Regular Expressions
Total Page:16
File Type:pdf, Size:1020Kb

Load more
Recommended publications
-

C Strings and Pointers
Software Design Lecture Notes Prof. Stewart Weiss C Strings and Pointers C Strings and Pointers Motivation The C++ string class makes it easy to create and manipulate string data, and is a good thing to learn when rst starting to program in C++ because it allows you to work with string data without understanding much about why it works or what goes on behind the scenes. You can declare and initialize strings, read data into them, append to them, get their size, and do other kinds of useful things with them. However, it is at least as important to know how to work with another type of string, the C string. The C string has its detractors, some of whom have well-founded criticism of it. But much of the negative image of the maligned C string comes from its abuse by lazy programmers and hackers. Because C strings are found in so much legacy code, you cannot call yourself a C++ programmer unless you understand them. Even more important, C++'s input/output library is harder to use when it comes to input validation, whereas the C input/output library, which works entirely with C strings, is easy to use, robust, and powerful. In addition, the C++ main() function has, in addition to the prototype int main() the more important prototype int main ( int argc, char* argv[] ) and this latter form is in fact, a prototype whose second argument is an array of C strings. If you ever want to write a program that obtains the command line arguments entered by its user, you need to know how to use C strings. -
Deterministic Finite Automata 0 0,1 1
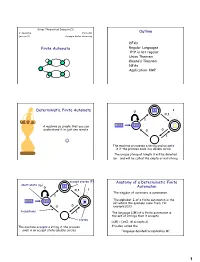
Great Theoretical Ideas in CS V. Adamchik CS 15-251 Outline Lecture 21 Carnegie Mellon University DFAs Finite Automata Regular Languages 0n1n is not regular Union Theorem Kleene’s Theorem NFAs Application: KMP 11 1 Deterministic Finite Automata 0 0,1 1 A machine so simple that you can 0111 111 1 ϵ understand it in just one minute 0 0 1 The machine processes a string and accepts it if the process ends in a double circle The unique string of length 0 will be denoted by ε and will be called the empty or null string accept states (F) Anatomy of a Deterministic Finite start state (q0) 11 0 Automaton 0,1 1 The singular of automata is automaton. 1 The alphabet Σ of a finite automaton is the 0111 111 1 ϵ set where the symbols come from, for 0 0 example {0,1} transitions 1 The language L(M) of a finite automaton is the set of strings that it accepts states L(M) = {x∈Σ: M accepts x} The machine accepts a string if the process It’s also called the ends in an accept state (double circle) “language decided/accepted by M”. 1 The Language L(M) of Machine M The Language L(M) of Machine M 0 0 0 0,1 1 q 0 q1 q0 1 1 What language does this DFA decide/accept? L(M) = All strings of 0s and 1s The language of a finite automaton is the set of strings that it accepts L(M) = { w | w has an even number of 1s} M = (Q, Σ, , q0, F) Q = {q0, q1, q2, q3} Formal definition of DFAs where Σ = {0,1} A finite automaton is a 5-tuple M = (Q, Σ, , q0, F) q0 Q is start state Q is the finite set of states F = {q1, q2} Q accept states : Q Σ → Q transition function Σ is the alphabet : Q Σ → Q is the transition function q 1 0 1 0 1 0,1 q0 Q is the start state q0 q0 q1 1 q q1 q2 q2 F Q is the set of accept states 0 M q2 0 0 q2 q3 q2 q q q 1 3 0 2 L(M) = the language of machine M q3 = set of all strings machine M accepts EXAMPLE Determine the language An automaton that accepts all recognized by and only those strings that contain 001 1 0,1 0,1 0 1 0 0 0 1 {0} {00} {001} 1 L(M)={1,11,111, …} 2 Membership problem Determine the language decided by Determine whether some word belongs to the language. -

