Design Optimization of Ttethernet-Based Distributed Real-Time Systems
Total Page:16
File Type:pdf, Size:1020Kb
Load more
Recommended publications
-
On Ttethernet for Integrated Fault-Tolerant Spacecraft Networks
On TTEthernet for Integrated Fault-Tolerant Spacecraft Networks Andrew Loveless∗ NASA Johnson Space Center, Houston, TX, 77058 There has recently been a push for adopting integrated modular avionics (IMA) princi- ples in designing spacecraft architectures. This consolidation of multiple vehicle functions to shared computing platforms can significantly reduce spacecraft cost, weight, and de- sign complexity. Ethernet technology is attractive for inclusion in more integrated avionic systems due to its high speed, flexibility, and the availability of inexpensive commercial off-the-shelf (COTS) components. Furthermore, Ethernet can be augmented with a variety of quality of service (QoS) enhancements that enable its use for transmitting critical data. TTEthernet introduces a decentralized clock synchronization paradigm enabling the use of time-triggered Ethernet messaging appropriate for hard real-time applications. TTEther- net can also provide two forms of event-driven communication, therefore accommodating the full spectrum of traffic criticality levels required in IMA architectures. This paper explores the application of TTEthernet technology to future IMA spacecraft architectures as part of the Avionics and Software (A&S) project chartered by NASA's Advanced Ex- ploration Systems (AES) program. Nomenclature A&S = Avionics and Software Project AA2 = Ascent Abort 2 AES = Advanced Exploration Systems Program ANTARES = Advanced NASA Technology Architecture for Exploration Studies API = Application Program Interface ARM = Asteroid Redirect Mission -

An Extension of the Omnet++ INET Framework for Simulating Real-Time Ethernet with High Accuracy
An Extension of the OMNeT++ INET Framework for Simulating Real-time Ethernet with High Accuracy Till Steinbach, Hermand Dieumo Kenfack, Franz Korf, Thomas C. Schmidt HAW-Hamburg, Department Informatik Berliner Tor 7, D-20099 Hamburg, Germany {till.steinbach, hermand.dieumo, korf, schmidt}@informatik.haw-hamburg.de ABSTRACT those fields; real-time Ethernet is a promising candidate for Real-time extensions to standard switched Ethernet widen the upcoming tasks. the realm of computer networking into the time-critical do- Ethernet has proven to be a flexible, widely deployed, and main. These technologies have started to establish in pro- highly scalable protocol. Current Ethernet is a technology cess automation, while Ethernet-based communication in- based on switching that also allows to increase the amount of frastructures in vehicles are novel and challenged by particu- traffic simultaneously transferred, by using segregated com- larly hard real-time constraints. Simulation tools are of vital munication in groups. However, due to its randomised me- importance to explore the technical feasibility and facilitate dia access and best effort approach, it does not provide re- the distributed process of vehicle infrastructure design. liable temporal performance bounds. Real-time extensions This paper introduces an extension of the OMNeT++ to Ethernet promise to overcome those obstacles. INET framework for simulating real-time Ethernet with high In process automation, several Ethernet-based products temporal accuracy. Our module implements the TTEther- already provide real-time functionality for tasks with strict net protocol, a real-time extension to standard Ethernet that temporal constraints. The use of real-time Ethernet in an is proposed for standardisation. -

