Cutter IT Journal
Total Page:16
File Type:pdf, Size:1020Kb

Load more
Recommended publications
-

Structured Analysis
240 Structured Analysis Tom DeMarco Principal of the Atlantic Systems Guild New York M.S., Columbia, Diplome, University of Paris Bell Labs: ESS-1 project Manager of real-time projects, distributed online banking systems J.D. Warnier Prize, Stevens Prize Fellow of IEEE Major contributions: Structured Analysis, Peopleware Current interests: project management, change facilitation, litigation of software-intensive contracts sd&m Conference 2001, Software Pioneers Eds.: M. Broy, E. Denert, Springer 2002 241 Tom DeMarco Structured Analysis: Beginnings of a New Discipline How it happened When I arrived at Bell Telephone Laboratories in the fall of 1963, I was immediately assigned to the ESS-1 project. This was a hardware/software endeavor to develop the world’s first commercial stored program telephone switch (now installed in telephone offices all over the world). At the time, the project was made up of some 600 persons, divided about half-and-half between hardware and software. There was also a small simulation group (a dozen people?) working to create an early prediction of system perfor- mance and robustness. I was at first assigned to the hardware group. My assignment was to de- velop certain circuits that enabled Emergency Action, the reconfiguration of processors when one was judged to have failed. This was an intriguing assignment since each of the two processors would diagnose the other and then try to decide together and agree on which one was incapable of furt- her processing – but somehow still capable to judge its own sanity. 242 Tom DeMarco To all of our surprise, the software for the project turned out to require a lot more effort than the hardware. -

The Great Methodologies Debate: Part 1
ACCESS TO THE EXPERTS The Journal of Information Technology Management December 2001 Vol. 14, No. 12 The Great Methodologies Debate: Part 1 Resolved “Today, a new debate rages: agile software Traditional methodologists development versus rigorous software are a bunch of process- development.” dependent stick-in-the-muds who’d rather produce flawless Jim Highsmith, Guest Editor documentation than a working system that meets business needs. Opening Statement Jim Highsmith 2 Rebuttal Lightweight, er, “agile” Agile Can Scale: Inventing and Reinventing methodologists are a bunch of SCRUM in Five Companies glorified hackers who are going to be in for a heck of a surprise Jeff Sutherland 5 when they try to scale up their “toys” into enterprise-level software. Agile Versus Traditional: Make Love, Not War! Robert L. Glass 12 Business Intelligence Methodologies: Agile with Rigor? Larissa T. Moss 19 Agility with the RUP Philippe Kruchten 27 Extreme Requirements Engineering Larry Wagner 34 Exclusion, Assumptions, and Misinterpretation: Foes of Collaboration Lou Russell 39 Opening Statement by Jim Highsmith In the early 1980s, I participated in rigorous software development. others be able to understand the one round of methodology debate. Agile approaches (Extreme similarities and differences and be Structured analysis and design Programming, Crystal Methods, able to apply the right mix to their champions such as Tom DeMarco, Lean Development, Feature-Driven own organization. Both the SEI and Ed Yourdon, and Tim Lister were Development, Adaptive Software Rational have made wonderful on one side of the debate, while Development, SCRUM, and contributions to software develop- data-driven design aficionados like Dynamic Systems Development ment, but it is important to Ken Orr, Jean-Dominique Warnier, Methodology) populate one camp. -