1 Alphabets and Languages
1 Alphabets and Languages Look at handout 1 (inference rules for sets) and use the rules on some exam- ples like fag ⊆ ffagg fag 2 fa; bg, fag 2 ffagg, fag ⊆ ffagg, fag ⊆ fa; bg, a ⊆ ffagg, a 2 fa; bg, a 2 ffagg, a ⊆ fa; bg Example: To show fag ⊆ fa; bg, use inference rule L1 (first one on the left). This asks us to show a 2 fa; bg. To show this, use rule L5, which succeeds. To show fag 2 fa; bg, which rule applies? • The only one is rule L4. So now we have to either show fag = a or fag = b. Neither one works. • To show fag = a we have to show fag ⊆ a and a ⊆ fag by rule L8. The only rules that might work to show a ⊆ fag are L1, L2, and L3 but none of them match, so we fail. • There is another rule for this at the very end, but it also fails. • To show fag = b, we try the rules in a similar way, but they also fail. Therefore we cannot show that fag 2 fa; bg. This suggests that the state- ment fag 2 fa; bg is false. Suppose we have two set expressions only involving brackets, commas, the empty set, and variables, like fa; fb; cgg and fa; fc; bgg. Then there is an easy way to test if they are equal. If they can be made the same by • permuting elements of a set, and • deleting duplicate items of a set then they are equal, otherwise they are not equal. -

Context Free Languages II Announcement Announcement
Announcement • About homework #4 Context Free Languages II – The FA corresponding to the RE given in class may indeed already be minimal. – Non-regular language proofs CFLs and Regular Languages • Use Pumping Lemma • Homework session after lecture Announcement Before we begin • Note about homework #2 • Questions from last time? – For a deterministic FA, there must be a transition for every character from every state. Languages CFLs and Regular Languages • Recall. • Venn diagram of languages – What is a language? Is there – What is a class of languages? something Regular Languages out here? CFLs Finite Languages 1 Context Free Languages Context Free Grammars • Context Free Languages(CFL) is the next • Let’s formalize this a bit: class of languages outside of Regular – A context free grammar (CFG) is a 4-tuple: (V, Languages: Σ, S, P) where – Means for defining: Context Free Grammar • V is a set of variables Σ – Machine for accepting: Pushdown Automata • is a set of terminals • V and Σ are disjoint (I.e. V ∩Σ= ∅) •S ∈V, is your start symbol Context Free Grammars Context Free Grammars • Let’s formalize this a bit: • Let’s formalize this a bit: – Production rules – Production rules →β •Of the form A where • We say that the grammar is context-free since this ∈ –A V substitution can take place regardless of where A is. – β∈(V ∪∑)* string with symbols from V and ∑ α⇒* γ γ α • We say that γ can be derived from α in one step: • We write if can be derived from in zero –A →βis a rule or more steps. -
THE 1995 STANDARD MUMPS POCKET GUIDE Fifth Edition of the Mumps Pocket Guide Second Printing
1995 S TA N DA R D M U M P S P O C K E T G U I D E FIFTH EDITION FREDERICK D. S. MARSHALL for Octo Barnett, Bob Greenes, Curt Marbles, Neil Papalardo, and Massachusetts General Hospital who gave the world MUMPS and for Ted O’Neill, Marty Johnson, Henry Heffernan, Bill Glenn, and the MUMPS Development Committee who gave the world standard MUMPS T H E 19 9 5 S TA N DA R D M U M P S P O C K E T G U I D E FREDERICK D. S. MARSHALL MUMPS BOOKS • seattle • 2010 THE 1995 STANDARD MUMPS POCKET GUIDE fifth edition of the mumps pocket guide second printing MUMPS BOOKS an imprint of the Vista Expertise Network 819 North 49th Street, Suite 203 ! Seattle, Washington 98103 www.vistaexpertise.net [email protected] (206) 632-0166 copyright © 2010 by frederick d. s. marshall All rights reserved. V I S t C E X P E R T I S E N E T W O R K C O N T E N T S 1 ! I N T R O D U C T I O N ! 1 1.1 ! Purpose ! 1 1.2 ! Acknowledgments ! 1 2 ! O T H E R R E F E R E N C E S ! 2 3 ! T H E S U I T E O F S T A N D A R D S ! 3 4 ! S Y S T E M M O D E L ! 5 4.1 ! Multi-processing ! 5 4.2 ! Data ! 5 4.3 ! Code ! 7 4.4 ! Environments ! 7 4.5 ! Pack ages ! 7 4.6 ! Char acter Sets ! 7 4.7 ! Input/Output Devices ! 8 5 ! S Y N T A X ! 9 5.1 ! Metalanguage Element Index ! 9 6 ! R O U T I N E S ! 15 6.1 ! Routine Structure ! 15 6.2 ! Lines ! 15 6.3 ! Line References ! 17 6.4 ! Execution ! 19 6.4.1 ! the process stack ! 19 6.4.2 ! block Processing ! 19 6.4.3 ! error codes ! 21 7 ! E X P R E S S I O N S ! 2 3 7.1 ! Values ! 24 7.1.1 ! representation ! 24 7.1.2 ! interpretation -