Developing Deterministic Networking Technology for Railway Applications Using Ttethernet Software-Based End Systems
INDustrial EXploitation of the genesYS cross-domain architecture Developing deterministic networking technology for railway applications using TTEthernet software-based end systems Project n° 100021 Astrit Ademaj, TTTech Computertechnik AG Outline INDustrial EXploitation of the genesYS cross-domain architecture GENESYS requirements - railway Time-triggered communication TTEthernet SW based implementation of the TTEthernet Conclusion ARTEMISIA Association Title Presentation - 2 GENESYS – GENeric Embedded SYStems INDustrial EXploitation of the genesYS cross-domain architecture Instruction how to build your embedded systems architecture GENESYS: ¾ is a reference architecture template providing specifications and requirements to design a cross domain embedded systems architecture. ¾ architecture style supports a composable, robust and comprehensible, component based framework with strict separation of computation from message based communication ¾ distinguishes between 3 integration levels: • Chip Level (IP cores communicate via a deterministic Network-on-a-Chip) • Device Level (Chips communicate within a device) • System Level (Devices communicate in an open or closed environment) ARTEMISIA Association Title Presentation - 3 GENESYS and the railway domain INDustrial EXploitation of the genesYS cross-domain architecture Safety-critical applications in the railway domain require ¾ deterministic communication networks ¾ robustness and ¾ composability are key issues. GENESYS ¾ architecture style supports a composable, robust and comprehensible, -
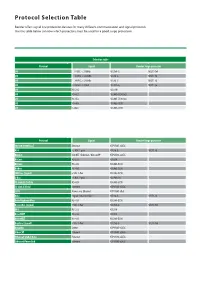
Protocol Selection Table
Protocol Selection Table Bender offers signal line protection devices for many different communication and signal protocols. Use the table below to know which protectors must be used for a good surge protection. Selection table Protocol Signal Bender Surge protector I/O ± 5 VDC, < 250kHz NSL7v5-G NSLT1-7v5 I/O ± 12 VDC, < 250kHz NSL18-G NSLT1-18 I/O ± 24 VDC, < 250kHz NSL36-G NSLT1-36 I/O 0-20mA / 4-20mA NSL420-G NSLT1-36 I/O RS-232 NSL-DH I/O RS-422 NSL485-EC90 (x2) I/O RS-452 NSL485-EC90 (x2) I/O RS-485 NSL485-EC90 I/O 1-Wire NSL485-EC90 Protocol Signal Bender Surge protector 10/100/1000BaseT Ethernet NTP-RJ45-xCAT6 AS-i 32 VDC 1-pair NSL36-G NSLT1-36 BACnet ARCNET / Ethernet / BACnet/IP NTP-RJ45-xCAT6 BACnet RS-232 NSL-DH BACnet RS-485 NSL485-EC90 BitBus RS-485 NSL485-EC90 CAN Bus (Signal) 5 VDC 1-Pair NSL485-EC90 C-Bus 36 VDC 1-pair NSSP6A-38 CC-Link/LT/Safety RS-485 NSL485-EC90 CC-Link IE Field Ethernet NTP-RJ45-xCAT6 CCTV Power over Ethernet NTP-RJ45-xPoE DALI Digital Serial Interface NSL36-G NSLT1-36 Data Highway/Plus RS-485 NSL485-EC90 DeviceNet (Signal) 5 VDC 1-Pair NSL7v5-G NSLT1-7v5 DF1 RS-232 NSL-DH DirectNET RS-232 NSL-DH DirectNET RS-485 NSL485-EC90 Dupline (Signal) 5 VDC 1-Pair NSL7v5-G NSLT1-7v5 Dynalite DyNet NTP-RJ45-xCAT6 EtherCAT Ethernet NTP-RJ45-xCAT6 Ethernet Global Data Ethernet NTP-RJ45-xCAT6 Ethernet Powerlink Ethernet NTP-RJ45-xCAT6 Protocol Signal Bender Surge protector FIP Bus RS-485 NSL485-EC90 FINS Ethernet NTP-RJ45-xCAT6 FINS RS-232 NSL-DH FINS DeviceNet (Signal) NSL7v5-G NSLT1-7v5 FOUNDATION Fieldbus H1 -