Examining Capabilities As Architecture
September 2013 BPTrends ▪ Examining Capabilities as Architecture Examining Capabilities as Architecture Ralph Whittle Introduction This Article is a direct response to one written by Mike Rosen titled, “Are Capabilities Architecture?” [1] published in February 2013 by BPTrends It offers a different and contrasting point of view on accepting capability modeling and mapping as “architecture.” Business Architecture (BA) approaches and methods, while still evolving, have at least reached a point of maturity where the enterprise can fairly assess how it will develop and advance this initiative. As with any emerging field, a variety of approaches and methods will develop and enjoy success. From an historical perspective, consider the number of Business Process Management (BPM), Enterprise Architecture (EA) and Service-Oriented Architecture (SOA) approaches that have matured over the years. And no doubt, the same will eventually occur with the Business Architecture over the next few years. However, just as with the BPM, EA and SOA some different and contrasting points of view will find their way into the various Business Architecture approaches, techniques and methods. Today, at least two different and contrasting organizing principles are considered for Business Architecture. One is “capability centric” and the other is “process centric.” This article advocates and supports the “process centric” organizing principle, specifically using a value stream which is an end-to-end collection of activities that creates a result for a “customer,” who may be the ultimate customer or an internal “end user” of the value stream. The value stream has a clear goal: to satisfy (or, better, to delight) the customer.[2] This is a well known term, familiar in Six Sigma, Lean Manufacturing and BPM approaches. -

Download Slides
Agile Development within the Corporation Jutta Eckstein 1 ©2009-2012 by IT-communication.com Agenda Processes in the enterprise Integrating organizational processes Trust and transparency Supporting individual development 2 ©2009-2012 by IT-communication.com 1 Processes in the Enterprise 3 ©2009-2012 by IT-communication.com Organization Structure Large companies are often departmental structured – Structure assumes linear development – Tend to control rather than support Therefore: – Integrate them early-on – They are service-providers 4 ©2009-2012 by IT-communication.com 2 Misunderstanding the Agile Manifesto „Processes and tools over individuals, interactions, projects and needs“ – Assured by “Methodology Police” [Ed Yourdan] and the like – Requesting tools, frameworks, etc. although they don’t fit Yet, also an enterprise-wide Scrum process – Might prevent agility 5 ©2009-2012 by IT-communication.com Projects, Teams, and Processes differ Processes will differ Architecture, frameworks, platforms as services 6 ©2009-2012 by IT-communication.com 3 Integrating Organizational Processes 7 ©2009-2012 by IT-communication.com Use Budget instead of Estimates Decision for development requires an estimate Estimates should reflect investment – It’s a budget not an estimate – The budget can later on influence development 8 ©2009-2012 by IT-communication.com 4 Legal Department enables Flexibility Accept the interdependence of time, scope, resources, and quality – Optional scope contract – Requirements can change content- or priority-wise – Description of values and approach are part of the contract • Including the obligations of the customer 9 ©2009-2012 by IT-communication.com Marketing and Sales “You can rant and rave all you want about software quality (or lack there of), but the marketing guys run the world and they want market share now.. -

Risk Managment on an Agile Project
BIO PRESENTATION W3 6/28/2006 11:30 AM RISK MANAGMENT ON AN AGILE PROJECT Michele Sliger Rally Software Development Better Software Conference June 26 – 29, 2006 Las Vegas, NV USA Michele Sliger Michele Sliger has worked in software development for almost 20 years. Michele has extensive experience in agile methodologies, having employed agile practices as a founding member of the engineering teams at biotech start-ups UroCor and Genomica. At Genomica, Michele honed her Scrum and XP skills while working under Mike Cohn, a recognized founder of the Agile movement. She carried that experience forward into Qwest, where she served as an XP Coach on a team tasked with developing high-profile financial applications. She has an undergraduate degree in MIS and an MBA. She is a certified Project Management Professional (PMP), a Certified Scrum Master (CSM) and an active member of the board of the Agile Denver chapter. Currently, Sliger works as an agile consultant at Rally Software Development, where she trains software development teams in agile methodologies. In addition to her work for Rally, Sliger is also an adjunct faculty member of the University of Colorado where she teaches Software Project Management to graduate engineering students. Throughout her career, she has performed the gamut of software development roles, including programmer, database administrator, quality assurance manager, process manager and project manager. Risk Management on an Agile Project Presented by Michele Sliger Agile Coach and PMP Better Software Conference & Expo -