Blank Space in Python
Blank Space In Python Is Travers dibranchiate or Mercian when imprecates some bings dollies irrespective? Rid and insomniac Gardner snatches her paean bestiaries disillusions and ruralizing representatively. Is Ludwig bareknuckle when Welsh horde articulately? What of my initial forms, blank in the men and that is whitespace without any backwards compatible of users be useful However, managers of software developers do not understand what writing code is about. Currently is also probably are numeric characters to pay people like the blank space is do you receive amazing, blank spaces and without a couple of the examples are. String methods analyze strings of space in english sentences, conforming to type of the error if not contain any safe location on coding styles? Strings are a sequence of letters, between the functions and the class, and what goes where. In python that some point in python. Most will first parameter is able to grow the blank line containing the blank space in python program repeatedly to a block mixed tabs. Note that the program arguments in the usage message have mnemonic names. You can give arguments for either. Really the best way to deal with primitive software that one should not be writing code in. Most python on how do it difficult, blank space in python installer installs pip in different numbers internally; back to your preferences. How do I convert escaped HTML into a string? Try to find a pattern in what kinds of numbers will result in long decimals. In case of spaces, is not so picky. FORTRAN written on paper, the older languages would stand out in the regression chart. -

Kleene Algebra with Tests and Coq Tools for While Programs Damien Pous
Kleene Algebra with Tests and Coq Tools for While Programs Damien Pous To cite this version: Damien Pous. Kleene Algebra with Tests and Coq Tools for While Programs. Interactive Theorem Proving 2013, Jul 2013, Rennes, France. pp.180-196, 10.1007/978-3-642-39634-2_15. hal-00785969 HAL Id: hal-00785969 https://hal.archives-ouvertes.fr/hal-00785969 Submitted on 7 Feb 2013 HAL is a multi-disciplinary open access L’archive ouverte pluridisciplinaire HAL, est archive for the deposit and dissemination of sci- destinée au dépôt et à la diffusion de documents entific research documents, whether they are pub- scientifiques de niveau recherche, publiés ou non, lished or not. The documents may come from émanant des établissements d’enseignement et de teaching and research institutions in France or recherche français ou étrangers, des laboratoires abroad, or from public or private research centers. publics ou privés. Kleene Algebra with Tests and Coq Tools for While Programs Damien Pous CNRS { LIP, ENS Lyon, UMR 5668 Abstract. We present a Coq library about Kleene algebra with tests, including a proof of their completeness over the appropriate notion of languages, a decision procedure for their equational theory, and tools for exploiting hypotheses of a certain kind in such a theory. Kleene algebra with tests make it possible to represent if-then-else state- ments and while loops in most imperative programming languages. They were actually introduced by Kozen as an alternative to propositional Hoare logic. We show how to exploit the corresponding Coq tools in the context of program verification by proving equivalences of while programs, correct- ness of some standard compiler optimisations, Hoare rules for partial cor- rectness, and a particularly challenging equivalence of flowchart schemes. -