Read Full Text (PDF)
Industrial networks and IIoT: Now and future trends Downloaded from: https://research.chalmers.se, 2021-09-25 14:32 UTC Citation for the original published paper (version of record): Sari, A., Lekidis, A., Butun, I. (2020) Industrial networks and IIoT: Now and future trends Industrial IoT: Challenges, Design Principles, Applications, and Security: 3-55 http://dx.doi.org/10.1007/978-3-030-42500-5_1 N.B. When citing this work, cite the original published paper. research.chalmers.se offers the possibility of retrieving research publications produced at Chalmers University of Technology. It covers all kind of research output: articles, dissertations, conference papers, reports etc. since 2004. research.chalmers.se is administrated and maintained by Chalmers Library (article starts on next page) 8JJINXHZXXNTSXXYFYXFSIFZYMTWUWTKNQJXKTWYMNXUZGQNHFYNTSFYMYYUX\\\WJXJFWHMLFYJSJYUZGQNHFYNTS ,QGXVWULDO1HWZRUNVDQG,,R71RZDQG)XWXUH7UHQGV (MFUYJW{/ZQ^ )4.D (.9&9.438 7*&)8 FZYMTWX &QUFWXQFS8FWN &QJ]NTX1JPNINX :SN[JWXNY^TK)JQF\FWJFWJ .SYWFHTR9JQJHTR8& 5:'1.(&9.438dddFor(.9&9.438(.9&9 ddd 5:'1.(&9.438ddd(.9&9.438ddd 8**574+.1* 8**574+.1* .XRFNQ'ZYZS (MFQRJWX:SN[JWXNY^TK9JHMSTQTL^ 5:'1.(&9.438ddd(.9&9.438ddd 8**574+.1* 8TRJTKYMJFZYMTWXTKYMNXUZGQNHFYNTSFWJFQXT\TWPNSLTSYMJXJWJQFYJIUWTOJHYXReviewJIUWTOJHYX .S2TYNTS;NJ\UWTOJHY *SJWL^HTSXZRUYNTSKTW.T9X^XYJRX;NJ\UWTOJHY &QQHTSYJSYKTQQT\NSLYMNXUFLJ\FXZUQTFIJIG^&QJ]NTX1JPNINXTS/ZQ^ 9MJZXJWMFXWJVZJXYJIJSMFSHJRJSYTKYMJIT\SQTFIJIKNQJ Industrial networks and IIoT: Now and future trends Alparslan Sari, Alexios Lekidis, and Ismail Butun For Abstractact ConnectivityConnecti is tthe one word summary for Industry 4.0 revolution. The importancemportancetance of InternetIntern of ThinThings (IoT) and Industrial IoT (IIoT) have been increased dramaticallyaticallytically with the rise ofo induindustrialization and industry 4.0. As new opportunities bring theireir own challenges, wwith the massive interconnected devices of the IIoT, cyber securityrity of thosetho netwnetworks anddpr privacy of their users have become an impor- tant aspect. -

Partner Directory Wind River Partner Program
PARTNER DIRECTORY WIND RIVER PARTNER PROGRAM The Internet of Things (IoT), cloud computing, and Network Functions Virtualization are but some of the market forces at play today. These forces impact Wind River® customers in markets ranging from aerospace and defense to consumer, networking to automotive, and industrial to medical. The Wind River® edge-to-cloud portfolio of products is ideally suited to address the emerging needs of IoT, from the secure and managed intelligent devices at the edge to the gateway, into the critical network infrastructure, and up into the cloud. Wind River offers cross-architecture support. We are proud to partner with leading companies across various industries to help our mutual customers ease integration challenges; shorten development times; and provide greater functionality to their devices, systems, and networks for building IoT. With more than 200 members and still growing, Wind River has one of the embedded software industry’s largest ecosystems to complement its comprehensive portfolio. Please use this guide as a resource to identify companies that can help with your development across markets. For updates, browse our online Partner Directory. 2 | Partner Program Guide MARKET FOCUS For an alphabetical listing of all members of the *Clavister ..................................................37 Wind River Partner Program, please see the Cloudera ...................................................37 Partner Index on page 139. *Dell ..........................................................45 *EnterpriseWeb -

On Ttethernet for Integrated Fault- Tolerant Spacecraft Networks
https://ntrs.nasa.gov/search.jsp?R=20170009923 2019-08-31T01:46:29+00:00Z On TTEthernet for Integrated Fault- Tolerant Spacecraft Networks Andrew Loveless NASA Johnson Space Center (JSC) AIAA SPACE 2015, Aug. 31st – Sep. 2nd 2015 Pasadena, CA Andrew Loveless, NASA/JSC Project Overview and Motivation • Integrated modular avionics (IMA) principles are attractive for inclusion in spacecraft architectures. Consolidates multiple functions to shared computing platforms. Reduces spacecraft cost, weight, and design complexity. Interchangeable components increases overall system maintainability – important for long duration missions! • The Avionics and Software (A&S) project . Funded by NASA’s Advanced Exploration Systems program. Developing a flexible mission agnostic spacecraft architecture according to IMA principles. NASA can minimize development time and cost by utilizing existing commercial technologies. Matures promising technologies for use in flight projects. 2 Andrew Loveless, NASA/JSC Project Overview and Motivation • IMA Considerations in Networking . Requires network capable of accommodating traffic from multiple highly diverse systems (e.g. critical vs. non-critical) – potentially all from one shared computer platform. Must prevent cascading faults b/w systems of differing criticalities connected to the same physical network. Most avionic system failures result from ineffective fault containment and the resulting domino effect. Some network technologies are better suited for certain tasks. Applying the same technology everywhere traditionally results in undue expense and limited performance. Results in hybrid architectures with multiple technologies (e.g. NASA’s LRO has MIL-STD-1553, SpaceWire, LVDS). 3 Andrew Loveless, NASA/JSC Project Overview and Motivation • Ethernet is promising . Inexpensive, widespread, and high speed = highly flexible. Commonality promotes interchangeability between components. -