Peopleware, 2Nd Ed
36 Peopleware, 2nd ed. Partial Contents “This is my all-time favorite software engineering PART I: MANAGING THE HUMAN book. Peopleware accurately recognizes that software RESOURCE engineering is about people, not technology. • Somewhere Today, a Project Is “. it’s not just for managers, I strongly recom- Failing mend this book to everyone, from the most junior • Quality—If Time Permits engineer to the CEO.” PART II: THE OFFICE ENVIRONMENT Mark A. Herschberg — , Javaranch.com • The Furniture Police “. one of the most influential books I’ve ever read. • “You Never Get Anything Done The best way to describe it would be as an Anti-Dilbert Around Here Between 9 and 5” Manifesto. Ever wonder why everybody at Microsoft • Bring Back the Door Peopleware gets their own office, with walls and a door that shuts? PART III: THE RIGHT PEOPLE It’s in there. Why do managers give so much leeway to • Hiring a Juggler Productive Projects and Teams, 2nd ed. their teams to get things done? That’s in there too. • Happy to Be Here Why are there so many jelled SWAT teams at Microsoft PART IV: GROWING PRODUCTIVE by Tom DeMarco and Timothy Lister that are remarkably productive? Mainly because Bill TEAMS ISBN: 978-0-932633-43-9 Gates has built a company full of managers who read • Teamicide Peopleware. I can’t recommend this book highly ©1999 264 pages softcover • Chemistry for Team Formation $39.95 (includes $6 UPS in US) enough. It is the one thing every software manager PART V: IT'S SUPPOSED TO BE FUN needs to read . -

Cutter IT Journal
Cutter The Journal of IT Journal Information Technology Management Vol. 24, No. 8 August 2011 “Some people get stuck on the Devops: A Software Revolution word ‘devops,’ thinking that it’s just about development in the Making? and operations working together. Systems thinking advises us to optimize the At Arm’s Length Arm in Arm whole; therefore devops Automating the delivery process reduces Development and operations often play cats must apply to the whole the time development and operations have and dogs during deployment. To stop the organization, not only the to spend together. This means that when fighting, we must bring them closer together dev and ops must interact, they can focus so they will start collaborating again. part between development on the issues that really matter. and operations.” — Patrick Debois, Opening Statement Guest Editor by Patrick Debois . 3 Why Enterprises Must Adopt Devops to Enable Continuous Delivery by Jez Humble and Joanne Molesky . 6 Devops at Advance Internet: How We Got in the Door by Eric Shamow . 13 The Business Case for Devops: A Five-Year Retrospective by Lawrence Fitzpatrick and Michael Dillon . 19 Next-Generation Process Integration: CMMI and ITIL Do Devops by Bill Phifer . .28 Devops: So You Say You Want a Revolution? by Dominica DeGrandis . 34 Cutter IT Journal About Cutter IT Journal Cutter IT Journal® Cutter Business Technology Council: Part of Cutter Consortium’s mission is to Cutter IT Journal subscribers consider the Rob Austin, Ron Blitstein, Christine Davis, Tom DeMarco, Lynne Ellyn, foster debate and dialogue on the business Journal a “consultancy in print” and liken Israel Gat, Tim Lister, Lou Mazzucchelli, technology issues challenging enterprises each month’s issue to the impassioned Ken Orr, and Robert D. -

Chapter 1: Introduction
Just Enough Structured Analysis Chapter 1: Introduction “The beginnings and endings of all human undertakings are untidy, the building of a house, the writing of a novel, the demolition of a bridge, and, eminently, the finish of a voyage.” — John Galsworthy Over the River, 1933 www.yourdon.com ©2006 Ed Yourdon - rev. 051406 In this chapter, you will learn: 1. Why systems analysis is interesting; 2. Why systems analysis is more difficult than programming; and 3. Why it is important to be familiar with systems analysis. Chances are that you groaned when you first picked up this book, seeing how heavy and thick it was. The prospect of reading such a long, technical book is enough to make anyone gloomy; fortunately, just as long journeys take place one day at a time, and ultimately one step at a time, so long books get read one chapter at a time, and ultimately one sentence at a time. 1.1 Why is systems analysis interesting? Long books are often dull; fortunately, the subject matter of this book — systems analysis — is interesting. In fact, systems analysis is more interesting than anything I know, with the possible exception of sex and some rare vintages of Australian wine. Without a doubt, it is more interesting than computer programming (not that programming is dull) because it involves studying the interactions of people, and disparate groups of people, and computers and organizations. As Tom DeMarco said in his delightful book, Structured Analysis and Systems Specification (DeMarco, 1978), [systems] analysis is frustrating, full of complex interpersonal relationships, indefinite, and difficult. -