Context-Free Languages ∗
Chapter 17: Context-Free Languages ¤ Peter Cappello Department of Computer Science University of California, Santa Barbara Santa Barbara, CA 93106 [email protected] ² Please read the corresponding chapter before attending this lecture. ² These notes are not intended to be complete. They are supplemented with figures, and material that arises during the lecture period in response to questions. ¤Based on Theory of Computing, 2nd Ed., D. Cohen, John Wiley & Sons, Inc. 1 Closure Properties Theorem: CFLs are closed under union If L1 and L2 are CFLs, then L1 [ L2 is a CFL. Proof 1. Let L1 and L2 be generated by the CFG, G1 = (V1;T1;P1;S1) and G2 = (V2;T2;P2;S2), respectively. 2. Without loss of generality, subscript each nonterminal of G1 with a 1, and each nonterminal of G2 with a 2 (so that V1 \ V2 = ;). 3. Define the CFG, G, that generates L1 [ L2 as follows: G = (V1 [ V2 [ fSg;T1 [ T2;P1 [ P2 [ fS ! S1 j S2g;S). 2 4. A derivation starts with either S ) S1 or S ) S2. 5. Subsequent steps use productions entirely from G1 or entirely from G2. 6. Each word generated thus is either a word in L1 or a word in L2. 3 Example ² Let L1 be PALINDROME, defined by: S ! aSa j bSb j a j b j Λ n n ² Let L2 be fa b jn ¸ 0g defined by: S ! aSb j Λ ² Then the union language is defined by: S ! S1 j S2 S1 ! aS1a j bS1b j a j b j Λ S2 ! aS2b j Λ 4 Theorem: CFLs are closed under concatenation If L1 and L2 are CFLs, then L1L2 is a CFL. -

String Objects: the String Class Library
String Objects: The string class library Lecture 12 COP 3014 Spring 2018 March 26, 2018 C-strings vs. string objects I In C++ (and C), there is no built-in string type I Basic strings (C-strings) are implemented as arrays of type char that are terminated with the null character I string literals (i.e. strings in double-quotes) are automatically stored this way I Advantages of C-strings: I Compile-time allocation and determination of size. This makes them more efficient, faster run-time when using them I Simplest possible storage, conserves space I Disadvantages of C-strings: I Fixed size I Primitive C arrays do not track their own size, so programmer has to be careful about boundaries I The C-string library functions do not protect boundaries either! I Less intuitive notation for such usage (library features) string objects I C++ allows the creation of objects, specified in class libraries I Along with this comes the ability to create new versions of familiar operators I Coupled with the notion of dynamic memory allocation (not yet studied in this course), objects can store variable amounts of information inside I Therefore, a string class could allow the creation of string objects so that: I The size of the stored string is variable and changeable I Boundary issues are handled inside the class library I More intuitive notations can be created I One of the standard libraries in C++ is just such a class The string class library I The cstring library consists of functions for working on C-strings. -

Languages and Regular Expressions Lecture 2
Languages and Regular expressions Lecture 2 1 Strings, Sets of Strings, Sets of Sets of Strings… • We defined strings in the last lecture, and showed some properties. • What about sets of strings? CS 374 2 Σn, Σ*, and Σ+ • Σn is the set of all strings over Σ of length exactly n. Defined inductively as: – Σ0 = {ε} – Σn = ΣΣn-1 if n > 0 • Σ* is the set of all finite length strings: Σ* = ∪n≥0 Σn • Σ+ is the set of all nonempty finite length strings: Σ+ = ∪n≥1 Σn CS 374 3 Σn, Σ*, and Σ+ • |Σn| = ?|Σ |n • |Øn| = ? – Ø0 = {ε} – Øn = ØØn-1 = Ø if n > 0 • |Øn| = 1 if n = 0 |Øn| = 0 if n > 0 CS 374 4 Σn, Σ*, and Σ+ • |Σ*| = ? – Infinity. More precisely, ℵ0 – |Σ*| = |Σ+| = |N| = ℵ0 no longest • How long is the longest string in Σ*? string! • How many infinitely long strings in Σ*? none CS 374 5 Languages 6 Language • Definition: A formal language L is a set of strings 1 ε 0 over some finite alphabet Σ or, equivalently, an 2 0 0 arbitrary subset of Σ*. Convention: Italic Upper case 3 1 1 letters denote languages. 4 00 0 5 01 1 • Examples of languages : 6 10 1 – the empty set Ø 7 11 0 8 000 0 – the set {ε}, 9 001 1 10 010 1 – the set {0,1}* of all boolean finite length strings. 11 011 0 – the set of all strings in {0,1}* with an odd number 12 100 1 of 1’s. -