ESA ADCSS 2015 Deterministic Ethernet in Space Avionics
Ensuring Reliable Networks ESA ADCSS 2015 Deterministic Ethernet in Space Avionics Bülent Altan Strategic Advisor with Jean-Francois Dufour, Christian Fidi and Matthias Mäke-Kail www.tttech.com Copyright © TTTech Computertechnik AG. All rights reserved. Page 1 Content Ensuring Reliable Networks Space Avionics: Trends & Challenges Communication Requirements + Deterministic Ethernet Spin-in of Existing (Communication) Technology Federated Architectures / Distributed IMA Scalable, Modular Platforms + Related Savings Current R&D Status State-of-the Art Examples with TTEthernet Conclusions www.tttech.com Copyright © TTTech Computertechnik AG. All rights reserved. Page 2 Trends Ensuring Reliable Networks Globalization of space industry Emergence of “new space” Launchers used to be stable, “high-volume” platforms Nano-satellites and constellations are becoming the high-volume platforms …and drive the requirements for new launchers Automotive industry drives electronics innovation – particularly with autonomous driving …and this is of course being noted by space agencies and the space industry FPGAs become more affordable, ASIC designs more costly www.tttech.com Copyright © TTTech Computertechnik AG. All rights reserved. Page 3 Challenges Ensuring Reliable Networks Software has become the largest portion of spacecraft development cost (30-40%) Data rates and volumes increase drastically (new instruments and sensor technologies, new on-board functions and increased autonomy) While hardware costs decrease, more functionality is asked of avionics systems which creates even more pressure on software development …Yet shorter development times are needed for economic feasibility Software development widely seen as main schedule risk Can automotive or industrial solutions be re-used? …and how does this impact obsolescence management? Can one platform cover such diverse spacecraft as launch vehicles, earth observation satellites and human rated capsules or habitats? And of course the perennial challenge of weight reduction www.tttech.com Copyright © TTTech Computertechnik AG. -

Ttethernet – a Powerful Network Solution for Advanced Integrated Systems Ttethernet: a Powerful Network Solution for Advanced Integrated Systems
GE Fanuc Intelligent Platforms TTEthernet – A Powerful Network Solution for Advanced Integrated Systems TTEthernet: A Powerful Network Solution for Advanced Integrated Systems TTEthernet – A Powerful Time-Triggered switches provide ARINC 664 functionality to meet existing Network Solution requirements of avionics Ethernet networks. With TTEthernet, critical control systems, audio/video and As the most widely-installed local area network technology, standard LAN applications can share one network. TTEthernet Ethernet is used as a universal network solution in office facilitates design of mixed criticality systems and system-of- and web applications, and production facilities. Engineering, systems integration. maintenance and training costs for Ethernet-based networks are considerably lower than costs for many proprietary bus In the aviation domain, TTEthernet can be used for high- systems and Ethernet generally offers higher bandwidths. speed active controls, smart sensor and actuator networks, But when Ethernet was developed over 30 years ago, time- deterministic avionics and vehicle backbone networks, critical, deterministic or safety-relevant tasks were not taken critical audio/video delivery, reflective memory, modular into account. controls and integrated modular systems such as Integrated Modular Avionics (IMA) or distributed IMA. TTEthernet also Time-Triggered Ethernet (TTEthernet) expands classical targets also critical embedded systems in aerospace and Ethernet use with powerful services (SAE AS6802) to meet defense, automotive, -