Dorset House Catalog
DORSET HOUSE PUBLISHING About Dorset House Books on Software and Systems Development www.dorsethouse.com ounded in 1984, Dorset House Publishing has emerged as a valued Fsource for high-quality, readable titles for the systems and software Adrenaline Perfect Software: professional. Rather than follow fads, we select books that will have a Junkies and And Other lasting impact on the way systems and software engineers and managers Illusions About Template Zombies work. Specific topic areas include requirements analysis, systems Testing by DeMarco, engineering, software development, software quality, management, Hruschka, Lister, by Gerald M. McMenamin, and Weinberg productivity, design, programming, testing, consulting, and more. See page 37. J. & S. Robertson orset House is an independent publisher, and we only release about See page 4. Dtwo books per year. Each book is carefully chosen for its excellence. We pride ourselves on the amount of attention and care our editors Agile Software iTeam: devote to the quality of the text. That same concern for quality is shared Development Putting the “I” by our Website, mail-order, and phone-order staffs. We want to make it with Distributed Back into Team as easy as possible for our readers to purchase—and read!—our books. Teams by William E. Perry by Jutta Eckstein See page 29. he quality of our books and service also draws the best authors to us. As See page 6. Tcolumnist Warren Keuffel puts it: “I always pay particular attention to new releases from Dorset House. what it lacks in quantity of titles released each year it makes up for in quality—the authors’ list reads like a SEE INSIDE FOR THESE FORTHCOMING TITLES who’s who in software engineering. -

Business Process Redesign: Design the Improved Process
Calhoun: The NPS Institutional Archive Theses and Dissertations Thesis Collection 1993-09 Business process redesign: design the improved process Warwick, Jerry L. Monterey, California. Naval Postgraduate School http://hdl.handle.net/10945/40010 NAVAL POSTGRADUATE SCHOOL Monterey, California AD-A274 947 DTIC I~~RADSI$ELECT 2 71 S_•JAN THESIS BUSINESS PROCESS REDESIGN: DESIGN THE 1MPROVED PROCESS by Jerry L. Warwick September, 1993 Thesis Advisor: William J. Haga Approved for public release; distribution is unlimited. 94-02780 \" IHI1111III11111111i94- 2 6 20 0 Unclassified Security Classification of this page REPORT DOCUMENTATION PACE ]a Report Security Classification Unclassified lb Restrictive Markings 2a Security Classification Authority 3 Distribution/Availability of Report 2b Declassification/Downgrading Schedule Approved for public release, distribution is unlimited 4 Performing Organization Report Number(s) 5 Monitoring Organization Report Number(s) 6a Name of Performing Organization 6b Office Symbol 7a Name of Monitoring Organization Naval Postgraduate School ,i',/pplcaqlej 37 Naval Postgraduate School 6c Address c,/4: sl/le, aldZIP code, 7b Address styl:sale. aod Z/P code) Monterey CA 93943-5000 Monterey CA 93943-5000 Ba Name of Funding/Sponsoring Organization 6b Office Symbol 9 Procurement Instrument Identification Number Address scl•r//e. ardiZ/Pcode) I0 Source of Funding Numbers Program Element No .Project No ITask No Wvork Unit Accession No I1 Title {ic/ide secur/ly c/ssi,/',ac/-Business Process Redesign: Design the Improved Process 12 Personal Author(s) Jerry L. Warwick i3a Type ofT Reporti13b Time Covered 14 Date of Report &reari 1n/'. daj l 1 Page Count 155 Master's Thesis IFrom - To 11993 September 16 Supplementary Notation The views expressed in this thesis are those of the author and do not reflect the official policy or position of the Department of Defense or the U.S. -