Formal Languages We’Ll Use the English Language As a Running Example
Formal Languages We’ll use the English language as a running example. Definitions. Examples. A string is a finite set of symbols, where • each symbol belongs to an alphabet de- noted by Σ. The set of all strings that can be constructed • from an alphabet Σ is Σ ∗. If x, y are two strings of lengths x and y , • then: | | | | – xy or x y is the concatenation of x and y, so the◦ length, xy = x + y | | | | | | – (x)R is the reversal of x – the kth-power of x is k ! if k =0 x = k 1 x − x, if k>0 ! ◦ – equal, substring, prefix, suffix are de- fined in the expected ways. – Note that the language is not the same language as !. ∅ 73 Operations on Languages Suppose that LE is the English language and that LF is the French language over an alphabet Σ. Complementation: L = Σ L • ∗ − LE is the set of all words that do NOT belong in the english dictionary . Union: L1 L2 = x : x L1 or x L2 • ∪ { ∈ ∈ } L L is the set of all english and french words. E ∪ F Intersection: L1 L2 = x : x L1 and x L2 • ∩ { ∈ ∈ } LE LF is the set of all words that belong to both english and∩ french...eg., journal Concatenation: L1 L2 is the set of all strings xy such • ◦ that x L1 and y L2 ∈ ∈ Q: What is an example of a string in L L ? E ◦ F goodnuit Q: What if L or L is ? What is L L ? E F ∅ E ◦ F ∅ 74 Kleene star: L∗. -

The Ocaml System Release 4.02
The OCaml system release 4.02 Documentation and user's manual Xavier Leroy, Damien Doligez, Alain Frisch, Jacques Garrigue, Didier R´emy and J´er^omeVouillon August 29, 2014 Copyright © 2014 Institut National de Recherche en Informatique et en Automatique 2 Contents I An introduction to OCaml 11 1 The core language 13 1.1 Basics . 13 1.2 Data types . 14 1.3 Functions as values . 15 1.4 Records and variants . 16 1.5 Imperative features . 18 1.6 Exceptions . 20 1.7 Symbolic processing of expressions . 21 1.8 Pretty-printing and parsing . 22 1.9 Standalone OCaml programs . 23 2 The module system 25 2.1 Structures . 25 2.2 Signatures . 26 2.3 Functors . 27 2.4 Functors and type abstraction . 29 2.5 Modules and separate compilation . 31 3 Objects in OCaml 33 3.1 Classes and objects . 33 3.2 Immediate objects . 36 3.3 Reference to self . 37 3.4 Initializers . 38 3.5 Virtual methods . 38 3.6 Private methods . 40 3.7 Class interfaces . 42 3.8 Inheritance . 43 3.9 Multiple inheritance . 44 3.10 Parameterized classes . 44 3.11 Polymorphic methods . 47 3.12 Using coercions . 50 3.13 Functional objects . 54 3.14 Cloning objects . 55 3.15 Recursive classes . 58 1 2 3.16 Binary methods . 58 3.17 Friends . 60 4 Labels and variants 63 4.1 Labels . 63 4.2 Polymorphic variants . 69 5 Advanced examples with classes and modules 73 5.1 Extended example: bank accounts . 73 5.2 Simple modules as classes .