On Ttethernet for Integrated Fault- Tolerant Spacecraft Networks
On TTEthernet for Integrated Fault- Tolerant Spacecraft Networks Andrew Loveless NASA Johnson Space Center (JSC) AIAA SPACE 2015, Aug. 31st – Sep. 2nd 2015 Pasadena, CA Andrew Loveless, NASA/JSC Project Overview and Motivation • Integrated modular avionics (IMA) principles are attractive for inclusion in spacecraft architectures. Consolidates multiple functions to shared computing platforms. Reduces spacecraft cost, weight, and design complexity. Interchangeable components increases overall system maintainability – important for long duration missions! • The Avionics and Software (A&S) project . Funded by NASA’s Advanced Exploration Systems program. Developing a flexible mission agnostic spacecraft architecture according to IMA principles. NASA can minimize development time and cost by utilizing existing commercial technologies. Matures promising technologies for use in flight projects. 2 Andrew Loveless, NASA/JSC Project Overview and Motivation • IMA Considerations in Networking . Requires network capable of accommodating traffic from multiple highly diverse systems (e.g. critical vs. non-critical) – potentially all from one shared computer platform. Must prevent cascading faults b/w systems of differing criticalities connected to the same physical network. Most avionic system failures result from ineffective fault containment and the resulting domino effect. Some network technologies are better suited for certain tasks. Applying the same technology everywhere traditionally results in undue expense and limited performance. Results in hybrid architectures with multiple technologies (e.g. NASA’s LRO has MIL-STD-1553, SpaceWire, LVDS). 3 Andrew Loveless, NASA/JSC Project Overview and Motivation • Ethernet is promising . Inexpensive, widespread, and high speed = highly flexible. Commonality promotes interchangeability between components. Can augment with QoS enhancements for critical applications. The A&S project considers Ethernet fundamental in the design of future manned spacecraft. -

Software-Defined Networking for Real-Time Ethernet
Presented at the 13th International Conference on Informatics in Control, Automation and Robotics (ICINCO), July 2016, http://www.icinco.org/ Software-defined Networking for Real-time Ethernet Jia Lei Du and Matthias Herlich Salzburg Research, Jakob Haringer Straße 5/3, Salzburg, Austria {jia.du, matthias.herlich}@salzburgresearch.at Keywords: Software-defined Networking, Real-time Ethernet Abstract: Real-time Ethernet is used in many industrial and embedded systems, but has so far mostly been statically configured. However, in the future these network configurations will be required to change dynamically, for example for highly flexible production lines or even software upgrades in modern cars that add new features which require changes to the in-vehicle network. Software-defined networking (SDN) is already increasingly used to dynamically configure non-real-time networks. In this paper we explore the idea of a software-defined real-time Ethernet. We analyze the features of current real-time Ethernet protocols, the applicability of SDN and give an overview of potential advantages of software-defined networking for real- time communication which can enable features not achievable using current solutions. In the future this development will likely lead to more flexible, efficient and robust real-time networks. 1 INTRODUCTION centralized intelligent controller with “dumb” forwarding devices in the data plane of the network Real-time Ethernet (RTE) allows the use of cost (McKeown et al., 2008). By monitoring network- effective, widespread and high-bandwidth Ethernet wide state, the controller obtains an up-to-date view technology in industrial environments like of the network and can dynamically adapt flows as automation, process control and transportation necessary. -

Time-Triggered Ethernet for In-Vehicle Networks
TTEthernet Related Work Till Steinbach Time-Triggered Ethernet for in-vehicle Introduction Commercial Efforts networks Scientific Efforts Related Work Classification of my Work Summary Till Steinbach [email protected] Hamburg University of Applied Sciences Anwendungen 2 – 18. June 2008 Agenda TTEthernet 1 Introduction Related Work Motivation and Problem Statement Till Steinbach Retrospect of previous Work Introduction Current State of my Work Commercial Efforts 2 Commercial Efforts Scientific Efforts Classification of my Approaches to Realtime Ethernet Work Analysis Summary Working groups 3 Scientific Efforts Approaches to Real-Time Ethernet Analysis Working Groups and Conferences 4 Classification of my Work 5 Summary Motivation TTEthernet Related Work Till Steinbach Introduction Motivation and Problem Statement Retrospect of previous Work Current State of my Work Commercial Efforts Scientific Efforts Classification of my Work Summary Source: Mercedes Motivation TTEthernet Related Work Till Steinbach Introduction Motivation and Problem Statement increasing demands for efficiency on in-vehicle Retrospect of previous Work Current State of my communication Work compliant with rigid real-time constraints Commercial Efforts flexible support for weakly constrained traffic Scientific Efforts Classification of my significant importance for safety, reliability or Work comfort Summary Problem Statement TTEthernet Related Work Till Steinbach Introduction Motivation and Problem Statement Retrospect of previous Work Wide variety of products for real-time