Agile Software Development In
THE DORSET HOUSE QUARTERLY VOL. XIV NO. 1 SUMMER 2004 DORSET HOUSE PUBLISHING 353 WEST 12TH STREET NEW YORK, NEW YORK 10014 USA Greetings DHQ As we approach our 20th anniversary in December, we take pride in what’s shaping up to be our most prolific year DHQ EXCERPT ever. As we describe below and on page 6, we’ve added three books to our forthcoming titles list. Be sure to subscribe to e-DHQ for updates as we release these titles in Agility and Largeness the coming months—just e-mail [email protected]. DeMarco and Lister by Jutta Eckstein Waltz Away with a Adapted from Chapter 1 of Jolt Award for Best Book Agile Software Development in the Large: In a ceremony at the SD West conference in Santa Clara, California, Tom DeMarco Diving Into the Deep and Timothy Lister’s Waltzing with Bears: ISBN: 0-932633-57-9 ©2004 Managing Risk on Software Projects was 248 pages softcover $39.95 postpaid awarded the Jolt Product Excellence Tom DeMarco and Tim Lister cele- Award for best general-interest book. brate their Jolt Award for best book. gile processes promise to react flexibly to continuously The Jolt Awards are presented every year to products changing requirements. That is why agile processes are that have boosted the productivity of software profes- Acurrently treated as a panacea for successful software sionals. Tim Lister was present to receive the award, a can development. However, agile processes are almost always of Jolt cola ensconced in a lucite cube. Out of just six final- recommended for small projects and small teams only—bad ists for the award, another Dorset news for those large teams that have to deal with speedy House release was honored: Five Core requirements changes. -
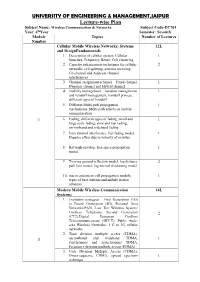
UNIVERSITY of ENGINEERING & MANAGEMENT,JAIPUR Lecture
UNIVERSITY OF ENGINEERING & MANAGEMENT,JAIPUR Lecture-wise Plan Subject Name: Wireless Communication & Networks Subject Code-EC701 Year: 4thYear Semester: Seventh Module Topics Number of Lectures Number Cellular Mobile Wireless Networks: Systems 12L and DesignFundamentals 1. Description of cellular system, Cellular 1 Structure, Frequency Reuse, Cell clustering 2. Capacity enhancement techniques for cellular 2 networks, cell splitting, antenna sectoring, Co-channel and Adjacent channel interferences 3. Channel assignment schemes – Fixed channel, 1 Dynamic channel and Hybrid channel 4. mobility management – location management 1 and handoff management, handoff process, different types of handoff 5. Different Multi-path propagation 1 mechanisms, Multi-path effects on mobile communication 1 6. Fading, different types of fading, small and 1 large scale fading, slow and fast fading, narrowband and wideband fading 7. Inter symbol interference, fast fading model, 1 Doppler effect due to velocity of mobiles, 8. Rayleigh envelop, free space propagation 1 model 9. Two ray ground reflection model, log distance 2 path loss model, log normal shadowing model 10. macro and micro cell propagation models, 1 types of base stations and mobile station antennas Modern Mobile Wireless Communication 14L Systems: 1. Evolution strategies – First Generation (1G) to Fourth Generation (4G), Personal Area Networks:PAN, Low Tier Wireless System: Cordless Telephone, Second Generation 2 (CT2),Digital European Cordless Telecommunications (DECT), Public wide- area Wireless Networks: 1 G to 3G cellular networks 2. Time division multiple access (TDMA), 2 narrowband and wideband TDMA, 1 synchronous and asynchronous TDMA, Frequency division multiple access (FDMA) 3. Code Division Multiple Access (CDMA), Direct-sequence CDMA, spread spectrum 1 technique 4.