the entire region • Predictive coding uses one sample to guess the next. It assumes a model and sends only differences from the model (error values). • Transform encoding transforms one set of reference planes to another. In the example of vector quantization from last class, we could rotate the axes 45 degrees so that fewer bits could be used to represent values on the U-axis. In this example, instead of using 4 bits to represent the ten possible values of U, we can use 2 bits for the four different values of U'. Entropy Encoding Entropy Encoding techniques are lossless techniques which tend to be simpler than source encoding techniques. The three entropy encoding techniques are: • Run-Length Encoding (RLE) encodes multiple appearances of the same value as {value, # of appearances}. -
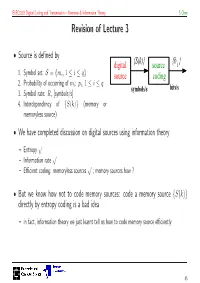
Revision of Lecture 3
ELEC3203 Digital Coding and Transmission – Overview & Information Theory S Chen Revision of Lecture 3 • Source is defined by digital {S(k)}source {b i } 1. Symbol set: = mi, 1 i q S { ≤ ≤ } source coding 2. Probability of occurring of mi: pi, 1 i q ≤ ≤ symbols/s bits/s 3. Symbol rate: Rs [symbols/s] 4. Interdependency of S(k) (memory or { } memoryless source) • We have completed discussion on digital sources using information theory – Entropy √ – Information rate √ – Efficient coding: memoryless sources √ ; memory sources how ? • But we know how not to code memory sources: code a memory source {S(k)} directly by entropy coding is a bad idea – in fact, information theory we just learnt tell us how to code memory source efficiently 45 ELEC3203 Digital Coding and Transmission – Overview & Information Theory S Chen Source Coding Visit • Transmit at certain rate Rb requires certain amount of resource – bandwidth and power – The larger the rate Rb, the larger the required resource • Source coding aims to get Rb as small as possible, ideally close to the source information rate – Information rate, a fundamental physical quantity of the source, tells you how many bits/s of information the source really needs to send out – If Rb is close to information rate, source coding is most efficient • Memoryless source {S(k)}, entropy coding on {S(k)} is most efficient, as data rate Rb is as close to source information rate as possible • For memory source {S(k)}, information theory also tells us how to code {S(k)} most efficiently 46 ELEC3203 Digital Coding and Transmission – Overview & Information Theory S Chen Remove Redundancy • Key to get close to information rate H · Rs is to remove redundancy – Part of S(k) can be predicted by {S(k − i)}, i ≥ 1 → When coding S(k) this temporal redundancy can be predicted from {S(k − i)}, i ≥ 1 – By removing the predictable part, resulting residual sequence {ε(k)} is near independent or uncorrelated, can thus be coded by an entropy coding • Speech samples are highly correlated, i.e. -

Entropy Based Estimation Algorithm Using Split Images to Increase Compression Ratio 33
http://dergipark.gov.tr/tujes Trakya University Journal of Engineering Sciences, 18(1): 31-41, 2017 ISSN 2147–0308 Araştırma Makalesi / Research Article ENTROPY BASED ESTIMATION ALGORITHM USING SPLIT IMAGES TO INCREASE COMPRESSION RATIO Emir ÖZTÜRK1*, Altan MESUT1 1 Department of Computer Engineering, Trakya University, Edirne-TURKEY Abstract: Compressing image files after splitting them into certain number of parts can increase compression ratio. Acquired compression ratio can also be increased by compressing each part of the image using different algorithms, because each algorithm gives different compression ratios on different complexity values. In this study, statistical compression results and measured complexity values of split images are obtained, and an estimation algorithm based on these results is presented. Our algorithm splits images into 16 parts, compresses each part with different algorithm and joins the images after compression. Compression results show that using our estimation algorithm acquires higher compression ratios over whole image compression techniques with ratio of 5% on average and 25% on maximum. Keywords: Estimation algorithm; image compression; image processing; image complexity SIKIŞTIRMA ORANINI ARTTIRMAK İÇİN BÖLÜNMÜŞ RESİMLERİ KULLANAN ENTROPİ TABANLI BIR TAHMİN ALGORİTMASI Özet: Resim dosyalarını belirli sayıda parçalara böldükten sonra sıkıştırma işlemi yapmak sıkıştırma oranını arttırabilmektedir. Elde edilen sıkıştırma oranı resmin her parçasının farklı bir algoritmayla sıkıştırılması ile daha da fazla arttırılabilmektedir. Her algoritma farklı karmaşıklık değerlerinde farklı sıkıştırma oranı sağlamaktadır. Bu çalışmada bölünmüş resimlerden sıkıştırma sonuçları istatistikleri ve ölçülen karmaşıklık değerleri elde edilmiş ve bu sonuçları kullanan bir tahmin algoritması önerilmiştir. Algoritmamız resimleri 16 parçaya böler, her parçayı farklı bir algoritmayla sıkıştırır ve bu parçaları en son aşamada birleştirir.